
Amazon Scraping: Neue Möglichkeiten für E-Commerce-Unternehmen erschließen
Veröffentlicht: 2024-03-13In der sich ständig weiterentwickelnden Landschaft des E-Commerce sind Daten der Grundstein für Wettbewerbsvorteile. Unter der Fülle an Online-Marktplätzen ist Amazon ein Riese, der ein umfangreiches Angebot an Produkten, Kundenrezensionen und Preisstrategien anbietet. Für E-Commerce-Unternehmen, die erfolgreich sein wollen, ist das Auslesen öffentlich verfügbarer Daten von Amazon nicht nur eine Option; Es ist eine strategische Notwendigkeit. In diesem Blog befassen wir uns damit, wie Amazon Data Scraping neue Möglichkeiten für E-Commerce-Unternehmen eröffnen kann.

Quelle: www.brightdata.com
Die Macht der Amazon-Daten
Amazons riesiger Fundus an Produktlisten, Rezensionen und Verbraucherverhaltensdaten ist eine Goldgrube für E-Commerce-Unternehmen. Durch die strategische Analyse dieser Daten können Unternehmen Einblicke in Markttrends, Preisdynamik, Kundenpräferenzen und Wettbewerbsstrategien gewinnen. Die manuelle Navigation in diesem Datenmeer ist jedoch unpraktisch. Hier kommen benutzerdefinierte Web-Scraping-Tools und -Dienste ins Spiel.
So durchsuchen Sie Amazon nach Produktdaten
Durch das Durchsuchen von Amazon nach Produktdaten können wertvolle Erkenntnisse für Marktanalysen, Wettbewerbsinformationen und Preisüberwachung gewonnen werden. Angesichts der Dynamik von Amazon und der umfangreichen JavaScript-basierten Schnittstellen erfordert die Extraktion dieser Daten jedoch einen strategischen Ansatz. Hier finden Sie eine kurze Anleitung, wie Sie Amazon effektiv nach Produktdaten durchsuchen können.
Die Struktur von Amazon verstehen
Machen Sie sich vor dem Einleiten eines Scrapings mit der Website-Struktur von Amazon vertraut, einschließlich der Kategorisierung von Produkten und der Formatierung von URLs. Dieses Verständnis wird Ihnen helfen, programmgesteuert auf der Website zu navigieren und Ihre Datenextraktion gezielter auszurichten.
Auswahl der richtigen Werkzeuge
Erwägen Sie für die JavaScript-reiche Umgebung von Amazon die Verwendung von Tools, die JavaScript wie einen echten Browser rendern können. Headless-Browser wie Puppeteer für Node.js oder Selenium WebDriver sind eine ausgezeichnete Wahl. Sie können mit der Webseite interagieren und Ihnen so das Scrapen dynamischer Inhalte ermöglichen, die über JavaScript geladen wurden.
Umgang mit Paginierung und dynamischen Inhalten
Amazon-Produktlisten sind paginiert und werden häufig dynamisch geladen. Ihr Scraping-Skript muss die Paginierung effektiv handhaben, indem es entweder „Nächste“-Seiten-Links erkennt und befolgt oder die für die Paginierung verwendeten URL-Parameter manipuliert. Darüber hinaus kann durch die Implementierung von Wartezeiten oder Verzögerungen in Ihrem Skript sichergestellt werden, dass dynamische Inhalte vor der Extraktion vollständig geladen werden.
