
SEOの秘密を解き明かす:トピックの最適化
公開: 2017-03-14Unwrapping the Secrets of SEOの前回の記事では、同僚のHolly Millerが、適切なタイミングで適切なSEOの形で優れたオンライントピックを選択するために採用する手順の概要を説明しました。 今度は、あなたが書いているトピックがユーザーと検索エンジンに対して等しく最適化されることを確認する時が来ました。 セマンティックトピックの最適化について話す時が来ました!

コンテンツ最適化の概要
オンラインマーケティング担当者、SEO、またはコンテンツライターとしての最終的な目標は、オンラインオーディエンス向けに作成したものがすべて期待どおりに機能することを確認することです。 これは、ユーザーシグナル、上位ランキング、ソーシャルシェア、またはコンバージョンの形で発生する可能性があります。 コンテンツの最適化の目標はまさにそれです。ユーザーが検索エンジンを介して情報を探しているときに重要な瞬間にコンテンツが確実につながるようにすることです。 そのためには、検索エンジン(したがってユーザー)が特定のトピックに可能な限り関連性があると見なす必要があります。 最終的に、コンテンツを最適化することは、コンテンツを最適化するのではなく、コンテンツの関連性を高めることであるということを理解することで、より効果的に機能します。
コンテンツの関連性を高めるというこの一般的な概念は、SEOの観点から見るのが楽しいだけでなく、コンテンツ作成者がトピックに含めるべきサブトピックを理解するのに非常に役立ちます。
コンテンツの関連性を高めるのに役立つデータを完全に信頼するために、Googleがコンテンツの関連性をどのように理解しているかを確認するために内部を調べてみましょう。
キーワード密度の簡単な歴史
人工知能、機械学習、その他すべての高度なアルゴリズムが登場する前は、Googleは主にリンクとキーワード密度の2つの要素に基づいてページの品質を評価していました。 私のようなSEOにとって、これは実際にはとても楽しかったです。 数年前の「昔」の検索エンジン最適化は、戦略ベースよりも戦術ベースでした。
今日では、それは別のボールゲームです。 グーグルや他の検索エンジンはよりスマートになり、いくつかのリンクやいくつかのページ上のキーワードだけに基づいて関連性を判断することはなくなりました。
OK、キーワード密度を使用してキーワードを最適化していない場合、トピックをどのように最適化しますか? 次の2つの概念は、最初は複雑に見えるかもしれませんが、理解しやすいはずです。
潜在的なセマンティックインデックス
1つは、潜在的セマンティックインデックス(LSI)です。 GoogleがLSIを使用する方法は、実際には非常に単純です。 数式は、コンテンツ内の用語間の近接性と関係を定義します。 検索エンジンはウェブページをクロールし、ウェブページのタイトルまたはメイントピックに基づいて、最も一般的な単語やフレーズがグループ化され、ページのコアトピックキーワードとして識別されます。 あなたのページで検索エンジンが見つけた用語が関連する用語である場合、「自動車」、「中古品」、「オークション」などの関連する用語を見つけることが期待されます。
ほとんどの人にとって、これはすべて非常によく知られているように聞こえるはずです。 LSIは単に共起ベースの方法であり、検索エンジンは他の用語と組み合わせて自然に発生する用語を検索します。 数ヶ月前に書いた投稿からのLSIの詳細をご覧ください。
TF*IDFへまたはTF*IDFへではない
さらに深く掘り下げたい場合は、TF * IDF、または用語頻度*逆文書頻度がより高度な式です。 Portent.comは、TF*IDFについて次のように書いています。
「..すべての情報検索アルゴリズムの母であるTF-IDFを除外することはできません。これは、用語頻度-逆ドキュメント頻度としてオタクを検索することで愛情を込めて知られています。
1970年代に導入されたこの一次ランキングアルゴリズムは、存在、発生数、および発生場所を使用して、ドキュメント内の特定の用語の重要性に関する統計的重みを生成します。 これには、長い退屈なドキュメントがその周囲のせん断性のために検索結果に表示されないようにするための正規化機能が含まれています。」
古い概念であることがわかりますが、それでも非常に関連性があります。 LSIと同様に、TF * IDFは特定のキーワードを調べ、それぞれの関係を理解しようとします。 ただし、各用語に特定の重みを付けることで、さらに一歩進んでいます。
どの単語やフレーズが中古車のトピックに関連しているかを理解しようとしているとしましょう。 上位20ページを表示する式を設定します。 TF*IDFは2つの方法で機能します。
- TF(用語頻度):クローラーは、各Webページ上の各単語を調べて、それらの各単語の用語頻度(キーワード密度)を決定します。

