
Yandex 소스 코드 유출로 검색 엔진에 대해 밝혀진 것
게시 됨: 2023-02-17Google, Bing, Yahoo와 같은 거대 검색 엔진 내부에 무엇이 들어가는지 궁금한 적이 있습니까?
2023년 1월 27일, 세계에서 네 번째로 큰 검색 엔진인 Yandex가 대규모(정확히 44GB) 데이터 유출 이후 최고의 헤드라인을 장식했습니다.
“그래서 러시아에서 가장 인기 있는 검색 엔진이 침해를 당했습니다. 나와 어떤 관련이 있습니까?” 물어볼 수 있습니다.
많은 뉴스 채널이 회사와 고객 데이터 보안에 대한 악의적인 행위로 일축한 것을 디지털 전문가들은 검색 엔진 작동 방식에 대한 보기 드문 통찰력으로 평가했습니다.
그리고 더 중요한 것은 그들이 어떤 콘텐츠를 우선시하고 그 이유는 무엇인지입니다.
데이터 유출로 우리가 처음에 1,922개의 순위 요소라고 생각했던 것이 공개되었지만 Ben Wills 덕분에 그 수가 17,853개로 수정되었습니다. 엄청나죠?
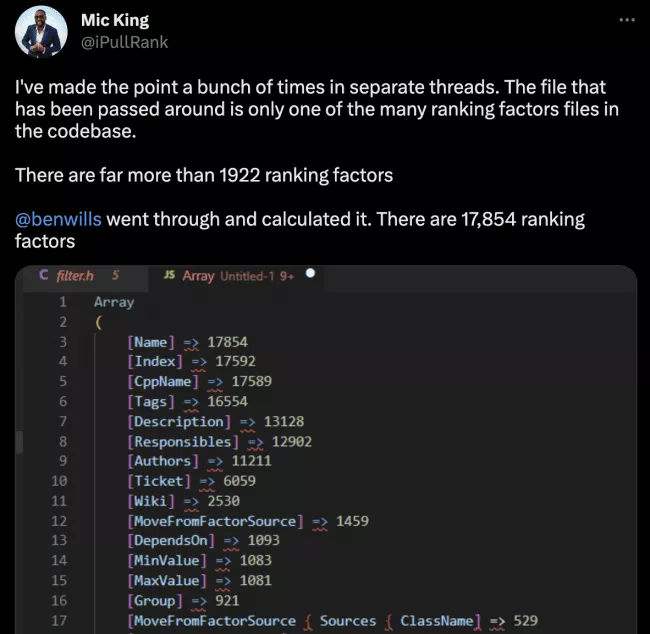
우리는 1,992개를 모두 통과했습니다.
가장 흥미로운 내용을 보려면 계속 읽어보세요.
Yandex 유출에서 얻은 정보를 사용하여 Google에서 더 높은 순위를 차지할 수 있습니까?
Yandex가 Google이 아니라는 것은 말할 필요도 없습니다.
그러나 다음과 같은 몇 가지 주목할만한 요인으로 인해 러시아 외부 및 검색 순위 실험 내부에서 이 유출이 관련성 있고 교육적입니다.
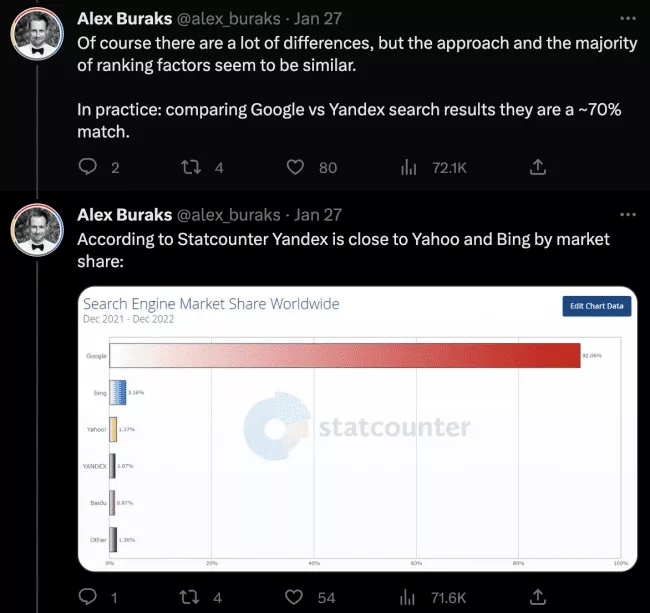
- Yandex와 Google 검색 결과는 ~70% 일치합니다.
