
Google検索コンソールで「重複、Googleはユーザーとは異なる正規を選択しました」を修正する方法
公開: 2022-02-11多くのウェブサイトは、SEOに適した方法で重複コンテンツを最適化できません。 実際、 Tomek Rudzkiの調査によると、重複コンテンツに関連するステータスは、あらゆるサイズのWebサイトでGoogle検索コンソールで2番目に一般的な問題です。
重複コンテンツのSEOの一般的な問題は、どのページバージョンがメインであるかについてGoogleがユーザーに同意しない場合です。 この場合、Google検索コンソールに「重複、Googleはユーザーとは異なる正規を選択しました」というステータスが表示される場合があります。
Googleのドキュメントには、「重複、Googleはユーザーとは異なる正規を選択した」と書かれています。
このページは一連のページに対して正規としてマークされていますが、Googleは別のURLの方が正規であると考えています。 Googleは、このページではなく、正規と見なすページのインデックスを作成しました。 このページを正規URLの複製として明示的にマークすることをお勧めします。 このページは、明示的なクロール要求なしで検出されました。 このURLを調べると、Googleが選択した正規URLが表示されます。出典: Google
Googleが意図したものとは異なるコンテンツをインデックスに登録した場合の結果は、個々のケースによって異なります。 最も深刻なのは、ユーザーがページにアクセスしたり、ページにとどまったりすることを思いとどまらせることです。たとえば、好みのバージョンに存在する重要な情報が欠落しているという結果を表示します。
この記事では、「重複、Googleがユーザーとは異なる正規を選択した」ステータスの考えられる原因と解決策を示します。
「重複、Googleはユーザーとは異なる正規を選択しました」ステータスはどこにありますか?
ページのステータスは、 Google検索コンソールのインデックスカバレッジレポートで確認できます。
Index Coverageレポートには、次の4つのグループの問題が含まれています。
- エラー、
- 警告付きで有効、
- 有効、
- 除外。
「重複、Googleはユーザーとは異なる正規を選択しました」は除外カテゴリに属します。 除外されたURLはインデックスに登録されず、Googleはそれが間違いであるとは考えていません。
[詳細]セクションのステータスをクリックすると、「重複、Googleはユーザーとは異なる正規を選択しました」と報告するURLのリストを表示できます。
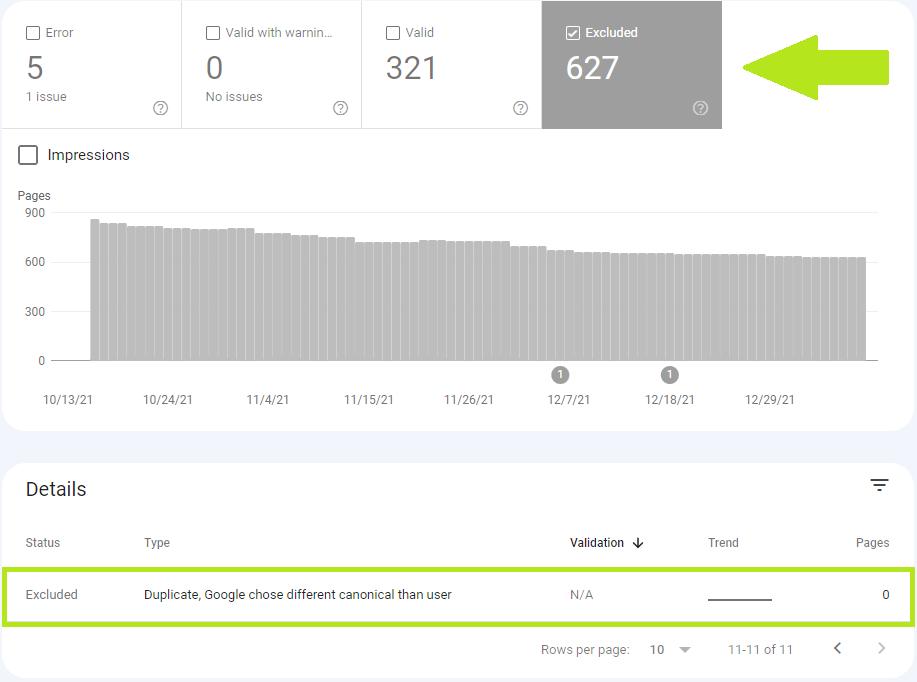
リストはエクスポートできますが、URLの制限は1000です。 ただし、複数のサイトマップがある場合は、サイトマップごとにレポートを個別にダウンロードして、エクスポートされるURLの数を増やすことができます。
Googleが正規のページとして選択したページを確認するにはどうすればよいですか?
