
SEO의 비밀 풀기: 주제 최적화
게시 됨: 2017-03-14Unwrapping the Secrets of SEO의 마지막 기사에서 제 동료 Holly Miller는 적시에 좋은 SEO 형태로 좋은 온라인 주제를 선택하는 단계를 설명했습니다. 이제 당신이 쓰고 있는 주제가 사용자와 검색 엔진에 똑같이 최적화되어 있는지 확인해야 할 때입니다. 의미론적 주제 최적화에 대해 이야기할 시간입니다!

콘텐츠 최적화 소개
온라인 마케터, SEO 또는 콘텐츠 작가로서 궁극적인 목표는 온라인 청중을 위해 제작한 것이 무엇이든 예상대로 작동하도록 하는 것입니다. 이는 사용자 신호, 더 높은 순위, 사회적 공유 또는 전환의 형태로 올 수 있습니다. 콘텐츠 최적화의 목표는 바로 사용자가 검색 엔진을 통해 정보를 찾고 있는 중요한 순간에 콘텐츠가 연결되도록 하는 것입니다. 그렇게 하려면 특정 주제에 대해 검색 엔진(및 사용자)이 가능한 한 관련성이 있는 것으로 간주해야 합니다. 궁극적으로 콘텐츠 최적화는 콘텐츠를 최적화하기보다 콘텐츠 관련성을 높이는 것이 실제로 하려는 것임을 이해하면 더 효과적입니다.
콘텐츠 관련성 증가에 대한 이 일반적인 개념은 SEO의 관점에서 재미를 찾을 뿐만 아니라 콘텐츠 작성자가 주제에 포함되어야 하는 하위 주제를 이해하는 데 매우 유용합니다.
콘텐츠 관련성을 높이는 데 도움이 되는 데이터를 완전히 신뢰하기 위해 Google이 콘텐츠의 관련성을 어떻게 이해하는지 자세히 살펴보겠습니다.
키워드 밀도의 간략한 역사
인공 지능, 기계 학습 및 모든 멋진 알고리즘이 등장하기 전에 Google은 주로 링크와 키워드 밀도라는 두 가지 요소를 기반으로 페이지 품질을 평가했습니다. 나 같은 SEO에게 이것은 실제로 꽤 재미있었습니다. 몇 년 전 "구시대"의 검색 엔진 최적화는 전략 기반보다 전술 기반이었습니다.
요즘은 다른 볼게임입니다. Google 및 기타 검색 엔진은 더 똑똑해졌으며 더 이상 단순히 몇 개의 링크나 몇 개의 페이지 키워드만으로 관련성을 판단하지 않습니다.
좋습니다. 키워드 밀도를 사용하여 키워드를 최적화하지 않는 경우 주제에 대해 어떻게 최적화합니까? 다음 두 개념은 처음에는 복잡해 보일 수 있지만 이해하기 쉬워야 합니다.
잠재 시맨틱 인덱싱
첫 번째는 LSI(Latent Semantic Indexing)입니다. Google이 LSI를 사용하는 방식은 실제로 매우 간단합니다. 수학 공식은 콘텐츠에서 용어 간의 근접성과 관계를 정의합니다. 검색 엔진은 웹 페이지를 크롤링하고 웹 페이지 제목이나 주요 주제에 따라 가장 일반적인 단어와 구문을 그룹화하고 페이지의 핵심 주제 키워드로 식별합니다. 검색 엔진이 귀하의 페이지에서 찾은 용어가 관련 용어인 경우 "자동차", "중고", "경매" 등과 같은 관련 용어를 찾을 것으로 예상합니다.
대부분의 경우 이 모든 것이 매우 친숙하게 들릴 것입니다. LSI는 단순히 검색 엔진이 다른 용어와 함께 자연스럽게 발생하는 용어를 찾는 동시 발생 기반 방법입니다. 다음은 몇 달 전에 작성한 게시물에서 LSI에 대한 추가 정보입니다.
TF*IDF로 또는 TF*IDF로 아님
더 깊이 들어가고 싶다면 TF*IDF 또는 Term Frequency * Inverted Document Frequency가 더 고급 공식입니다. Portent.com은 TF*IDF에 대해 다음과 같이 씁니다.
"..모든 정보 검색 알고리즘의 어머니인 TF-IDF는 검색 괴짜에게 용어 빈도-역 문서 빈도로 애칭으로 알려져 있습니다.
