
Yandex のソース コード リークが検索エンジンについて明らかにしたこと
公開: 2023-02-17Google、Bing、Yahoo などの巨大な検索エンジンの内部はどうなっているのか疑問に思ったことはありませんか?
2023 年 1 月 27 日、世界で 4 番目に大きい検索エンジンである Yandex が、大量 (正確には 44 GB) のデータ漏えいの後、トップの見出しに登場しました。
「つまり、ロシアで最も人気のある検索エンジンが侵害を受けました。 それは私にどのように関連していますか? あなたは尋ねるかもしれません。
多くのニュース チャンネルが会社と顧客のデータ セキュリティに対する悪意のある行為として手を振ったように、デジタルの専門家は、検索エンジンの動作に関するまれな洞察としてそれを評価しました。
さらに重要なのは、彼らが優先するコンテンツとその理由です。
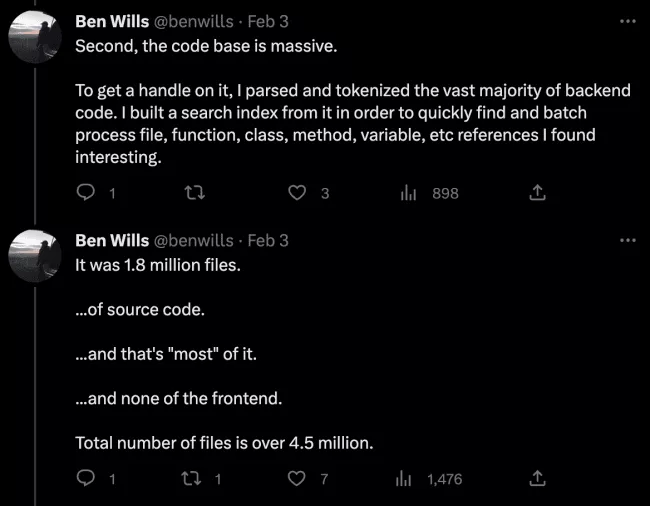
データ漏洩により、当初は 1,922 のランキング要素と考えられていたものが公開されましたが、Ben Wills のおかげで、その数は 17,853 に修正されました。 大規模ですよね?
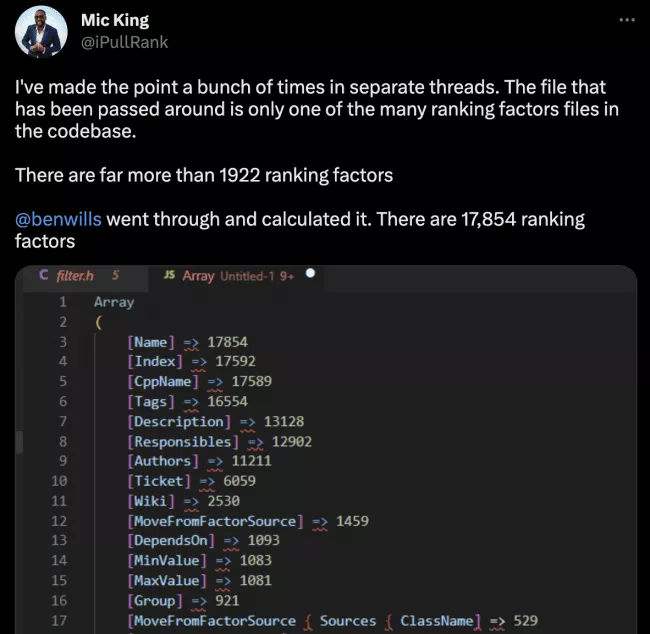
1,992 をすべて通過しました。
私たちが最も興味深いと思ったものを見るために読んでください。
Yandex のリークから学んだことを使用して、Google で上位にランク付けできますか?
