
Amazon Scraping : ouvrir de nouvelles opportunités pour les entreprises de commerce électronique
Publié: 2024-03-13Dans le paysage en constante évolution du commerce électronique, les données constituent la pierre angulaire de l’avantage concurrentiel. Parmi la pléthore de marchés en ligne, Amazon constitue un géant, hébergeant une vaste gamme de produits, d’avis clients et de stratégies de tarification. Pour les entreprises de commerce électronique qui cherchent à prospérer, récupérer les données accessibles au public sur Amazon n’est pas seulement une option ; c'est un impératif stratégique. Dans ce blog, nous expliquons comment le grattage de données d'Amazon peut ouvrir de nouvelles opportunités pour les entreprises de commerce électronique.

Source : www.brightdata.com
La puissance des données Amazon
Le vaste référentiel d'Amazon de listes de produits, d'avis et de données sur le comportement des consommateurs est une mine d'or pour les entreprises de commerce électronique. En analysant stratégiquement ces données, les entreprises peuvent obtenir des informations sur les tendances du marché, la dynamique des prix, les préférences des clients et les stratégies concurrentielles. Cependant, naviguer manuellement dans cet océan de données n’est pas pratique. C’est là que les outils et services de web scraping personnalisés entrent en jeu.
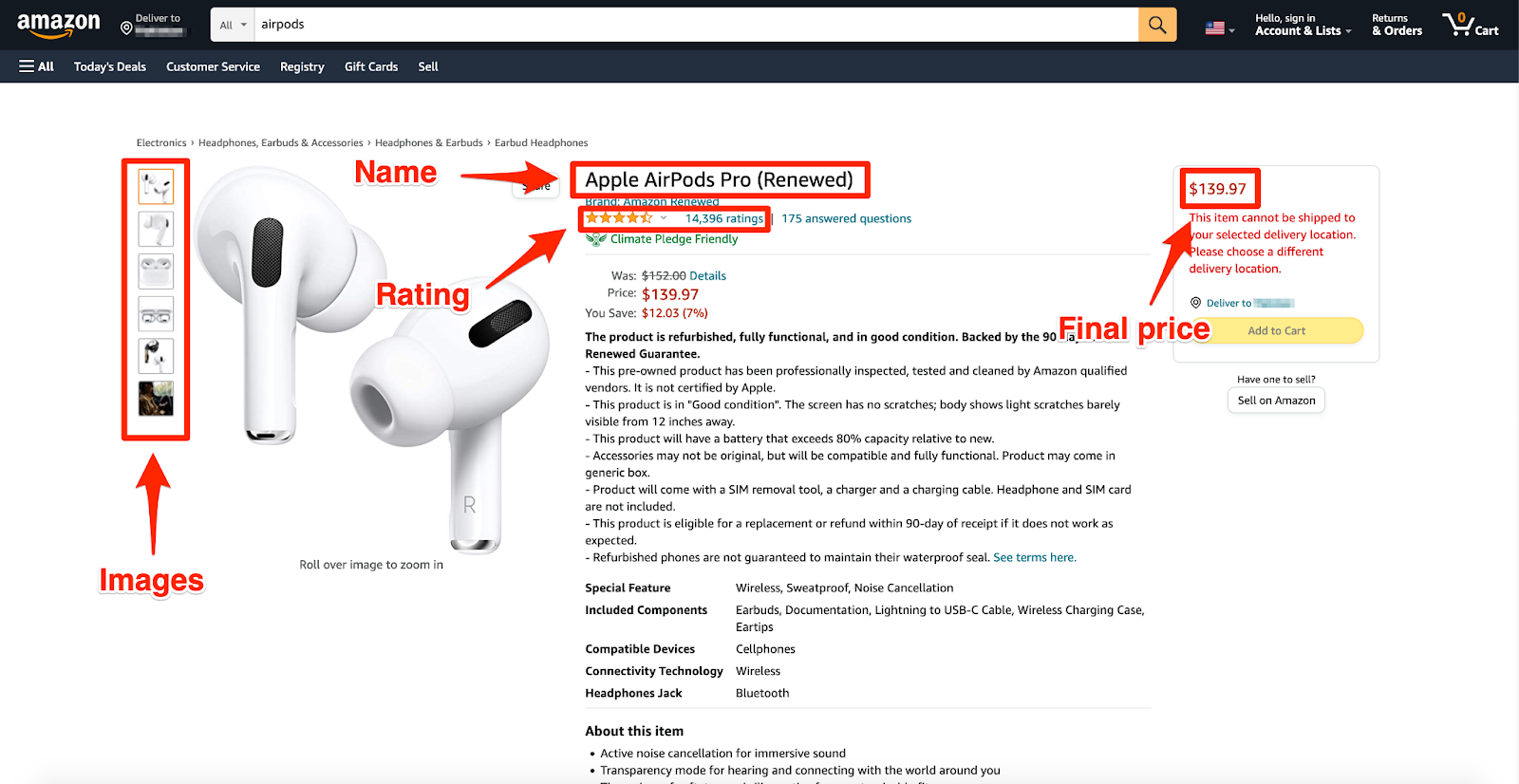
Comment récupérer Amazon pour les données produit
Récupérer des données sur les produits sur Amazon peut débloquer des informations précieuses pour l'analyse du marché, la veille concurrentielle et la surveillance des prix. Cependant, étant donné la nature dynamique d'Amazon et ses riches interfaces basées sur JavaScript, l'extraction de ces données nécessite une approche stratégique. Voici un guide concis sur la façon de récupérer efficacement les données produit d'Amazon.
