
Google アナリティクスと Shopify を組み合わせる: BigQuery で e コマース データ ウェアハウスを作成する
公開: 2023-02-15Google アナリティクスは、ウェブサイトにアクセスしたユーザーの行動を理解できる優れたツールです。 一方、 Shopify eコマースの観点からパフォーマンスの詳細なカバレッジを提供するのに優れています. どちらも優れた機能を備えていますが、Shopify と Google アナリティクス (GA) からのデータを分離しただけでは、必要なより深い洞察を得ることができない場合があります。 それぞれが強力な情報を提供する能力を持っていますが、データを組み合わせることで得られる洞察のレベルははるかに高くなります.
この特定の例では、自然で健康的なドッグフードを製造する英国を拠点とする会社である Pooch & Mutt の友人のために、これをどのように達成したかを説明します. Google アナリティクスで収集されたデータを取得し、それを Shopify の e コマース データや Recharge のサブスクリプション データと組み合わせて使用し、これを Bold の従来のサブスクリプション データと結合することで、洞察を強化したいと考えました。 このようなさまざまなデータ ソースを使用することで、より豊かで完全な全体像を構築することができました。
このブログでは、このデータを集計する方法の概要を説明し、データを組み合わせてこれらのデータ駆動型の洞察を抽出および視覚化するための思考プロセスについて概説します。 具体的には、次の 3 つの質問にどのように回答したかを説明します。
- サブスクリプションのサインアップを促進するチャネルはどれですか?
- GA を超えるバスケットの組み合わせ。 加入者と非加入者に最も人気のあるバスケットはどれで、最も収益性が高いのはどれですか?
- ユーザーがサブスクライバーになるまでに、平均でどれくらいの期間と何回の購入が必要ですか?
方法論
これらの質問に答える前に、まず、それぞれのプラットフォームからすべてのデータを一元化された場所に収集し、このデータを照合するために使用できるテーブルを構築する方法について説明しましょう.
データ構造
BigQuery (BQ) を使用してデータを一元化することを選択したのは、その汎用性とデータセットの組み合わせを処理する機能のためです。 以下のフローチャートは、データとこれが達成された方法との間の一般的な接続を強調しています。
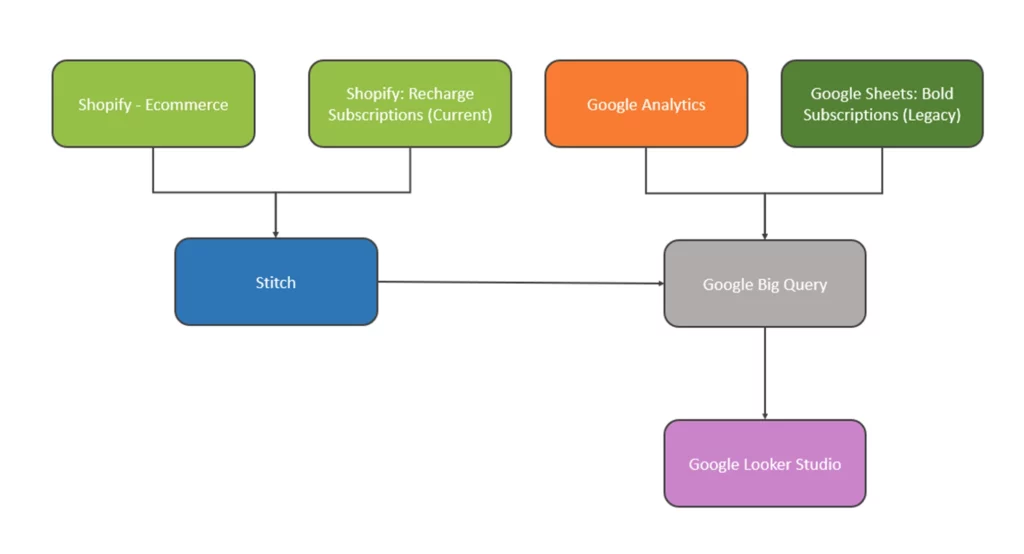
ステッチ
Stitch は、データを抽出して、事前に構築されたデータ ウェアハウスにロードできる手頃な価格のツールです。
必要なテーブルを選択するだけで、Stitch を介して Shopify と Recharge に簡単に接続できました。 この場合、最も重要なテーブルは Recharge の「customers」と「subscriptions」、および Shopify の「orders」です。