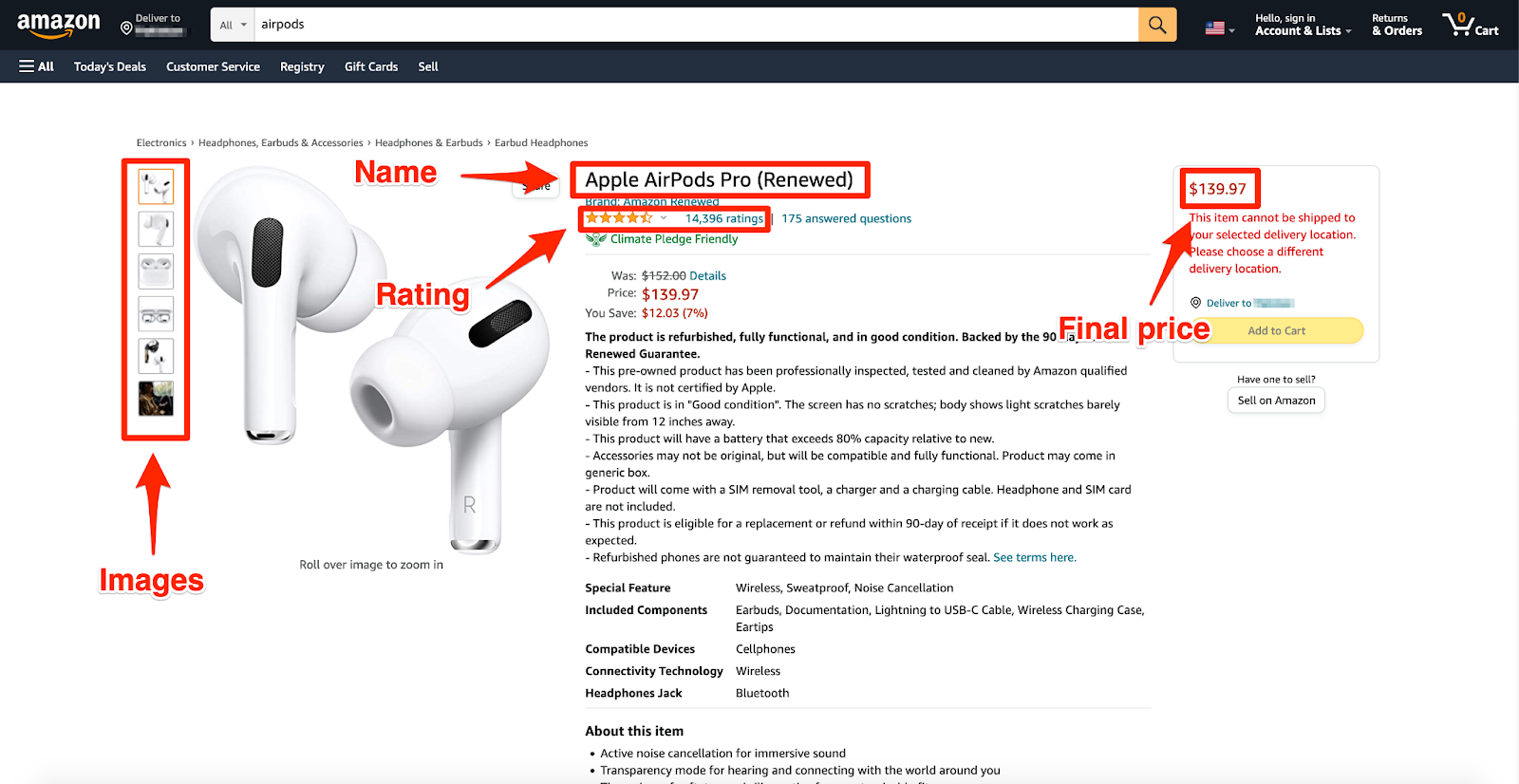
Produktdaten extrahieren
Nachdem Sie Ihre Tools eingerichtet und die Navigation verwaltet haben, können Sie sich darauf konzentrieren, die spezifischen Produktdaten zu extrahieren, die Sie benötigen. Dazu können Produktnamen, Preise, Bewertungen und Rezensionen gehören. Mithilfe der CSS-Selektoren dieser Datenpunkte können Sie den Inhalt mit dem von Ihnen gewählten Scraping-Tool extrahieren. Mit Puppeteer würden Sie beispielsweise Methoden wie page.evaluate() verwenden, um den Textinhalt von Elementen abzurufen, die Ihren Selektoren entsprechen.
Respektieren Sie die Richtlinien von Amazon
Es ist von entscheidender Bedeutung, verantwortungsvoll zu scrapen und sich an die robots.txt-Datei und die Nutzungsbedingungen von Amazon zu halten. Stellen Sie sicher, dass Ihre Scraping-Aktivitäten die Server von Amazon nicht überlasten. Die Implementierung höflicher Scraping-Praktiken wie Ratenbegrenzung und die Verwendung einer angemessenen Anforderungsverzögerung kann dazu beitragen, das Risiko einer Blockierung zu verringern.