Comprendre la structure d'Amazon
Avant de lancer une recherche, familiarisez-vous avec la structure du site Web d'Amazon, notamment la manière dont les produits sont classés et le format des URL. Cette compréhension vous aidera à naviguer sur le site par programmation et à cibler votre extraction de données avec plus de précision.
Choisir les bons outils
Pour l'environnement riche en JavaScript d'Amazon, envisagez d'utiliser des outils capables d'afficher JavaScript comme un vrai navigateur. Les navigateurs sans tête tels que Puppeteer pour Node.js ou Selenium WebDriver sont d'excellents choix. Ils peuvent interagir avec la page Web, vous permettant de récupérer le contenu dynamique chargé via JavaScript.
Gestion de la pagination et du contenu dynamique
Les listes de produits Amazon sont paginées et souvent chargées dynamiquement. Votre script de scraping doit gérer efficacement la pagination, soit en détectant et en suivant les liens de la page « Suivante », soit en manipulant les paramètres d'URL utilisés pour la pagination. De plus, la mise en œuvre d'attentes ou de retards dans votre script peut garantir que le contenu dynamique est entièrement chargé avant l'extraction.
Extraction des données produit
Une fois vos outils configurés et la navigation gérée, concentrez-vous sur l’extraction des données produit spécifiques dont vous avez besoin. Cela peut inclure les noms de produits, les prix, les notes et les avis. À l'aide des sélecteurs CSS de ces points de données, vous pouvez extraire le contenu à l'aide de l'outil de scraping de votre choix. Par exemple, avec Puppeteer, vous utiliserez des méthodes telles que page.evaluate() pour récupérer le contenu textuel des éléments correspondant à vos sélecteurs.
Respecter les politiques d'Amazon
Il est crucial d'agir de manière responsable en adhérant au fichier robots.txt et aux conditions de service d'Amazon. Assurez-vous que vos activités de scraping ne surchargent pas les serveurs d'Amazon ; la mise en œuvre de pratiques de scraping polies telles que la limitation du débit et l'utilisation d'un délai de demande raisonnable peuvent aider à atténuer le risque d'être bloqué.
Débloquer des opportunités avec Amazon Scraping
Source : www.scrapingbee.com
Analyse compétitive
Dans le domaine dynamique du commerce électronique, rester en tête signifie garder un œil attentif sur la concurrence. Imaginez pouvoir jeter un coup d'œil au manuel de vos concurrents : comprendre non seulement ce qu'ils vendent, mais aussi comment ils fixent le prix de leurs produits et ce que disent leurs clients. C'est le pouvoir du grattage.
Pensez à « Brand X », une startup proposant des articles pour la maison respectueux de l’environnement. En grattant Amazon, ils ont remarqué une lacune dans les savons à vaisselle biodégradables et abordables. Tirant parti de cette idée, la marque X a lancé une ligne de haute qualité à des prix compétitifs qui est rapidement devenue un best-seller, se taillant ainsi une niche sur un marché encombré.
Optimisation des prix
Sur Amazon, le bon prix peut attirer les clients et stimuler les ventes, tandis qu’un mauvais prix peut les faire fuir. Grâce au scraping stratégique, les entreprises peuvent collecter des données sur les prix d'un large éventail de produits, ajustant ainsi leurs propres prix en temps réel pour rester compétitives et attrayantes pour les consommateurs.
