
Amazon Scraping: revelando novas oportunidades para empresas de comércio eletrônico
Publicados: 2024-03-13No cenário em constante evolução do comércio eletrônico, os dados são a base da vantagem competitiva. Entre a infinidade de mercados online, a Amazon se destaca como um gigante, hospedando uma ampla gama de produtos, avaliações de clientes e estratégias de preços. Para empresas de comércio eletrônico que buscam prosperar, extrair dados publicamente disponíveis da Amazon não é apenas uma opção; é um imperativo estratégico. Neste blog, investigamos como a coleta de dados da Amazon pode desbloquear novas oportunidades para empresas de comércio eletrônico.

Fonte: www.brightdata.com
O poder dos dados da Amazon
O vasto repositório de listas de produtos, análises e dados de comportamento do consumidor da Amazon é uma mina de ouro para empresas de comércio eletrônico. Ao analisar estrategicamente esses dados, as empresas podem obter insights sobre tendências de mercado, dinâmica de preços, preferências dos clientes e estratégias competitivas. No entanto, navegar manualmente neste oceano de dados é impraticável. É aqui que entram em ação as ferramentas e serviços personalizados de web scraping.
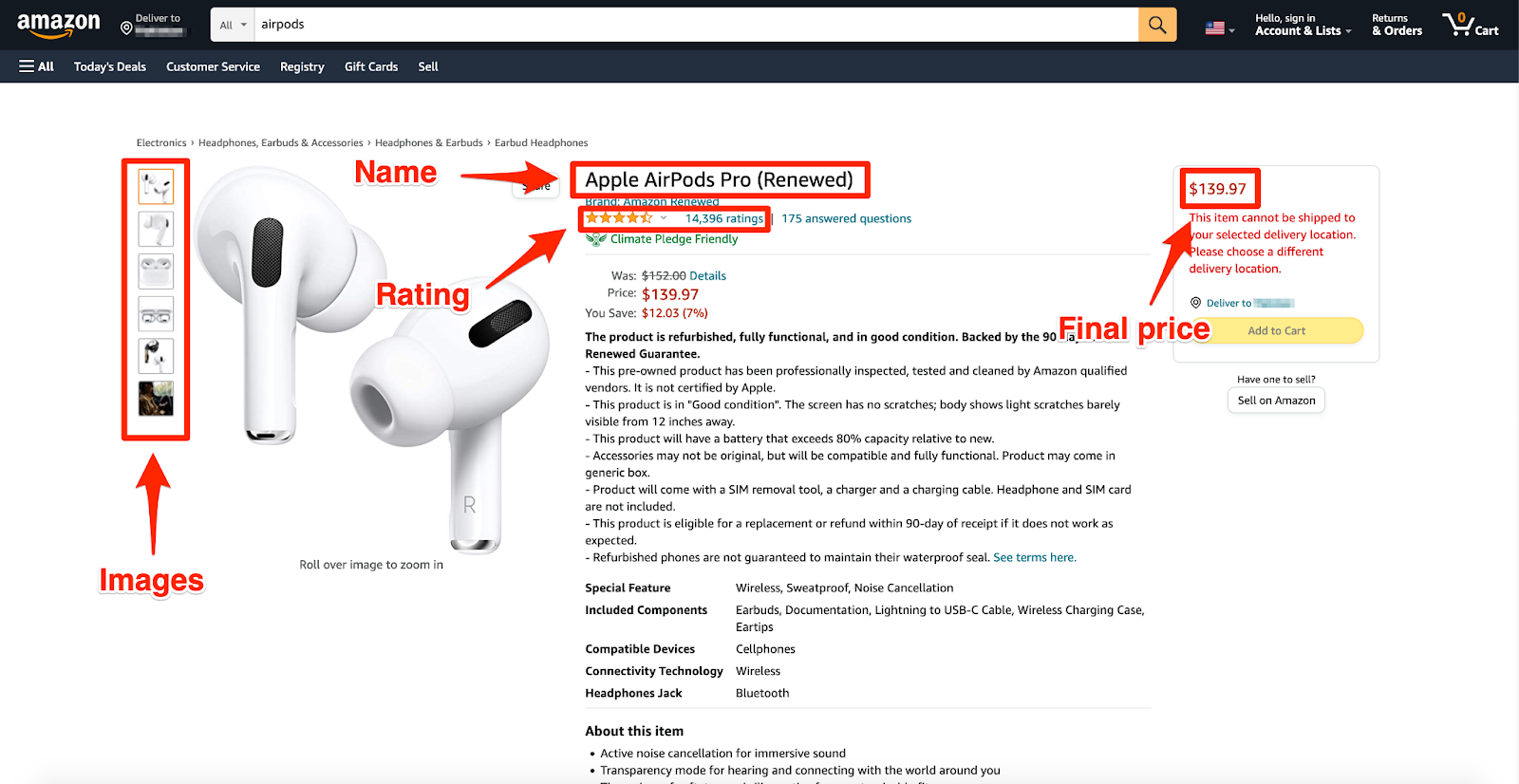
Como extrair dados de produtos da Amazon
Extrair dados de produtos da Amazon pode desbloquear insights valiosos para análise de mercado, inteligência competitiva e monitoramento de preços. No entanto, dada a natureza dinâmica da Amazon e as interfaces ricas baseadas em JavaScript, a extração desses dados requer uma abordagem estratégica. Aqui está um guia conciso sobre como extrair dados de produtos da Amazon de maneira eficaz.
Compreendendo a estrutura da Amazon
Antes de iniciar uma varredura, familiarize-se com a estrutura do site da Amazon, incluindo como os produtos são categorizados e como os URLs são formatados. Esse entendimento o ajudará a navegar no site de maneira programática e a direcionar a extração de dados com mais precisão.
Escolhendo as ferramentas certas
Para o ambiente rico em JavaScript da Amazon, considere usar ferramentas que possam renderizar JavaScript como um navegador real. Navegadores sem cabeça, como Puppeteer for Node.js ou Selenium WebDriver, são escolhas excelentes. Eles podem interagir com a página da web, permitindo que você copie conteúdo dinâmico carregado via JavaScript.