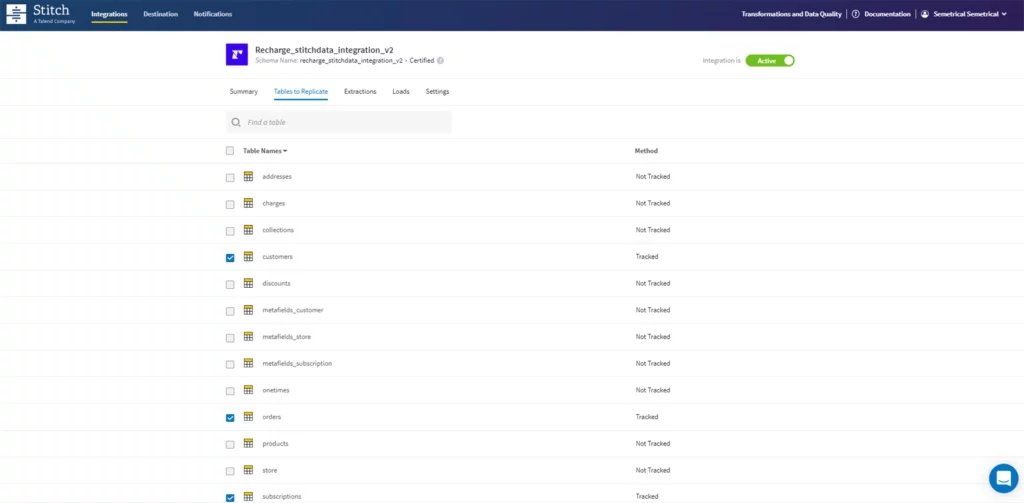

この情報は、Stitch の自動スケジューリング プロセスを通じて 6 時間ごとに BQ と同期されます。
大胆な
過去の購読者データについては、最終的なエクスポートを行い、これを Google スプレッドシート経由で BQ にアップロードしました。
グーグルアナリティクス
これには Stitch も使用できますが、RStudio を使用してこのデータを BQ に取り込むことにしました。 これを行う方法について詳しく知りたい場合は、R で GA API を使用する方法について、R Studio の専門家である Danny Smith によるブログを読むことができます。
マスターテーブルの構築
BQ に必要なデータがすべて揃ったら、結合を開始できます。 これを行うために行った手順は次のとおりです。
- Bold からの従来のサブスクライバー データを、Recharge からの現在のサブスクライバー データと組み合わせて調整しました。
- 次に、注文 ID (SPFYXXXXX など)、ソース、メディア、チャネルを含む e コマース データを GA から取得しました。
- Shopifyの注文データに結合する前に、GAおよびユニオン化された購読者データのテーブルに基づいて新しい列を作成しました。 この場合、これらの追加の列の一部が含まれています。
- 「アクティブな」加入者識別子
- サブスクリプションの元の日付
- 注文のソース、メディア、チャネル
- 最初または繰り返しの顧客注文
- 次に、この新しいデータを結合したい Shopify 注文データから関連するフィールドを選択しました。 主な例は次のとおりです。
- 顧客ID
- オーダーID
- 注文日
- SKU
- アイテムの数量
- 商品価格
- 合計注文金額
- ディスカウントコード
- 割引額
- タグ (サブスクライバーと非サブスクライバーを分類するための追加の方法として使用)
- ここでの最終段階は、いくつかの追加の列を作成して、同じ順序の異なるアイテムの重複行をより簡単に処理することでした。
- 平均時間
- 平均割引
- サブスクライバーのステータス (タグ + Bold & Recharge テーブルに存在する場合)
次に、このクエリを 1 日 1 回実行するようにスケジュールし、その結果を追加のクエリのマスター テーブルとして使用しました。 これにより、完全なクエリを複数回実行する必要がなくなりました。これは、Looker Studio ダッシュボードからリクエストが行われるたびではなく、スケジュールされたときにのみ更新される静的テーブルであるためです。

インサイト
方法論を説明し、必要なすべてのデータを取得するために実行する手順の概要を説明したので、このデータを使用して質問に答える方法について説明します。
サブスクリプションのサインアップを促進するチャネルはどれですか?
