
A questão da duplicidade para SEO e como lidar com isso
Publicados: 2022-06-03Digamos que você enviou uma carta, mas há outras 50 pessoas com o mesmo nome na mesma cidade, considerando que não há um número exato de casa. Onde a carta seria entregue? Como o carteiro saberá quem é o destinatário correto entre as 50 pessoas? Não só vai confundir o pobre carteiro, mas também causar-lhe muita angústia.
Agora, se o carteiro é um mecanismo de pesquisa e há mais de uma página da Web com o mesmo conteúdo, imagine sua situação quando estiver tentando descobrir qual delas classificar nos resultados de pesquisa. Isso é o que causa um problema de duplicidade no SEO. De fato, 29% das páginas de 200 milhões de rastreamentos na web têm conteúdo duplicado.
A duplicação de conteúdo é simplesmente a presença do mesmo conteúdo em vários sites com endereços (ou URLs) diferentes. A duplicação de conteúdo nem sempre é intencional. Nenhum proprietário ou desenvolvedor de site gostaria de perder as classificações dos mecanismos de pesquisa porque seu conteúdo é semelhante ao conteúdo de outro site.
Algumas das causas comuns de duplicidade são:
Páginas copiadas ou sucateadas
Suponha que você encontre uma ótima postagem de blog em um site e a compartilhe no seu. Aqui você está copiando esse conteúdo em seu site, o que pode não ser ética ou moralmente errado. Mas para um mecanismo de pesquisa, isso significa que existem vários locais para o mesmo conteúdo.
Este é especialmente um problema que os sites de comércio eletrônico enfrentam. Os produtos de um determinado fabricante podem ser vendidos em muitas lojas online, mas a descrição do produto é a mesma. Aqui, apenas algumas lojas proeminentes conseguirão o negócio.
Siteliner e Copyscape são duas ferramentas comumente usadas para detectar duplicidade. Enquanto o Siteliner verifica se há duplicidade interna em um site, o Copyscape verifica se o conteúdo de um site está duplicado com outros sites.
Parâmetros de URL
Às vezes, uma pequena alteração na ordem do parâmetro de um URL pode criar conteúdo duplicado. Esses parâmetros não alteram o conteúdo de uma página. Mas para um mecanismo de pesquisa, esses são dois URLs diferentes.
Da mesma forma, ao fazer compras on-line, o site fornece um ID de sessão que é essencialmente um registro de sua atividade no site. Por causa disso, muitos sistemas acabam usando esses IDs de sessão para URLs.
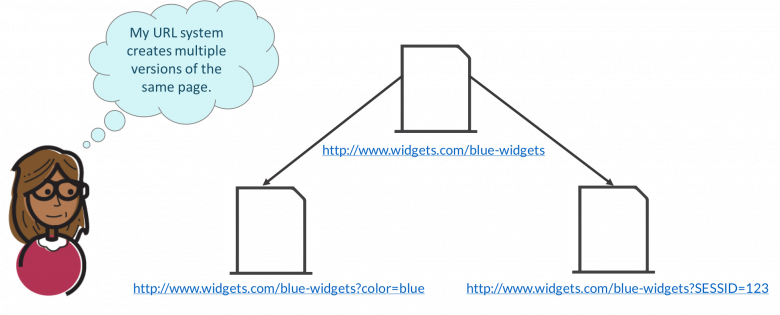
Fonte da imagem: Moz
As classificações do mecanismo de pesquisa de um site são afetadas negativamente quando seu URL possui vários parâmetros. Esses parâmetros acabam criando muitas URLs com conteúdo semelhante que podem confundir um rastreador e afetar a indexação adequada do site. Para o Google, os URLs sem parâmetros têm uma classificação de pesquisa melhor.
www vs páginas não www e HTTP vs HTTPs
Existem muitos sites que são encontrados em URLs www e não www. Certos sites têm duas versões, uma com http:// e outra com https:// como prefixos. Se ambas as versões de um site estiverem ativas, elas serão indexadas separadamente pelos mecanismos de pesquisa.
Se você está procurando uma campanha de SEO bem-sucedida, a duplicidade precisa ser abordada. Como você pode evitar esse problema de duplicidade?
Usar 301s
O redirecionamento é uma das melhores maneiras de lidar com a duplicidade de conteúdo. Um redirecionamento 301 significa que a página foi movida permanentemente da página “duplicada” para a página “original”.
Isso resolverá o problema de uma competição entre várias páginas com uma pequena variação de URL. Os sites com “https://” e “http://” ou o prefixo www e não www serão integrados automaticamente ao mesmo local.
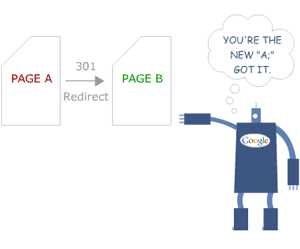
Fonte da imagem: Moz
Use uma tag “rel canonical”
A tag “rel canonical” nada mais é do que uma maneira de informar ao mecanismo de pesquisa que não há diferença entre as duas URLs. Essa tag indica ao mecanismo de pesquisa que a Página X é uma duplicata da Página Y original e para todos os propósitos futuros de classificação e conteúdo, a Página Y deve ser considerada.

