
Amazon Scraping: desbloqueando nuevas oportunidades para empresas de comercio electrónico
Publicado: 2024-03-13En el panorama en constante evolución del comercio electrónico, los datos son la piedra angular de la ventaja competitiva. Entre la gran cantidad de mercados en línea, Amazon se destaca como un gigante que alberga una amplia gama de productos, reseñas de clientes y estrategias de precios. Para las empresas de comercio electrónico que buscan prosperar, extraer datos disponibles públicamente de Amazon no es solo una opción; es un imperativo estratégico. En este blog, profundizamos en cómo la extracción de datos de Amazon puede desbloquear nuevas oportunidades para las empresas de comercio electrónico.

Fuente: www.brightdata.com
El poder de los datos de Amazon
El vasto repositorio de listados de productos, reseñas y datos de comportamiento del consumidor de Amazon es una mina de oro para las empresas de comercio electrónico. Al analizar estratégicamente estos datos, las empresas pueden obtener información sobre las tendencias del mercado, la dinámica de precios, las preferencias de los clientes y las estrategias competitivas. Sin embargo, navegar manualmente por este océano de datos no es práctico. Aquí es donde entran en juego las herramientas y servicios de web scraping personalizados.
Cómo extraer datos de productos de Amazon
La búsqueda de datos de productos en Amazon puede desbloquear información valiosa para el análisis de mercado, la inteligencia competitiva y el seguimiento de precios. Sin embargo, dada la naturaleza dinámica de Amazon y sus ricas interfaces basadas en JavaScript, extraer estos datos requiere un enfoque estratégico. Aquí hay una guía concisa sobre cómo extraer datos de productos de Amazon de manera efectiva.
Comprender la estructura de Amazon
Antes de iniciar un raspado, familiarícese con la estructura del sitio web de Amazon, incluida la forma en que se clasifican los productos y el formato de las URL. Esta comprensión le ayudará a navegar por el sitio mediante programación y a orientar la extracción de datos con mayor precisión.
Elegir las herramientas adecuadas
Para el entorno rico en JavaScript de Amazon, considere utilizar herramientas que puedan representar JavaScript como un navegador real. Los navegadores sin cabeza como Puppeteer para Node.js o Selenium WebDriver son excelentes opciones. Pueden interactuar con la página web, lo que le permite extraer contenido dinámico cargado a través de JavaScript.
Manejo de paginación y contenido dinámico
Los listados de productos de Amazon están paginados y, a menudo, se cargan dinámicamente. Su secuencia de comandos de raspado debe manejar la paginación de manera efectiva, ya sea detectando y siguiendo los enlaces de la página "Siguiente" o manipulando los parámetros de URL utilizados para la paginación. Además, implementar esperas o retrasos en su secuencia de comandos puede garantizar que el contenido dinámico se cargue por completo antes de la extracción.
Extracción de datos del producto
Con sus herramientas configuradas y la navegación manejada, concéntrese en extraer los datos específicos del producto que necesita. Esto podría incluir nombres de productos, precios, calificaciones y reseñas. Utilizando los selectores CSS de estos puntos de datos, puede extraer el contenido utilizando la herramienta de scraping elegida. Por ejemplo, con Puppeteer, usarías métodos como page.evaluate() para recuperar el contenido de texto de los elementos que coinciden con tus selectores.
Respetando las políticas de Amazon
Es fundamental realizar scraping de forma responsable respetando el archivo robots.txt y los términos de servicio de Amazon. Asegúrese de que sus actividades de scraping no sobrecarguen los servidores de Amazon; implementar prácticas educadas de scraping, como limitar la velocidad y utilizar un retraso de solicitud razonable, puede ayudar a mitigar el riesgo de ser bloqueado.