1970년대에 도입된 이 기본 순위 알고리즘은 문서에서 특정 용어의 중요성에 대한 통계적 가중치를 생성하기 위해 존재, 발생 횟수 및 발생 위치를 사용합니다. 여기에는 긴 지루한 문서가 둘레의 전단 특성으로 인해 검색 결과에 머무르는 것을 방지하는 정규화 기능이 포함되어 있습니다.”
오래된 개념이라는 것을 알 수 있지만 여전히 매우 관련성이 있습니다. LSI와 유사하게 TF*IDF는 특정 키워드를 살펴보고 각각의 관계를 이해하려고 합니다. 그러나 각 용어에 특정 가중치를 부여하여 한 단계 더 나아갑니다.
어떤 단어와 문구가 중고차 주제와 관련이 있는지 이해하려고 한다고 가정해 보겠습니다. 상위 20개 순위 페이지를 보도록 공식을 설정했습니다. TF*IDF는 두 가지 방식으로 작동합니다.
- TF(용어 빈도): 크롤러는 각 웹페이지의 각 단어를 보고 각 단어의 용어 빈도(키워드 밀도)를 결정합니다.

이것은 2페이지, 3페이지 등에 대해 반복됩니다.
- IDF(Inverted Document Frequency): 크롤러는 이 모든 단어를 살펴보고 이 단어가 존재하는 문서(분석된 20개 중)의 수를 식별합니다.
- 2페이지, 3페이지 등으로 반복됩니다.
- TF*IDF: 이 두 항목을 합치면 단순 로그가 계산되고 분석된 각 용어에 대한 점수(가중치)가 반환됩니다.
중고차: TF*IDF = 0.8
중고차: TF*IDF = 0.6
이 방법을 놀랍게 만드는 것은 실제로 어떤 단어와 주제가 텍스트의 핵심 주제와 함께 사용되어야 하는지를 이해하려고 시도할 때 추측을 하지 않는다는 것입니다. 그런 다음 어떤 키워드가 가장 큰 비중을 차지하는지 분석할 수 있으므로 글을 쓰고 있는 주제에 더 중요합니다.
그런데 Google은 검색 특허 중 일부에서 TF*IDF에 대해 이야기합니다.
- https://www.google.com/patents/US7711668
- https://www.google.com/patents/US20130346424
- https://www.google.com/patents/US7730061
이전에 이해하는 것이 중요하다고 생각하지 않았다면. 지금 하시길 바랍니다.
엔티티 유형 탐구
이제 엔터티 유형에 대해 이야기해 보겠습니다. Google이 특정 주제에 대한 가장 중요한 용어를 이해하는 방법의 샘플을 보았습니다. Google은 또한 단어의 분류를 이해합니다. 이 기사를 예로 들어 보겠습니다. 헤드라인은 "트럼프가 35%의 미국 수입 관세로 독일 자동차 제조업체를 위협합니다"라는 제목으로 기사에서 읽을 내용에 대한 좋은 개요를 제공합니다. 간단히 말해서, 이 기사는 BMW, GM의 Vauxhall 브랜드 및 기타 브랜드가 미국에서 더 많이 생산하기 위해 트럼프 대통령에 의해 통지되고 있다고 말합니다. 그들은 미국 기반 제조에 더 많은 투자를 하지 않습니다. 아래에서는 IBM Watson의 엔터티 검색 도구를 사용하여 기계 학습 알고리즘이 콘텐츠 관련성을 정의하는 방법과 각 단어가 특정 엔터티 유형으로 분류되는 방법을 확인합니다.





Google이 항목을 클러스터링하는 방법에 대한 추가 리소스는 다음과 같습니다.
http://searchengineland.com/google-patent-question-answering-using-entity-references-unstructured-data-267273
이것은 무엇을 의미 하는가? 검색 엔진, 특히 기계 학습을 사용할 만큼 똑똑한 엔진은 텍스트 문서의 모든 단어를 보고 무게를 측정하고 분류합니다. 경쟁에서 이기려면 이러한 모든 개념을 이해하고 페이지의 모든 것이 적절하게 최적화되어 있는지 확인해야 합니다.
콘텐츠 품질 대 콘텐츠 구조
콘텐츠를 품질 측면에서 적절하게 만드는 것에 대해 이야기했으므로 이제 콘텐츠가 구조 측면에서 관련성이 있는지 살펴보겠습니다.
많은 SEO가 잘못 알고 있는 한 가지 거대한 패러다임은 페이지의 아무 곳에나 콘텐츠(최적화도 잘 됨)를 뱉어내고 순위가 오르기를 바라는 것입니다(특히 전자 상거래에서 호일에 대해 말하는 것입니다). 두 가지 콘텐츠를 살펴보겠습니다.

