
SEOの重複の問題とその処理方法
公開: 2022-06-03手紙を郵送したが、正確な家番号がないことを考えると、同じ都市に同じ名前の人が50人いるとします。 手紙はどこに届けられますか? 郵便配達員は、50人のうち誰が正しい受取人であるかをどのようにして知るのでしょうか。 それは貧しい郵便配達員を混乱させるだけでなく、彼に多くの苦痛を引き起こします。
郵便配達員が検索エンジンであり、同じコンテンツのWebページが複数ある場合、検索結果でランク付けするWebページを見つけようとするときの窮状を想像してみてください。 これがSEOの重複問題の原因です。 実際、2億のWebクロールのうち29%のページに重複するコンテンツがあります。
コンテンツの複製とは、アドレス(またはURL)が異なる複数のWebサイトに同じコンテンツが存在することです。 コンテンツの複製は必ずしも意図的なものではありません。 彼らのコンテンツが別のウェブサイトのコンテンツに類似しているので、ウェブサイトの所有者や開発者は検索エンジンのランキングを失いたくないでしょう。
重複の一般的な原因のいくつかは次のとおりです。
コピーまたはスクラップされたページ
あなたがウェブサイトで素晴らしいブログ投稿を見つけて、それをあなたのもので共有するとします。 ここであなたはあなたのウェブサイトにそのコンテンツをコピーしていますが、それは倫理的または道徳的に間違っていないかもしれません。 しかし、検索エンジンの場合、同じコンテンツに対して複数の場所があることを意味します。
これは特にeコマースWebサイトが直面する問題です。 特定のメーカーの製品は多くのオンラインストアで販売されている可能性がありますが、製品の説明は同じです。 ここでは、少数の著名な店だけがビジネスを手に入れます。
SitelinerとCopyscapeは、重複を検出するために一般的に使用される2つのツールです。 SitelinerがWebサイトの内部重複をチェックしている間、CopyscapeはWebサイトのコンテンツが他のWebサイトと重複していないかチェックします。
URLパラメータ
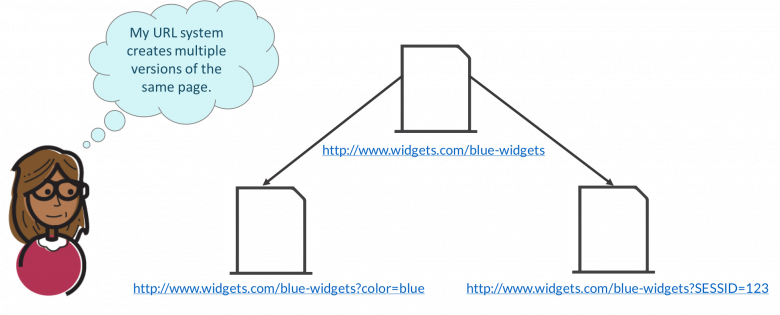
URLのパラメータの順序を少し変更すると、コンテンツが重複する場合があります。 これらのパラメータは、ページのコンテンツを変更しません。 ただし、検索エンジンの場合、これらは2つの異なるURLです。
同様に、オンラインで買い物をしている間も、WebサイトはセッションIDを提供します。これは、基本的にWebサイトでのアクティビティのログです。 このため、多くのシステムはURLにこれらのセッションIDを使用することになります。
画像ソース:Moz
Webサイトの検索エンジンのランキングは、そのURLに複数のパラメーターがある場合に悪影響を受けます。 これらのパラメーターは、クローラーを混乱させ、Webサイトの適切なインデックス作成に影響を与える可能性のある、類似したコンテンツを含む多くのURLを作成することになります。 Googleの場合、パラメータ以外のURLの方が検索ランキングが高くなります。
wwwとwww以外のページおよびHTTPとHTTPS
wwwと非wwwの両方のURLにある多くのサイトがあります。 特定のWebサイトには2つのバージョンがあります。1つはhttp://を使用し、もう1つはプレフィックスとしてhttps://を使用します。 これらのバージョンのWebサイトが両方とも公開されている場合、検索エンジンによって個別にインデックスが作成されます。
あなたが成功したSEOキャンペーンを探しているなら、重複に対処する必要があります。 この重複の問題をどのように回避できますか?
