
Le problème de duplicité pour le référencement et comment le gérer
Publié: 2022-06-03Disons que vous avez envoyé une lettre mais qu'il y a 50 autres personnes portant le même nom dans la même ville, étant donné qu'il n'y a pas de numéro de maison exact. Où la lettre serait-elle livrée ? Comment le facteur saura-t-il qui est le bon destinataire parmi les 50 personnes ? Non seulement cela confondra le pauvre facteur, mais cela lui causera également beaucoup de détresse.
Maintenant, si le facteur est un moteur de recherche et qu'il existe plusieurs pages Web avec le même contenu, imaginez son sort lorsqu'il essaie de déterminer laquelle classer dans les résultats de recherche. C'est ce qui cause un problème de duplicité dans le référencement. En fait, 29 % des pages sur 200 millions d'explorations Web ont un contenu dupliqué.
La duplication de contenu est simplement la présence du même contenu sur plusieurs sites Web avec des adresses (ou URL) différentes. La duplication de contenu n'est pas toujours intentionnelle. Aucun propriétaire ou développeur de site Web ne voudrait perdre le classement des moteurs de recherche parce que son contenu est similaire au contenu d'un autre site Web.
Certaines des causes courantes de duplicité sont :
Pages copiées ou supprimées
Supposons que vous trouviez un excellent article de blog sur un site Web et que vous le partagiez sur le vôtre. Ici, vous copiez ce contenu sur votre site Web, ce qui peut ne pas être éthiquement ou moralement répréhensible. Mais pour un moteur de recherche, cela signifie qu'il existe plusieurs emplacements pour le même contenu.
C'est particulièrement un problème auquel les sites de commerce électronique sont confrontés. Les produits d'un fabricant particulier peuvent être vendus dans de nombreuses boutiques en ligne, mais la description du produit est la même. Ici, seuls quelques magasins de premier plan obtiendront l'affaire.
Siteliner et Copyscape sont deux outils couramment utilisés pour détecter la duplicité. Alors que Siteliner vérifie un site Web pour la duplicité interne, Copyscape vérifie le contenu d'un site Web pour la duplication avec d'autres sites Web.
Paramètres d'URL
Parfois, un léger changement dans l'ordre des paramètres d'une URL peut créer du contenu en double. Ces paramètres ne changeront pas le contenu d'une page. Mais pour un moteur de recherche, ce sont deux URL différentes.
De même, lors de vos achats en ligne également, le site Web vous donne un identifiant de session qui est essentiellement un journal de votre activité sur le site Web. Pour cette raison, de nombreux systèmes finissent par utiliser ces identifiants de session pour les URL.
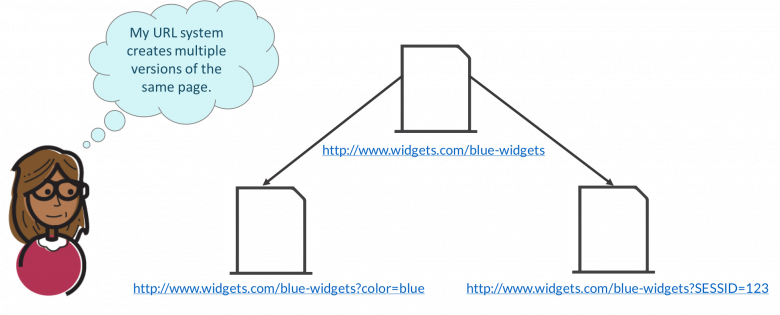
Source de l'image : Moz
Le classement d'un site Web dans les moteurs de recherche est affecté lorsque son URL comporte plusieurs paramètres. Ces paramètres finissent par créer de nombreuses URL avec un contenu similaire qui peuvent confondre un robot et affecter la bonne indexation du site Web. Pour Google, les URL sans paramètre ont un meilleur classement de recherche.
Pages www vs non-www et HTTP vs HTTPs
Il existe de nombreux sites qui se trouvent à la fois sur les URL www et non-www. Certains sites Web ont deux versions, une avec http:// et une avec https:// comme préfixes. Si ces deux versions d'un site Web sont en ligne, elles seront indexées séparément par les moteurs de recherche.
Si vous recherchez une campagne de référencement réussie, la duplicité doit être résolue. Comment éviter ce problème de duplicité ?
Utiliser les 301
La redirection est l'un des meilleurs moyens de gérer la duplicité de contenu. Une redirection 301 signifie que la page est définitivement passée de la page "dupliquée" à la page "d'origine".
Cela résoudra le problème d'une concurrence entre plusieurs pages avec une légère variation d'URL. Les sites Web avec "https://" et "http://", ou les préfixes www et non-www seront automatiquement intégrés au même emplacement.
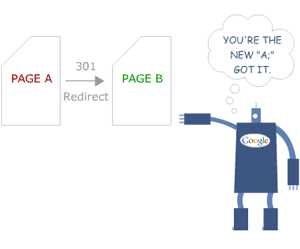
Source de l'image : Moz
Utiliser une balise « rel canonique »
La balise "rel canonique" n'est rien d'autre qu'un moyen de dire au moteur de recherche qu'il n'y a pas de différence entre les deux URL. Cette balise indique au moteur de recherche que la page X est un doublon de la page Y d'origine et qu'à toutes fins futures de classement et de contenu, la page Y doit être prise en compte.

