
Korzystanie z wyrażenia regularnego (wyrażeń regularnych) w marketingu cyfrowym
Opublikowany: 2021-11-30Co to jest wyrażenie regularne:
Wyrażenie regularne, w skrócie Regex, to ciąg tekstu, który pozwala nam zarządzać, dopasowywać, filtrować i wyodrębniać tekst.
Regex jest szczególnie przydatny w marketingu cyfrowym, gdzie często konieczne jest wyodrębnienie określonych fragmentów przydatnych danych z dużych zbiorów danych.
Wyodrębnianie tych przydatnych danych może być uciążliwym zadaniem, gdy jest wykonywane ręcznie, często wymagając dużo czasu. Dzięki Regex możemy używać formuł, aby uprościć i przyspieszyć te zadania.
Chociaż Regex może początkowo wydawać się zniechęcający lub onieśmielający, ten blog powinien pokazać, jak prosty może być Regex i pomóc zachęcić innych marketerów do rozpoczęcia eliminacji i automatyzacji najbardziej nudnych i czasochłonnych części analizy danych.
Wspólne tokeny:
Wyrażenie regularne składa się z tokenów. Każdy z tych tokenów pasuje do pojedynczego znaku lub serii znaków w zestawie danych lub określa pozycję, w której musi się znajdować znak. W poniższej tabeli możemy zobaczyć kilka przykładów najczęściej używanych tokenów.
| Znak | Funkcjonować |
| | | Alternatywnie albo/albo. „A|B” pasuje zarówno do „A”, jak i „B”. |
| . | Dopasowuje dowolny pojedynczy znak inny niż nowy wiersz. |
| * | Dopasowuje zero lub więcej niż. Tak więc „.*” dopasowuje zero lub więcej znaków innych niż nowa linia. |
| + | Dopasowuje jeden lub więcej niż. Tak więc „.+” pasuje do jednego lub więcej znaków innych niż nowa linia. |
| ? | Dopasowuje zero lub jeden raz. Więc ".?" pasuje, jeśli jest zero lub jeden dowolny znak inny niż nowa linia. |
| \ | Dosłownie pasuje do następującego znaku. Więc "\." pasuje tylko do „.” i żadnych innych postaci. |
| (…) | Zaokrąglone nawiasy oznaczają grupę przechwytywania. Wszystko w zaokrąglonych nawiasach jest rejestrowane. |
| (?:…) | Zaokrąglone nawiasy, po których następuje „?:” oznaczają grupę, której nie można przechwycić. Jest to podobne do grupy przechwytywania, ale zawartość nie jest zachowywana. |
| {…} | Nawiasy klamrowe określają, ile wystąpień poprzedniego tokena chcesz dopasować. Na przykład „(a{1,3})” dopasuje od 1 do 3 wystąpień litery „a”. |
| […] | Nawiasy kwadratowe pozwalają nam zdefiniować zakresy lub różne znaki lub tokeny, które mają być dopasowane. Na przykład „[Az]” pasuje do dowolnej dużej lub małej litery. |
| ^ | „^” pasuje do początku ciągu lub gdy jest używany w nawiasach kwadratowych, oznacza znaki spoza zakresu. Na przykład [^Az] nie będzie pasować do żadnych małych ani wielkich liter. |
| $ | „$” dopasowuje koniec ciągu. Na przykład „[Az]$” dopasuje się do dużej lub małej litery, gdy zostanie znalezione na końcu ciągu. |
| \s | „\s” pasuje do dowolnego znaku odstępu. |
| \S | „\S” pasuje do dowolnego znaku innego niż biały. |
| \d | „\d” pasuje do dowolnego znaku cyfry. |
| \D | „\D” pasuje do dowolnego znaku niebędącego cyfrą. |
| \w | „\w” pasuje do dowolnej litery, cyfry lub podkreślenia. |
| \W | „\W” pasuje do czegokolwiek innego niż litera, cyfra lub podkreślenie. |
Przykłady przydatnych aplikacji dla Regex w marketingu cyfrowym:
krzycząca żaba
W Screaming Frog możemy wykonać niestandardowe ekstrakcje za pomocą Regex. Niestandardowe ekstrakcje pozwalają nam wyodrębnić mnóstwo przydatnych informacji ze strony internetowej.