Lidando com paginação e conteúdo dinâmico
As listagens de produtos da Amazon são paginadas e geralmente carregadas de forma dinâmica. Seu script de scraping precisa lidar com a paginação de maneira eficaz, detectando e seguindo os links da página 'Próxima' ou manipulando os parâmetros de URL usados para paginação. Além disso, a implementação de esperas ou atrasos no seu script pode garantir que o conteúdo dinâmico seja totalmente carregado antes da extração.
Extraindo dados do produto
Com suas ferramentas configuradas e navegação controlada, concentre-se em extrair os dados específicos do produto que você precisa. Isso pode incluir nomes de produtos, preços, classificações e comentários. Usando os seletores CSS desses pontos de dados, você pode extrair o conteúdo usando a ferramenta de extração escolhida. Por exemplo, com o Puppeteer, você usaria métodos como page.evaluate() para recuperar o conteúdo de texto dos elementos que correspondem aos seus seletores.
Respeitando as políticas da Amazon
É crucial agir com responsabilidade, aderindo ao arquivo robots.txt e aos termos de serviço da Amazon. Certifique-se de que suas atividades de scraping não sobrecarreguem os servidores da Amazon; implementar práticas educadas de scraping, como limitação de taxa e usar um atraso de solicitação razoável, pode ajudar a mitigar o risco de bloqueio.
Desbloqueando oportunidades com Amazon Scraping
Fonte: www.scrapingbee.com
Analise competitiva
Na movimentada arena do comércio eletrônico, permanecer à frente significa ficar de olho na concorrência. Imagine ser capaz de dar uma olhada no manual do seu concorrente – entendendo não apenas o que eles vendem, mas como eles definem o preço de seus produtos e o que seus clientes estão dizendo. Esse é o poder da raspagem.
Considere a “Marca X”, uma startup que oferece produtos domésticos ecológicos. Ao vasculhar a Amazon, eles notaram uma lacuna em sabonetes biodegradáveis e acessíveis. Aproveitando essa percepção, a Marca X introduziu uma linha de alta qualidade e preços competitivos que rapidamente se tornou um best-seller, conquistando efetivamente um nicho em um mercado concorrido.