La balise "rel canonical" est placée dans l'en-tête HTML d'une page Web et doit être ajoutée à chaque version copiée de la page Web.

Source de l'image : HiTech Work
Contrôlez et gérez votre contenu :
Créez un contenu unique et de haute qualité pour vos pages Web afin d'éviter le problème de duplication. Si vous avez une description de produit d'un fabricant, écrivez-en de nouvelles et utilisez des images originales qui éviteront le chevauchement avec d'autres sites de commerce électronique.
Cela prend du temps. Mais à long terme, il est important que votre site Web se démarque. Le contenu unique sera automatiquement sélectionné par le moteur de recherche, ce qui améliorera le classement du site Web.
Réduire le même type de contenu
Pour éviter le problème de duplication via les identifiants de session, désactivez-les simplement dans les paramètres de votre système. Pour les variantes d'URL, assurez-vous que le script est construit avec le même ordre de paramètre pour éviter la duplicité.
Google Search Console dispose d'un outil de paramètres d'URL qui aide à créer des URL conviviales pour les moteurs de recherche. Cela aide essentiellement à améliorer l'apparence du site Web sur les moteurs de recherche. L'utilisation de mots, de ponctuations et de cookies appropriés pour empêcher la création d'identifiants de session sont des moyens simples de résoudre ce problème.
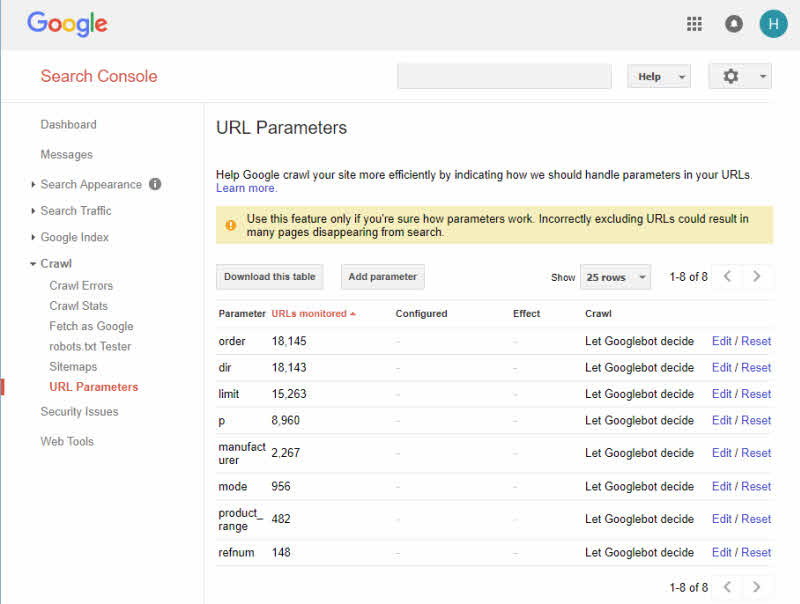
Source de l'image : Hallam
Lien vers le contenu original
Si vous copiez le contenu d'un autre site Web et que vous souhaitez éviter le problème de duplication, ajoutez simplement le lien vers l'original au début ou à la fin de la page Web. Cela peut être fait lorsque vous syndiquez du contenu. Ici, assurez-vous que le site Web de syndication (disons RSS) renvoie au site d'origine.
Conclusion
Vous n'avez pas besoin d'être effrayé par la duplicité du contenu. Plusieurs fois, cela arrive accidentellement. Mais il y a aussi des moments où les propriétaires de sites Web prennent le contenu d'un autre site Web et le mettent sur le leur après de légères modifications. Cela conduit également à la duplicité, même si vous pourriez penser que la langue est différente.
Lors du classement d'un site Web, un moteur de recherche tiendra compte de la quantité de contenu copié, du contenu qui a été vu en premier et du site Web le plus puissant. Lorsqu'un moteur de recherche trouve une page Web avec du contenu copié, non seulement le classement de la page est affecté, mais le site est également mis en évidence comme une source non fiable et ses points de qualité sont retirés.
La duplicité est un gros piège lorsqu'il s'agit d'améliorer le classement de recherche d'un site Web, mais elle est hautement réparable. Une fois ce problème résolu, vous pouvez suivre l'amélioration du classement de votre site Web dans les moteurs de recherche au fil du temps.
Mais garder une veille constante sur les performances d'un site Web est difficile. Et pour cela, vous pouvez utiliser Pro Rank Tracker. Cet outil vous donne des mises à jour régulières sur le classement de votre site Web avant et après avoir résolu ses problèmes de duplicité afin que vous puissiez suivre efficacement votre croissance.
Les moteurs de recherche n'ont aucune exception lorsqu'ils essaient d'évaluer la valeur d'un contenu. Ils suivent purement des algorithmes définis. Pour vous faire remarquer par le moteur de recherche, corrigez immédiatement le problème de duplicité. Un bon classement dans les moteurs de recherche signifie un bon trafic qui augmentera votre retour sur investissement.