Cómo desbloquear oportunidades con Amazon Scraping
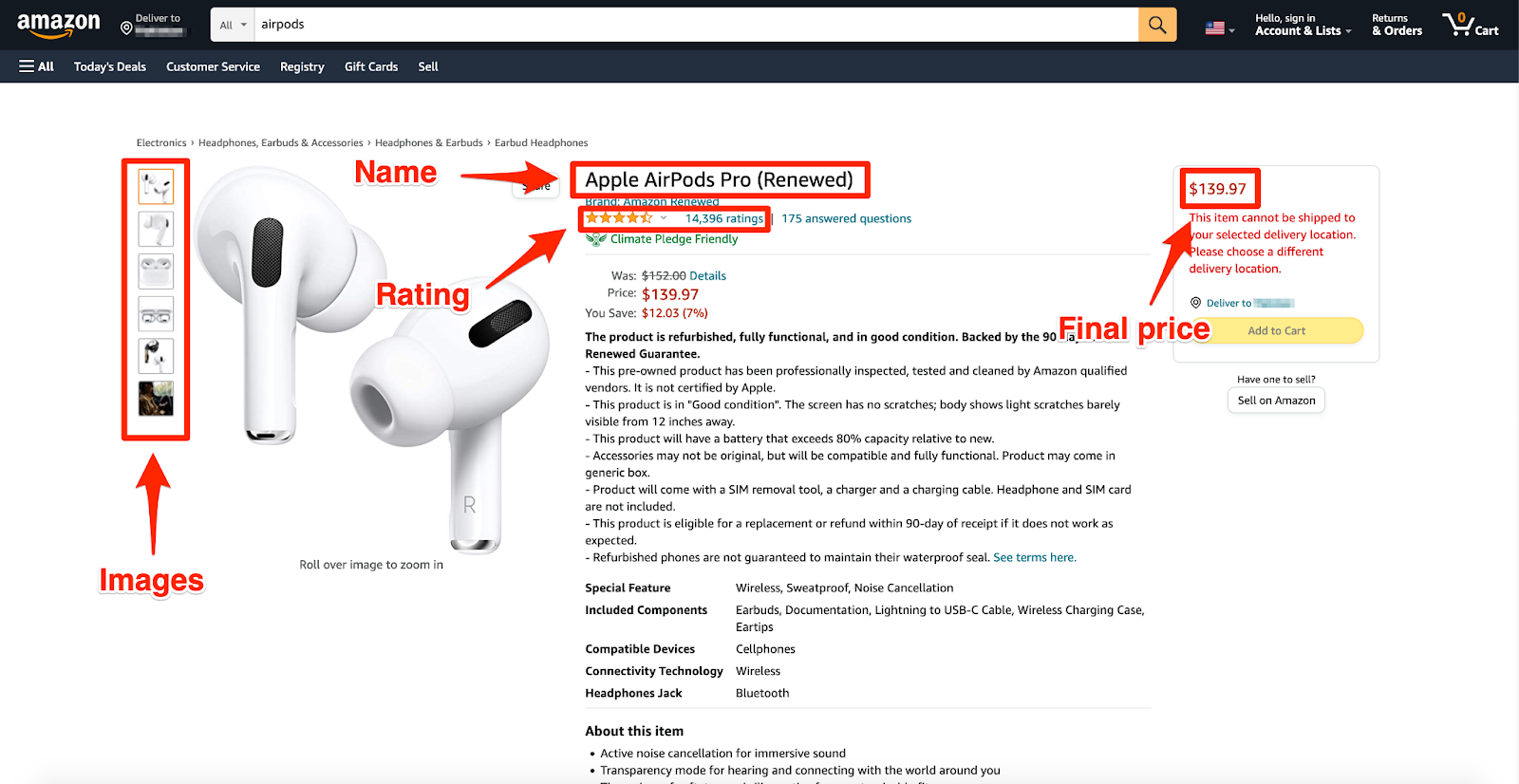
Fuente: www.scrapingbee.com
Análisis competitivo
En el bullicioso ámbito del comercio electrónico, mantenerse a la vanguardia significa vigilar de cerca a la competencia. Imagínese poder echar un vistazo al manual de estrategias de su competidor: comprender no sólo lo que venden, sino también cómo fijan el precio de sus productos y lo que dicen sus clientes. Ese es el poder del raspado.
Considere “Brand X”, una startup que ofrece artículos para el hogar ecológicos. Al descartar Amazon, notaron una brecha en jabones para platos biodegradables y asequibles. Aprovechando esta información, Brand X introdujo una línea de alta calidad y precio competitivo que rápidamente se convirtió en un éxito de ventas, labrándose efectivamente un nicho en un mercado abarrotado.
