
Amazon Scraping: nuove opportunità per le aziende di e-commerce
Pubblicato: 2024-03-13Nel panorama in continua evoluzione dell’e-commerce, i dati sono la pietra angolare del vantaggio competitivo. Tra la pletora di mercati online, Amazon è un gigante, che ospita una vasta gamma di prodotti, recensioni dei clienti e strategie di prezzo. Per le aziende di e-commerce che desiderano prosperare, recuperare i dati disponibili al pubblico da Amazon non è solo un'opzione; è un imperativo strategico. In questo blog, approfondiamo come lo scraping dei dati di Amazon può sbloccare nuove opportunità per le attività di e-commerce.

Fonte: www.brightdata.com
Il potere dei dati di Amazon
Il vasto archivio di Amazon di elenchi di prodotti, recensioni e dati sul comportamento dei consumatori è una miniera d'oro per le aziende di e-commerce. Analizzando strategicamente questi dati, le aziende possono ottenere informazioni dettagliate sulle tendenze del mercato, sulle dinamiche dei prezzi, sulle preferenze dei clienti e sulle strategie competitive. Tuttavia, navigare manualmente in questo oceano di dati non è pratico. È qui che entrano in gioco strumenti e servizi di web scraping personalizzati.
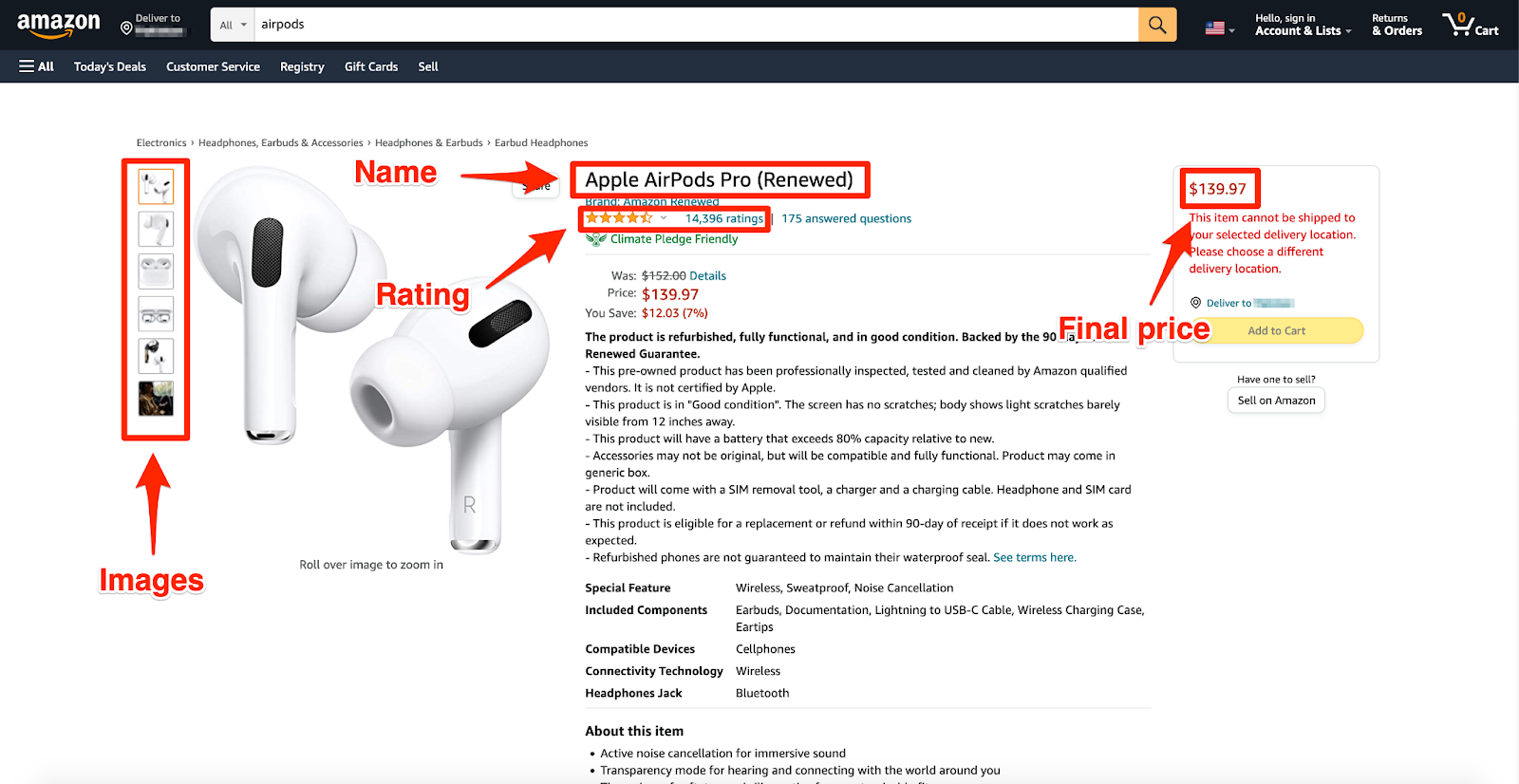
Come eseguire lo scraping di Amazon per i dati di prodotto
Recuperare i dati di prodotto da Amazon può sbloccare preziose informazioni per l'analisi di mercato, l'intelligence competitiva e il monitoraggio dei prezzi. Tuttavia, data la natura dinamica di Amazon e le ricche interfacce basate su JavaScript, l'estrazione di questi dati richiede un approccio strategico. Ecco una guida concisa su come recuperare in modo efficace i dati di prodotto da Amazon.