- Yandex는 PageRank를 사용합니다(Google의 것과 거의 동일).
- Yandex는 많은 전직 Google 직원을 고용하고 있으며 많은 사람들은 Yandex가 유사한 방식으로 설계되었다고 추측합니다.
- Yandex는 반전 색인 또는 임베딩과 같이 Google과 유사한 정보 검색 모범 사례를 따릅니다.
- Google 및 Bing 검색 엔진과 마찬가지로 Yandex는 Okapi BM25 순위 기능을 사용하여 주어진 검색 쿼리에 대한 문서의 관련성을 추정합니다.
즉, Yandex 소스 코드 유출로 밝혀진 내용은 처음으로 검색 순위가 작동하는 방식을 가정하는 것과 아는 것 사이를 더 잘 구분하는 데 도움이 됩니다.
Yandex 코드 유출 내부: 검색 엔진 작동 방식에 대한 11가지 발견
일반적으로 Yandex 순위 요소는 세 가지 범주로 나눌 수 있습니다.
- 인바운드 백링크, 인바운드 내부 링크, 헤더, 광고 비율 등과 같은 정적 요소 는 웹사이트와 관련이 있습니다.
- 텍스트 관련성, 키워드 포함 등과 같은 동적 요인. 이는 웹사이트 및 검색어와 관련이 있습니다.
- 사용자의 위치, 쿼리 언어, 의도 수정자 등과 같은 사용자 검색 관련 요소 는 사용자 쿼리와 직접적으로 관련됩니다.
통계 모델에 사용되는 가장 큰 가중치는 다음과 같습니다.
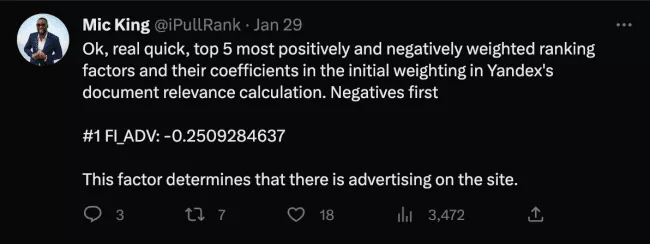
1. 온페이지 광고
페이지의 광고는 부정적인 요소로 간주됩니다. 사실상 가장 높은 음의 순위 가중치를 가진 요소입니다.
페이지의 광고 배치 수 및 배경을 클릭할 수 있는 경우와 같은 여러 광고 관련 요인은 Yandex가 보이는 화면에 대한 광고 비율이 높은 페이지를 좋아하지 않는다는 것을 암시합니다.
2. URL 수준 요인
URL 구성은 Yandex가 고려하는 또 다른 요소입니다. 그리고 더 구체적으로:
- URL에 숫자가 있음.
- URL의 후행 슬래시("/") 수
- URL의 대문자 수
Yandex가 Google이 아니며 이 유출이 가치가 없다는 주장으로 돌아가서 이러한 URL 요소는 Google의 URL 구조 가이드라인의 요소와 매우 유사합니다.
3. 페이지 수준 요인
여기서 펼쳐야 할 것이 많습니다. 결과적으로 Yandex에는 SERP 구축에 역할을 하는 수많은 페이지 수준 요소가 있습니다. 가장 주목할만한 것 중 일부는 다음과 같습니다.