« GadgetPro », un détaillant d'électronique, utilise les données d'Amazon pour surveiller les tendances des prix des derniers gadgets. Lorsqu'ils remarquent qu'un concurrent majeur baisse les prix de leurs montres intelligentes, GadgetPro répond en offrant une remise à durée limitée, fidélisant ainsi l'intérêt des clients et les ventes.
Détection des tendances
Avec des millions de transactions quotidiennes, Amazon est une mine d’or pour repérer les tendances de consommation. L'extraction de données peut mettre en évidence les produits qui gagnent en popularité, permettant ainsi aux entreprises de réagir rapidement à ces tendances.
« Fashion Forward », une boutique de vêtements en ligne, identifie une augmentation soudaine des recherches de « mode durable » sur Amazon. S'adaptant rapidement, ils élargissent leur gamme de vêtements respectueux de l'environnement, se positionnant comme des pionniers en matière de durabilité.
Améliorer l'expérience client
Les avis Amazon sont plus que de simples commentaires ; ils constituent une ligne directe vers les désirs et les besoins du client. En analysant ces avis, les entreprises peuvent identifier exactement ce qui ravit les clients ou les éloigner, puis s'adapter en conséquence.
« Happy Pets », une entreprise de fournitures pour animaux de compagnie, remarque des plaintes récurrentes concernant la durabilité des jouets pour chiens vendus sur Amazon. Voyant une opportunité, ils développent une nouvelle gamme de jouets presque indestructibles, répondant directement à cette préoccupation et améliorant considérablement la satisfaction des clients.
Gestion de l'inventaire
Savoir ce qui est chaud et ce qui ne l'est pas peut avoir un impact significatif sur les décisions en matière d'inventaire. Le scraping d'Amazon permet aux entreprises de surveiller quels produits s'envolent des étagères et lesquels languissent, permettant une gestion des stocks plus intelligente.
« The Book Nook », une petite librairie en ligne, utilise les données d'Amazon pour suivre les genres et les auteurs tendances. Cette information leur permet de s'approvisionner en titres populaires avant les périodes de pointe d'achat, garantissant ainsi de répondre à la demande sans surstock.
Pourquoi choisir PromptCloud pour les services de Web Scraping personnalisés
Chez PromptCloud, nous comprenons les complexités et les défis du scraping de données Amazon. Grâce à une technologie robuste et à une équipe d'experts, nous proposons des solutions de scraping Amazon personnalisées qui répondent aux besoins spécifiques de votre entreprise. Voici pourquoi PromptCloud se démarque :

- Conformité et fiabilité : naviguer dans les conditions d'utilisation d'Amazon peut être délicat. Nos pratiques de scraping sont conçues pour être conformes et éthiques, garantissant des données fiables sans risquer l'interdiction de compte.
- Évolutivité : Que vous soyez une startup ou une entreprise établie, nos solutions évolutives évoluent avec votre entreprise, gérant l'extraction de données de quelques produits à des millions.
- Extraction de données personnalisée : au-delà des données génériques, nous adaptons nos solutions de scraping pour capturer les points de données spécifiques cruciaux pour votre stratégie commerciale.
- Exactitude et qualité des données : nos processus sophistiqués de nettoyage et de validation des données garantissent que vous recevez des données précises et exploitables.
- Intégration transparente : nous fournissons les données extraites dans des formats qui s'intègrent parfaitement à vos systèmes existants, que ce soit pour l'analyse, le CRM ou la gestion des stocks.
En résumé
Amazon scraping offre un avantage stratégique dans le domaine concurrentiel du commerce électronique. En tirant parti de la richesse des données disponibles sur Amazon, les entreprises peuvent prendre des décisions éclairées qui stimulent la croissance, améliorent la satisfaction des clients et optimisent leurs opérations. Avec PromptCloud, libérez tout le potentiel du data scraping d'Amazon, en transformant les données en informations exploitables et en résultats commerciaux tangibles.
Gardez une longueur d'avance dans le jeu du commerce électronique avec PromptCloud. Contactez-nous dès aujourd'hui pour découvrir comment nous pouvons donner à votre entreprise des solutions de scraping Amazon personnalisées. Contactez-nous à [email protected]
Questions fréquemment posées
Est-il légal de gratter sur Amazon ?