Erschließen Sie Chancen mit Amazon Scraping
Quelle: www.scrapingbee.com
Wettbewerbsanalyse
Um im geschäftigen E-Commerce-Bereich die Nase vorn zu haben, muss man die Konkurrenz genau im Auge behalten. Stellen Sie sich vor, Sie könnten einen Blick in die Spielregeln Ihrer Konkurrenten werfen und nicht nur verstehen, was diese verkaufen, sondern auch, wie sie ihre Produkte bepreisen und was ihre Kunden sagen. Das ist die Kraft des Schabens.
Betrachten Sie „Brand X“, ein Startup, das umweltfreundliche Haushaltswaren anbietet. Als sie Amazon aussortierten, bemerkten sie eine Lücke bei erschwinglichen, biologisch abbaubaren Spülmitteln. Auf der Grundlage dieser Erkenntnisse führte Brand
Preisoptimierung
Bei Amazon kann der richtige Preis Kunden anziehen und den Umsatz steigern, während der falsche Preis sie abschrecken kann. Durch strategisches Scraping können Unternehmen Preisdaten für ein breites Produktspektrum sammeln und ihre eigenen Preise in Echtzeit anpassen, um wettbewerbsfähig und für Verbraucher attraktiv zu bleiben.
„GadgetPro“, ein Elektronikhändler, nutzt Amazon-Daten, um Preistrends für die neuesten Gadgets zu überwachen. Wenn sie bemerken, dass ein führender Konkurrent die Preise für Smartwatches senkt, reagiert GadgetPro mit einem zeitlich begrenzten Rabatt und bindet so erfolgreich das Kundeninteresse und den Umsatz.
Trenderkennung
Mit Millionen von Transaktionen täglich ist Amazon eine Goldgrube für die Erkennung von Verbrauchertrends. Mithilfe von Data Scraping können Sie erkennen, welche Produkte sich großer Beliebtheit erfreuen, sodass Unternehmen frühzeitig auf diese Trends zugreifen können.
„Fashion Forward“, eine Online-Bekleidungsboutique, stellt einen plötzlichen Anstieg der Suchanfragen nach „nachhaltiger Mode“ auf Amazon fest. Sie passen sich schnell an, erweitern ihr Sortiment an umweltfreundlicher Bekleidung und positionieren sich als Trendsetter in Sachen Nachhaltigkeit.
Verbesserung des Kundenerlebnisses
Amazon-Bewertungen sind mehr als nur Feedback; Sie sind der direkte Draht zu den Wünschen und Bedürfnissen des Kunden. Durch die Analyse dieser Bewertungen können Unternehmen genau feststellen, was Kunden begeistert oder abschreckt, und dann entsprechende Anpassungen vornehmen.
„Happy Pets“, ein Heimtierbedarfsunternehmen, bemerkt immer wieder Beschwerden über die Haltbarkeit von auf Amazon verkauften Hundespielzeugen. Als sie eine Chance sahen, entwickelten sie eine neue Linie nahezu unzerstörbarer Spielzeuge, die direkt auf dieses Problem eingeht und die Kundenzufriedenheit erheblich steigert.
Bestandsverwaltung
Zu wissen, was angesagt ist und was nicht, kann sich erheblich auf Bestandsentscheidungen auswirken. Mit Amazon Scraping können Unternehmen überwachen, welche Produkte aus den Regalen verschwinden und welche vergriffen sind, was eine intelligentere Lagerverwaltung ermöglicht.
„The Book Nook“, ein kleiner Online-Buchladen, nutzt Amazon-Daten, um angesagte Genres und Autoren zu verfolgen. Diese Erkenntnisse ermöglichen es ihnen, sich vor der Haupteinkaufssaison mit beliebten Titeln einzudecken und sicherzustellen, dass sie die Nachfrage ohne Überbestände decken.
Warum sollten Sie PromptCloud für benutzerdefinierte Web-Scraping-Dienste wählen?
