
Membuka Rahasia SEO: Mengoptimalkan Topik
Diterbitkan: 2017-03-14Dalam angsuran terakhir kami dari Membongkar Rahasia SEO, kolega saya Holly Miller menguraikan langkah-langkah untuk digunakan dalam memilih topik online yang baik pada waktu yang tepat, dan dalam kondisi SEO yang baik. Sekarang saatnya untuk memastikan bahwa topik yang Anda tulis akan dioptimalkan dengan baik untuk pengguna dan mesin telusur. Saatnya berbicara tentang pengoptimalan topik semantik!

Pengantar Pengoptimalan Konten
Sebagai pemasar online, SEO, atau penulis konten, tujuan akhir Anda adalah memastikan apa pun yang Anda buat untuk audiens online akan berkinerja seperti yang diharapkan. Itu bisa datang dalam bentuk sinyal pengguna, peringkat yang lebih tinggi, pembagian sosial – atau konversi. Tujuan pengoptimalan konten adalah persis seperti itu – untuk memastikan konten Anda terhubung pada saat-saat penting ketika pengguna mencari informasi melalui mesin telusur. Agar itu terjadi, itu perlu dianggap serelevan mungkin oleh mesin pencari (dan dengan demikian pengguna) untuk topik tertentu. Pada akhirnya, mengoptimalkan konten Anda lebih baik dilayani dengan memahami bahwa apa yang sebenarnya Anda coba lakukan adalah meningkatkan relevansi konten daripada mengoptimalkannya.
Konsep umum tentang peningkatan relevansi konten ini adalah sesuatu yang tidak hanya menyenangkan untuk dipelajari dari sudut pandang SEO, tetapi juga sangat berguna untuk membantu penulis konten memahami subtopik mana yang harus disertakan dalam topik.
Untuk sepenuhnya memercayai data yang akan membantu kami meningkatkan relevansi konten, mari selami di bawah tenda untuk melihat bagaimana Google memahami relevansi dalam konten.
Sejarah Singkat Kepadatan Kata Kunci
Sebelum hari-hari kecerdasan buatan, pembelajaran mesin, dan semua algoritme mewah itu, Google menilai kualitas halaman terutama berdasarkan dua faktor: tautan dan kepadatan kata kunci. Untuk SEO seperti saya, ini sebenarnya cukup menyenangkan. Optimisasi mesin pencari di "masa lalu" beberapa tahun yang lalu dulunya jauh lebih berbasis taktik daripada berbasis strategi.
Saat ini, ini adalah permainan bola yang berbeda. Google dan mesin pencari lainnya menjadi lebih pintar dan tidak lagi menilai relevansi hanya berdasarkan beberapa tautan atau beberapa kata kunci di halaman.
Oke, jika Anda tidak mengoptimalkan kata kunci menggunakan kepadatan kata kunci, bagaimana Anda mengoptimalkan topik? Dua konsep berikutnya mungkin tampak rumit pada awalnya, tetapi seharusnya mudah dipahami.
Pengindeksan Semantik Laten
Yang pertama adalah Latent Semantic Indexing, atau LSI. Cara Google menggunakan LSI sebenarnya cukup sederhana. Rumus matematika mendefinisikan kedekatan dan hubungan antara istilah dalam sepotong konten. Mesin pencari akan merayapi halaman web dan, berdasarkan judul halaman web atau topik utama Anda, kata dan frasa yang paling umum dikelompokkan dan diidentifikasi sebagai kata kunci topik inti halaman. Jika istilah yang ditemukan mesin telusur di halaman Anda adalah istilah yang relevan, ia akan berharap menemukan istilah terkait seperti "mobil", "bekas", "lelang", dll.
Bagi sebagian besar dari Anda, semua ini pasti terdengar sangat familiar. LSI hanyalah metode berbasis kejadian bersama di mana mesin pencari mencari istilah yang secara alami muncul bersamaan dengan istilah lain. Berikut info lebih lanjut tentang LSI dari posting yang saya tulis beberapa bulan yang lalu.
Ke TF*IDF atau Tidak ke TF*IDF
Jika Anda ingin masuk lebih dalam, TF*IDF, atau Frekuensi Term * Frekuensi Dokumen Terbalik, adalah rumus yang lebih canggih. Portent.com menulis ini tentang TF*IDF:
“..TIDAK OK untuk mengabaikan induk dari semua algoritme pencarian informasi, TF-IDF, yang dikenal dengan istilah search geeks sebagai Frekuensi Term-Inverse Document Frequency.
Diperkenalkan pada 1970-an, algoritme peringkat utama ini menggunakan kehadiran, jumlah kemunculan, dan lokasi kemunculan untuk menghasilkan bobot statistik tentang pentingnya istilah tertentu dalam dokumen. Ini termasuk fitur normalisasi untuk mencegah dokumen lama yang membosankan dari mengambil tempat di hasil pencarian karena sifat geser ketebalannya.
Meskipun Anda dapat melihatnya sebagai konsep yang lebih tua, itu masih sangat relevan. Mirip dengan LSI, TF*IDF melihat kata kunci tertentu dan mencoba memahami hubungan di antara masing-masing kata kunci tersebut. Namun, ini melangkah lebih jauh dengan memberikan bobot khusus untuk setiap istilah.
Katakanlah Anda mencoba memahami kata dan frasa mana yang relevan dengan topik mobil bekas. Kami telah menetapkan formula untuk melihat 20 halaman peringkat teratas. TF*IDF akan bekerja dengan dua cara:
- TF (Frekuensi Term): crawler akan melihat setiap kata pada setiap halaman web dan menentukan frekuensi istilah (kepadatan kata kunci) dari masing-masing kata tersebut:

Ini akan diulang untuk halaman 2, halaman 3, dll.
- IDF (Frekuensi Dokumen Terbalik): Perayap kemudian akan melihat semua kata ini dan mengidentifikasi berapa banyak dokumen (dari 20 yang dianalisis) kata-kata ini ada.
- Ini diulang untuk halaman 2, halaman 3, dll…
- TF*IDF: Setelah kedua item ini disatukan, logaritma sederhana dihitung dan mengembalikan skor (bobot) untuk setiap istilah yang dianalisis.
Mobil bekas: TF*IDF = 0.8
Mobil bekas: TF*IDF = 0.6
Apa yang membuat metode ini luar biasa adalah bahwa metode ini benar-benar menghilangkan tebakan untuk mencoba memahami kata-kata dan topik mana yang harus digunakan dalam hubungannya dengan topik inti teks Anda. Anda kemudian dapat menganalisis kata kunci mana yang paling berbobot dan karena itu lebih penting untuk topik yang Anda tulis.
Dan omong-omong – Google berbicara tentang TF*IDF dalam beberapa paten pencariannya:
- https://www.google.com/patents/US7711668
- https://www.google.com/patents/US20130346424
- https://www.google.com/patents/US7730061
Jika Anda tidak berpikir itu penting untuk dipahami sebelumnya. Saya harap Anda melakukannya sekarang.
Menyelidiki Jenis Entitas
Sekarang mari kita bicara tentang tipe entitas. Kami telah melihat contoh bagaimana Google memahami istilah yang paling penting untuk topik tertentu ; Google juga memahami kategorisasi kata. Mari kita gunakan artikel ini sebagai contoh. Judulnya berbunyi "Trump mengancam pembuat mobil Jerman dengan tarif impor AS 35 persen," memberikan gambaran yang baik tentang apa yang Anda baca di artikel itu. Singkatnya, artikel itu mengatakan BMW, merek Vauxhall GM dan lainnya sedang diberitahu oleh Presiden Trump untuk memproduksi lebih banyak di AS. Dia mengutip Daimler dan Renaul-Nissan untuk merakit produk di Agauscalientes, Meksiko, dan mengancam mereka dengan tarif impor jika mereka tidak berinvestasi lebih banyak dalam manufaktur yang berbasis di AS. Di bawah ini, saya menggunakan alat pencarian entitas dari IBM Watson untuk melihat bagaimana algoritme pembelajaran mesin mendefinisikan relevansi konten dan bagaimana setiap kata diklasifikasikan ke dalam jenis entitas tertentu:





Berikut adalah referensi tambahan tentang cara Google mengelompokkan entitas:

http://searchengineland.com/google-patent-question-answering-using-entity-references-unstructured-data-267273
Apa artinya ini? Mesin pencari, terutama yang cukup pintar untuk menggunakan pembelajaran mesin, melihat SETIAP kata dalam dokumen teks Anda, dan akan menimbang dan mengklasifikasikannya. Untuk memenangkan persaingan, Anda harus memahami semua konsep ini dan memastikan semua yang ada di halaman Anda dioptimalkan dengan benar.
Kualitas Konten vs. Struktur Konten
Sekarang kita telah berbicara tentang membuat konten kita relevan dalam hal kualitas, mari kita lihat bagaimana konten kita relevan dalam hal struktur.
Salah satu paradigma besar yang banyak SEO (dulu) salah adalah hanya memuntahkan konten (bahkan dioptimalkan dengan baik) di mana saja di halaman dan berharap itu akan memberi peringkat (saya sedang berbicara tentang Anda gagal terutama di e-commerce). Mari kita lihat dua bagian konten:
Versi 1 :
“Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Cras venenatis mi eu urna tristique, id dictum ligula aliquet. Pellentesque non dignissim leo. Ut dignissim accumsan lectus, at maximus quam lobortis sit amet. Donec pharetra placerat mauris, sit amet molestie diam dictum ac. Vivamus quis ex quis arcu malesuada rhoncus vel eget ex. Sed eget tortor ut augue mattis aliquet in ac nunc. Vestibulum non arcu id quam egestas tristique. Suspendisse fringilla id risus nec dictum. Nunc finibus risus id odio vulputate, di pretium nisi ultricies. Integer imperdiet velit ligula, vitae pulvinar elit malesuada vitae.”
Versi 2 :
“Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Cras venenatis mi eu urna tristique, id dictum ligula aliquot:
- Pellentesque non dignissim leo. Ut dignissim accumsan lectus, at maximus quam lobortis sit amet. Donec pharetra placerat mauris, sit amet molestie diam dictum ac.
- Vivamus quis ex quis arcu malesuada rhoncus vel eget ex.
- Sed eget tortor ut augue mattis aliquet in ac nunc. Vestibulum non arcu id quam egestas tristique. Suspendisse fringilla id risus nec dictum.
Nunc finibus risus id odio vulputate, di pretium nisi ultricies. Integer imperdiet velit ligula, vitae pulvinar elit malesuada vitae.”
Versi 2 terlihat lebih baik, bukan?
Ini bukan hanya sesuatu yang akan membantu sinyal pengguna secara keseluruhan (rasio pentalan yang lebih rendah, waktu yang lebih tinggi di halaman, yang diharapkan akan mengarah pada peningkatan halaman per sesi) – tetapi akan membantu peringkat karena mesin pencari memahami berbagai elemen CSS dan oleh karena itu bagaimana halaman diletakkan keluar.
Menjadi Nyata dengan Konsep Ini
Katakanlah topik inti Anda adalah "membeli mobil bekas" dan Anda mencoba memahami subtopik mana yang harus ditulis: Haruskah saya membicarakan prosesnya? Tips? Membeli mobil luar negeri?
Langkah pertama adalah memahami pasar sebaik mungkin pada saat tertentu. Dengan menggunakan platform pengembangan konten tangkas Searchmetrics Content Experience, kami dapat dengan cepat mengidentifikasi beberapa item tingkat tinggi, termasuk volume pencarian, musim, kata kunci serupa & integrasi pencarian untuk memandu topik kami:

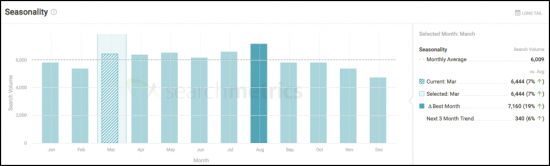

Langkah selanjutnya dalam Pengalaman Konten Searchmetrics bekerja dengan Topic Explorer untuk memahami topik mana yang beresonansi di pasar, dan mengapa:
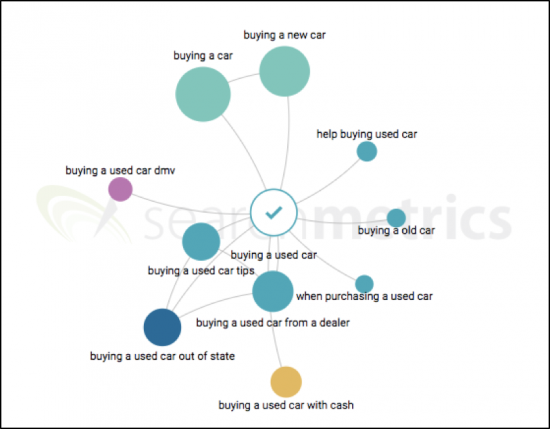
Berkat grafik topik Searchmetrics, kami dapat dengan cepat mengidentifikasi topik inti yang secara semantis dekat dengan topik utama "membeli mobil bekas". Menariknya, kita akan melihat bahwa banyak orang tertarik untuk mengetahui cara membeli mobil bekas secara tunai, atau membeli mobil bekas di luar negeri, atau dari dealer. Karena analisis kami dapat mencakup hingga lima topik inti, kami akan menyertakan topik dengan volume penelusuran yang lebih tinggi.
Dengan memilih beberapa topik lain ini, total volume pencarian kami meningkat menjadi sekitar 7.000+
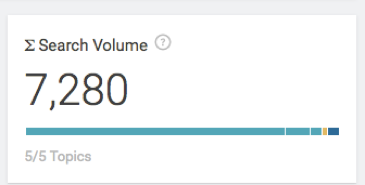
Selesai, kita bisa mulai menulis!
Menerapkan Kata Kunci dengan Pengembangan Konten Agile
Setelah kita siap untuk menulis, mari kita lihat apa yang akan Anda lihat di sebelah kiri dalam modul editor Pengalaman Konten Searchmetrics. Bahkan sebelum menulis apa pun, kita akan melihat beberapa hal yang sangat menarik, terutama kata kunci mana (pada dasarnya subtopik) untuk ditulis, dan frekuensi yang direkomendasikan untuk masing-masing kata kunci agar mendapat peringkat yang baik dalam hasil pencarian.
Ingat semua konsep konten ini sebelumnya di artikel? Lihat untuk melihat di mana sebagian besar rekomendasi kata kunci ini dihitung.
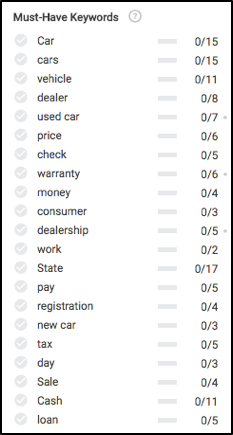
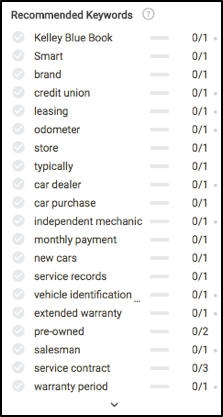
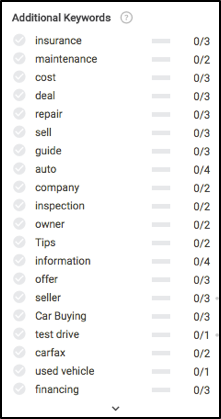
Berdasarkan data di atas, untuk memastikan konten kami sepenuhnya relevan, kami perlu menulis tentang asuransi, perawatan, proses test drive, garansi, pendaftaran, pembiayaan, dan beberapa lainnya.
Begitu kita mulai menulis, di sinilah kesenangan dimulai:

Saya dapat menggunakan alat ini untuk mengambil pendekatan berbasis data untuk menulis konten secara holistik, mendapatkan skor tentang seberapa mudah dibaca dan terstruktur dengan baik dan bahkan melihat di konsol di mana konten duplikat dari situs lain dapat menyebabkan masalah peringkat bagi saya.
Jika Anda ingin mengetahui sedikit lebih banyak dan masuk ke dalam data, kami akan memecah TF*IDF dan rekomendasi berbasis data lainnya.
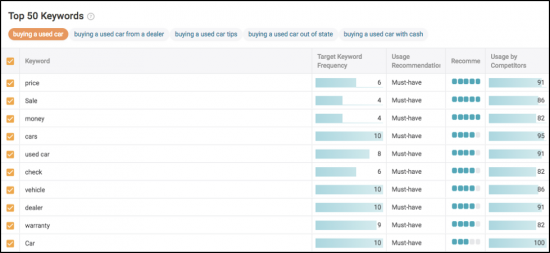
Akhirnya, Anda melacak dampak. Pastikan Anda melacak semua 5 topik inti untuk melihat mana yang berkinerja lebih baik dalam hal peringkat, lalu lintas, dan sinyal pengguna.
Sebuah pengingat: mentalitas lama "terbitkan dan lupakan" tidak ada lagi. Anda harus “memublikasikan dan mendaur ulang” untuk memastikan konten Anda selalu dioptimalkan dan diperbarui.
Membuka bungkus Rahasia SEO
Memahami dasar-dasar pengoptimalan konten semantik sangat penting. Anda tidak perlu menjadi teknis. Anda tidak perlu menjadi ilmuwan data. Anda hanya perlu memperhatikan dan penasaran. Setelah Anda memahami nilai dari mengoptimalkan konten Anda secara semantik, penulisan data-centric tidak hanya akan lebih menyenangkan, tetapi juga akan mulai lebih masuk akal.