Yandex が Google ではないことは言うまでもありません。
しかし、いくつかの注目すべき要因により、このリークはロシア外および検索ランキング実験内で関連性があり (そして教育的) あります。
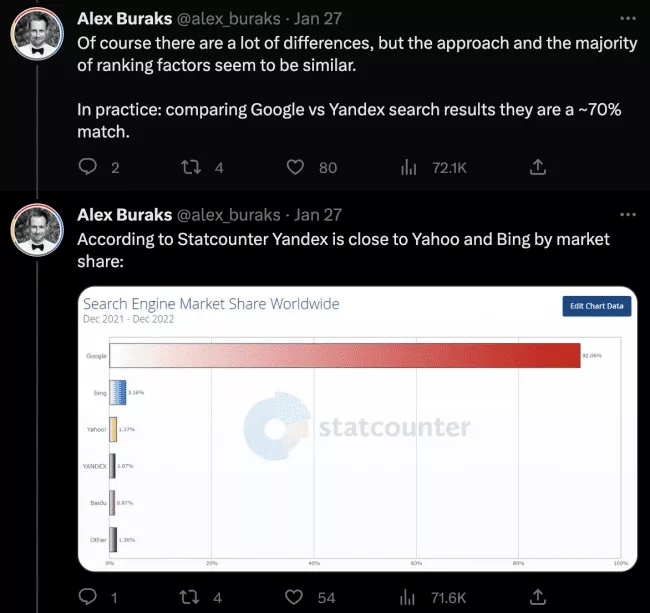
- Yandex と Google の検索結果の一致率は最大 70% です
- Yandex は PageRank を使用します (Google のものとほぼ同じです)。
- Yandex は多くの元 Google 社員を雇用しており、多くの人は同様の方法で設計されたと推測しています。
- Yandex は、反転インデックスや埋め込みなど、Google と同様の情報検索のベスト プラクティスに従います。
- Google や Bing の検索エンジンと同様に、Yandex は Okapi BM25 ランキング関数を使用して、特定の検索クエリに対するドキュメントの関連性を推定します。
そうは言っても、Yandex のソース コード リークが明らかにしたことは、検索ランキングがどのように機能するかを想定することと知ることを初めて区別するのに役立ちます。
Yandex コード リークの内部: 検索エンジンの動作に関する 11 の調査結果
一般に、Yandex のランキング要因は次の 3 つのカテゴリに分類できます。
- インバウンド バックリンク、インバウンド内部リンク、ヘッダー、広告比率などの静的要因。これらは Web サイトに関連しています。
- テキストの関連性、キーワードの包含などの動的要因。これらは、Web サイトと検索クエリの両方に関連しています。
- ユーザーの場所、クエリ言語、インテント修飾子などのユーザー検索関連の要因。これらはユーザー クエリに直接関係します。
統計モデルで使用される最大の重み付け要因は次のとおりです。
1. オンページ広告
ページ上の広告はマイナス要因と見なされます。 実際のところ、これは負のランキングの重みが最も高い要因です。
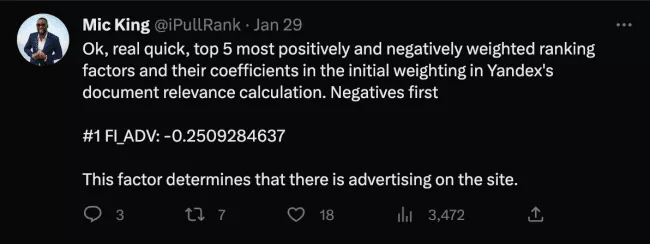
ページ上の広告の配置数や背景がクリック可能かどうかなど、広告に関連する複数の要因から、Yandex は表示画面に対する広告の比率が高いページを好まないことが示唆されます。
2. URL レベルの要因
URL の構造は、Yandex が考慮に入れるもう 1 つの要素です。 より具体的には:
- URL 内の数字の存在。
- URL の末尾のスラッシュ (「/」) の数
- URL の大文字の数
Yandex は Google ではなく、このリークは価値がないという議論に戻ると、これらの URL 要素は Google の URL 構造ガイドラインの要素とよく似ています。
3. ページレベルの要因
ここで展開することがたくさんあります。 結局のところ、Yandex には、SERP の構築に役割を果たす多数のページ レベルの要因があります。 最も注目すべきもののいくつかは次のとおりです。
- ページの鮮度- 特にブログ コンテンツやニュース Web サイトの場合。 コンテンツ ページが 10 年以上経過している場合、ランキングにマイナスの影響を与えます。 そのため、コンテンツを頻繁に更新してください。