- これを計算するために、最初の注文日に基づいて「First」または「Repeat」を返すマスター テーブルに作成したフィールドを使用して、顧客による最初の注文を調べました。
- マスター テーブル内のチャネル グループとサブスクライバー ステータスの追加列を使用して、最初の購入または再購入のいずれかで、サブスクライバーになった人々の最初の注文と、それらが GA でどのチャネルに関連付けられたかを確認できます。 .
- サブスクライバーだけを見るステップを取り除くことで、どのチャネルが主に最初の購入を促進しているかを確認することもできました。
GA を超えるバスケットの組み合わせ。 加入者と非加入者に最も人気のあるバスケットは何ですか?また、最も収益性の高いバスケットはどれですか?
- STRING_AGG 関数を使用して、単一の注文のさまざまな製品を ' | で区切って単一の行にまとめることができました。 '。 これにより、基本的に注文ごとにバスケットが作成されます。
- この情報に加えて、これらの各アイテムの収益を「バスケットの合計」として合計しました。これは、関連するすべての情報を注文ごとに行にすることを目的としています。
- もちろん、製品間 (フレーバー、サイズなど) には多くの差異があるため、基本製品バスケットの組み合わせを確認するために、この差異を取り除いた列を追加しました。
- 次に、「ROW_NUMBER() OVER (PARTITION BY Transaction_ID) AS Identifier」を使用して、各注文に連続した値を割り当てました。 次に、これをダッシュボードのフィルターとして使用して、まだすべての情報が含まれている単一の行を分離しました。
ユーザーがサブスクライバーになるまでに、平均でどれくらいの期間と何回の購入が必要ですか?
- マスター テーブルを使用して、購読者であることがわかっているすべての顧客 ID を取得し、最初の購読日を取得しました。
- 次に、最小注文日を取得し、DATE_DIFF 関数を使用して、これらの日付の差を「日」で計算しました。
- 最後のステップでは、チャネルとサブスクライブまでの平均日数を取得しました。これにより、顧客が通常サブスクライバーになるまでの平均日数を示す表が作成されました。
- 顧客がサブスクライバーになる前に行った平均注文数を計算するために、一意の注文 ID の数を、「サブスクライバー」であり、注文日が最小サブスクリプション日よりも前の一意の顧客 ID の数で割っただけです。
これらは、これらのレポートを使用して生成したビューの表面レベルの例にすぎません。 データには無限の可能性があります。このプロジェクトの他の例には、さまざまな観点から顧客の生涯価値を調べたり、割引コードの使用と顧客の生涯行動全体への影響を評価したりすることが含まれます。 これらの洞察により、ビジネス上の意思決定を補足するために使用できます。 たとえば、サブスクライバーになるまでに平均 3 回の注文が必要であることがわかっている場合、2 回の購入後に顧客がサブスクライバーになるように促すオファーやインセンティブを共有することができます。 この結果は、後で測定することができます。
まとめ
このケース スタディは、GA から Shopify まで、複数のデータ ソースを組み合わせることで得られる、信じられないほど価値のあるデータ駆動型の洞察の可能性を示しています。 このインフラストラクチャが作成されると、動的に維持され、ビジネスのさまざまな側面についてレポートするために使用できます。
このブログで回答した質問が、ご自身のビジネスに関心のある質問と似ている場合は、お問い合わせフォームに記入してご連絡ください。