
디지털 마케팅에서 Regex(정규 표현식) 사용
게시 됨: 2021-11-30정규 표현식이란 무엇입니까?
정규식 또는 줄여서 Regex는 텍스트를 관리, 일치, 필터링 및 추출할 수 있는 텍스트 문자열입니다.
Regex는 대규모 데이터 세트에서 유용한 데이터의 특정 부분을 추출해야 하는 경우가 많은 디지털 마케팅에 특히 유용합니다.
이 유용한 데이터를 추출하는 것은 수동으로 완료할 때 성가신 작업이 될 수 있으며 종종 상당한 시간이 소요됩니다. Regex를 사용하면 수식을 사용하여 이러한 작업을 단순화하고 속도를 높일 수 있습니다.
Regex는 처음에는 벅차거나 위협적으로 보일 수 있지만 이 블로그는 Regex가 얼마나 간단한지 보여주고 다른 마케터가 데이터 분석에서 가장 지루하고 시간이 많이 걸리는 부분을 제거하고 자동화하는 작업을 시작하도록 권장해야 합니다.
일반 토큰:
정규식은 토큰으로 구성됩니다. 이러한 각 토큰은 데이터 세트 내의 단일 문자 또는 일련의 문자와 일치하거나 문자가 있어야 하는 위치를 결정합니다. 아래 표에서 가장 일반적으로 사용되는 토큰의 몇 가지 예를 볼 수 있습니다.
| 토큰 | 기능 |
| | | 대안, 어느 쪽이든/또는. "A|B"는 "A" 및 "B" 모두와 일치합니다. |
| . | 새 줄 이외의 단일 문자와 일치합니다. |
| * | 0 이상과 일치합니다. 따라서 ".*"는 줄 바꿈 이외의 문자가 0개 이상 일치합니다. |
| + | 하나 이상과 일치합니다. 따라서 ".+"는 새 줄 이외의 하나 이상의 문자와 일치합니다. |
| ? | 0회 또는 1회 일치합니다. 그래서 ".?" 줄 바꿈 이외의 문자가 0개 또는 하나 있으면 일치합니다. |
| \ | 문자 그대로 다음 문자와 일치합니다. 그래서 "\." "."와만 일치합니다. 그리고 다른 캐릭터는 없습니다. |
| (…) | 둥근 괄호는 캡처 그룹을 나타냅니다. 둥근 괄호 안의 모든 것이 캡처됩니다. |
| (?:…) | 둥근 괄호 뒤에 "?:"가 오는 것은 캡처되지 않은 그룹을 나타냅니다. 이는 캡처 그룹과 유사하지만 콘텐츠가 유지되지 않습니다. |
| {…} | 중괄호는 일치시키려는 이전 토큰의 인스턴스 수를 결정합니다. 예를 들어, "(a{1,3})"는 문자 "a"의 인스턴스 1개에서 3개 사이에 일치합니다. |
| […] | 대괄호를 사용하면 일치시킬 범위나 다른 문자 또는 토큰을 정의할 수 있습니다. 예를 들어, "[Az]"는 모든 대문자 또는 소문자와 일치합니다. |
| ^^ | "^"는 문자열의 시작과 일치하거나 대괄호 안에 사용되는 경우 범위에 없는 문자를 의미합니다. 예를 들어 [^Az]는 소문자 또는 대문자와 일치하지 않습니다. |
| $ | "$"는 문자열의 끝과 일치합니다. 예를 들어, "[Az]$"는 문자열 끝에 있는 경우 대문자 또는 소문자와 일치합니다. |
| \에스 | "\"는 모든 공백 문자와 일치합니다. |
| \에스 | "\S"는 공백이 아닌 모든 문자와 일치합니다. |
| \디 | "\d"는 모든 숫자 문자와 일치합니다. |
| \디 | "\D"는 숫자가 아닌 모든 문자와 일치합니다. |
| \w | "\w"는 모든 문자, 숫자 또는 밑줄과 일치합니다. |
| \W | "\W"는 문자, 숫자 또는 밑줄 이외의 모든 항목과 일치합니다. |
디지털 마케팅에서 정규식에 대한 유용한 응용 프로그램의 예:
비명 개구리
Screaming Frog에서는 Regex를 사용하여 사용자 지정 추출을 수행할 수 있습니다. 사용자 지정 추출을 사용하면 웹사이트에서 수많은 유용한 정보를 추출할 수 있습니다.
추출할 수 있는 데이터의 몇 가지 예는 다음과 같습니다. 이메일 주소, 추적 ID, 스키마 마크업, 페이지 제목, URL 등. 생각할 수 있다면 Regex를 사용하여 찾을 수 있습니다!