Optimización de precios
En Amazon, el precio correcto puede atraer clientes e impulsar las ventas, mientras que el precio incorrecto puede ahuyentarlos. A través del scraping estratégico, las empresas pueden recopilar datos de precios en un espectro de productos, ajustando sus propios precios en tiempo real para seguir siendo competitivos y atractivos para los consumidores.
"GadgetPro", un minorista de productos electrónicos, utiliza datos de Amazon para monitorear las tendencias de precios de los últimos dispositivos. Cuando notan que un competidor líder reduce los precios de los relojes inteligentes, GadgetPro responde ofreciendo un descuento por tiempo limitado, reteniendo con éxito el interés y las ventas de los clientes.
Detección de tendencias
Con millones de transacciones diarias, Amazon es una mina de oro para detectar tendencias de consumo. La extracción de datos puede resaltar qué productos están ganando popularidad, lo que permite a las empresas aprovechar estas tendencias desde el principio.
“Fashion Forward”, una boutique de ropa en línea, identifica un aumento repentino en las búsquedas de “moda sostenible” en Amazon. Al adaptarse rápidamente, amplían su línea de prendas ecológicas y se posicionan como pioneros en sostenibilidad.
Mejorar la experiencia del cliente
Las reseñas de Amazon son más que simples comentarios; son una línea directa con los deseos y necesidades del cliente. Al analizar estas reseñas, las empresas pueden identificar exactamente qué es lo que deleita a los clientes o qué los ahuyenta, y luego ajustarlos en consecuencia.
“Happy Pets”, una empresa de artículos para mascotas, observa quejas recurrentes sobre la durabilidad de los juguetes para perros que se venden en Amazon. Al ver una oportunidad, desarrollan una nueva línea de juguetes casi indestructibles, abordando directamente esta preocupación y mejorando significativamente la satisfacción del cliente.
La gestión del inventario
Saber qué está de moda y qué no puede afectar significativamente las decisiones de inventario. El scraping de Amazon permite a las empresas monitorear qué productos están volando de los estantes y cuáles languidecen, lo que permite una gestión de existencias más inteligente.
“The Book Nook”, una pequeña librería en línea, utiliza datos de Amazon para rastrear géneros y autores de tendencia. Esta información les permite abastecerse de títulos populares antes de las temporadas de mayor compra, lo que garantiza satisfacer la demanda sin tener un exceso de existencias.
Por qué elegir PromptCloud para servicios de web scraping personalizados
En PromptCloud, entendemos las complejidades y los desafíos del raspado de datos de Amazon. Con tecnología sólida y un equipo experto, ofrecemos soluciones de scraping de Amazon personalizadas que se adaptan a sus necesidades comerciales específicas. He aquí por qué PromptCloud se destaca:

- Cumplimiento y confiabilidad : navegar por los términos de uso de Amazon puede ser complicado. Nuestras prácticas de scraping están diseñadas para cumplir con las normas y ser éticas, lo que garantiza datos confiables sin correr el riesgo de que se prohíban cuentas.
- Escalabilidad : ya sea que sea una nueva empresa o una empresa establecida, nuestras soluciones escalables crecen con su negocio y manejan la extracción de datos desde unos pocos productos hasta millones.
- Extracción de datos personalizada : más allá de los datos genéricos, adaptamos nuestras soluciones de scraping para capturar los puntos de datos específicos cruciales para su estrategia comercial.
- Precisión y calidad de los datos : nuestros sofisticados procesos de limpieza y validación de datos garantizan que reciba datos precisos y procesables.
- Integración perfecta : entregamos datos extraídos en formatos que se integran perfectamente con sus sistemas existentes, ya sea para análisis, CRM o gestión de inventario.
En resumen
El scraping de Amazon ofrece una ventaja estratégica en el competitivo ámbito del comercio electrónico. Al aprovechar la gran cantidad de datos disponibles en Amazon, las empresas pueden tomar decisiones informadas que impulsen el crecimiento, mejoren la satisfacción del cliente y optimicen las operaciones. Con PromptCloud, libere todo el potencial de la extracción de datos de Amazon, transformando los datos en conocimientos prácticos y resultados comerciales tangibles.
Manténgase a la vanguardia en el juego del comercio electrónico con PromptCloud. Contáctenos hoy para explorar cómo podemos potenciar su negocio con soluciones personalizadas de scraping de Amazon. Póngase en contacto con nosotros en [email protected]
Preguntas frecuentes
¿Es legal realizar scraping en Amazon?