Otimização de preços
Na Amazon, o preço certo pode atrair clientes e aumentar as vendas, enquanto o preço errado pode afastá-los. Através da recolha estratégica, as empresas podem recolher dados sobre preços de um espectro de produtos, ajustando os seus próprios preços em tempo real para se manterem competitivas e apelativas aos consumidores.
“GadgetPro”, um varejista de eletrônicos, usa dados da Amazon para monitorar tendências de preços dos gadgets mais recentes. Quando percebem que um concorrente líder está reduzindo os preços dos smartwatches, a GadgetPro responde oferecendo um desconto por tempo limitado, retendo com sucesso o interesse do cliente e as vendas.
Detecção de tendências
Com milhões de transações diárias, a Amazon é uma mina de ouro para identificar tendências de consumo. A coleta de dados pode destacar quais produtos estão ganhando popularidade, permitindo que as empresas adotem essas tendências antecipadamente.
“Fashion Forward”, uma boutique de roupas online, identifica um aumento repentino nas pesquisas por “moda sustentável” na Amazon. Adaptando-se rapidamente, expandem a sua linha de vestuário ecológico, posicionando-se como criadores de tendências em sustentabilidade.
Melhorando a experiência do cliente
As avaliações da Amazon são mais do que apenas feedback; eles são uma linha direta com os desejos e necessidades do cliente. Ao analisar essas avaliações, as empresas podem identificar exatamente o que encanta os clientes ou os afasta e, em seguida, ajustar-se de acordo.
“Happy Pets”, uma empresa de suprimentos para animais de estimação, percebe reclamações recorrentes sobre a durabilidade dos brinquedos para cães vendidos na Amazon. Vendo uma oportunidade, eles desenvolvem uma nova linha de brinquedos quase indestrutíveis, abordando diretamente esta preocupação e melhorando significativamente a satisfação do cliente.
Gestão de inventário
Saber o que é interessante e o que não é pode impactar significativamente as decisões de inventário. A raspagem da Amazon permite que as empresas monitorem quais produtos estão saindo das prateleiras e quais estão definhando, permitindo um gerenciamento de estoque mais inteligente.
“The Book Nook”, uma pequena livraria online, usa dados da Amazon para rastrear gêneros e autores em alta. Essa percepção permite que eles estoquem títulos populares antes dos períodos de pico de compras, garantindo que atendam à demanda sem excesso de estoque.
Por que escolher PromptCloud para serviços personalizados de Web Scraping
Na PromptCloud, entendemos as complexidades e os desafios da coleta de dados da Amazon. Com tecnologia robusta e uma equipe especializada, oferecemos soluções personalizadas de raspagem da Amazon que atendem às suas necessidades comerciais específicas. Veja por que o PromptCloud se destaca:

- Conformidade e confiabilidade : navegar pelos termos de uso da Amazon pode ser complicado. Nossas práticas de scraping são projetadas para serem compatíveis e éticas, garantindo dados confiáveis sem risco de banimento de contas.
- Escalabilidade : seja você uma startup ou uma empresa estabelecida, nossas soluções escaláveis crescem junto com seus negócios, lidando com a extração de dados de alguns produtos até milhões.
- Extração de dados personalizada : além dos dados genéricos, adaptamos nossas soluções de raspagem para capturar os pontos de dados específicos cruciais para sua estratégia de negócios.
- Precisão e qualidade dos dados : Nossos sofisticados processos de limpeza e validação de dados garantem que você receba dados precisos e acionáveis.
- Integração perfeita : entregamos dados extraídos em formatos que se integram perfeitamente aos seus sistemas existentes, seja para análise, CRM ou gerenciamento de inventário.
Resumindo
A raspagem da Amazon oferece uma vantagem estratégica na arena competitiva do comércio eletrônico. Ao aproveitar a riqueza de dados disponíveis na Amazon, as empresas podem tomar decisões informadas que impulsionam o crescimento, aumentam a satisfação do cliente e otimizam as operações. Com o PromptCloud, libere todo o potencial da coleta de dados da Amazon, transformando dados em insights acionáveis e resultados de negócios tangíveis.