Comprendere la struttura di Amazon
Prima di avviare uno scraping, familiarizza con la struttura del sito Web di Amazon, compreso il modo in cui vengono classificati i prodotti e il modo in cui vengono formattati gli URL. Questa comprensione ti aiuterà a navigare nel sito in modo programmatico e a indirizzare l'estrazione dei dati in modo più accurato.
Scegliere gli strumenti giusti
Per l'ambiente ricco di JavaScript di Amazon, considera l'utilizzo di strumenti in grado di eseguire il rendering di JavaScript come un vero browser. I browser headless come Puppeteer for Node.js o Selenium WebDriver sono scelte eccellenti. Possono interagire con la pagina Web, consentendoti di recuperare contenuti dinamici caricati tramite JavaScript.
Gestione dell'impaginazione e dei contenuti dinamici
Gli elenchi dei prodotti Amazon sono impaginati e spesso caricati dinamicamente. Il tuo script di scraping deve gestire l'impaginazione in modo efficace, rilevando e seguendo i collegamenti alla pagina "Successiva" o manipolando i parametri URL utilizzati per l'impaginazione. Inoltre, l'implementazione di attese o ritardi nello script può garantire che il contenuto dinamico sia completamente caricato prima dell'estrazione.
Estrazione dei dati del prodotto
Una volta impostati gli strumenti e gestita la navigazione, concentrati sull'estrazione dei dati di prodotto specifici di cui hai bisogno. Ciò potrebbe includere nomi di prodotti, prezzi, valutazioni e recensioni. Utilizzando i selettori CSS di questi punti dati, puoi estrarre il contenuto utilizzando lo strumento di scraping scelto. Ad esempio, con Puppeteer, utilizzeresti metodi come page.evaluate() per recuperare il contenuto testuale degli elementi che corrispondono ai tuoi selettori.
Rispetto delle politiche di Amazon
È fondamentale procedere in modo responsabile aderendo al file robots.txt di Amazon e ai termini di servizio. Assicurati che le tue attività di scraping non sovraccarichino i server di Amazon; l'implementazione di pratiche di scraping educate come la limitazione della velocità e l'utilizzo di un ritardo ragionevole nelle richieste può aiutare a mitigare il rischio di essere bloccati.
Sbloccare le opportunità con Amazon Scraping
Fonte: www.scrapingbee.com
Analisi competitiva
Nella vivace arena dell’e-commerce, stare al passo significa tenere d’occhio la concorrenza. Immagina di poter sbirciare nel playbook del tuo concorrente, comprendendo non solo cosa vende, ma anche come fissano i prezzi dei suoi prodotti e cosa dicono i suoi clienti. Questo è il potere del raschiamento.
Considera "Brand X", una startup che offre prodotti per la casa ecologici. Raschiando Amazon, hanno notato una lacuna nei saponi per piatti convenienti e biodegradabili. Sfruttando questa intuizione, Brand X ha introdotto una linea di alta qualità a prezzi competitivi che è diventata rapidamente un bestseller, ritagliandosi di fatto una nicchia in un mercato affollato.