Bei PromptCloud verstehen wir die Komplexität und Herausforderungen des Amazon Data Scraping. Mit robuster Technologie und einem Expertenteam bieten wir maßgeschneiderte Amazon-Scraping-Lösungen, die auf Ihre spezifischen Geschäftsanforderungen zugeschnitten sind. Darum zeichnet sich PromptCloud aus:

- Compliance und Zuverlässigkeit : Das Navigieren in den Nutzungsbedingungen von Amazon kann schwierig sein. Unsere Scraping-Praktiken sind auf Konformität und ethische Grundsätze ausgelegt und gewährleisten zuverlässige Daten, ohne dass das Risiko einer Kontosperrung besteht.
- Skalierbarkeit : Ganz gleich, ob Sie ein Startup oder ein etabliertes Unternehmen sind, unsere skalierbaren Lösungen wachsen mit Ihrem Unternehmen und übernehmen die Datenextraktion von wenigen Produkten bis hin zu Millionen.
- Maßgeschneiderte Datenextraktion : Über generische Daten hinaus passen wir unsere Scraping-Lösungen so an, dass sie die spezifischen Datenpunkte erfassen, die für Ihre Geschäftsstrategie entscheidend sind.
- Datengenauigkeit und -qualität : Unsere ausgefeilten Datenbereinigungs- und Validierungsprozesse stellen sicher, dass Sie genaue und umsetzbare Daten erhalten.
- Nahtlose Integration : Wir liefern extrahierte Daten in Formaten, die sich nahtlos in Ihre bestehenden Systeme integrieren lassen, sei es für Analysen, CRM oder Bestandsverwaltung.
In Summe
Amazon Scraping bietet einen strategischen Vorteil im wettbewerbsintensiven E-Commerce-Bereich. Durch die Nutzung der Fülle der auf Amazon verfügbaren Daten können Unternehmen fundierte Entscheidungen treffen, die das Wachstum vorantreiben, die Kundenzufriedenheit steigern und den Betrieb optimieren. Nutzen Sie mit PromptCloud das volle Potenzial des Amazon Data Scraping und wandeln Sie Daten in umsetzbare Erkenntnisse und greifbare Geschäftsergebnisse um.
Bleiben Sie mit PromptCloud im E-Commerce-Spiel vorne. Kontaktieren Sie uns noch heute, um herauszufinden, wie wir Ihr Unternehmen mit maßgeschneiderten Amazon-Scraping-Lösungen stärken können. Kontaktieren Sie uns unter [email protected]
Häufig gestellte Fragen
Ist es legal, bei Amazon zu kratzen?
Die Rechtmäßigkeit des Scrapings von Daten von Amazon – oder einer beliebigen anderen Website – hängt von verschiedenen Faktoren ab, unter anderem davon, wie Sie Scraping betreiben, welche Daten Sie Scraping betreiben und was Sie mit den Daten vorhaben. Hier sind einige Überlegungen, die Sie beachten sollten:
Nutzungsbedingungen von Amazon :
Die Nutzungsbedingungen (ToS) von Amazon beziehen sich ausdrücklich auf das Daten-Scraping. Generell verbietet Amazon das Scraping ohne ausdrückliche Genehmigung, wie in den AGB dargelegt. Es ist wichtig, diese Bedingungen sorgfältig zu lesen, um zu verstehen, was erlaubt ist und was nicht. Ein Verstoß gegen diese Bedingungen kann zu rechtlichen Schritten von Amazon führen, einschließlich eines Verbots der Nutzung ihrer Dienste.
robots.txt-Datei :
Websites verwenden die robots.txt-Datei, um anzugeben, welche Teile ihrer Website von Bots zur Indexierung durch Suchmaschinen gecrawlt werden können. Obwohl dies nicht rechtsverbindlich ist, gilt die Einhaltung der Anweisungen in robots.txt als bewährte Vorgehensweise in der Web-Scraping-Community. Die robots.txt-Datei von Amazon bietet Einblicke in die Teile ihrer Website, die sie lieber nicht entfernen möchten.
Urheberrechtsgesetze :
Von Amazon erfasste Daten, insbesondere Produktbeschreibungen, Bilder und Rezensionen, können dem Urheberrecht unterliegen. Die Verwendung dieser Daten ohne Genehmigung könnte die Rechte der Urheberrechtsinhaber verletzen und möglicherweise zu rechtlichen Komplikationen führen.