Fique à frente no jogo do comércio eletrônico com o PromptCloud. Contate-nos hoje para explorar como podemos capacitar seu negócio com soluções personalizadas de scraping da Amazon. Entre em contato conosco em [email protected]
perguntas frequentes
É legal raspar da Amazon?
A legalidade da coleta de dados da Amazon – ou de qualquer site, nesse caso – depende de vários fatores, incluindo como você coleta, quais dados você coleta e o que pretende fazer com os dados. Aqui estão algumas considerações a serem lembradas:
Termos de serviço da Amazon :
Os Termos de Serviço (ToS) da Amazon abordam explicitamente a coleta de dados. Geralmente, a Amazon proíbe a raspagem sem permissão explícita, conforme descrito em seus ToS. É crucial revisar esses termos cuidadosamente para entender o que é permitido e o que não é. A violação desses termos pode resultar em ação legal por parte da Amazon, incluindo a proibição de usar seus serviços.
Arquivo robots.txt :
Os sites usam o arquivo robots.txt para indicar quais partes do site podem ser rastreadas por bots para indexação pelos mecanismos de pesquisa. Embora não seja juridicamente vinculativo, respeitar as instruções no robots.txt é considerado uma boa prática na comunidade de web scraping. O arquivo robots.txt da Amazon fornece informações sobre quais partes do site eles preferem que não sejam copiadas.
Leis de direitos autorais :
Os dados extraídos da Amazon, especialmente descrições de produtos, imagens e avaliações, podem estar sujeitos a leis de direitos autorais. A utilização destes dados sem autorização pode infringir os direitos dos detentores dos direitos de autor, podendo levar a complicações jurídicas.
Regulamentos de privacidade de dados :
Se os seus dados extraídos incluírem informações pessoais, você deve estar atento aos regulamentos de privacidade de dados, como o GDPR na União Europeia ou o CCPA na Califórnia, que impõem regras rígidas sobre a coleta e uso de dados pessoais.
Doutrina de Uso Justo :
Em algumas jurisdições, a doutrina do “uso justo” pode permitir a extração limitada para fins como pesquisa, comentários ou crítica, sem a necessidade de permissão. No entanto, o que constitui uso justo pode variar e é aconselhável consultar um advogado se você planeja confiar nesta doutrina.
O que é um raspador Amazon?
Um raspador da Amazon é uma ferramenta ou software projetado para extrair dados do site da Amazon de forma programática. Essas ferramentas navegam pelas páginas da Amazon, coletando sistematicamente informações como detalhes de produtos, preços, avaliações, classificações e informações do vendedor. Os dados extraídos são normalmente organizados e armazenados em um formato estruturado, como CSV, Excel ou banco de dados, tornando-os acessíveis para análise ou processamento posterior.
Finalidade e casos de uso
Os scrapers da Amazon atendem a vários propósitos, com aplicações abrangendo vários setores e domínios. Aqui estão alguns casos de uso comuns:
- Análise competitiva : as empresas usam o Amazon Scraper para monitorar preços de concorrentes, ofertas de produtos e avaliações de clientes, permitindo-lhes ajustar suas estratégias em tempo real.
- Pesquisa de mercado : Ao analisar tendências de produtos, popularidade e feedback dos consumidores, as empresas podem identificar lacunas de mercado e oportunidades para novos produtos.
- Monitoramento de preços : varejistas e plataformas de comércio eletrônico empregam o raspador da Amazon para rastrear alterações e promoções de preços, permitindo estratégias de preços dinâmicas.
- Agregação de avaliações : extrair análises de produtos da Amazon ajuda as empresas a coletar insights sobre a satisfação do consumidor e a qualidade do produto.
A Amazon tem anti-raspagem?
Sim, a Amazon implementa várias medidas anti-raspagem para proteger seu site e seus dados. Como uma das maiores plataformas de comércio eletrônico do mundo, a Amazon detém grandes quantidades de dados valiosos, o que a torna um alvo principal para esforços de coleta de dados. Para manter a integridade do seu site e proteger os dados, a Amazon desenvolveu diversas técnicas para detectar e prevenir web scraping não autorizado. Essas medidas incluem:
- CAPTCHAs : a Amazon usa CAPTCHAs (teste de Turing Público Completamente Automatizado para diferenciar computadores e humanos) para verificar se um usuário é humano e não um bot. Isso pode interromper atividades automatizadas de scraping, exigindo entrada manual.