La légalité de la récupération de données sur Amazon – ou sur n'importe quel site Web, d'ailleurs – dépend de divers facteurs, notamment de la manière dont vous récupérez, des données que vous récupérez et de ce que vous avez l'intention de faire avec ces données. Voici quelques considérations à garder à l’esprit :
Conditions d'utilisation d'Amazon :
Les conditions de service (ToS) d'Amazon traitent explicitement du grattage de données. De manière générale, Amazon interdit le scraping sans autorisation explicite, comme indiqué dans ses conditions d'utilisation. Il est essentiel de lire attentivement ces termes pour comprendre ce qui est autorisé et ce qui ne l'est pas. La violation de ces conditions pourrait entraîner des poursuites judiciaires de la part d'Amazon, notamment l'interdiction d'utiliser leurs services.
Fichier robots.txt :
Les sites Web utilisent le fichier robots.txt pour indiquer quelles parties de leur site peuvent être explorées par des robots pour être indexées par les moteurs de recherche. Bien que cela ne soit pas juridiquement contraignant, le respect des instructions contenues dans le fichier robots.txt est considéré comme une bonne pratique dans la communauté du web scraping. Le fichier robots.txt d'Amazon fournit des informations sur les parties de leur site qu'ils préfèrent ne pas supprimer.
Lois sur le droit d'auteur :
Les données récupérées sur Amazon, en particulier les descriptions de produits, les images et les avis, peuvent être soumises aux lois sur les droits d'auteur. L'utilisation de ces données sans autorisation pourrait porter atteinte aux droits des titulaires des droits d'auteur, entraînant potentiellement des complications juridiques.
Règlement sur la confidentialité des données :
Si vos données récupérées incluent des informations personnelles, vous devez être conscient des réglementations sur la confidentialité des données telles que le RGPD dans l'Union européenne ou le CCPA en Californie, qui imposent des règles strictes sur la collecte et l'utilisation des données personnelles.
Doctrine de l'utilisation équitable :
Dans certaines juridictions, la doctrine de « l’utilisation équitable » peut autoriser une récupération limitée à des fins telles que la recherche, les commentaires ou la critique, sans avoir besoin d’autorisation. Cependant, ce qui constitue une utilisation équitable peut varier et il est conseillé de consulter un conseiller juridique si vous envisagez de vous appuyer sur cette doctrine.
Qu'est-ce qu'un grattoir Amazon ?
Un scraper Amazon est un outil ou un logiciel conçu pour extraire des données du site Web d'Amazon par programme. Ces outils parcourent les pages Web d'Amazon et collectent systématiquement des informations telles que les détails des produits, les prix, les avis, les notes et les informations sur le vendeur. Les données extraites sont ensuite généralement organisées et stockées dans un format structuré, tel que CSV, Excel ou une base de données, les rendant accessibles pour une analyse ou un traitement ultérieur.
Objectif et cas d'utilisation
Les scrapers Amazon servent à diverses fins, avec des applications couvrant plusieurs secteurs et domaines. Voici quelques cas d’utilisation courants :
- Analyse concurrentielle : les entreprises utilisent Amazon Scraper pour surveiller les prix des concurrents, les offres de produits et les avis des clients, leur permettant ainsi d'ajuster leurs stratégies en temps réel.
- Étude de marché : en analysant les tendances des produits, leur popularité et les commentaires des consommateurs, les entreprises peuvent identifier les lacunes du marché et les opportunités pour de nouveaux produits.
- Surveillance des prix : les détaillants et les plateformes de commerce électronique utilisent Amazon Scraper pour suivre les modifications de prix et les promotions, permettant ainsi des stratégies de tarification dynamiques.
- Agrégation d'avis : l'extraction d'avis sur les produits d'Amazon aide les entreprises à recueillir des informations sur la satisfaction des consommateurs et la qualité des produits.
Amazon a-t-il un anti-grattage ?
Oui, Amazon met en œuvre diverses mesures anti-scraping pour protéger son site Web et ses données. En tant que l'une des plus grandes plateformes de commerce électronique au monde, Amazon détient de grandes quantités de données précieuses, ce qui en fait une cible privilégiée pour les efforts de récupération de données. Pour maintenir l'intégrité de son site et protéger les données, Amazon a développé plusieurs techniques pour détecter et empêcher le web scraping non autorisé. Ces mesures comprennent :
- CAPTCHA : Amazon utilise des CAPTCHA (test de Turing public entièrement automatisé pour distinguer les ordinateurs des humains) pour vérifier qu'un utilisateur est humain et non un robot. Cela peut interrompre les activités de scraping automatisées en nécessitant une saisie manuelle.