これは、2ページ目、3ページ目などで繰り返されます。
- IDF(Inverted Document Frequency):次に、クローラーはこれらすべての単語を調べ、これらの単語が含まれているドキュメントの数(分析された20個のうち)を識別します。
- 2ページ目、3ページ目などで繰り返されます…
- TF * IDF:これら2つの項目を組み合わせると、単純な対数が計算され、分析された各用語のスコア(重み)が返されます。
中古自動車:TF * IDF = 0.8
中古自動車:TF * IDF = 0.6
この方法を驚くべきものにしているのは、実際には、どの単語を理解しようとするかという当て推量が不要であり、したがって、トピックをテキストのコアトピックと組み合わせて使用する必要があるということです。 次に、どのキーワードが最も重要であり、したがって、あなたが書いているトピックにとってより重要であるかを分析することができます。
ちなみに、Googleはいくつかの検索特許でTF*IDFについて語っています。
- https://www.google.com/patents/US7711668
- https://www.google.com/patents/US20130346424
- https://www.google.com/patents/US7730061
以前に理解することが重要だと思わなかった場合。 私はあなたが今やることを願っています。
エンティティタイプの詳細
それでは、エンティティタイプについて説明しましょう。 Googleが特定のトピックの最も重要な用語をどのように理解するかのサンプルを見てきました。 Googleは単語の分類も理解しています。 この記事を例として使用してみましょう。 見出しには、「トランプは米国の輸入関税の35%でドイツの自動車メーカーを脅かしている」と書かれており、この記事で読んだ内容の概要がわかりやすく説明されています。 簡単に言えば、記事によると、BMW、GMのVauxhallブランドなどは、米国でより多くの製品を生産するようにトランプ大統領から通知されています。彼らは米国を拠点とする製造業にこれ以上投資しません。 以下では、IBMのWatsonのエンティティ検索ツールを使用して、機械学習アルゴリズムがコンテンツの関連性を定義する方法と、各単語が特定のエンティティタイプに分類される方法を確認します。





Googleがエンティティをクラスター化する方法に関する追加のリソースは次のとおりです。
http://searchengineland.com/google-patent-question-answering-using-entity-references-unstructured-data-267273
これは何を意味するのでしょうか? 検索エンジン、特に機械学習を使用するのに十分賢い検索エンジンは、テキストドキュメント内のすべての単語を調べ、それらを比較検討して分類します。 競争に打ち勝つには、これらすべての概念を理解し、ページ上のすべてが適切に最適化されていることを確認する必要があります。
コンテンツの品質とコンテンツの構造
コンテンツを品質の観点から関連性のあるものにすることについて説明したので、コンテンツが構造の観点からどのように関連性があるかを見てみましょう。