아래 이미지에서 이메일 주소를 찾는 데 사용되는 정규식의 예를 볼 수 있습니다. 웹사이트에 일반 텍스트로 된 이메일 주소가 있으면 보안 취약점이 될 수 있고 이메일 주소가 스크랩될 수 있으므로 유용할 수 있습니다.
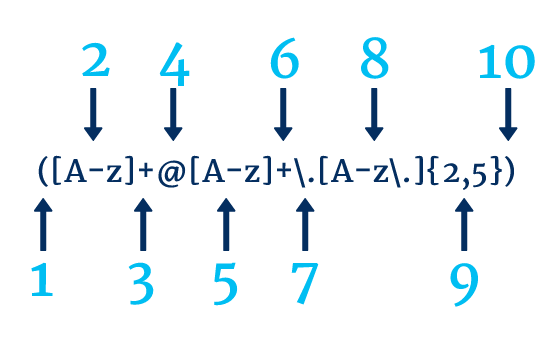
- 1단계는 캡처 그룹의 시작을 보여줍니다.
- 2단계는 대문자, 소문자 또는 밑줄과 일치합니다.
- 3단계는 2단계에서 1개 이상의 인스턴스를 찾고 있음을 알려줍니다.
- 4단계는 @와 일치합니다.
- 5단계는 대문자, 소문자 또는 밑줄과 일치합니다.
- 6단계는 5단계에서 1개 이상의 인스턴스를 찾고 있음을 알려줍니다.
- 7단계는 마침표와 일치하므로 \를 사용해야 "."가 아니라 문자 그대로 마침표와 일치합니다. 기능
- 8단계는 대문자, 소문자, 밑줄 또는 마침표와 일치합니다.
- 9단계는 8단계에서 2~5번의 발생을 찾고 있음을 알려줍니다.
- 10단계는 캡처 그룹의 종료를 보여줍니다.
Codefixer 웹 사이트를 사용하여 비명 개구리의 사용자 지정 추출을 수행하고 크롤링을 실행하면 웹 사이트에 나타나는 모든 이메일 주소를 볼 수 있습니다.


구글 애널리틱스
Google Analytics를 통해 다음과 같은 다양한 애플리케이션에 Regex를 사용할 수 있습니다. 보기 필터링, 목표 생성, 잠재고객 생성, 콘텐츠 그룹화 및 채널 그룹화.
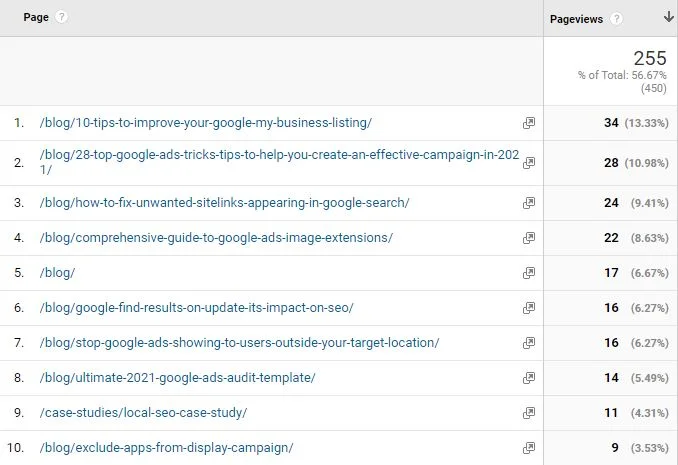
아래 예에서는 블로그 또는 사례 연구 페이지에 대한 페이지뷰만 표시하도록 필터링하기 위해 Google Analytics에서 사용되는 Regex의 예를 볼 수 있습니다. 확실히 이것은 약간 과잉입니다. (blog|case)를 사용할 수 있지만 작동 방식에 대한 더 나은 데모를 제공합니다.

- 1단계는 캡처 그룹의 시작을 보여줍니다.
- 2단계는 이것이 문자열의 시작 부분이어야 함을 의미합니다.
- 3단계는 "/"와 일치합니다. 문자 그대로 정확히 일치시키기 위해 슬래시 앞에 "\"를 사용합니다.
- 4단계는 "blog"라는 단어와 일치합니다.
- 5단계는 새 줄을 제외한 모든 문자와 한 번 이상 일치합니다.
- 6단계는 수직 막대 전후에 무언가를 일치시켜야 함을 의미합니다.
- 7단계는 이것이 문자열의 시작 부분이어야 함을 의미합니다.
- 8단계는 "/"와 일치합니다. 문자 그대로 정확히 일치시키기 위해 슬래시 앞에 "\"를 사용합니다.