Ottimizzazione dei prezzi
Su Amazon, il prezzo giusto può attrarre clienti e incrementare le vendite, mentre il prezzo sbagliato può allontanarli. Attraverso lo scraping strategico, le aziende possono raccogliere dati sui prezzi di un’ampia gamma di prodotti, adeguando i propri prezzi in tempo reale per rimanere competitive e attraenti per i consumatori.
"GadgetPro", un rivenditore di elettronica, utilizza i dati di Amazon per monitorare le tendenze dei prezzi per gli ultimi gadget. Quando notano che un concorrente leader abbassa i prezzi sugli smartwatch, GadgetPro risponde offrendo uno sconto per un periodo limitato, mantenendo con successo l'interesse e le vendite dei clienti.
Individuazione delle tendenze
Con milioni di transazioni giornaliere, Amazon è una miniera d'oro per individuare le tendenze dei consumatori. Lo scraping dei dati può evidenziare quali prodotti stanno diventando sempre più popolari, consentendo alle aziende di cogliere tempestivamente queste tendenze.
“Fashion Forward”, una boutique di abbigliamento online, identifica un improvviso picco nelle ricerche di “moda sostenibile” su Amazon. Adattandosi rapidamente, espandono la loro linea di abbigliamento ecologico, posizionandosi come trendsetter nella sostenibilità.
Migliorare l'esperienza del cliente
Le recensioni di Amazon sono molto più che semplici feedback; sono una linea diretta con i desideri e le esigenze del cliente. Analizzando queste recensioni, le aziende possono individuare esattamente ciò che soddisfa i clienti o li allontana e quindi adeguarsi di conseguenza.
"Happy Pets", un'azienda di articoli per animali domestici, nota lamentele ricorrenti sulla durata dei giocattoli per cani venduti su Amazon. Vedendo un'opportunità, sviluppano una nuova linea di giocattoli quasi indistruttibili, affrontando direttamente questa preoccupazione e migliorando significativamente la soddisfazione del cliente.
Gestione delle scorte
Sapere cosa è interessante e cosa no può avere un impatto significativo sulle decisioni relative all'inventario. Lo scraping di Amazon consente alle aziende di monitorare quali prodotti stanno volando via dagli scaffali e quali stanno languendo, consentendo una gestione più intelligente delle scorte.
"The Book Nook", una piccola libreria online, utilizza i dati di Amazon per tracciare generi e autori di tendenza. Questa intuizione consente loro di fare scorta di titoli popolari prima delle stagioni di picco degli acquisti, garantendo di soddisfare la domanda senza eccedere nelle scorte.
Perché scegliere PromptCloud per servizi di web scraping personalizzati
Noi di PromptCloud comprendiamo le complessità e le sfide dello scraping dei dati di Amazon. Con una tecnologia solida e un team di esperti, offriamo soluzioni di scraping Amazon personalizzate che soddisfano le tue esigenze aziendali specifiche. Ecco perché PromptCloud si distingue:

- Conformità e affidabilità : orientarsi tra i termini di utilizzo di Amazon può essere complicato. Le nostre pratiche di scraping sono progettate per essere conformi ed etiche, garantendo dati affidabili senza rischiare il ban degli account.
- Scalabilità : che tu sia una startup o un'impresa consolidata, le nostre soluzioni scalabili crescono con la tua azienda, gestendo l'estrazione dei dati da pochi prodotti a milioni.
- Estrazione dati personalizzata : oltre ai dati generici, personalizziamo le nostre soluzioni di scraping per acquisire punti dati specifici cruciali per la tua strategia aziendale.
- Precisione e qualità dei dati : i nostri sofisticati processi di pulizia e convalida dei dati garantiscono la ricezione di dati accurati e utilizzabili.
- Integrazione perfetta : forniamo i dati estratti in formati che si integrano perfettamente con i tuoi sistemi esistenti, che si tratti di analisi, CRM o gestione dell'inventario.
In sintesi
Lo scraping di Amazon offre un vantaggio strategico nell’arena competitiva dell’e-commerce. Sfruttando la ricchezza di dati disponibili su Amazon, le aziende possono prendere decisioni informate che guidano la crescita, migliorano la soddisfazione dei clienti e ottimizzano le operazioni. Con PromptCloud, sblocca tutto il potenziale del data scraping di Amazon, trasformando i dati in informazioni fruibili e risultati aziendali tangibili.
