
Découvrir les secrets du référencement : optimiser les sujets
Publié: 2017-03-14Dans notre dernier article de Unwrapping the Secrets of SEO, ma collègue Holly Miller a décrit les étapes à suivre pour choisir de bons sujets en ligne au bon moment et en bonne forme pour le référencement. Il est maintenant temps de vous assurer que les sujets sur lesquels vous écrivez seront optimisés aussi bien pour les utilisateurs que pour les moteurs de recherche. Il est temps de parler d'optimisation sémantique des sujets !

Introduction à l'optimisation de contenu
En tant que spécialiste du marketing en ligne, SEO ou rédacteur de contenu, votre objectif ultime est de vous assurer que tout ce que vous créez pour un public en ligne fonctionnera comme prévu. Cela pourrait prendre la forme de signaux d'utilisateurs, de classements plus élevés, de partages sociaux ou de conversions. L'objectif de l'optimisation du contenu est exactement cela : s'assurer que votre contenu se connecte aux moments importants lorsque les utilisateurs recherchent des informations via les moteurs de recherche. Pour cela, il doit être jugé le plus pertinent possible par les moteurs de recherche (et donc les utilisateurs) pour un sujet précis. En fin de compte, l'optimisation de votre contenu est mieux servie si vous comprenez que ce que vous essayez vraiment de faire est d'augmenter la pertinence du contenu plutôt que de l'optimiser.
Ce concept général d'augmentation de la pertinence du contenu est non seulement amusant à comprendre du point de vue d'un SEO, mais est également extrêmement utile pour aider les rédacteurs de contenu à comprendre quels sous-thèmes doivent être inclus dans les sujets.
Afin de faire pleinement confiance aux données qui nous aideront à accroître la pertinence de notre contenu, plongeons sous le capot pour voir comment Google comprend la pertinence du contenu.
Une brève histoire de la densité des mots-clés
Avant l'époque de l'intelligence artificielle, de l'apprentissage automatique et de tous ces algorithmes fantaisistes, Google évaluait la qualité des pages principalement en fonction de deux facteurs : les liens et la densité des mots clés. Pour les référenceurs comme moi, c'était en fait assez amusant. L'optimisation des moteurs de recherche dans les "vieux jours" d'il y a quelques années était beaucoup plus basée sur la tactique que sur la stratégie.
De nos jours, c'est un jeu de balle différent. Google et les autres moteurs de recherche sont devenus plus intelligents et ne jugent plus la pertinence en se basant simplement sur quelques liens ou quelques mots-clés sur la page.
OK, si vous n'optimisez pas un mot-clé en utilisant la densité des mots-clés, comment optimisez-vous un sujet ? Les deux concepts suivants peuvent sembler compliqués au premier abord, mais devraient être faciles à comprendre.
Indexation sémantique latente
Le premier est l'indexation sémantique latente, ou LSI. La façon dont Google utilise LSI est en fait assez simple. Une formule mathématique définit la proximité et la relation entre les termes d'un élément de contenu. Les moteurs de recherche explorent une page Web et, en fonction du titre ou du sujet principal de votre page Web, les mots et expressions les plus courants sont regroupés et identifiés comme mots-clés du sujet principal de la page. Si les termes trouvés par le moteur de recherche sur votre page sont des termes pertinents, il s'attendra à trouver des termes connexes tels que « automobiles », « d'occasion », « vente aux enchères », etc.
Pour la plupart d'entre vous, tout cela devrait sembler très familier. LSI est simplement une méthode basée sur la cooccurrence où les moteurs de recherche recherchent des termes qui apparaissent naturellement en conjonction avec d'autres termes. Voici plus d'informations sur LSI à partir d'un article que j'ai écrit il y a quelques mois.
Vers TF*IDF ou Non vers TF*IDF
Si vous cherchez à aller plus loin, TF*IDF, ou Term Frequency * Inverted Document Frequency, est la formule la plus avancée. Portent.com écrit ceci à propos de TF*IDF :
“..Ce n'est PAS OK de laisser de côté la mère de tous les algorithmes de récupération d'informations, TF-IDF, affectueusement connue des geeks de la recherche sous le nom de Term Frequency-Inverse Document Frequency.