Datenschutzbestimmungen :
Wenn Ihre gescrapten Daten personenbezogene Daten enthalten, müssen Sie Datenschutzbestimmungen wie die DSGVO in der Europäischen Union oder die CCPA in Kalifornien beachten, die strenge Regeln für die Erhebung und Nutzung personenbezogener Daten vorschreiben.
Fair-Use-Doktrin :
In einigen Gerichtsbarkeiten erlaubt die „Fair Use“-Doktrin möglicherweise begrenztes Scraping für Zwecke wie Forschung, Kommentare oder Kritik, ohne dass eine Genehmigung erforderlich ist. Was eine faire Nutzung darstellt, kann jedoch unterschiedlich sein, und es ist ratsam, einen Rechtsbeistand zu konsultieren, wenn Sie vorhaben, sich auf diese Doktrin zu verlassen.
Was ist ein Amazon Scraper?
Ein Amazon-Scraper ist ein Tool oder eine Software, mit der Daten programmgesteuert von der Amazon-Website extrahiert werden können. Diese Tools navigieren durch die Webseiten von Amazon und sammeln systematisch Informationen wie Produktdetails, Preise, Rezensionen, Bewertungen und Verkäuferinformationen. Die extrahierten Daten werden dann typischerweise in einem strukturierten Format wie CSV, Excel oder einer Datenbank organisiert und gespeichert, sodass sie für die Analyse oder Weiterverarbeitung zugänglich sind.
Zweck und Anwendungsfälle
Amazon-Scraper dienen verschiedenen Zwecken, wobei sich die Anwendungen über mehrere Branchen und Domänen erstrecken. Hier sind einige häufige Anwendungsfälle:
- Wettbewerbsanalyse : Unternehmen nutzen Amazon Scraper, um die Preise der Wettbewerber, Produktangebote und Kundenbewertungen zu überwachen und so ihre Strategien in Echtzeit anzupassen.
- Marktforschung : Durch die Analyse von Produkttrends, Beliebtheit und Verbraucherfeedback können Unternehmen Marktlücken und Chancen für neue Produkte identifizieren.
- Preisüberwachung : Einzelhändler und E-Commerce-Plattformen nutzen Amazon Scraper, um Preisänderungen und Werbeaktionen zu verfolgen und so dynamische Preisstrategien zu ermöglichen.
- Bewertungsaggregation : Das Extrahieren von Produktbewertungen von Amazon hilft Unternehmen, Einblicke in die Kundenzufriedenheit und Produktqualität zu gewinnen.
Bietet Amazon Anti-Scraping?
Ja, Amazon implementiert verschiedene Anti-Scraping-Maßnahmen, um seine Website und Daten zu schützen. Als eine der größten E-Commerce-Plattformen weltweit verfügt Amazon über riesige Mengen wertvoller Daten und ist damit ein Hauptziel für Data-Scraping-Bemühungen. Um die Integrität seiner Website zu wahren und die Daten zu schützen, hat Amazon verschiedene Techniken entwickelt, um unbefugtes Web Scraping zu erkennen und zu verhindern. Zu diesen Maßnahmen gehören:
- CAPTCHAs : Amazon verwendet CAPTCHAs (vollständig automatisierter öffentlicher Turing-Test zur Unterscheidung von Computern und Menschen), um zu überprüfen, ob ein Benutzer ein Mensch und kein Bot ist. Dies kann automatisierte Scraping-Aktivitäten unterbrechen, da manuelle Eingaben erforderlich sind.
- Ratenbegrenzung : Amazon überwacht die Häufigkeit von Anfragen von einer einzelnen IP-Adresse und kann Ratenbegrenzungen festlegen. Überhöhte Anfrageraten können Sperren auslösen und der IP-Adresse vorübergehend oder dauerhaft den Zugriff auf die Website verbieten.
- User-Agent-Analyse : Amazon überprüft die User-Agent-Zeichenfolge eingehender Anfragen, die den Gerätetyp und Browser identifiziert, der die Anfrage stellt. Anfragen mit verdächtigen oder Bot-assoziierten User-Agent-Strings können blockiert oder umgeleitet werden.