- 페이지 신선도 - 특히 블로그 콘텐츠 및 뉴스 웹사이트의 경우. 콘텐츠 페이지가 10년 이상 된 경우 부정적인 순위 요소입니다. 따라서 콘텐츠를 자주 업데이트하십시오.
- 최종 목적지 - 사용자의 검색 여정을 종료하는 Yandex 보상 페이지, 즉 사용자가 찾고 있는 것을 찾았다는 의미입니다.
- 건전한 트래픽 소스 비율 - Yandex는 단일 소스(예: 자연 검색)에서 트래픽을 받는 페이지를 좋아하지 않습니다. 페이지 순위를 높이려면 유기적, 유료, 직접 등 모든 종류의 소스에서 트래픽을 가져와야 합니다.
- 콘텐츠 품질 - 텍스트가 독창적이고 키워드로 채워지지 않는 것이 중요합니다. 텍스트가 외부 도메인에서 인용/링크된 경우 순위가 상승합니다. 또한 품질이 좋지 않은 콘텐츠는 양질의 콘텐츠의 순위를 떨어뜨립니다.
4. 웹사이트 수준 요인
페이지 신선도 요소를 기반으로 궁극적인 조합은 오랫동안 활성화되고 콘텐츠를 자주 업데이트하는 잘 구축된 웹 사이트를 보유하는 것입니다.
또한 Yandex는 클릭 가능성 관점에서 웹사이트의 전반적인 품질을 판단합니다. 즉, 사용자가 검색을 위해 URL을 얼마나 자주 클릭합니까?
또 다른 긍정적인 순위 요소는 도메인 이름입니다. Yandex는 .COM 도메인에 순위 향상을 제공합니다.
5. 페이지 품질
콘텐츠 품질에 대해서는 이미 논의했지만 전체 페이지 품질은 어떻습니까? Yandex는 다음과 같은 몇 가지 요소를 기반으로 페이지의 품질을 평가합니다.

- 방문 횟수
- 고유 방문자 수
- 페이지에서 보낸 시간
- 페이지에서 수행된 작업 수
6. 사용자 행동 및 참여
우리가 논의해야 할 유출로부터 몇 가지 흥미로운 사용자 행동 테이크아웃이 있었습니다.
핵심 요소는 호스트가 전체적으로 받는 클릭 수와 노출 수입니다. Yandex는 또한 페이지가 모바일 친화적인지 여부를 고려하고 세션 기간 및 페이지에 머문 시간을 포함하여 모바일 장치에서의 사용자 행동을 분석합니다. 또한 방문자가 같은 달에 웹사이트를 다시 방문하는 경우 이는 긍정적인 순위 요소입니다.
그러나 아마도 가장 매력적인 것은 다음과 같습니다.
사용자 리뷰가 있는 페이지는 검색 결과에서 우선 순위가 부여됩니다.
7. 호스트 순위 및 위치
Yandex는 사용자와 지리적으로 가까운 콘텐츠의 우선 순위를 지정하는 데 중점을 둡니다. 따라서 두 도메인 이름이 동일한 검색 쿼리를 놓고 경쟁할 때 사용자에게 더 가까운 도메인 이름이 순위 상승을 얻습니다.
기술 순위 요소 측면에서 클라이언트 오류 400개와 서버 오류 500개를 줄이면 SERP에서 앞서게 됩니다. 또한 Yandex는 크롤링 깊이에 많은 관심을 기울입니다. 그렇기 때문에 중요한 페이지가 홈 페이지에서 두 번 이상 클릭되지 않도록 해야 합니다.
8. 백링크 품질
Yandex는 웹사이트의 인기를 인위적으로 부풀리는 추천 체인 생성에 불이익을 주기 위해 다양한 조치를 취합니다.
그러한 측정 중 하나는 과도한 링크가 조작 동작을 나타낼 수 있으므로 하이퍼링크된 텍스트의 백분율을 분석하는 것입니다. 또한 사이트로 연결되는 링크의 품질을 고려하여 유료 또는 저품질 링크가 많은 사이트에 불이익을 줍니다.