Introduit dans les années 1970, cet algorithme de classement principal utilise la présence, le nombre d'occurrences et les lieux d'occurrence pour produire un poids statistique sur l'importance d'un terme particulier dans le document. Il comprend une fonction de normalisation pour empêcher les longs documents ennuyeux de s'installer dans les résultats de recherche en raison de la nature de cisaillement de leur circonférence.
Bien que vous puissiez voir que c'est un concept plus ancien, il reste toujours très pertinent. Semblable à LSI, TF*IDF examine des mots-clés spécifiques et essaie de comprendre la relation entre chacun. Cependant, il va plus loin en donnant une pondération spécifique à chaque terme.
Disons que vous essayez de comprendre quels mots et expressions sont pertinents pour le sujet des voitures d'occasion. Nous définirions la formule pour examiner les 20 premières pages de classement. TF*IDF fonctionnera de deux manières :
- TF (Term Frequency) : un robot d'exploration examinera chacun des mots sur chaque page Web et déterminera la fréquence des termes (densité des mots clés) de chacun de ces mots :

Ceci serait répété pour la page 2, la page 3, etc.
- IDF (Inverted Document Frequency) : le crawler examinera ensuite tous ces mots et identifiera dans combien de documents (sur les 20 analysés) ces mots sont présents.
- C'est répété pour la page 2, la page 3, etc…
- TF*IDF : Une fois ces deux items réunis, un simple logarithme est calculé et renvoie un score (poids) pour chaque terme analysé.
Automobile d'occasion : TF*IDF = 0,8
Automobile d'occasion : TF*IDF = 0,6
Ce qui rend cette méthode étonnante, c'est qu'elle élimine les conjectures pour essayer de comprendre quels mots et donc quels sujets doivent être utilisés en conjonction avec le sujet principal de votre texte. Vous êtes alors en mesure d'analyser quels mots-clés ont le plus de poids et sont donc plus importants pour le sujet sur lequel vous écrivez.
Et au fait, Google parle de TF*IDF dans quelques-uns de ses brevets de recherche :
- https://www.google.com/patents/US7711668
- https://www.google.com/patents/US20130346424
- https://www.google.com/patents/US7730061
Si vous ne pensiez pas qu'il était important de comprendre avant. J'espère que vous le faites maintenant.
Explorer les types d'entités
Parlons maintenant des types d'entités. Nous avons vu un exemple de la façon dont Google comprend les termes les plus importants pour un sujet spécifique ; Google comprend également la catégorisation des mots. Prenons cet article comme exemple. Le titre se lit comme suit "Trump menace les constructeurs automobiles allemands avec un droit d'importation américain de 35 %", donnant un bon aperçu de ce que vous auriez lu dans l'article. En bref, l'article indique que BMW, la marque Vauxhall de GM et d'autres sont mises en demeure par le président Trump de produire davantage aux États-Unis. Il cite Daimler et Renaul-Nissan pour avoir assemblé des produits à Agauscalientes, au Mexique, et les menace d'un tarif d'importation si ils n'investissent pas davantage dans la fabrication basée aux États-Unis. Ci-dessous, j'utilise l'outil de recherche d'entités d'IBM Watson pour voir comment un algorithme d'apprentissage automatique définit la pertinence du contenu et comment chaque mot est classé dans un type d'entité spécifique :





Voici une ressource supplémentaire concernant la manière dont Google regroupe les entités :

http://searchengineland.com/google-patent-question-answering-using-entity-references-unstructured-data-267273
Qu'est-ce que ça veut dire? Les moteurs de recherche, en particulier ceux qui sont suffisamment intelligents pour utiliser l'apprentissage automatique, examinent CHAQUE mot de votre document texte, les pèsent et les classent. Pour battre la concurrence, vous devrez comprendre tous ces concepts et vous assurer que tout sur votre page est correctement optimisé.
Qualité du contenu vs structure du contenu
Maintenant que nous avons parlé de rendre notre contenu pertinent en termes de qualité, regardons comment notre contenu est pertinent en termes de structure.