Niektóre przykłady danych, które możemy wyodrębnić, obejmują; Adresy e-mail, identyfikatory śledzenia, znaczniki schematu, tytuły stron, adresy URL i wiele innych. Jeśli potrafisz o tym pomyśleć, prawdopodobnie możesz użyć Regex, aby to znaleźć!
Na poniższym obrazku widzimy przykład Regexa używanego do wyszukiwania adresów e-mail. Może to być przydatne, ponieważ posiadanie adresów e-mail w postaci zwykłego tekstu w witrynie może stanowić lukę w zabezpieczeniach i powodować zeskrobywanie adresów e-mail.
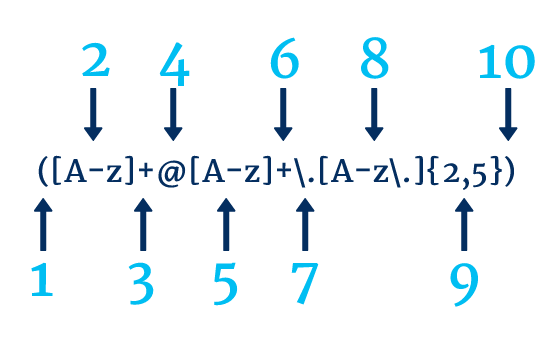
- Krok 1 pokazuje początek grupy przechwytywania
- Krok 2 dopasowuje dowolne wielkie i małe litery lub podkreślenia
- Krok 3 mówi nam, że szukamy 1 lub więcej wystąpień kroku 2
- Krok 4 pasuje do @
- Krok 5 dopasowuje dowolne wielkie litery, małe litery lub podkreślenia
- Krok 6 mówi nam, że szukamy 1 lub więcej wystąpień kroku 5
- Krok 7 pasuje do kropki, musimy użyć \, więc dopasowujemy kropkę dosłownie, a nie „.” funkcjonować
- Krok 8 pasuje do dowolnych wielkich liter, małych liter, podkreśleń lub kropek
- Krok 9 mówi nam, że szukamy od 2 do 5 wystąpień kroku 8
- Krok 10 pokazuje zamknięcie grupy przechwytywania
Jeśli wykonamy niestandardową ekstrakcję krzyczącej żaby za pomocą strony Codefixer i uruchomimy indeksowanie, możemy wtedy zobaczyć dowolny z adresów e-mail, które pojawiają się na stronie.


Google Analytics
Google Analytics pozwala nam używać Regex do wielu aplikacji, takich jak; filtrowanie widoków, tworzenie celów, tworzenie odbiorców, grupowanie treści i grupowanie kanałów.
W poniższym przykładzie widzimy przykład reguły Regex używanej w Google Analytics do filtrowania, aby wyświetlać tylko odsłony dla blogów lub stron studium przypadku. Trzeba przyznać, że jest to trochę przesada, możesz po prostu użyć (blog|przypadek), ale to daje lepszą demonstrację, jak to działa.

- Krok 1 pokazuje początek grupy przechwytywania
- Krok 2 oznacza, że musi to być początek ciągu
- Krok 3 pasuje do „/”. Używamy „\” przed ukośnikiem, aby dosłownie dopasować dokładnie ten znak
- Krok 4 pasuje do słowa „blog”
- Krok 5 pasuje do dowolnego znaku z wyjątkiem nowej linii raz lub więcej razy
- Krok 6 oznacza, że musimy dopasować coś przed lub za pionową kreską
- Krok 7 oznacza, że musi to być początek ciągu
- Krok 8 pasuje do „/”. Używamy „\” przed ukośnikiem, aby dosłownie dopasować dokładnie ten znak
- Krok 9 pasuje do słowa „przypadek”
- Krok 10 pasuje do dowolnego znaku z wyjątkiem nowej linii raz lub więcej razy
- Krok 11 pokazuje zamknięcie grupy przechwytywania
Kiedy filtrujemy nasz widok Google Analytics, widzimy teraz, że widzimy tylko odsłony naszych stron, które znajdują się w podfolderach bloga lub studiów przypadku.