Mantieni un vantaggio nel gioco dell'e-commerce con PromptCloud. Contattaci oggi per scoprire come possiamo potenziare la tua attività con soluzioni di scraping Amazon personalizzate. Mettiti in contatto con noi all'indirizzo [email protected]
Domande frequenti
È legale prelevare da Amazon?
La legalità dello scraping dei dati da Amazon, o da qualsiasi sito web, dipende da vari fattori, tra cui il modo in cui effettui lo scraping, quali dati raccogli e cosa intendi fare con i dati. Ecco alcune considerazioni da tenere a mente:
Termini di servizio di Amazon :
I Termini di servizio (ToS) di Amazon affrontano esplicitamente lo scraping dei dati. In generale, Amazon vieta lo scraping senza un permesso esplicito, come indicato nei propri ToS. È fondamentale rivedere attentamente questi termini per capire cosa è consentito e cosa no. La violazione di questi termini potrebbe comportare azioni legali da parte di Amazon, incluso il divieto di utilizzare i propri servizi.
File robots.txt :
I siti web utilizzano il file robots.txt per indicare quali parti del loro sito possono essere scansionate dai bot per l'indicizzazione da parte dei motori di ricerca. Sebbene non sia giuridicamente vincolante, il rispetto delle istruzioni contenute nel file robots.txt è considerato una buona pratica nella comunità del web scraping. Il file robots.txt di Amazon fornisce informazioni su quali parti del loro sito preferiscono non essere raschiate.
Leggi sul diritto d'autore :
I dati raccolti da Amazon, in particolare le descrizioni dei prodotti, le immagini e le recensioni, potrebbero essere soggetti alle leggi sul copyright. L'utilizzo di questi dati senza autorizzazione potrebbe violare i diritti dei titolari del copyright, portando potenzialmente a complicazioni legali.
Regolamento sulla privacy dei dati :
Se i tuoi dati raschiati includono informazioni personali, devi tenere presente le normative sulla privacy dei dati come il GDPR nell'Unione Europea o il CCPA in California, che impongono regole rigide sulla raccolta e l'utilizzo dei dati personali.
Dottrina del fair use :
In alcune giurisdizioni, la dottrina del “fair use” potrebbe consentire uno scraping limitato per scopi quali ricerca, commento o critica, senza bisogno di autorizzazione. Tuttavia, ciò che costituisce fair use può variare ed è consigliabile consultare un consulente legale se intendi fare affidamento su questa dottrina.
Cos'è un Amazon Scraper?
Uno scraper Amazon è uno strumento o un software progettato per estrarre dati dal sito Web di Amazon in modo programmatico. Questi strumenti navigano attraverso le pagine web di Amazon, raccogliendo sistematicamente informazioni come dettagli del prodotto, prezzi, recensioni, valutazioni e informazioni sul venditore. I dati estratti vengono quindi generalmente organizzati e archiviati in un formato strutturato, come CSV, Excel o un database, rendendoli accessibili per l'analisi o l'ulteriore elaborazione.
Scopo e casi d'uso
Gli scraper Amazon servono a vari scopi, con applicazioni che abbracciano più settori e domini. Ecco alcuni casi d'uso comuni:
- Analisi competitiva : le aziende utilizzano Amazon Scraper per monitorare i prezzi della concorrenza, le offerte di prodotti e le recensioni dei clienti, consentendo loro di adattare le proprie strategie in tempo reale.
- Ricerche di mercato : analizzando le tendenze dei prodotti, la popolarità e il feedback dei consumatori, le aziende possono identificare le lacune del mercato e le opportunità per nuovi prodotti.
- Monitoraggio dei prezzi : i rivenditori e le piattaforme di e-commerce utilizzano lo scraper Amazon per tenere traccia delle variazioni di prezzo e delle promozioni, consentendo strategie di prezzo dinamiche.
- Aggregazione delle recensioni : l'estrazione delle recensioni dei prodotti da Amazon aiuta le aziende a raccogliere informazioni sulla soddisfazione dei consumatori e sulla qualità dei prodotti.
Amazon ha l'anti raschiamento?
Sì, Amazon implementa varie misure anti-scraping per proteggere il proprio sito Web e i propri dati. Essendo una delle più grandi piattaforme di e-commerce a livello globale, Amazon detiene grandi quantità di dati preziosi, rendendolo un obiettivo primario per gli sforzi di data scraping. Per mantenere l'integrità del proprio sito e salvaguardare i dati, Amazon ha sviluppato diverse tecniche per rilevare e prevenire il web scraping non autorizzato. Queste misure includono:
- CAPTCHA : Amazon utilizza i CAPTCHA (test di Turing pubblico completamente automatizzato per distinguere computer e esseri umani) per verificare che un utente sia umano e non un bot. Ciò può interrompere le attività di scraping automatizzate richiedendo input manuali.