Un énorme paradigme que de nombreux référenceurs (utilisés) se trompent consiste simplement à cracher du contenu (même bien optimisé) n'importe où sur la page et à espérer qu'il se classera (je parle de vous, en particulier dans le commerce électronique). Jetons un coup d'œil à deux éléments de contenu :
V ersion 1 :
« Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Cras venenatis mi eu urna tristique, id dictum ligula aliquet. Pellentesque non dignissime lion. Ut dignissim accumsan lectus, at maximus quam lobortis sit amet. Donec pharetra placerat mauris, sit amet molestie diam dictum ac. Vivamus quis ex quis arcu malesuada rhoncus vel eget ex. Sed eget tortor ut augue mattis aliquet in ac nunc. Vestibulum non arcu id quam egestas tristique. Suspendisse fringilla id risus nec dictum. Nunc finibus risus id odio vulputate, at pretium nisi ultricies. Integer imperdiet velit ligula, vitae pulvinar elit malesuada vitae.“
Variante 2 :
« Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Cras venenatis mi eu urna tristique, id dictum ligula aliquot :
- Pellentesque non dignissime lion. Ut dignissim accumsan lectus, at maximus quam lobortis sit amet. Donec pharetra placerat mauris, sit amet molestie diam dictum ac.
- Vivamus quis ex quis arcu malesuada rhoncus vel eget ex.
- Sed eget tortor ut augue mattis aliquet in ac nunc. Vestibulum non arcu id quam egestas tristique. Suspendisse fringilla id risus nec dictum.
Nunc finibus risus id odio vulputate, at pretium nisi ultricies. Integer imperdiet velit ligula, vitae pulvinar elit malesuada vitae.
La version 2 est meilleure, non ?
Ce n'est pas seulement quelque chose qui aidera les signaux globaux des utilisateurs (taux de rebond plus faible, temps plus long sur la page, ce qui, espérons-le, conduira à une augmentation du nombre de pages par session) - mais aidera les classements car les moteurs de recherche comprennent divers éléments CSS et donc comment une page est posée dehors.
Devenir réel avec ces concepts
Disons que votre sujet principal est « l'achat d'une voiture d'occasion » et que vous essayez de comprendre sur quels sous-sujets écrire : Dois-je parler du processus ? Des astuces? Acheter une voiture hors de l'état?
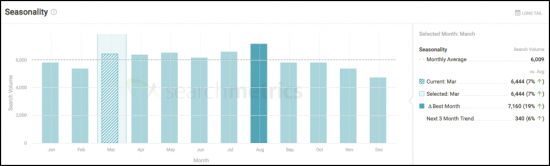
La première étape consiste à comprendre le marché du mieux que vous pouvez à un moment donné. Grâce à la plate-forme de développement de contenu agile Searchmetrics Content Experience, nous sommes en mesure d'identifier rapidement quelques éléments de haut niveau, notamment le volume de recherche, la saisonnalité, les mots clés similaires et les intégrations de recherche pour guider nos sujets :


La prochaine étape de l'expérience de contenu Searchmetrics consiste à travailler avec l'explorateur de sujets pour comprendre quels sujets résonnent sur le marché et pourquoi :
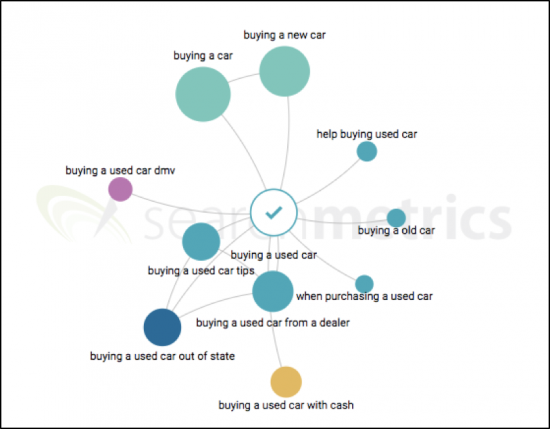
Grâce au graphique de sujets de Searchmetrics, nous sommes en mesure d'identifier rapidement les sujets principaux qui sont sémantiquement proches du sujet principal "l'achat d'une voiture d'occasion". Fait intéressant, nous remarquerons que de nombreuses personnes souhaitent savoir comment acheter une voiture d'occasion avec de l'argent, ou acheter une voiture d'occasion hors de l'État ou auprès d'un concessionnaire. Étant donné que notre analyse peut inclure jusqu'à cinq sujets principaux, nous inclurons ceux dont le volume de recherche est le plus élevé.
