
SEO의 이중성 문제와 해결 방법
게시 됨: 2022-06-03당신이 편지를 보냈지만 정확한 집 번호가 없는 것을 고려하면 같은 도시에 같은 이름을 가진 50명의 다른 사람들이 있다고 가정해 봅시다. 편지는 어디로 배달되었을까요? 우편 배달부가 50명 중 정확한 수취인을 어떻게 알 수 있습니까? 그것은 가난한 우편 배달부를 혼란스럽게 할 뿐만 아니라 그에게 많은 고통을 줄 것입니다.
이제 우편 배달부가 검색 엔진이고 동일한 콘텐츠를 가진 웹 페이지가 두 개 이상 있는 경우 검색 결과에서 어느 페이지의 순위를 매길지 알아낼 때의 곤경을 상상해 보십시오. 이것이 SEO에서 이중성 문제를 일으키는 원인입니다. 실제로 2억 개의 웹 크롤링 중 29%의 페이지에 중복 콘텐츠가 있습니다.
콘텐츠 복제는 단순히 주소(또는 URL)가 다른 여러 웹사이트에 동일한 콘텐츠가 존재하는 것입니다. 콘텐츠 복제가 항상 의도적인 것은 아닙니다. 웹사이트 소유자나 개발자는 콘텐츠가 다른 웹사이트의 콘텐츠와 유사하기 때문에 검색 엔진 순위에서 지고 싶어하지 않을 것입니다.
이중성의 일반적인 원인은 다음과 같습니다.
복사 또는 스크랩한 페이지
웹 사이트에서 멋진 블로그 게시물을 찾아 공유한다고 가정해 보겠습니다. 여기에서 윤리적으로나 도덕적으로 잘못된 것이 아닐 수 있는 웹사이트의 해당 콘텐츠를 복사하고 있습니다. 그러나 검색 엔진의 경우 동일한 콘텐츠에 대해 여러 위치가 있음을 의미합니다.
이것은 특히 전자 상거래 웹사이트가 직면한 문제입니다. 특정 제조업체의 제품은 여러 온라인 상점에서 판매될 수 있지만 제품 설명은 동일합니다. 여기서는 소수의 유명 상점만 비즈니스를 수행할 것입니다.
Siteliner와 Copyscape는 이중성을 감지하는 데 일반적으로 사용되는 두 가지 도구입니다. Siteliner가 웹사이트의 내부 이중성을 확인하는 동안 Copyscape는 웹사이트의 콘텐츠가 다른 웹사이트와 중복되는지 확인합니다.
URL 매개변수
때때로 URL의 매개변수 순서를 약간 변경하면 중복 콘텐츠가 생성될 수 있습니다. 이 매개변수는 페이지의 내용을 변경하지 않습니다. 그러나 검색 엔진의 경우 이들은 두 개의 다른 URL입니다.
유사하게, 온라인 쇼핑도 하는 동안 웹사이트는 본질적으로 웹사이트에서의 활동 로그인 세션 ID를 제공합니다. 이 때문에 많은 시스템이 URL에 이러한 세션 ID를 사용하게 됩니다.
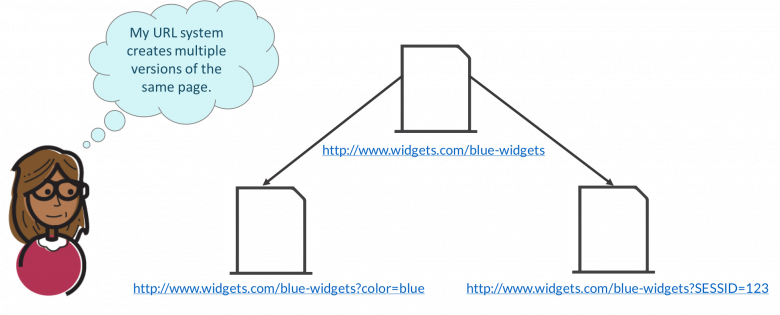
이미지 출처: 모즈
URL에 여러 매개변수가 있는 경우 웹사이트의 검색 엔진 순위가 부정적인 영향을 받습니다. 이러한 매개변수는 결국 크롤러를 혼동시키고 웹사이트의 적절한 색인 생성에 영향을 줄 수 있는 유사한 콘텐츠로 많은 URL을 생성합니다. Google의 경우 매개변수가 아닌 URL이 검색 순위가 더 좋습니다.
www 대 www가 아닌 페이지 및 HTTP 대 HTTPS
www와 www가 아닌 URL 모두에서 찾을 수 있는 사이트가 많이 있습니다. 특정 웹사이트에는 접두사로 http://가 있는 버전과 https://가 있는 버전의 두 가지 버전이 있습니다. 이 두 버전의 웹사이트가 모두 활성 상태인 경우 검색 엔진에서 별도로 색인을 생성합니다.
성공적인 SEO 캠페인을 찾고 있다면 이중성을 해결해야 합니다. 이 이중성 문제를 어떻게 피할 수 있습니까?
301을 사용
리디렉션은 콘텐츠 중복성을 처리하는 가장 좋은 방법 중 하나입니다. 301 리디렉션은 페이지가 "중복"에서 "원본" 페이지로 영구적으로 이동되었음을 의미합니다.
이것은 약간의 URL 변형으로 여러 페이지 간의 경쟁 문제를 해결할 것입니다. "https://" 및 "http://" 또는 www와 www가 없는 접두사가 있는 웹 사이트는 자동으로 동일한 위치에 통합됩니다.