링크 품질에 대해 말하자면 링크 품질에 직접적으로 기여하는 요소는 리디렉션 수와 링크 구성 방법입니다.
9. 검색 트래픽에 미치는 영향
Google과 유사하게, 좋은 SEO 관행을 통합한 웹사이트는 그렇지 않은 웹사이트보다 더 나은 성과를 냅니다. 쉽게 검색할 수 있다는 것은 Yandex에서 더 높은 순위를 달성할 수 있는 확실한 방법입니다.
당연히 검색 의도를 제공할 수 있는 페이지는 각 검색 쿼리의 리더입니다. 제목 태그와 본문 텍스트에 정확한 검색어가 포함된 페이지가 유리합니다. 또한 동의어 사용은 순위 상승으로 이어질 수 있는 또 다른 긍정적인 신호입니다.
10. 위키피디아 부스트
고품질 페이지에 대한 또 다른 강력한 신호는 Wikipedia에서 링크되어 있는지 여부입니다. Yandex는 Wikipedia에서 링크된 페이지를 선호하고 더 높은 순위를 매깁니다.
11. 동영상 콘텐츠
동영상 콘텐츠가 포함된 웹사이트에 우선순위가 부여됩니다. 그러나 문제가 있습니다. Yandex는 Yandex에서 호스팅하는 동영상이 있는 페이지의 순위를 더 높게 매깁니다(duh).
페이지의 동영상 콘텐츠를 평가할 때는 동영상의 전체 길이에 대한 평균 시청 시간이라는 표준 측정이 적용됩니다.
이 11가지 결과 모두 훌륭한 통찰력을 제공했지만 SEO 세계에서는 유출된 데이터가 가치가 있는지 여부에 대한 논쟁이 있었습니다.
SEO 세계에서 유출된 순위 요소에 대한 반응
노골적인 해고에서 심층 분석에 이르기까지 SEO는 Yandex 유출에 대해 엇갈린 의견을 표명했습니다.
Kevin Indig는 가장 일반적인 반대 의견을 요약하고 순위 요인의 중요성에 대해 많은 정보를 제공했습니다.

Kevin Indig의 "SEOs are underestimate The Yandex 유출" 기사의 스니펫
Ben Wills, Alex Buraks 및 Mic King과 같은 SEO 분야의 주목할만한 이름은 유출된 데이터를 해독하기 위해 소매를 걷어붙였습니다.
Ben Wills는 소스 코드를 이해하고 이벤트의 중요성을 파악하는 데 도움을 준 최초의 전문가 중 하나입니다(비록 그가 조금 늦게 Twitter 스레드를 열었음에도 불구하고).
거의 동시에 Rob Ousbey는 Yandex 코드용 탐색기 도구의 알파 버전을 공유했습니다.

Mic King은 소스 코드를 살펴보던 중 "이 코드에서 잠을 자지 마세요"라고 말하면서 라이브로 첫인상을 공유했습니다.
러시아의 SEO 포럼은 그다지 혼잡하지 않았으며 웹마스터는 서구 SEO 세계와 유사한 통찰력을 공유했습니다. 그러나 러시아 SEO 전문가인 댄 테일러(Dan Taylor)가 언급한 것처럼 Yandex가 제품과 서비스를 선호한다는 이야기도 많이 있었습니다.
결론
Yandex 소스 코드 유출로 인해 SEO 수행 방식이 변경됩니까?
아마 아닐 겁니다.
그러나 중요하지 않은 것으로 레이블을 지정하고 스크롤하여 지나치는 것은 큰 실수입니다.
분명히 Yandex와 Google 사이에는 많은 유사점이 있습니다. 따라서 이 유출은 더 많은 실험을 위한 훌륭한 출발점이 될 수 있으며 사용자 경험과 양질의 콘텐츠에 더욱 집중하도록 유도할 수 있습니다.
그러니 무릎을 꿇고 테스트를 시작하십시오.