多くのSEO(以前)が間違っている大きなパラダイムの1つは、ページの任意の場所にコンテンツを(十分に最適化されていても)吐き出し、ランク付けされることを期待することです(特に、eコマースでの失敗について話しています)。 2つのコンテンツを見てみましょう。
バージョン1 :
「Loremipsumdolorは、amet、consecteturadipiscingelitに座っています。
Cras venenatis mi eu urna tristique、id dictumligulaaliquet。 Pellentesque nondignissimleo。 Ut dignissim accumsan lectus、maximusquamlobortisで座っています。 Donec pharetra placerat mauris、amet molstie diamdictumacに座ります。 Vivamus quis ex quis arcu malesuada rhoncus velegetex。 sed eget tortor ut augue mattis aliquet inacnunc。 Vestibulum non arcu id quamegestastristique。 Suspendisse fringilla id risusnecdictum。 Nunc finibus risus id odio vulputate、pretiumnisiultriciesで。 整数の履歴書、履歴書、履歴書、履歴書。」
バージョン2 :
「Loremipsumdolorは、amet、consecteturadipiscingelitに座っています。
Cras venenatis mi eu urna tristique、id dictum ligula aliquot:
- Pellentesque nondignissimleo。 Ut dignissim accumsan lectus、maximusquamlobortisで座っています。 Donec pharetra placerat mauris、amet molstie diamdictumacに座ります。
- Vivamus quis ex quis arcu malesuada rhoncus velegetex。
- sed eget tortor ut augue mattis aliquet inacnunc。 Vestibulum non arcu id quamegestastristique。 Suspendisse fringilla id risusnecdictum。
Nunc finibus risus id odio vulputate、pretiumnisiultriciesで。 整数の履歴書、履歴書、履歴書、履歴書。」
バージョン2の方が見栄えがいいですよね?
これは、全体的なユーザーシグナル(バウンス率の低下、ページ滞在時間の延長、セッションあたりのページ数の増加につながることを願っています)に役立つだけでなく、検索エンジンがさまざまなCSS要素を理解し、ページがどのように配置されるかを理解するのに役立ちます。アウト。
これらの概念を実現する
あなたのコアトピックが「中古車の購入」であり、どのサブトピックについて書くべきかを理解しようとしているとしましょう。プロセスについて話すべきですか? チップ? 州外の車を購入しますか?
最初のステップは、いつでも可能な限り市場を理解することです。 Searchmetrics Content Experienceのアジャイルコンテンツ開発プラットフォームを使用して、検索ボリューム、季節性、類似のキーワード、トピックをガイドする検索統合など、いくつかの高レベルのアイテムをすばやく特定できます。