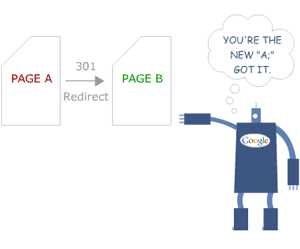

이미지 출처: 모즈
"rel canonical" 태그 사용
"rel canonical" 태그는 검색 엔진에 두 URL 간에 차이가 없음을 알리는 방법일 뿐입니다. 이 태그는 페이지 X가 원래 페이지 Y의 복제본이며 향후 순위 및 콘텐츠 목적을 위해 페이지 Y가 고려되어야 함을 검색 엔진에 나타냅니다.
"rel canonical" 태그는 웹 페이지의 HTML 헤드에 배치되며 웹 페이지의 모든 복사된 버전에 추가되어야 합니다.

이미지 출처: 하이테크워크
콘텐츠 제어 및 관리:
복제 문제를 피하기 위해 웹 페이지에 고유하고 고품질의 콘텐츠를 만드십시오. 제조사의 제품 설명이 있는 경우 다른 전자 상거래 사이트와 중복되지 않도록 새 설명을 작성하고 원본 사진을 사용하십시오.
시간이 많이 걸립니다. 그러나 장기적으로 웹사이트가 눈에 띄는 것이 중요합니다. 고유한 콘텐츠는 검색 엔진에서 자동으로 선택되어 웹사이트의 순위가 높아집니다.
동일한 유형의 콘텐츠 줄이기
세션 ID를 통한 중복 문제를 방지하려면 시스템 설정에서 비활성화하십시오. URL 변형의 경우 중복을 피하기 위해 동일한 매개변수 순서로 스크립트를 빌드해야 합니다.
Google Search Console에는 검색 엔진 친화적인 URL을 만드는 데 도움이 되는 URL 매개변수 도구가 있습니다. 기본적으로 웹 사이트의 검색 엔진 모양을 개선하는 데 도움이 됩니다. 세션 ID 생성을 방지하기 위해 적절한 단어, 구두점 및 쿠키를 사용하는 것은 이 문제를 해결하는 몇 가지 간단한 방법입니다.
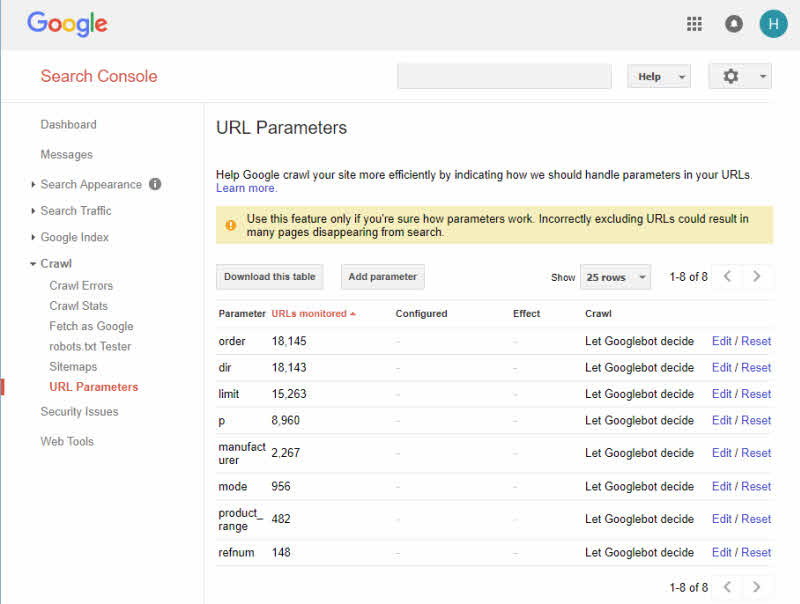
이미지 출처 : 한람
원본 콘텐츠에 대한 링크
다른 웹사이트에서 콘텐츠를 복사하는 경우 중복 문제를 방지하려면 웹 페이지 시작 또는 끝에 원본 링크를 추가하기만 하면 됩니다. 이는 콘텐츠를 신디케이트할 때 수행할 수 있습니다. 여기에서 신디케이션 웹사이트(예: RSS)가 원래 사이트로 다시 연결되는지 확인합니다.
결론
콘텐츠 이중성에 겁먹을 필요는 없습니다. 우연히 발생하는 경우가 많습니다. 그러나 웹사이트 소유자가 다른 웹사이트에서 콘텐츠를 가져와 약간의 변경 후에 게시하는 경우도 있습니다. 이것은 또한 언어가 다르다고 생각할 수도 있지만 이중성을 낳습니다.
웹사이트의 순위를 매길 때 검색 엔진은 복사된 콘텐츠의 양, 가장 먼저 본 콘텐츠 및 더 강력한 웹사이트를 고려합니다. 검색 엔진이 복사된 콘텐츠가 있는 웹 페이지를 찾으면 페이지의 순위가 영향을 받을 뿐만 아니라 사이트가 신뢰할 수 없는 소스로 강조 표시되고 품질 점수가 떨어집니다.
이중성은 웹사이트의 검색 순위를 높이는 데 있어 큰 함정이지만 고칠 수 있습니다. 이 문제가 해결되면 웹사이트의 검색 엔진 순위가 시간이 지남에 따라 개선된 것을 추적할 수 있습니다.
그러나 웹사이트의 성능을 지속적으로 관찰하는 것은 어렵습니다. 이를 위해 Pro Rank Tracker를 사용할 수 있습니다. 이 도구는 중복 문제를 해결하기 전후에 웹 사이트 순위에 대한 정기적인 업데이트를 제공하므로 성장을 효율적으로 추적할 수 있습니다.
검색 엔진은 콘텐츠의 가치를 측정할 때 예외가 없습니다. 그들은 순전히 설정된 알고리즘을 따릅니다. 검색 엔진의 주목을 받으려면 중복 문제를 즉시 수정하십시오. 좋은 검색 엔진 순위는 ROI를 높일 좋은 트래픽을 의미합니다.