- Dynamische Inhalte und AJAX-Aufrufe : Ein Großteil der Amazon-Inhalte wird dynamisch mithilfe von JavaScript- und AJAX-Aufrufen geladen, was es für einfache Scraping-Bots, die nur statische HTML-Inhalte analysieren können, schwieriger macht.
- Rechtliche Vereinbarungen und Nutzungsbedingungen : Die Nutzungsbedingungen von Amazon enthalten Klauseln, die das unbefugte Scraping ihrer Website-Inhalte verhindern. Sie behalten sich das Recht vor, rechtliche Schritte gegen Unternehmen einzuleiten, die gegen diese Bedingungen verstoßen.
- Verschleierungstechniken : Amazon setzt möglicherweise Verschleierungstechniken ein, die es schwieriger machen, die Muster und Strukturen im HTML-Quellcode zu identifizieren, was den Extraktionsprozess für Scraper erschwert.
Wie erkennt Amazon Scraping?
Amazon setzt mehrere hochentwickelte Anti-Scraping-Techniken ein, um unbefugte Data-Scraping-Aktivitäten auf seiner Plattform zu erkennen und zu verhindern. Diese Maßnahmen sollen die Daten der Website schützen und sicherstellen, dass die Serverressourcen effizient genutzt werden und in erster Linie echte Benutzer und nicht automatisierte Bots bedienen. Hier sind einige Möglichkeiten, wie Amazon Scraping erkennen kann:
Ungewöhnliche Zugriffsmuster
Amazon überwacht Zugriffsmuster, die vom typischen menschlichen Surfverhalten abweichen. Dies kann eine ungewöhnlich hohe Anzahl von Anfragen von einer einzelnen IP-Adresse, den Zugriff auf mehrere Produktseiten in einem kurzen Zeitraum oder die wiederholte Abfrage derselben Informationen umfassen.
Rate der Anfragen
Automatisierte Scraper senden Anfragen oft viel schneller als ein Mensch. Amazon kann dies erkennen, indem es die Häufigkeit der Anfragen eines einzelnen Benutzers oder einer einzelnen IP-Adresse in einem bestimmten Zeitraum überwacht. Wenn die Anforderungsrate einen bestimmten Schwellenwert überschreitet, wird dies als potenzielle Scraping-Aktivität gekennzeichnet.
Nicht standardmäßige Benutzeragenten
Web-Scraping-Skripte verwenden möglicherweise einen nicht standardmäßigen Benutzeragenten oder einen, der üblicherweise mit Scraping-Tools in Verbindung gebracht wird. Amazon kann diese Benutzeragenten erkennen und sie mit CAPTCHAs blockieren oder herausfordern.
Header-Analyse
Die Server von Amazon können die Header eingehender Anfragen analysieren. Fehlende oder ungewöhnliche Header, die normalerweise in legitimen Browseranfragen vorhanden sind, können auf automatisierte Scraping-Aktivitäten hinweisen.
Verhaltensanalyse und Interaktion
Echte Benutzer interagieren auf vorhersehbare Weise mit Webseiten, einschließlich Mausbewegungen, Klicks und auf Seiten verbrachter Zeit. Automatisierten Skripten fehlt diese Komplexität und sie können durch Verhaltensanalysealgorithmen erkannt werden.
CAPTCHA-Herausforderungen
Amazon stellt möglicherweise CAPTCHA-Herausforderungen dar, wenn es verdächtige Aktivitäten erkennt. CAPTCHAs sind so konzipiert, dass sie nur von Menschen gelöst werden können und können automatisierte Scraping-Tools effektiv blockieren.
Analyse von Verkehrsquellen
Empfehlungsdaten können auch zur Erkennung von Scraping verwendet werden. Automatisierte Tools verfügen möglicherweise nicht über legitime Verweispfade (z. B. von einer Suchmaschine oder einer anderen Webseite bei Amazon), wodurch ihre Anfragen hervorstechen.
Konto- und Cookie-Analyse
Für Vorgänge, die ein Amazon-Konto erfordern, kann die Plattform die Kontoaktivität und die Cookie-Integrität analysieren. Verdächtiges Kontoverhalten oder fehlende/ungültige Cookies können Anti-Scraping-Maßnahmen auslösen.