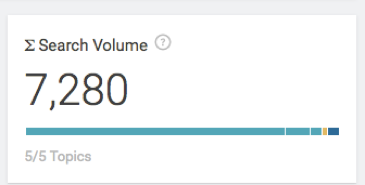
En sélectionnant quelques-uns de ces autres sujets, notre volume de recherche total passe à environ 7 000+
Ceci fait, nous pouvons commencer à écrire !
Application de mots-clés avec le développement de contenu agile
Une fois que nous sommes prêts à écrire, jetons un coup d'œil à ce que vous verriez à gauche dans le module d'édition de Searchmetrics Content Experience. Avant même d'écrire quoi que ce soit, nous remarquerons quelques choses très intéressantes, principalement sur quels mots clés (essentiellement des sous-thèmes) écrire, et la fréquence recommandée pour que chacun soit bien classé dans les résultats de recherche.
Vous souvenez-vous de tous ces concepts de contenu plus haut dans l'article ? Jetez un œil pour voir où la plupart de ces recommandations de mots clés sont calculées.
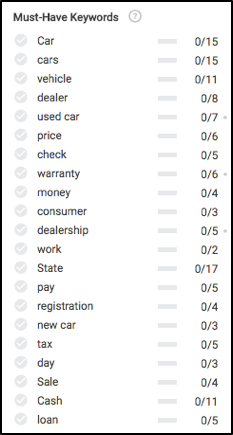
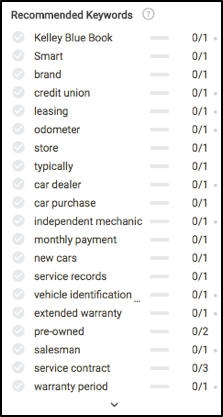
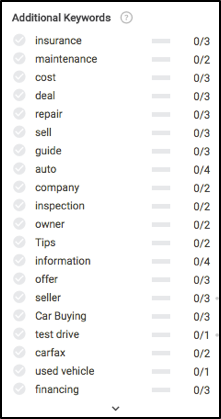
Sur la base des données ci-dessus, afin de nous assurer que notre contenu est pleinement pertinent, nous devons écrire sur l'assurance, la maintenance, le processus d'essai routier, la garantie, l'enregistrement, le financement et quelques autres.
Une fois que nous commençons à écrire, c'est là que le plaisir commence :

Je peux utiliser l'outil pour adopter une approche basée sur les données pour écrire du contenu de manière holistique, obtenir une note sur sa lisibilité et sa bonne structure et même voir dans la console où le contenu dupliqué d'autres sites pourrait me causer des problèmes de classement.
Si vous cherchez à en savoir un peu plus et à entrer dans les données, nous décomposerons TF * IDF et d'autres recommandations basées sur les données.
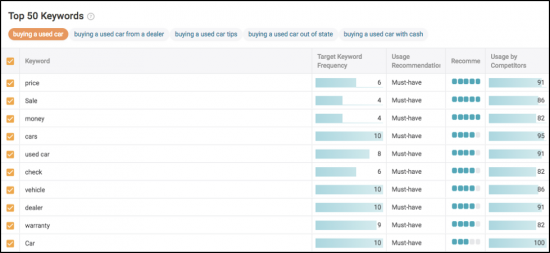
Enfin, vous suivez l'impact. Assurez-vous de suivre les 5 sujets principaux pour voir lequel fonctionne le mieux en termes de classement, de trafic et de signaux utilisateur.
Un rappel : la vieille mentalité « publier et oublier » n'est plus. Vous devez « publier et recycler » pour vous assurer que votre contenu est toujours optimisé et à jour.
Dévoiler les secrets du SEO
Comprendre les bases de l'optimisation de contenu sémantique est essentiel. Vous n'avez pas besoin d'être technique. Vous n'avez pas besoin d'être un data scientist. Il suffit d'être attentif et curieux. Une fois que vous aurez compris l'intérêt d'optimiser sémantiquement votre contenu, l'écriture centrée sur les données ne sera pas seulement plus amusante, mais commencera à avoir beaucoup plus de sens.