A tag “rel canonical” é colocada no cabeçalho HTML de uma página web e deve ser adicionada a cada versão copiada da página web.

Fonte da imagem: HiTechWork
Controle e gerencie seu conteúdo:
Crie conteúdo exclusivo e de alta qualidade para suas páginas da web para evitar o problema de duplicação. Se você tiver uma descrição do produto de um fabricante, escreva novas e use fotos originais que evitarão a sobreposição com outros sites de comércio eletrônico.
Isso é demorado. Mas, a longo prazo, é importante que seu site se destaque. O conteúdo exclusivo será selecionado automaticamente pelo mecanismo de pesquisa, o que aumentará a classificação do site.
Reduza o mesmo tipo de conteúdo
Para evitar o problema de duplicação por meio de IDs de sessão, basta desativá-los nas configurações do sistema. Para variações de URL, certifique-se de que o script seja criado com a mesma ordem de parâmetro para evitar duplicidade.
O Google Search Console tem uma ferramenta de parâmetros de URL que ajuda a criar URLs amigáveis para mecanismos de pesquisa. Basicamente, ajuda a melhorar a aparência do mecanismo de pesquisa do site. Usar palavras, pontuação e cookies adequados para impedir a criação de IDs de sessão são algumas maneiras simples de resolver esse problema.
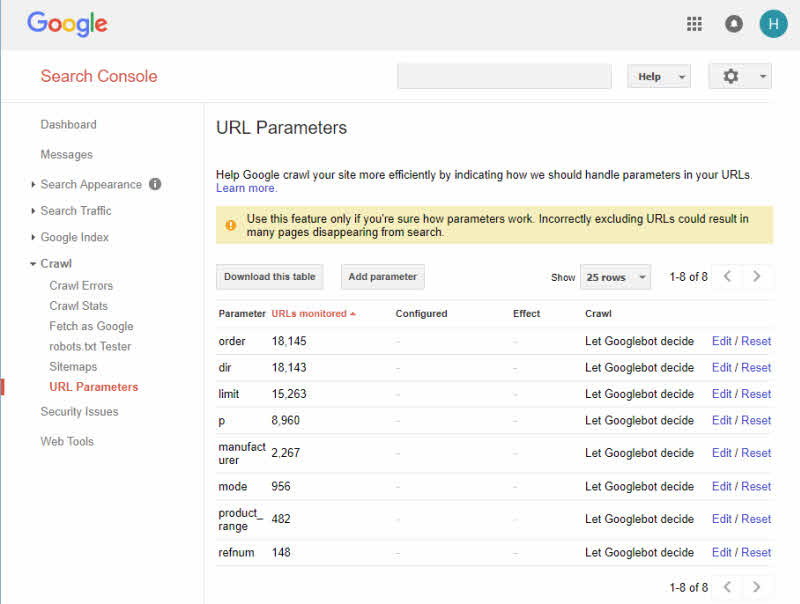
Fonte da imagem: Hallam
Link para o conteúdo original
Caso você esteja copiando conteúdo de outro site e queira evitar o problema de duplicação, basta adicionar o link ao original no início ou no final da página da web. Isso pode ser feito quando você está distribuindo conteúdo. Aqui, certifique-se de que o site de distribuição (digamos RSS) tenha links para o site original.
Conclusão
Você não precisa se assustar com a duplicidade de conteúdo. Muitas vezes isso acontece acidentalmente. Mas também há momentos em que os proprietários de sites pegam conteúdo de outro site e o colocam no deles após pequenas alterações. Isso também leva à duplicidade, mesmo que você pense que a linguagem é diferente.
Ao classificar um site, um mecanismo de pesquisa considerará quanto conteúdo é copiado, qual conteúdo foi visto primeiro e qual site tem mais força. Quando um mecanismo de pesquisa encontra uma página da Web com conteúdo copiado, não apenas a classificação da página é afetada, mas o site também é destacado como uma fonte não confiável e seus pontos de qualidade são retirados.
A duplicidade é uma grande armadilha quando se trata de melhorar a classificação de pesquisa de um site, mas é altamente corrigível. Depois que esse problema for resolvido, você poderá acompanhar a melhoria que a classificação do mecanismo de pesquisa do seu site teve ao longo do tempo.
Mas manter uma vigilância constante sobre o desempenho de um site é difícil. E para isso você pode usar o Pro Rank Tracker. Essa ferramenta fornece atualizações regulares sobre a classificação do seu site antes e depois de resolver seus problemas de duplicidade, para que você possa acompanhar seu crescimento com eficiência.
Os mecanismos de pesquisa não têm exceções ao tentar avaliar o valor de um conteúdo. Eles seguem puramente algoritmos definidos. Para ser notado pelo mecanismo de pesquisa, corrija o problema de duplicidade imediatamente. Uma boa classificação nos mecanismos de pesquisa significa um bom tráfego, o que aumentará seu ROI.