- 最後の目的地- Yandex は、ユーザーの検索ジャーニーを終了するページに報酬を与えます。これは、ユーザーが探しているものを見つけたことを意味します。
- 健全なトラフィック ソース比率- Yandex は、単一のソース (オーガニック検索など) からトラフィックを得るページを好みません。 ページが上位にランクされるには、オーガニック、ペイド、ダイレクトなど、あらゆる種類のソースからトラフィックを獲得する必要があります。
- コンテンツの品質- テキストがオリジナルであり、キーワードが詰め込まれていないことが不可欠です。 テキストが外部ドメインで引用/リンクされている場合、ランキングが向上します。 また、質の低いコンテンツを使用すると、質の高いコンテンツのランク付けが低下します。
4. ウェブサイトレベルの要因
ページの新鮮さの要因に基づいて構築する究極の組み合わせは、長い間アクティブであり、頻繁にコンテンツを更新している確立されたWebサイトを持つことです.
また、Yandex は、クリック可能性の観点から Web サイトの全体的な品質を判断します。 つまり、ユーザーが検索のために URL をクリックする頻度は?
もう 1 つのプラスのランキング要因は、ドメイン名です。 Yandex は、.COM ドメインのランキングを向上させます。

5. ページの品質
コンテンツの品質についてはすでに説明しましたが、全体的なページの品質はどうでしょうか? Yandex は、いくつかの要因に基づいてページの品質を評価します。
- 訪問回数
- ユニークビジター数
- ページ滞在時間
- ページで実行されたアクションの数
6. ユーザーの行動とエンゲージメント
リークから議論する必要がある興味深いユーザー行動がいくつかありました.
重要な要素は、ホストが全体的に受け取るクリック数とインプレッション数です。 Yandex は、ページがモバイル フレンドリーであるかどうかも考慮し、モバイル デバイスでのユーザーの行動 (セッションの継続時間やページでの滞在時間など) を分析します。 また、訪問者が同じ月内にウェブサイトに戻った場合、それはランキング要因としてプラスになります。
しかし、おそらく最も魅力的なものは次のとおりです。
ユーザー レビューを掲載しているページは、検索結果で優先的に表示されます。
7. ホストのランクと場所
Yandex は、地理的にユーザーに近いコンテンツを優先することに重点を置いています。 そのため、2 つのドメイン名が同じ検索クエリで競合している場合、ユーザーに近い方のドメイン名がランキングを上げます。
技術的なランキング要因に関しては、400 クライアント エラーと 500 サーバー エラーの数を減らすことで、SERP で優位に立つことができます。 その上、Yandex はクロールの深さに多くの注意を払っています。 そのため、重要なページがホームページから 2 クリック以上離れていないことを確認してください。
8.バックリンクの品質
Yandex は、ウェブサイトの人気を人為的に膨らませる紹介チェーンの作成にペナルティを課すためにさまざまな手段を採用しています。
そのような尺度の 1 つは、ハイパーリンクされたテキストの割合を分析することです。過剰なリンクは操作的な動作を示している可能性があるためです。 また、サイトに誘導するリンクの品質を考慮し、多数の有料または低品質のリンクを含むサイトにペナルティを課します.