La legalidad de extraer datos de Amazon (o de cualquier sitio web, en realidad) depende de varios factores, incluido cómo se extraen, qué datos se extraen y qué pretende hacer con ellos. Aquí hay algunas consideraciones a tener en cuenta:
Términos de servicio de Amazon :
Los Términos de servicio (ToS) de Amazon abordan explícitamente la extracción de datos. Generalmente, Amazon prohíbe el scraping sin permiso explícito, como se describe en sus ToS. Es fundamental revisar estos términos detenidamente para comprender qué está permitido y qué no. La violación de estos términos podría dar lugar a acciones legales por parte de Amazon, incluida la prohibición del uso de sus servicios.
Archivo robots.txt :
Los sitios web utilizan el archivo robots.txt para indicar qué partes de su sitio pueden ser rastreadas por robots para ser indexadas por los motores de búsqueda. Si bien no es legalmente vinculante, respetar las instrucciones del archivo robots.txt se considera una buena práctica en la comunidad de web scraping. El archivo robots.txt de Amazon proporciona información sobre qué partes de su sitio prefieren que no sean eliminadas.
Leyes de derechos de autor :
Los datos extraídos de Amazon, especialmente las descripciones de productos, imágenes y reseñas, pueden estar sujetos a leyes de derechos de autor. El uso de estos datos sin permiso podría infringir los derechos de los titulares de los derechos de autor, lo que podría generar complicaciones legales.
Regulaciones de privacidad de datos :
Si los datos recopilados incluyen información personal, debe tener en cuenta las normas de privacidad de datos como el GDPR en la Unión Europea o la CCPA en California, que imponen reglas estrictas sobre la recopilación y el uso de datos personales.
Doctrina de uso legítimo :
En algunas jurisdicciones, la doctrina del “uso justo” podría permitir el scraping limitado con fines como investigación, comentarios o críticas, sin necesidad de permiso. Sin embargo, lo que constituye un uso legítimo puede variar y es recomendable consultar a un abogado si planea confiar en esta doctrina.
¿Qué es un raspador de Amazon?
Un raspador de Amazon es una herramienta o software diseñado para extraer datos del sitio web de Amazon mediante programación. Estas herramientas navegan por las páginas web de Amazon y recopilan sistemáticamente información como detalles del producto, precios, reseñas, calificaciones e información del vendedor. Luego, los datos extraídos generalmente se organizan y almacenan en un formato estructurado, como CSV, Excel o una base de datos, lo que los hace accesibles para su análisis o procesamiento posterior.
Propósito y casos de uso
Los scrapers de Amazon tienen varios propósitos, con aplicaciones que abarcan múltiples industrias y dominios. A continuación se muestran algunos casos de uso comunes:
- Análisis competitivo : las empresas utilizan Amazon Scraper para monitorear los precios de la competencia, las ofertas de productos y las reseñas de los clientes, lo que les permite ajustar sus estrategias en tiempo real.
- Investigación de mercado : al analizar las tendencias de los productos, la popularidad y los comentarios de los consumidores, las empresas pueden identificar brechas en el mercado y oportunidades para nuevos productos.
- Monitoreo de precios : los minoristas y las plataformas de comercio electrónico emplean el raspador de Amazon para rastrear los cambios de precios y las promociones, lo que permite estrategias de precios dinámicas.
- Agregación de reseñas : extraer reseñas de productos de Amazon ayuda a las empresas a recopilar información sobre la satisfacción del consumidor y la calidad del producto.
¿Amazon tiene anti scraping?
Sí, Amazon implementa varias medidas anti-scraping para proteger su sitio web y sus datos. Como una de las plataformas de comercio electrónico más grandes del mundo, Amazon posee grandes cantidades de datos valiosos, lo que la convierte en un objetivo principal para los esfuerzos de extracción de datos. Para mantener la integridad de su sitio y salvaguardar los datos, Amazon ha desarrollado varias técnicas para detectar y prevenir el web scraping no autorizado. Estas medidas incluyen:
- CAPTCHA : Amazon utiliza CAPTCHA (prueba pública de Turing completamente automatizada para diferenciar computadoras y humanos) para verificar que un usuario es un humano y no un bot. Esto puede interrumpir las actividades de scraping automatizadas al requerir entrada manual.