버전 1 :
“Lorem ipsum dolor sitmet, consectetur adipiscing elit.
Cras venenatis mi eu urna tristique, id dictum ligula aliquet. Pellentesque 비 품위있는 레오. Ut dignissim accumsan lectus, at maximus quam lobortis sit amet. Donec pharetra placerat mauris, sit amet molestie diam dictum ac. Vivamus quis ex quis arcu malesuada rhoncus vel eget ex. Sed eget tortor ut augue mattis aliquet in ac nunc. Vestibulum non arcu id quam egestas tristique. Suspendisse fringilla id risus nec dictum. Nunc finibus risus id odio vulputate, at pretium nisi ultricies. 정수 Imperdiet Velit ligula, vitae pulvinar elit malesuada vitae."
버전 2 :
“Lorem ipsum dolor sitmet, consectetur adipiscing elit.
Cras venenatis mi eu urna tristique, id dictum ligula aliquot:
- Pellentesque 비 품위있는 레오. Ut dignissim accumsan lectus, at maximus quam lobortis sit amet. Donec pharetra placerat mauris, sit amet molestie diam dictum ac.
- Vivamus quis ex quis arcu malesuada rhoncus vel eget ex.
- Sed eget tortor ut augue mattis aliquet in ac nunc. Vestibulum non arcu id quam egestas tristique. Suspendisse fringilla id risus nec dictum.
Nunc finibus risus id odio vulputate, at pretium nisi ultricies. 정수 Imperdiet Velit ligula, vitae pulvinar elit malesuada vitae."
버전 2가 더 좋아보이죠?
이것은 전반적인 사용자 신호(낮은 이탈률, 페이지에 머문 시간 증가, 세션당 페이지 증가로 이어짐)에 도움이 될 뿐만 아니라 검색 엔진이 다양한 CSS 요소를 이해하므로 페이지가 배치되는 방식에 따라 순위를 매기는 데 도움이 됩니다. 밖으로.
이러한 개념으로 현실화하기
핵심 주제가 "중고차 구매"이고 어떤 하위 주제에 대해 쓸지 이해하려고 한다고 가정해 보겠습니다. 프로세스에 대해 이야기해야 할까요? 팁? 국외 자동차를 구입?
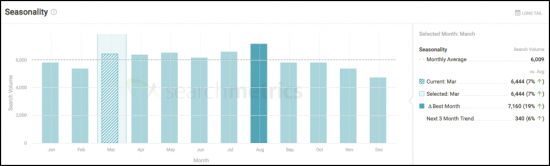
첫 번째 단계는 주어진 순간에 최대한 시장을 이해하는 것입니다. Searchmetrics Content Experience 민첩한 콘텐츠 개발 플랫폼을 사용하여 검색량, 계절성, 유사한 키워드 및 검색 통합을 포함하여 몇 가지 상위 수준 항목을 빠르게 식별하여 주제를 안내할 수 있습니다.


Searchmetrics Content Experience의 다음 단계는 Topic Explorer와 협력하여 시장에서 반향을 일으키는 주제와 그 이유를 이해하는 것입니다.
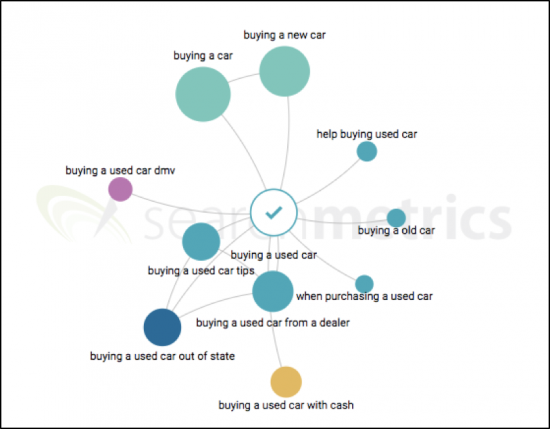
Searchmetrics 주제 그래프 덕분에 "중고차 구매"라는 주요 주제와 의미상 가까운 핵심 주제를 빠르게 식별할 수 있습니다. 흥미롭게도 많은 사람들이 현금으로 중고차를 사는 방법이나 다른 주나 딜러로부터 중고차를 사는 방법에 관심이 있다는 것을 알게 될 것입니다. 분석에는 최대 5개의 핵심 주제가 포함될 수 있으므로 검색량이 많은 주제를 포함합니다.