- Limitação de taxa : a Amazon monitora a frequência de solicitações de um único endereço IP e pode impor limites de taxa. Taxas de solicitação excessivas podem desencadear bloqueios, proibindo temporária ou permanentemente o endereço IP de acessar o site.
- Análise do agente do usuário : a Amazon verifica a string do agente do usuário das solicitações recebidas, que identifica o tipo de dispositivo e navegador que faz a solicitação. Solicitações com strings de agente de usuário suspeitas ou associadas a bots podem ser bloqueadas ou redirecionadas.
- Conteúdo dinâmico e chamadas AJAX : grande parte do conteúdo da Amazon é carregado dinamicamente usando chamadas JavaScript e AJAX, tornando-o mais desafiador para bots de scraping simples que só podem analisar conteúdo HTML estático.
- Acordos legais e termos de serviço : os termos de serviço da Amazon incluem cláusulas que restringem a extração não autorizada do conteúdo do site. Eles se reservam o direito de tomar medidas legais contra entidades que violem estes termos.
- Técnicas de ofuscação : a Amazon pode empregar técnicas de ofuscação que dificultam a identificação de padrões e estruturas no código-fonte HTML, complicando o processo de extração de scrapers.
Como a Amazon detecta scraping?
A Amazon emprega várias técnicas sofisticadas de anti-raspagem para detectar e prevenir atividades não autorizadas de raspagem de dados em sua plataforma. Estas medidas foram concebidas para proteger os dados do site e garantir que os recursos do servidor sejam utilizados de forma eficiente, servindo principalmente utilizadores genuínos em vez de bots automatizados. Aqui estão algumas maneiras pelas quais a Amazon pode detectar raspagem:
Padrões de acesso incomuns
A Amazon monitora padrões de acesso que divergem do comportamento típico de navegação humana. Isso pode incluir um volume incomumente alto de solicitações de um único endereço IP, acesso a várias páginas de produtos em um curto período ou consulta repetida das mesmas informações.
Taxa de solicitações
Scrapers automatizados geralmente enviam solicitações em uma taxa muito mais rápida do que um ser humano faria. A Amazon pode detectar isso monitorando a frequência de solicitações provenientes de um único usuário ou endereço IP em um determinado período. Se a taxa de solicitação exceder um determinado limite, ela será sinalizada como possível atividade de scraping.
Agentes de usuário não padrão
Os scripts de web scraping podem usar um agente de usuário não padrão ou comumente associado a ferramentas de scraping. A Amazon pode detectar esses agentes de usuário e bloqueá-los ou desafiá-los com CAPTCHAs.
Análise de cabeçalho
Os servidores da Amazon podem analisar os cabeçalhos das solicitações recebidas. Cabeçalhos ausentes ou incomuns que normalmente estão presentes em solicitações legítimas de navegadores podem sinalizar atividades automatizadas de raspagem.
Análise Comportamental e Interação
Os usuários genuínos interagem com as páginas da web de maneiras previsíveis, incluindo movimentos do mouse, cliques e tempo gasto nas páginas. Os scripts automatizados não possuem essa complexidade e podem ser detectados por meio de algoritmos de análise comportamental.
Desafios CAPTCHA
A Amazon pode apresentar desafios de CAPTCHA ao detectar atividades suspeitas. CAPTCHAs são projetados para serem resolvidos apenas por humanos e podem bloquear efetivamente ferramentas automatizadas de raspagem.
Analisando Fontes de Tráfego
Os dados de referência também podem ser usados para detectar raspagem. As ferramentas automatizadas podem não ter caminhos de referência legítimos (como um mecanismo de pesquisa ou outra página da Web na Amazon), fazendo com que suas solicitações se destaquem.
Análise de contas e cookies
Para operações que exigem uma conta Amazon, a plataforma pode analisar a atividade da conta e a integridade dos cookies. Comportamento suspeito da conta ou cookies ausentes/inválidos podem desencadear medidas anti-raspagem.