- Limitation de débit : Amazon surveille la fréquence des requêtes provenant d'une seule adresse IP et peut imposer des limites de débit. Des taux de requêtes excessifs peuvent déclencher des blocages, interdisant temporairement ou définitivement à l’adresse IP d’accéder au site.
- Analyse de l'agent utilisateur : Amazon vérifie la chaîne de l'agent utilisateur des demandes entrantes, qui identifie le type d'appareil et de navigateur effectuant la demande. Les requêtes contenant des chaînes d'agent utilisateur suspectes ou associées à un robot peuvent être bloquées ou redirigées.
- Contenu dynamique et appels AJAX : une grande partie du contenu d'Amazon est chargée dynamiquement à l'aide d'appels JavaScript et AJAX, ce qui rend la tâche plus difficile pour les simples robots de scraping qui ne peuvent analyser que le contenu HTML statique.
- Accords juridiques et conditions de service : les conditions de service d'Amazon incluent des clauses qui restreignent la suppression non autorisée du contenu de leur site Web. Ils se réservent le droit d'intenter des poursuites judiciaires contre les entités qui violeraient ces conditions.
- Techniques d'obfuscation : Amazon peut utiliser des techniques d'obscurcissement qui rendent plus difficile l'identification des modèles et des structures dans le code source HTML, compliquant ainsi le processus d'extraction pour les scrapers.
Comment Amazon détecte-t-il le scraping ?
Amazon utilise plusieurs techniques anti-scraping sophistiquées pour détecter et empêcher les activités non autorisées de scraping de données sur sa plateforme. Ces mesures sont conçues pour protéger les données du site Web et garantir que les ressources du serveur sont utilisées efficacement, en servant principalement les utilisateurs authentiques plutôt que les robots automatisés. Voici quelques façons par lesquelles Amazon peut détecter le scraping :
Modèles d'accès inhabituels
Amazon surveille les modèles d'accès qui s'écartent du comportement de navigation humain typique. Cela peut inclure un volume inhabituellement élevé de requêtes provenant d’une seule adresse IP, l’accès à plusieurs pages de produits sur une courte période ou l’interrogation répétée des mêmes informations.
Taux de demandes
Les scrapers automatisés envoient souvent des requêtes à un rythme beaucoup plus rapide que ne le ferait un humain. Amazon peut le détecter en surveillant la fréquence des requêtes provenant d'un seul utilisateur ou d'une seule adresse IP au cours d'une période donnée. Si le taux de requêtes dépasse un certain seuil, il est signalé comme une activité de scraping potentielle.
Agents utilisateurs non standard
Les scripts de scraping Web peuvent utiliser un agent utilisateur non standard ou un agent couramment associé aux outils de scraping. Amazon peut détecter ces agents utilisateurs et les bloquer ou les contester avec des CAPTCHA.
Analyse d'en-tête
Les serveurs d'Amazon peuvent analyser les en-têtes des requêtes entrantes. Les en-têtes manquants ou inhabituels qui sont généralement présents dans les requêtes légitimes du navigateur peuvent signaler des activités de scraping automatisées.
Analyse comportementale et interaction
Les utilisateurs authentiques interagissent avec les pages Web de manière prévisible, notamment par les mouvements de la souris, les clics et le temps passé sur les pages. Les scripts automatisés n'ont pas cette complexité et peuvent être détectés grâce à des algorithmes d'analyse comportementale.
Défis CAPTCHA
Amazon peut présenter des défis CAPTCHA lorsqu'il détecte une activité suspecte. Les CAPTCHA sont conçus pour être résolus uniquement par des humains et peuvent bloquer efficacement les outils de scraping automatisés.
Analyser les sources de trafic
Les données de référence peuvent également être utilisées pour détecter le grattage. Les outils automatisés peuvent ne pas disposer de chemins de référence légitimes (comme à partir d'un moteur de recherche ou d'une autre page Web sur Amazon), ce qui fait que leurs demandes se démarquent.
Analyse des comptes et des cookies
Pour les opérations nécessitant un compte Amazon, la plateforme peut analyser l'activité du compte et l'intégrité des cookies. Un comportement de compte suspect ou des cookies manquants/invalides peuvent déclencher des mesures anti-scraping.