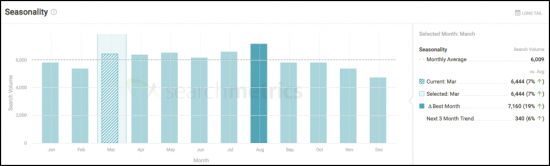

Searchmetrics Content Experienceの次のステップは、トピックエクスプローラーと連携して、市場で共鳴しているトピックとその理由を理解することです。
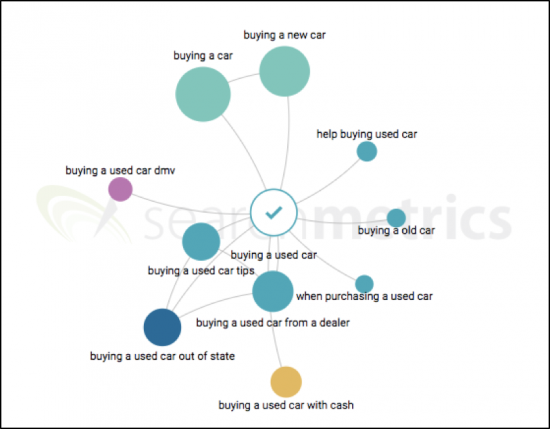
Searchmetricsトピックグラフのおかげで、「中古車の購入」というメイントピックに意味的に近いコアトピックをすばやく特定できます。 興味深いことに、多くの人が中古車を現金で購入する方法、州外またはディーラーから中古車を購入する方法を知りたいと思っていることに気付くでしょう。 分析には最大5つのコアトピックを含めることができるため、検索ボリュームの多いトピックを含めます。
これらの他のトピックのいくつかを選択することにより、検索ボリュームの合計は約7,000以上に増加します
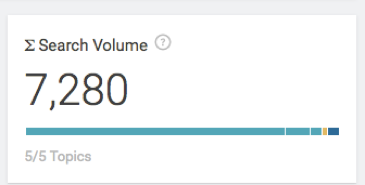
これで、書き始めることができます。
アジャイルコンテンツ開発でのキーワードの適用
書く準備ができたら、SearchmetricsContentExperienceのエディターモジュールの左側に表示される内容を見てみましょう。 何かを書く前に、いくつかの非常に興味深いことに気付くでしょう。主に、どのキーワード(基本的にサブトピック)について書くか、そしてそれぞれが検索結果で上位にランク付けするために推奨される頻度です。
記事の前半でこれらすべてのコンテンツの概念を覚えていますか? これらのキーワードの推奨事項のほとんどがどこで計算されているかを確認してください。
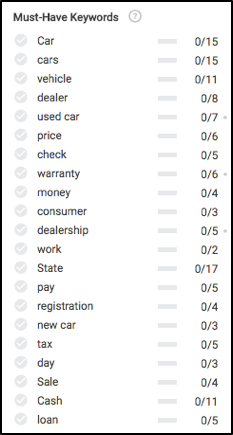
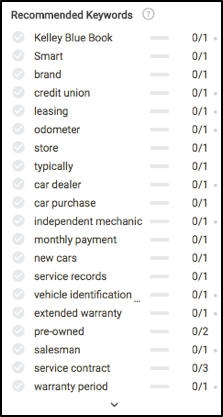
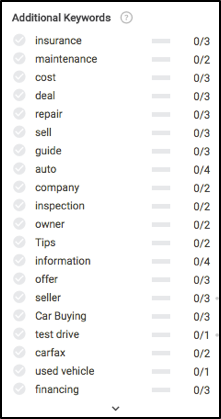
上記のデータに基づいて、コンテンツが完全に関連していることを確認するために、保険、メンテナンス、試乗プロセス、保証、登録、資金調達などについて書く必要があります。
書き始めると、ここから楽しみが始まります。

このツールを使用して、コンテンツを全体的に書き込むためのデータ駆動型アプローチを採用し、コンテンツがどれほど読みやすく、適切に構造化されているかを評価し、他のサイトからの重複コンテンツがランキングで問題を引き起こす可能性がある場所をコンソールで確認することもできます。
もう少し詳しく調べてデータを調べたい場合は、TF*IDFおよびその他のデータ駆動型の推奨事項を分析します。
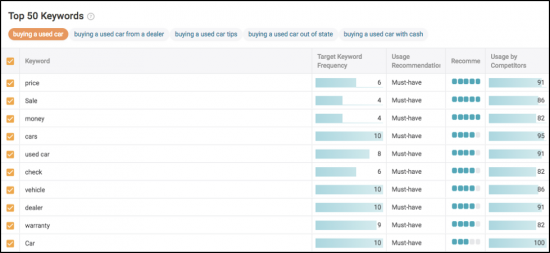
最後に、影響を追跡します。 5つのコアトピックすべてを追跡して、ランキング、トラフィック、ユーザーシグナルの観点からどれが優れているかを確認してください。
注意:古い「公開して忘れる」という考え方はもはやありません。 コンテンツが常に最適化され、最新であることを確認するには、「公開してリサイクル」する必要があります。
SEOの秘密を解き明かす
セマンティックコンテンツの最適化の基本を理解することは非常に重要です。 技術的である必要はありません。 データサイエンティストである必要はありません。 あなたは単に注意を払い、好奇心をそそる必要があります。 コンテンツをセマンティックに最適化することの価値を理解すると、データ中心の書き込みがより楽しくなるだけでなく、はるかに理にかなっているようになります。