- Limitación de velocidad : Amazon monitorea la frecuencia de las solicitudes desde una única dirección IP y puede imponer límites de velocidad. Las tasas de solicitud excesivas pueden provocar bloqueos, prohibiendo temporal o permanentemente el acceso de la dirección IP al sitio.
- Análisis de agente de usuario : Amazon verifica la cadena de agente de usuario de las solicitudes entrantes, lo que identifica el tipo de dispositivo y navegador que realiza la solicitud. Las solicitudes con cadenas de agentes de usuario sospechosas o asociadas a bots se pueden bloquear o redirigir.
- Contenido dinámico y llamadas AJAX : gran parte del contenido de Amazon se carga dinámicamente utilizando JavaScript y llamadas AJAX, lo que lo hace más desafiante para los robots de scraping simples que solo pueden analizar contenido HTML estático.
- Acuerdos legales y términos de servicio : los Términos de servicio de Amazon incluyen cláusulas que restringen la extracción no autorizada del contenido de su sitio web. Se reservan el derecho de emprender acciones legales contra entidades que violen estos términos.
- Técnicas de ofuscación : Amazon puede emplear técnicas de ofuscación que dificultan la identificación de los patrones y estructuras dentro del código fuente HTML, lo que complica el proceso de extracción para los scrapers.
¿Cómo detecta Amazon el scraping?
Amazon emplea varias técnicas anti-scraping sofisticadas para detectar y prevenir actividades de raspado de datos no autorizadas en su plataforma. Estas medidas están diseñadas para proteger los datos del sitio web y garantizar que los recursos del servidor se utilicen de manera eficiente, atendiendo principalmente a usuarios genuinos en lugar de robots automatizados. A continuación se muestran algunas formas en las que Amazon puede detectar el scraping:
Patrones de acceso inusuales
Amazon monitorea patrones de acceso que se desvían del comportamiento de navegación humano típico. Esto puede incluir un volumen inusualmente alto de solicitudes desde una única dirección IP, acceder a varias páginas de productos en un período corto o consultar repetidamente la misma información.
Tasa de solicitudes
Los raspadores automatizados a menudo envían solicitudes a un ritmo mucho más rápido que lo que lo haría un humano. Amazon puede detectar esto monitoreando la frecuencia de las solicitudes provenientes de un único usuario o dirección IP en un período de tiempo determinado. Si la tasa de solicitudes excede un cierto umbral, se marca como posible actividad de scraping.
Agentes de usuario no estándar
Los scripts de raspado web pueden utilizar un agente de usuario no estándar o uno que esté comúnmente asociado con herramientas de raspado. Amazon puede detectar estos agentes de usuario y bloquearlos o desafiarlos con CAPTCHA.
Análisis de encabezado
Los servidores de Amazon pueden analizar los encabezados de las solicitudes entrantes. Los encabezados faltantes o inusuales que normalmente están presentes en solicitudes legítimas del navegador pueden indicar actividades de scraping automatizadas.
Análisis de comportamiento e interacción
Los usuarios genuinos interactúan con las páginas web de maneras predecibles, incluidos los movimientos del mouse, los clics y el tiempo que pasan en las páginas. Los scripts automatizados carecen de esta complejidad y pueden detectarse mediante algoritmos de análisis de comportamiento.
Desafíos CAPTCHA
Amazon puede presentar desafíos CAPTCHA cuando detecta actividad sospechosa. Los CAPTCHA están diseñados para que solo los humanos puedan resolverlos y pueden bloquear eficazmente las herramientas de scraping automatizadas.
Análisis de fuentes de tráfico
Los datos de referencia también se pueden utilizar para detectar scraping. Es posible que las herramientas automatizadas no tengan rutas de referencia legítimas (como desde un motor de búsqueda u otra página web de Amazon), lo que hace que sus solicitudes se destaquen.
Análisis de cuentas y cookies
Para operaciones que requieren una cuenta de Amazon, la plataforma puede analizar la actividad de la cuenta y la integridad de las cookies. El comportamiento sospechoso de la cuenta o las cookies faltantes o no válidas pueden desencadenar medidas anti-scraping.