
Desvendando os segredos do SEO: otimizando tópicos
Publicados: 2017-03-14Em nossa última parte do Unwrapping the Secrets of SEO, minha colega Holly Miller descreveu as etapas a serem empregadas na escolha de bons tópicos on-line no momento certo e em boa forma de SEO. Agora é hora de garantir que os tópicos sobre os quais você está escrevendo sejam otimizados igualmente bem para usuários e mecanismos de pesquisa. É hora de falar sobre otimização de tópicos semânticos!

Introdução à otimização de conteúdo
Como profissional de marketing on-line, SEO ou redator de conteúdo, seu objetivo final é garantir que tudo o que você criar para o público on-line funcionará conforme o esperado. Isso pode vir na forma de sinais de usuários, classificações mais altas, compartilhamentos sociais – ou conversões. O objetivo da otimização de conteúdo é exatamente esse – garantir que seu conteúdo se conecte em momentos importantes quando os usuários estiverem procurando informações por meio de mecanismos de pesquisa. Para que isso aconteça, ele precisa ser considerado o mais relevante possível pelos mecanismos de pesquisa (e, portanto, pelos usuários) para um tópico específico. Em última análise, otimizar seu conteúdo é mais bem servido ao entender que o que você realmente está tentando fazer é aumentar a relevância do conteúdo em vez de otimizá-lo.
Esse conceito geral de aumentar a relevância do conteúdo é algo que não é apenas divertido de se explorar da perspectiva de um SEO, mas também é extremamente útil para ajudar os redatores de conteúdo a entender quais subtópicos devem ser incluídos nos tópicos.
Para confiar totalmente nos dados que nos ajudarão a aumentar a relevância do nosso conteúdo, vamos mergulhar nos bastidores para ver como o Google entende a relevância do conteúdo.
Uma breve história da densidade de palavras-chave
Antes dos dias de inteligência artificial, aprendizado de máquina e todos aqueles algoritmos sofisticados, o Google classificava a qualidade da página principalmente com base em dois fatores: links e densidade de palavras-chave. Para SEOs como eu, isso foi realmente muito divertido. A otimização de mecanismos de pesquisa nos “velhos tempos” de alguns anos atrás costumava ser muito mais baseada em tática do que em estratégia.
Hoje em dia, é um jogo diferente. O Google e outros mecanismos de busca ficaram mais inteligentes e não julgam mais a relevância com base apenas em alguns links ou em algumas palavras-chave na página.
OK, se você não está otimizando para uma palavra-chave usando a densidade de palavras-chave, como você otimiza para um tópico? Os próximos dois conceitos podem parecer complicados no início, mas devem ser fáceis de entender.
Indexação semântica latente
A primeira é a Indexação Semântica Latente, ou LSI. A maneira como o Google usa o LSI é bem simples. Uma fórmula matemática define a proximidade e a relação entre os termos em um conteúdo. Os mecanismos de pesquisa rastrearão uma página da Web e, com base no título da página da Web ou no tópico principal, as palavras e frases mais comuns serão agrupadas e identificadas como as palavras-chave do tópico principal da página. Se os termos que o mecanismo de pesquisa encontrou em sua página forem relevantes, espera-se encontrar termos relacionados, como “automóveis”, “segunda mão”, “leilão” etc.
Para a maioria de vocês, tudo isso deve soar muito familiar. O LSI é simplesmente um método baseado em co-ocorrência em que os mecanismos de pesquisa procuram termos que ocorrem naturalmente em conjunto com outros termos. Aqui estão mais informações sobre o LSI de um post que escrevi há alguns meses.
Para TF*IDF ou Não para TF*IDF
Se você deseja ir mais fundo, TF*IDF, ou Frequência de Termo * Frequência de Documento Invertido, é a fórmula mais avançada. Portent.com escreve isso sobre TF*IDF:
“.. NÃO é OK deixar de fora a mãe de todos os algoritmos de recuperação de informação, TF-IDF, conhecido carinhosamente por geeks de busca como Term Frequency-Inverse Document Frequency.
Introduzido na década de 1970, esse algoritmo de classificação primária usa a presença, o número de ocorrências e os locais de ocorrência para produzir um peso estatístico sobre a importância de um termo específico no documento. Ele inclui um recurso de normalização para evitar que documentos longos e chatos passem a residir nos resultados da pesquisa devido à natureza de cisalhamento de sua circunferência.”
Embora você possa ver que é um conceito mais antigo, ainda permanece muito relevante. Semelhante ao LSI, o TF*IDF analisa palavras-chave específicas e tenta entender a relação entre cada uma delas. No entanto, vai um passo além, dando peso específico a cada termo.
Digamos que você esteja tentando entender quais palavras e frases são relevantes para o tópico de carros usados. Definimos a fórmula para analisar as 20 principais páginas de classificação. O TF*IDF funcionará de duas maneiras:
- TF (Term Frequency): um rastreador analisará cada uma das palavras em cada página da Web e determinará a frequência do termo (densidade de palavras-chave) de cada uma dessas palavras:

Isso seria repetido para a página 2, página 3, etc.
- IDF (Inverted Document Frequency): O rastreador analisará todas essas palavras e identificará em quantos documentos (dos 20 analisados) essas palavras estão presentes.
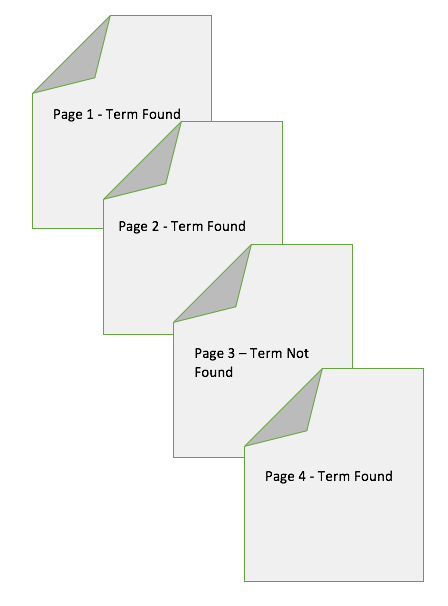
- É repetido para a página 2, página 3, etc…
- TF*IDF: Uma vez que esses dois itens são colocados juntos, um logaritmo simples é calculado e retorna uma pontuação (peso) para cada termo analisado.
Automóvel usado: TF*IDF = 0,8
Automóvel usado: TF*IDF = 0,6
O que torna esse método incrível é que ele realmente elimina as suposições de tentar entender quais palavras e, portanto, tópicos devem ser usados em conjunto com o tópico central do seu texto. Você pode então analisar quais palavras-chave têm mais peso e, portanto, são mais importantes para o tópico sobre o qual está escrevendo.
E a propósito – o Google fala sobre o TF*IDF em algumas de suas patentes de busca:
- https://www.google.com/patents/US7711668
- https://www.google.com/patents/US20130346424
- https://www.google.com/patents/US7730061
Se você não achou importante entender antes. Eu espero que você faça agora.
Aprofundando os tipos de entidade
Agora vamos falar sobre tipos de entidade. Vimos uma amostra de como o Google entende os termos mais importantes de um tópico específico ; O Google também entende a categorização de palavras. Vamos usar este artigo como exemplo. A manchete diz “Trump ameaça montadoras alemãs com 35% de tarifa de importação dos EUA”, dando uma boa visão geral do que você leu no artigo. Em resumo, o artigo diz que a BMW, a marca Vauxhall da GM e outras estão sendo notificadas pelo presidente Trump para produzir mais nos EUA. eles não investem mais na fabricação baseada nos EUA. Abaixo, uso a ferramenta de pesquisa de entidade do Watson da IBM para ver como um algoritmo de aprendizado de máquina define a relevância do conteúdo e como cada palavra é classificada em um tipo de entidade específico:





Veja um recurso adicional sobre como o Google agrupa entidades:

http://searchengineland.com/google-patent-question-answering-using-entity-references-unstructured-data-267273
O que isto significa? Os mecanismos de pesquisa, especialmente aqueles inteligentes o suficiente para usar o aprendizado de máquina, analisam TODAS as palavras em seu documento de texto e as pesam e classificam. Para vencer a concorrência, você precisará entender todos esses conceitos e garantir que tudo em sua página esteja devidamente otimizado.
Qualidade do conteúdo versus estrutura do conteúdo
Agora que falamos sobre tornar nosso conteúdo relevante em termos de qualidade, vamos ver como nosso conteúdo é relevante em termos de estrutura.
Um grande paradigma que muitos SEOs (costumavam) errar é simplesmente cuspir conteúdo (mesmo bem otimizado) em qualquer lugar da página e esperar que ele seja classificado (estou falando de você, especialmente no comércio eletrônico). Vejamos dois conteúdos:
Versão 1 :
“Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Cras venenatis mi eu urna tristique, id dictum ligula aliquet. Pellentesque non dignissim leo. Ut dignissim accumsan lectus, at maximus quam lobortis sit amet. Donec pharetra placerat mauris, sit amet molestie diam dictum ac. Vivamus quis ex quis arcu maleuada rhoncus vel eget ex. Sed eget tortor ut augue mattis aliquet in ac nunc. Vestibulum non arcu id quam egestas tristique. Suspendisse fringilla id risus nec dictum. Nunc finibus risus id odio vulputate, em pretium nisi ultricies. Integer imperdiet velit ligula, vitae pulvinar elit maleuada vitae.”
Versão 2 :
“Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Cras venenatis mi eu urna tristique, id dictum ligula aliquot:
- Pellentesque non dignissim leo. Ut dignissim accumsan lectus, at maximus quam lobortis sit amet. Donec pharetra placerat mauris, sit amet molestie diam dictum ac.
- Vivamus quis ex quis arcu maleuada rhoncus vel eget ex.
- Sed eget tortor ut augue mattis aliquet in ac nunc. Vestibulum non arcu id quam egestas tristique. Suspendisse fringilla id risus nec dictum.
Nunc finibus risus id odio vulputate, em pretium nisi ultricies. Integer imperdiet velit ligula, vitae pulvinar elit maleuada vitae.”
A versão 2 parece melhor, certo?
Isso não é apenas algo que ajudará os sinais gerais do usuário (menor taxa de rejeição, maior tempo na página, o que, esperançosamente, levará a um aumento de páginas por sessão) – mas ajudará nas classificações, pois os mecanismos de pesquisa entendem vários elementos CSS e, portanto, como uma página é colocada Fora.
Caindo na real com esses conceitos
Digamos que seu tópico principal seja “comprar um carro usado” e você esteja tentando entender sobre quais subtópicos escrever: Devo falar sobre o processo? Pontas? Comprar um carro fora do estado?
O primeiro passo é entender o mercado da melhor maneira possível em um determinado momento. Usando a plataforma de desenvolvimento de conteúdo ágil Searchmetrics Content Experience, podemos identificar rapidamente alguns itens de alto nível, incluindo volume de pesquisa, sazonalidade, palavras-chave semelhantes e integrações de pesquisa para orientar nossos tópicos:

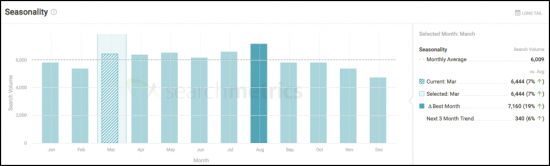

A próxima etapa da Searchmetrics Content Experience é trabalhar com o Topic Explorer para entender quais tópicos estão repercutindo no mercado e por quê:
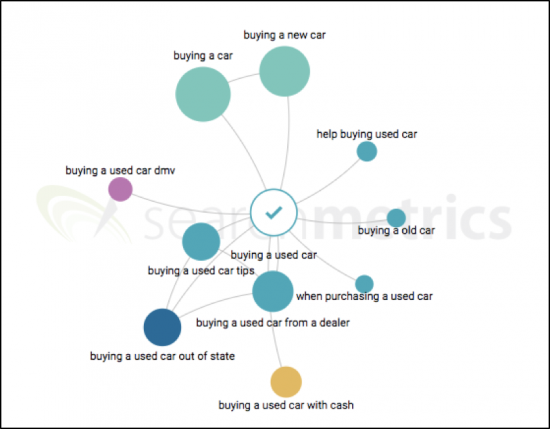
Graças ao gráfico de tópicos do Searchmetrics, podemos identificar rapidamente os tópicos principais que são semanticamente próximos ao tópico principal de “comprar um carro usado”. Curiosamente, vamos notar que muitas pessoas estão interessadas em saber como comprar um carro usado com dinheiro, ou comprar um carro usado fora do estado, ou de uma concessionária. Como nossa análise pode incluir até cinco tópicos principais, incluiremos aqueles com maior volume de pesquisa.
Ao selecionar alguns desses outros tópicos, nosso volume total de pesquisa aumenta para cerca de 7.000+
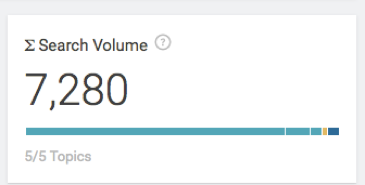
Feito isso, podemos começar a escrever!
Aplicando palavras-chave com desenvolvimento ágil de conteúdo
Quando estivermos prontos para escrever, vamos dar uma olhada no que você veria à esquerda no módulo do editor do Searchmetrics Content Experience. Antes mesmo de escrever qualquer coisa, notamos algumas coisas muito interessantes, principalmente quais palavras-chave (essencialmente subtópicos) sobre as quais escrever e a frequência recomendada para cada uma para se classificar bem nos resultados de pesquisa.
Lembre-se de todos esses conceitos de conteúdo no início do artigo? Dê uma olhada para ver onde a maioria dessas recomendações de palavras-chave são calculadas.
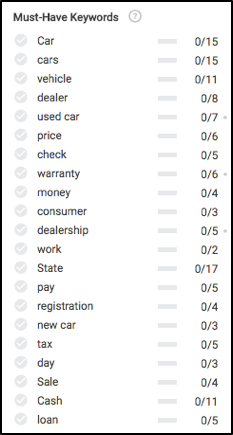
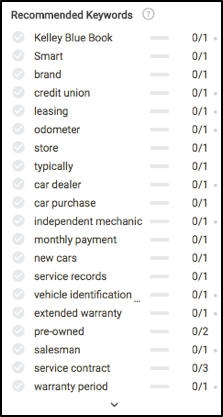
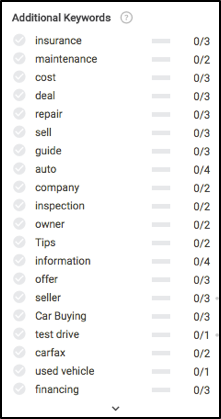
Com base nos dados acima, para garantir que nosso conteúdo seja totalmente relevante, precisamos escrever sobre seguro, manutenção, processo de test drive, garantia, registro, financiamento e alguns outros.
Uma vez que começamos a escrever, é aqui que a diversão começa:

Posso usar a ferramenta para adotar uma abordagem orientada por dados para escrever conteúdo de forma holística, obter pontuação de quão legível e bem estruturado é e até mesmo ver no console onde o conteúdo duplicado de outros sites pode me causar problemas na classificação.
Se você quiser se aprofundar um pouco mais e entrar nos dados, detalharemos o TF*IDF e outras recomendações baseadas em dados.
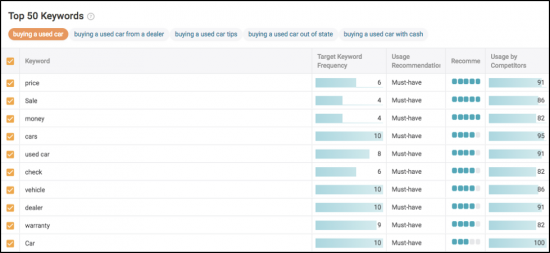
Por fim, você acompanha o impacto. Certifique-se de acompanhar todos os 5 tópicos principais para ver qual tem melhor desempenho em termos de classificações, tráfego e sinais do usuário.
Um lembrete: a velha mentalidade de “publicar e esquecer” não existe mais. Você deve “publicar e reciclar” para garantir que seu conteúdo esteja sempre otimizado e atualizado.
Desvendando os segredos do SEO
Compreender os fundamentos da otimização de conteúdo semântico é vital. Você não precisa ser técnico. Você não precisa ser um cientista de dados. Você só precisa prestar atenção e ser curioso. Depois de entender o valor de otimizar semanticamente seu conteúdo, a escrita centrada em dados não será apenas mais divertida, mas começará a fazer muito mais sentido.