「重複、Googleはユーザーとは異なる正規を選択しました」ステータスでは、Googleが選択したページは表示されません。 あなたが見ることができるのは、それがあなたが索引付けしたいページとは異なるものであるということだけです。
Googleが選択したページを確認するには、 URL検査ツールに移動する必要があります。
確認したいURLを入力すると、カバレッジステータスなど、さまざまな情報が表示されます。 このオプションを展開すると、Googleが選択した正規およびユーザーが宣言した正規を表示できます。
URLインスペクションAPIのおかげで、 URLインスペクションツールを使用して1日あたり最大2000のURLを一括チェックし、Googleが選択した正規情報に関する情報をJSONファイルで取得できるようになりました。
追加されたAPIアクセスは、ユーザーが選択したものとは異なる標準をGoogleが選択するのに苦労している人にとって非常に役立ちます。 APIがないと、URLの大規模なサンプルでGoogleが選択した正規ファイルを確認するのに非常に時間がかかります。
Googleはどのようにして正規ページを選択しますか?
Googleが正規ページを選択するために使用する方法に飛び込む前に、どのページが元のページであるかをGoogleが判断することが不可欠である理由を説明しましょう。
まず、 Googleのガイドラインでは、検索エンジンは「明確な情報を含むページのインデックス作成と表示に努めています。 そのため、重複するコンテンツに遭遇した後、ユーザーにとって最も有用であると特定した正規のコンテンツを選択します。 そうしないと、ユーザーには同じコンテンツにつながる多くの異なる結果が表示されます。
第二に、 Googleのドキュメントによると、 「重複は正規のページよりもクロールされる頻度が低い」とのことです。 これにより、Googleはより重要なページをクロールするためのリソースを節約し、サーバーのクロール負荷を軽減できます。
それでは、Googleが正規ページをどのように選択するかを見てみましょう。
2つの一般的なガイドラインに従って正規URLを選択しようとします。最初に、サイトが使用するように見えるURL 。 それで、サイトの好みは何ですか? 次に、ユーザーにとってどのURLがより役立つでしょうか。出典:ジョン・ミューラー
正規バージョンを決定するときにGoogleが確認するシグナルには、次のものがあります。
- 正規タグ、
- サイトマップ、
- 内部リンク構造、
- HTTPS over HTTPプロトコル、
- 見栄えの良いURL、
- リダイレクトします。
これらの要素は、インデックスに登録するページをGoogleが理解するのに役立つヒントです。 ただし、検索エンジンはそれらを尊重する義務はありません。
正規タグ
<link rel = "canonical" href = "https://example.com/original-page">正規タグは、<head>セクションに配置されるHTMLコードの一部です。 そのhref属性には、正規バージョンのページへのリンクが含まれています。 問題のページがコンテンツの重複した非正規バージョンである場合は、href属性に正規バージョンへのリンクを配置する必要があります。
ただし、自己参照の正規タグを追加することもできます。 自己参照ページには、href属性がそれ自体を指している正規タグが含まれています。 GoogleのSEO営業時間中、 John Muellerは、ページのバージョンが1つしかない場合でも、自己参照の正規タグを使用することを推奨しました。
この自己参照の正規を実行することをお勧めします。これにより、インデックスを作成するページ、またはインデックスを作成するときのURLが明確になります。1つのページがある場合でも、そのページをプルアップできるURLのバリエーションが異なる場合があります。 たとえば、最後にパラメータを使用すると、おそらく大文字またはwwwと非wwwを使用し、これらすべてをrel正規タグでクリーンアップできます。
出典:ジョン・ミューラー
サイトマップ
サイトマップは、サイト所有者としてインデックスを作成したいURLをリストした単純なテキストファイルです。 これは、検索エンジンボットへのロードマップとして機能し、最初にWebサイト全体をクロールすることなく、貴重なURLをすばやく見つけることができます。
サイトマップには、正規のURLのみを含める必要があります。 サイトマップ内に重複するページを配置すると、クロールの予算(GoogleがWebサイトでクロールできるURLの数)を浪費し、検索エンジンを混乱させる可能性があります。