リンクの品質について言えば、リンクの品質に直接影響する要因は、リダイレクトの数とリンクの構築方法です。
9. 検索トラフィックへの影響
Google と同様に、優れた SEO プラクティスを組み込んだ Web サイトは、そうでない Web サイトよりも優れたパフォーマンスを発揮します。 簡単に見つけられるようにすることは、Yandex でより高いランキングを達成するための確実な方法です。
当然のことながら、検索意図に応えることができるページは、それぞれの検索クエリのリーダーです。 タイトル タグと本文テキストに正確な検索クエリを含むページには利点があります。 また、同義語の使用は、ランキングの上昇につながる可能性があるもう 1 つの肯定的なシグナルです。
10.ウィキペディアブースト
高品質のページのもう 1 つの強力なシグナルは、ウィキペディアからリンクされているかどうかです。 Yandex はウィキペディアからリンクされているページを優先し、上位にランク付けします。
11. ビデオコンテンツ
動画コンテンツを含む Web サイトが優先されます。 しかし、問題があります。Yandex は、Yandex がホストするビデオを含むページを上位にランク付けします (当然)。
ページのビデオ コンテンツを評価するという点では、ビデオの合計時間に対する平均視聴時間という標準的な尺度が適用されます。
これら 11 の調査結果はすべていくつかの優れた洞察を提供しましたが、SEO の世界では、漏洩したデータに価値があるかどうかについて議論がありました。
リークされたランキング要因に対するSEO界の反応
完全な却下から詳細な分析まで、SEO は Yandex のリークについてさまざまな意見を表明しました。
Kevin Indig は、最も一般的な反対意見を要約し、ランキング要因の重要性について優れた情報を提供しました。

Kevin Indig による記事「SEO は Yandex リークを過小評価している」の抜粋
Ben Wills、Alex Buraks、Mic King などの SEO 分野の著名人は、漏洩したデータを解読するために袖をまくり上げて深く潜り込みました。
Ben Wills は、ソース コードを理解し、イベントの重要性を把握するのに役立つ最初の専門家の 1 人です (彼は少し後に Twitter スレッドを開きましたが)。
ほぼ同時に、Rob Ousbey は、Yandex コード用のエクスプローラー ツールのアルファ版を共有しました。

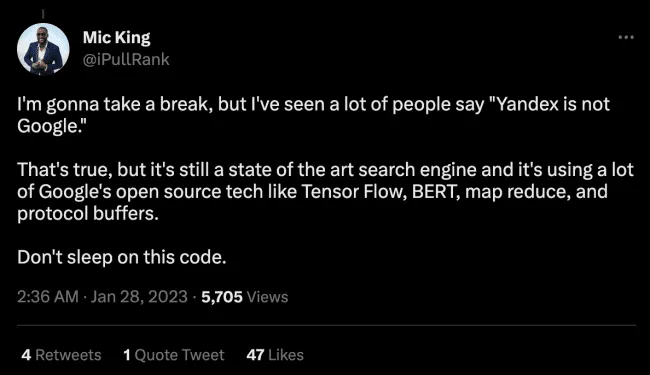
Mic King は、ソース コードを調べながらライブで第一印象を共有し、「このコードで眠らないでください」と語りました。
ロシアの SEO フォーラムも同様に混雑しており、ウェブマスターは西側の SEO の世界と同様の洞察を共有していました。 しかし、ロシアのSEO専門家であるダン・テイラーが取り上げたように、Yandexが自社の製品とサービスを支持していることについても多くの話がありました.
結論
Yandex のソース コードが流出したことで、SEO のやり方が変わりますか?
おそらくそうではありません。
しかし、重要ではないというラベルを付けてスクロールし過ぎてしまうのは大きな間違いです。
どうやら、Yandex と Google には多くの類似点があります。 したがって、このリークは、より多くの実験の優れた出発点として機能し、ユーザーエクスペリエンスと質の高いコンテンツにさらに集中するよう促す可能性があります.
だから、ナックルダウンしてテストを開始してください。