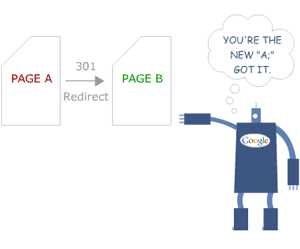
301を使用する
リダイレクトは、コンテンツの重複に対処するための最良の方法の1つです。 301リダイレクトは、ページが「複製」ページから「元の」ページに永続的に移動したことを意味します。
これにより、URLがわずかに異なる複数のページ間の競合の問題が解決されます。 「https://」と「http://」、またはwwwとwww以外のプレフィックスが付いたWebサイトは、自動的に同じ場所に統合されます。

画像ソース:Moz
「relcanonical」タグを使用する
「relcanonical」タグは、2つのURLに違いがないことを検索エンジンに伝える方法に他なりません。 このタグは、ページXが元のページYの複製であり、ランキングとコンテンツの将来のすべての目的のために、ページYを考慮する必要があることを検索エンジンに示します。
「relcanonical」タグは、WebページのHTMLヘッドに配置され、コピーされたすべてのバージョンのWebページに追加する必要があります。

画像ソース:HiTechWork
コンテンツの制御と管理:
重複の問題を回避するために、Webページに独自の高品質のコンテンツを作成します。 メーカーからの製品説明がある場合は、他のeコマースサイトとの重複を避けるために、新しいものを作成し、元の写真を使用してください。
これには時間がかかります。 しかし、長期的には、あなたのウェブサイトが目立つことが重要です。 ユニークなコンテンツは検索エンジンによって自動的に選択され、ウェブサイトのランキングを上げます。
同じ種類のコンテンツを減らす
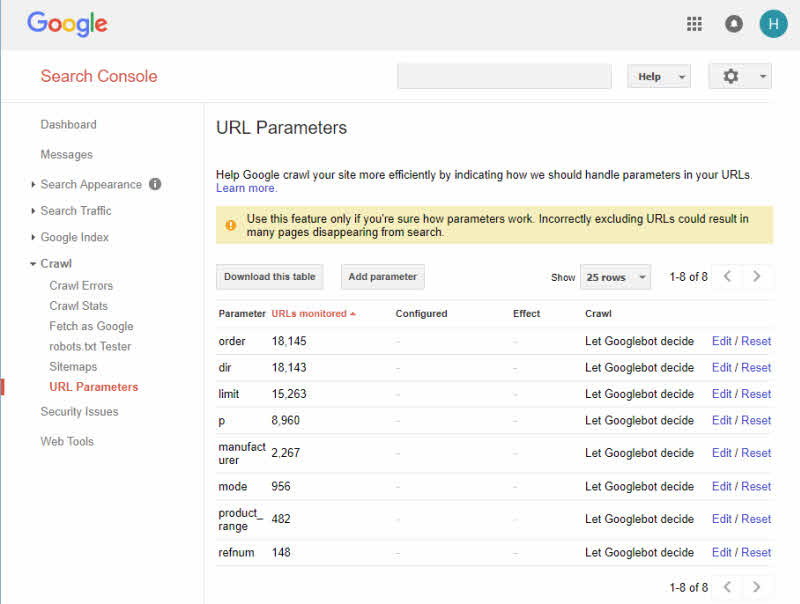
セッションIDによる重複の問題を回避するには、システム設定からIDを無効にするだけです。 URLのバリエーションについては、重複を避けるために、スクリプトが同じパラメーター順序で作成されていることを確認してください。
Google検索コンソールには、検索エンジンに適したURLを作成するのに役立つURLパラメータツールがあります。 それは基本的にウェブサイトの検索エンジンの外観を改善するのに役立ちます。 適切な単語、句読点、およびCookieを使用して、セッションIDが作成されないようにすることは、この問題を解決するための簡単な方法です。
画像出典:ハラム
オリジナルコンテンツへのリンク
別のWebサイトからコンテンツをコピーしていて、重複の問題を回避したい場合は、Webページの最初または最後に元のWebページへのリンクを追加するだけです。 これは、コンテンツをシンジケートしているときに実行できます。 ここで、シンジケートWebサイト(RSSなど)が元のサイトにリンクしていることを確認します。
結論
コンテンツの重複に惑わされる必要はありません。 多くの場合、それは偶然に起こります。 ただし、Webサイトの所有者が他のWebサイトからコンテンツを取得し、わずかな変更を加えた後にそれを自分のWebサイトに配置する場合もあります。 言語が違うと思うかもしれませんが、これは重複にもつながります。
検索エンジンは、Webサイトをランク付けするときに、コピーされるコンテンツの量、最初に表示されたコンテンツ、およびより強力なWebサイトを検討します。 検索エンジンがコピーされたコンテンツを含むWebページを見つけると、ページのランキングが影響を受けるだけでなく、そのサイトは信頼できないソースとして強調表示され、その品質ポイントが失われます。
重複は、ウェブサイトの検索ランキングを向上させる上で大きな落とし穴ですが、高度に修正可能です。 この問題が解決されると、Webサイトの検索エンジンランキングが時間の経過とともに見た改善を追跡できます。
しかし、Webサイトのパフォーマンスを常に監視することは困難です。 そのためには、プロランクトラッカーを使用できます。 このツールを使用すると、重複の問題を解決する前後にWebサイトのランキングを定期的に更新できるため、成長を効率的に追跡できます。
コンテンツの価値を測定しようとしている間、検索エンジンには例外はありません。 それらは純粋に設定されたアルゴリズムに従います。 検索エンジンに気付かれるには、重複の問題をすぐに修正してください。 良い検索エンジンランキングはあなたのROIを高める良いトラフィックを意味します。