ただし、サイトマップ内にURLを配置しても、検索エンジンがそのURLにインデックスを付けることは保証されません。 これは、あなたが最も気にかけているページを彼らが理解するのに役立つヒントにすぎません。 XMLサイトマップの究極のガイドでは、サイトマップの作成と最適化について詳しく知ることができます。
内部リンク
ページをリンクする方法は、検索エンジンがすべての価値のあるページを見つけて、それらの重要性を判断するのに役立ちます。
ページの価値が高いほど、より多くのリンクがそのページを指す必要があります。
2つの等しく価値のあるページがあると想像してみましょう。 それらの1つは、サイトマップからのみリンクされています。 もう1つはナビゲーションで簡単に見つけることができ、Webサイトの他のページからそれを指すリンクがあります。 この場合、Googleは、リンクのあるページの方がサイトマップでのみ見られるページよりも価値があると想定しています。
内部リンク構造は、Webサイトアーキテクチャと呼ばれるより複雑な問題の一部です。 それについてもっと知りたい場合は、サイトアーキテクチャに関する広範なガイドを読むことをお勧めします。このガイドでは、それが何であるか、およびWebサイトに最適なものを設計する方法について詳しく説明しています。
HTTPS over HTTP
HTTPは、サーバーとクライアント間のデータ転送を定義するプロトコルです。 HTTPSは、プロトコルの暗号化されたバージョンです。 追加されたセキュリティ層のおかげで、データ送信はより安全になり、データ操作のリスクはより小さくなります。
HTTPSはページのランキングに影響します。
HTTPバージョンとHTTPSバージョンの両方でアクセス可能なページがある場合、GoogleはHTTPSバージョンのインデックスを作成することを選択します。

見栄えの良いURL
URLは、ユーザーと検索エンジンの両方がページの内容を確認するのに役立ちます。 Webサイトの所有者は、URLがどのように表示されるかを制御できます。 John Muellerが言ったように、複数のURLが同じページにつながる場合、Googleは「見栄えの良いもの」を選択する可能性があります。
見栄えの良いURLとはどういう意味ですか? Googleは、「サイトのURL構造は可能な限りシンプルにする必要がある」と述べています。
2つのURLの例を見てみましょう。
- https://www.example.com/index.php?id_sezione=360&sid=sdr3bc
- https://www.example.com/summer/dress
2番目のURLは間違いなく「見栄えが良い」です。 これは、このページが短く、このページの内容を明確に示しているためです。 URL構造について詳しく知りたい場合は、SEOに適したURLを作成する方法に関する記事を読むことをお勧めします。
リダイレクト
301リダイレクトの使用は、サイト上の重複コンテンツを統合する方法の1つです。 ユーザーまたは検索エンジンボットがページにアクセスすると、自動的に新しいページにリダイレクトされます。
ページの1つのバージョンのみをWebサイトで利用できるようにしたい場合に使用できます。 たとえば、wwwバージョンとwww以外のバージョンがある場合は、301リダイレクトを使用して、どちらを使用可能にしてインデックスを作成するかを指定できます。
「重複、Googleはユーザーとは異なる正規を選択しました」ステータスの原因と解決策
場合によっては、ユーザーとは異なる正規URLを選択しても結果が得られないことがあります。 2つのページが同一である場合、Googleが選択したページは、選択したページと同じようにランク付けされる可能性があります。
しかし、チャンスは、あなたが理由のために正規のページを選んだということです。 ページが同一でない場合、Googleが選択したページにいくつかの重要な詳細が欠落している可能性があり、ユーザーがWebサイトにアクセスするのを思いとどまらせる可能性があります。
それでは、Googleが正規バージョンと問題を修正する方法についてあなたに同意しない可能性がある考えられる原因を見てみましょう。
Googleは、次のようなさまざまな理由で、ユーザーとは異なる正規のページを選択する場合があります。
- 一貫性のない信号、
- 一意のコンテンツを含まない自己参照型の正規タグ、
- レンダリングの問題、
- 同じ/類似した言語で異なる国をターゲットにします。
一貫性のない信号
「Googleはどのように正規ページを選択するのですか?」で述べたように章では、どのページが元のページであるかを示すために使用できる複数のシグナルがあります。 ただし、一貫性のない方法で使用すると、Googleが混乱し、インデックスに間違ったURLが選択される可能性があります。
3つの重複ページがある状況を想像してみましょう。
- すべてのページには、ページAを指す正規のタグがあります。