Menedżer tagów Google
W Menedżerze tagów Google możemy użyć Regex do wyzwalania zdarzeń Google Analytics, gdy użytkownik wykona akcję.
Jedną z rzeczy, które możemy śledzić za pomocą Menedżera tagów Google, jest kliknięcie przez użytkowników numeru telefonu w witrynie.
Czasami w witrynie śledzenie prostych zdarzeń, takich jak kliknięcia numeru telefonu, może być skomplikowane przez formatowanie lub zmiany numeru telefonu pojawiające się w witrynie.
Komplikuje to proces tworzenia w Menedżerze tagów Google tagu wyzwalającego zdarzenie po kliknięciu numeru telefonu, ponieważ nie ma on spójnego formatu, co oznacza, że nie możemy po prostu ustawić tego wyzwalacza, gdy klikany adres URL zawiera „tel: 02890 923383”.
Załóżmy, że mamy linki do numeru telefonu Codefixer na stronie internetowej w trzech różnych formach;
- tel: 02890923383
- tel: 028 90 923383
- tel:(+44) 2890 923383
Możemy użyć następującego wyrażenia regularnego, aby dopasować wszystkie trzy powyższe numery telefonów.

- Krok 1 pokazuje początek grupy nieprzechwyconej „(?:”
- Krok 2 będzie pasował do „tel:”
- Krok 3 otwiera pierwszą grupę przechwytywania
- Krok 4 pasuje do „028” na początku numerów telefonów, jeśli ma to zastosowanie
- Krok 5 oznacza „lub”, więc możemy dopasować pierwszy lub następny zestaw znaków
- Krok 6 pasuje do „(+44)”. Znak „\” służy do ucieczki znaków specjalnych +, ( i )
- Krok 7 zamyka grupę przechwytywania
- Krok 8 pasuje, jeśli jest zero lub jeden znak odstępu
- Krok 9 pasuje do dowolnego znaku z zakresu 0-9
- Krok 10 pasuje, jeśli jest zero lub jeden znak odstępu
- Krok 11 dopasowuje się do co najmniej jednego z poprzednich kroków i ostatecznie zamyka grupę, której nie można przechwycić
Jak nauczyć się regexa:
Chociaż powyższy przewodnik zawiera wprowadzenie, kilka przykładów i praktyczne zastosowania Regex, najpierw przyznam, że w żadnym wypadku nie jestem ekspertem, a czytanie posta na blogu prawdopodobnie nie uczyni Cię ekspertem w nagły.
Głównym sposobem na poprawę Regex jest zakasanie rękawów i regularne ćwiczenie swoich umiejętności.
W ramach mojej roli jako PPC Lead w Codefixer, zacząłem regularnie używać Regex, aby uprościć i zautomatyzować proste zadania, a wraz z upływem czasu zacząłem używać go w bardziej złożonych lub skomplikowanych sytuacjach, które pomogły mi lepiej zrozumieć i używa do Regex.
Istnieje mnóstwo fantastycznych bezpłatnych zasobów online do nauki języka Regex. Trzy główne strony internetowe, które uważam za najbardziej przydatne to:
- https://regex101.com/ – Fantastyczna strona internetowa do tworzenia, testowania i debugowania Regex. Zwykle zawsze mam otwartą kartę w przeglądarce z otwartym Regex101. To absolutne ratowanie życia, gdy po prostu nie możesz dowiedzieć się, jak coś zrobić!
- https://regexone.com – Regexone to strona internetowa z łatwymi do naśladowania i pouczającymi, przyjemnymi ćwiczeniami, które pomogą Ci nauczyć się i korzystać z Regex. Zadania zaczynają się dość łatwo, ale szybko się rozwijają, stając się trudniejsze. Idealny dla początkujących.
- https://www.sitepoint.com/learn-regex/ – Ten blog Sitepoint wyjaśnia Regex w bardzo prosty i łatwy do zrozumienia sposób. Chociaż prawdopodobnie nie będziesz tego potrzebował codziennie, zawsze będzie to miejsce na moim pasku zakładek jako świetne źródło informacji dla początkujących.