- 9단계는 "case"라는 단어와 일치합니다.
- 10단계는 새 줄을 제외한 모든 문자와 한 번 이상 일치합니다.
- 11단계는 캡처 그룹 닫기를 보여줍니다.
Google Analytics 보기를 필터링하면 이제 블로그 또는 사례 연구 하위 폴더에 있는 페이지의 페이지 보기만 표시된다는 것을 알 수 있습니다.
Google 태그 관리자
Google 태그 관리자에서는 사용자가 작업을 완료할 때 Regex를 사용하여 Google 애널리틱스 이벤트를 트리거할 수 있습니다.
Google 태그 관리자를 사용하여 추적할 수 있는 한 가지는 사용자가 웹사이트에서 전화번호를 클릭하는 것입니다.
때때로 웹사이트에서 전화번호 클릭과 같은 간단한 이벤트를 추적하는 것은 웹사이트에 표시되는 전화번호의 형식이나 변형으로 인해 복잡해질 수 있습니다.
이는 전화번호가 일관된 형식이 아니기 때문에 클릭될 때 이벤트를 트리거하도록 Google 태그 관리자에서 태그를 생성할 수 있는 프로세스를 복잡하게 합니다. 즉, 클릭 URL에 "전화:02890 923383".
웹 사이트에 세 가지 다른 형식의 Codefixer 전화 번호 링크가 있다고 가정해 보겠습니다.
- 전화:02890923383
- 전화:028 90 923383
- 전화:(+44) 2890 923383
다음 정규식을 사용하여 위의 세 전화 번호 모두와 일치시킬 수 있습니다.

- 1단계는 비캡처 그룹 "(?:")의 시작을 보여줍니다.
- 2단계는 "tel:"과 일치합니다.
- 3단계는 첫 번째 캡처 그룹을 엽니다.
- 4단계는 해당되는 경우 전화번호 시작 부분의 "028"과 일치합니다.
- 5단계는 "또는"을 의미하므로 첫 번째 또는 다음 문자 집합과 일치시킬 수 있습니다.
- 6단계는 "(+44)"와 일치합니다. "\"는 특수 문자 +, ( 및 )를 이스케이프하는 것입니다.
- 7단계에서 캡처 그룹을 닫습니다.
- 8단계는 공백 문자가 0개 또는 1개 있는 경우 일치합니다.
- 9단계는 0-9 사이의 모든 문자와 일치합니다.
- 10단계는 공백 문자가 0개 또는 1개 있는 경우 일치합니다.
- 11단계는 이전 단계 중 하나 이상과 일치하고 최종적으로 비캡처 그룹을 닫습니다.
정규식을 배우는 방법:
위의 가이드는 Regex에 대한 소개, 몇 가지 예 및 실용적인 응용 프로그램을 제공하지만, 내가 전문가가 아님을 먼저 인정하고 블로그 게시물을 읽는다고 해서 모든 전문가가 되지는 않을 것입니다. 갑자기.
Regex를 향상시키는 주요 방법은 소매를 걷어붙이고 정기적으로 기술을 연습하는 것입니다.
Codefixer에서 PPC 리드로서의 역할의 일환으로 정규식을 정기적으로 사용하여 간단한 작업을 단순화하고 자동화하기 시작했으며 시간이 지남에 따라 더 복잡하거나 복잡한 상황에서 정규식을 사용하기 시작하여 이해도를 높이는 데 도움이 되었습니다. Regex의 용도.
Regex 학습을 위한 환상적인 무료 리소스가 온라인에 많이 있습니다. 내가 가장 유용하다고 생각한 세 가지 주요 웹 사이트는 다음과 같습니다.
- https://regex101.com/ – Regex를 빌드, 테스트 및 디버깅하기 위한 환상적인 웹사이트입니다. 나는 보통 Regex101이 열려 있는 내 브라우저에 탭이 열려 있습니다. 어떻게 해야 할지 잘 모를 때 이것은 절대적인 생명의 은인입니다!
- https://regexone.com – Regexone은 Regex를 배우고 사용하는 데 도움이 되는 따라하기 쉽고 유익하고 즐거운 연습을 제공하는 웹사이트입니다. 작업은 매우 쉽게 시작하지만 빠르게 진행되어 점점 더 어려워집니다. 초보자에게 이상적입니다.
- https://www.sitepoint.com/learn-regex/ – 이 Sitepoint 블로그는 Regex를 매우 간단하고 이해하기 쉬운 용어로 설명합니다. 이것이 매일 필요하지는 않지만 초보자를 위한 훌륭한 리소스로 항상 내 책갈피 막대에 표시됩니다.