- Limitazione di velocità : Amazon monitora la frequenza delle richieste da un singolo indirizzo IP e può imporre limiti di velocità. Tassi di richiesta eccessivi possono innescare blocchi, vietando temporaneamente o permanentemente l'indirizzo IP dall'accesso al sito.
- Analisi user-agent : Amazon controlla la stringa user-agent delle richieste in entrata, che identifica il tipo di dispositivo e browser che effettua la richiesta. Le richieste con stringhe user-agent sospette o associate a bot possono essere bloccate o reindirizzate.
- Contenuti dinamici e chiamate AJAX : gran parte dei contenuti di Amazon viene caricata dinamicamente utilizzando chiamate JavaScript e AJAX, rendendolo più difficile per semplici bot di scraping che possono solo analizzare contenuti HTML statici.
- Accordi legali e Termini di servizio : i Termini di servizio di Amazon includono clausole che limitano lo scraping non autorizzato dei contenuti del loro sito web. Si riservano il diritto di intraprendere azioni legali contro entità che violano questi termini.
- Tecniche di offuscamento : Amazon può utilizzare tecniche di offuscamento che rendono più difficile identificare i modelli e le strutture all'interno del codice sorgente HTML, complicando il processo di estrazione per gli scraper.
In che modo Amazon rileva lo scraping?
Amazon utilizza diverse sofisticate tecniche anti-scraping per rilevare e prevenire attività di raschiamento dei dati non autorizzate sulla sua piattaforma. Queste misure sono progettate per proteggere i dati del sito Web e garantire che le risorse del server vengano utilizzate in modo efficiente, servendo principalmente utenti reali piuttosto che bot automatizzati. Ecco alcuni modi in cui Amazon può rilevare lo scraping:
Modelli di accesso insoliti
Amazon monitora i modelli di accesso che si discostano dal tipico comportamento di navigazione umana. Ciò può includere un volume insolitamente elevato di richieste da un singolo indirizzo IP, l'accesso a più pagine di prodotto in un breve periodo o l'interrogazione ripetuta delle stesse informazioni.
Tasso di richieste
Gli scraper automatizzati spesso inviano richieste a una velocità molto più rapida di quanto farebbe un essere umano. Amazon può rilevarlo monitorando la frequenza delle richieste provenienti da un singolo utente o indirizzo IP in un determinato intervallo di tempo. Se il tasso di richiesta supera una determinata soglia, viene contrassegnato come potenziale attività di scraping.
Agenti utente non standard
Gli script di web scraping potrebbero utilizzare un agente utente non standard o uno comunemente associato agli strumenti di scraping. Amazon può rilevare questi agenti utente e bloccarli o contestarli con CAPTCHA.
Analisi dell'intestazione
I server di Amazon possono analizzare le intestazioni delle richieste in entrata. Intestazioni mancanti o insolite tipicamente presenti nelle richieste legittime del browser possono segnalare attività di scraping automatizzate.
Analisi e interazione comportamentale
Gli utenti reali interagiscono con le pagine Web in modi prevedibili, inclusi i movimenti del mouse, i clic e il tempo trascorso sulle pagine. Gli script automatizzati non hanno questa complessità e possono essere rilevati tramite algoritmi di analisi comportamentale.
Sfide CAPTCHA
Amazon potrebbe presentare sfide CAPTCHA quando rileva attività sospette. I CAPTCHA sono progettati per essere risolvibili solo dagli esseri umani e possono bloccare efficacemente gli strumenti di scraping automatizzati.
Analisi delle fonti di traffico
I dati di riferimento possono essere utilizzati anche per rilevare lo scraping. Gli strumenti automatizzati potrebbero non avere percorsi di riferimento legittimi (come da un motore di ricerca o da un'altra pagina web su Amazon), facendo risaltare le loro richieste.
Analisi di account e cookie
Per le operazioni che richiedono un account Amazon, la piattaforma può analizzare l'attività dell'account e l'integrità dei cookie. Comportamenti sospetti dell'account o cookie mancanti/non validi possono attivare misure anti-scraping.