이러한 다른 주제 중 몇 가지를 선택하면 총 검색량이 약 7,000개 이상으로 증가합니다.
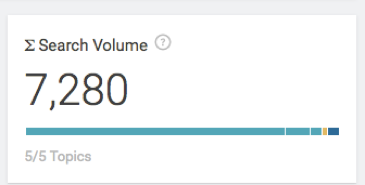
이제 작성을 시작할 수 있습니다.
애자일 콘텐츠 개발로 키워드 적용하기
작성할 준비가 되면 Searchmetrics Content Experience의 편집기 모듈 왼쪽에 표시되는 내용을 살펴보겠습니다. 글을 쓰기 전에 우리는 주로 어떤 키워드(기본적으로 하위 주제)에 대해 쓸 것인지, 검색 결과에서 좋은 순위를 매기기 위해 추천되는 빈도와 같은 몇 가지 매우 흥미로운 사실을 알게 될 것입니다.
이 기사 앞부분의 이러한 모든 콘텐츠 개념을 기억하십니까? 이러한 추천 키워드의 대부분이 어디에서 계산되는지 살펴보십시오.
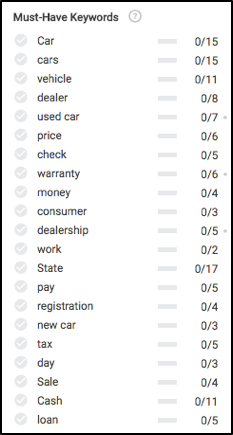
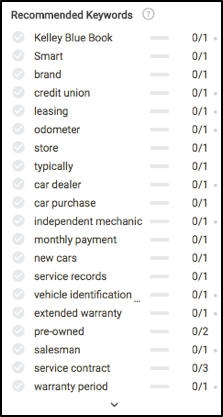
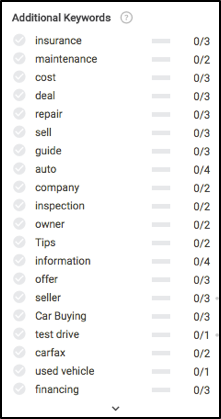
위의 데이터를 기반으로 콘텐츠가 완전히 관련성이 있는지 확인하기 위해 보험, 유지 관리, 테스트 드라이브 프로세스, 보증, 등록, 자금 조달 및 기타 몇 가지 사항에 대해 작성해야 합니다.
쓰기 시작하면 재미가 시작됩니다.

이 도구를 사용하여 데이터 기반 접근 방식을 사용하여 콘텐츠를 전체적으로 작성하고, 콘텐츠의 가독성과 구조화 정도를 평가하고, 콘솔에서 다른 사이트의 중복 콘텐츠로 인해 순위 문제가 발생할 수 있는 곳을 확인할 수도 있습니다.
좀 더 자세히 알아보고 데이터에 대해 알아보려면 TF*IDF 및 기타 데이터 기반 권장 사항을 분석해 보겠습니다.
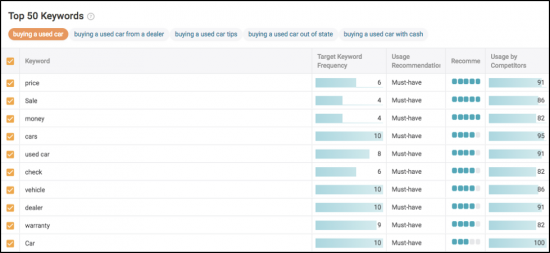
마지막으로 영향을 추적합니다. 5가지 핵심 주제를 모두 추적하여 순위, 트래픽 및 사용자 신호 측면에서 어느 것이 더 나은 실적을 보이는지 확인하십시오.
알림: 오래된 "게시하고 잊어버리십시오" 사고방식은 더 이상 없습니다. 콘텐츠가 항상 최적화되고 최신 상태인지 확인하려면 "게시하고 재활용"해야 합니다.
SEO의 비밀 풀기
시맨틱 콘텐츠 최적화의 기본을 이해하는 것이 중요합니다. 기술적인 사람이 될 필요는 없습니다. 데이터 과학자가 될 필요는 없습니다. 관심을 갖고 호기심을 갖기만 하면 됩니다. 의미론적으로 콘텐츠를 최적화하는 것의 가치를 이해하고 나면 데이터 중심 글쓰기가 더 재미있을 뿐만 아니라 훨씬 더 이해가 되기 시작할 것입니다.