- ページBはサイトマップにあります。
- ページCには、それを指す最も多くの内部リンクがあります。
信号が競合する場合、 Googleはどのページが実際の正規のページであるかを推測する必要があります。
信号を明確にすると、信頼しやすくなります:)。 たとえば、内部リンク、サイトマップ、hreflang、rel-canonicalなどがすべて揃っている場合、推測することはあまりありません。 多くの場合、それはかなり一貫性がなく、選ぶのが難しいです。
—ジョン(個人)(@ JohnMu)2018年2月28日
解決
「重複、Googleはユーザーとは異なる正規を選択しました」というステータスのこの原因に対する1つの解決策があります。それは、一貫性を保つことです。
正規信号を設定する際に留意すべきいくつかのヒントを次に示します。
- 非正規のページやリダイレクトのあるページをサイトマップに配置しないでください。
- 内部リンクに一貫性があり、すべてのリンクが正規バージョンを指していることを確認してください。
- 標準タグは最終バージョンを指している必要があり、別のページにリダイレクトするページを含めないでください。
- 正規ループ(ページAにはページBを指す正規タグがあり、ページBにはページAを指す正規タグがあります)および正規チェーン(ページAにはページBを指す正規タグがあり、ページBには正規タグがあります)は避けてください。ページCを指す)。
一意のコンテンツを含まない自己参照の正規タグ
自己参照の正規タグを持つ複数のページがあり、Googleがそれらに一意の値が含まれていないと判断した場合、インデックスに登録するページは1つだけになる可能性があります。
これは通常、複数の製品が同じ説明を持っている場合にeコマースサイトで発生します。
同じベッドモデルをさまざまなサイズで販売している場合は、ユーザーが探しているものを簡単に見つけられるように、さまざまなサイズのすべてのページにインデックスを付けることができます。 結局のところ、彼らがキングサイズのベッドを探していて、検索結果に子供向けの小さなベッドしか表示されない場合、彼らはあなたのページを無視して、代わりに競合他社のWebサイトにアクセスする可能性があります。
誰かがあなたのページでこの重複した説明の中にあるテキストを検索している場合、このテキストはあなたのウェブサイトの一連のページで見つかったと認識し、おそらく1つか2つのページを選択しようとしますあなたのウェブサイトから表示します。出典:ジョン・ミューラー
解決
ページに独自のコンテンツを追加します。
自己参照の正規タグだけに依存しないでください。 代わりに、各ページに一意の値があることを確認してください。
John Muellerは、 GoogleのSEOオフィスアワー中に説明が重複する問題に対処しました。 彼は、製品が異なることを示す追加のテキスト情報を少なくともいくつか持っている必要があると述べました。
[…]商品の視覚的要素をカバーするテキストコンテンツがまったくない場合、検索結果にこれらを実際に適切に表示することは非常に困難になります。 […]これが私がここでとる角度です。説明の一部を複製しても問題ありません。 しかし、私は間違いなく、あなたが販売しているそれらの個々の製品に固有の視覚的要素についてのテキストを実際に持っている何かがそこにあることを確認します。
出典:ジョン・ミューラー
レンダリングの問題
検索エンジンはまだJavaScriptのレンダリングに完全ではありません。 したがって、コンテンツの表示に大きく依存している場合、Googleはページ上のすべての要素を表示する際に問題が発生する可能性があります。
レンダリングは、Googleや他の検索エンジンが当社のウェブサイトのコンテンツとレイアウトを見て理解するために不可欠です。 レンダリングしないと、コンテンツはオンラインに存在しません。 WebサイトのHTMLコードを調べるだけで、コンテンツを見ることができた時代は過ぎ去りました。出典: SEOマニフェストのレンダリング–JavaScriptSEOでは不十分な理由
Googleは、ページを一意にするコンテンツをレンダリングできないため、一部のページが重複していると見なす場合があります。
3つの固有のページがあるとします。 それぞれに自己参照の正規タグがあります。 JavaScriptはメインコンテンツを生成しますが、何らかの理由でGoogleはそれをレンダリングしません。 代わりに、すべてのページで同じである空のスペースとナビゲーションバーなどのいくつかの追加要素が表示されます。 Googleにとって、これらのページは重複しているように見えます。そのため、インデックスを作成するために1つだけを選択します。
Googleがページをどのようにレンダリングするかは、Google検索コンソールのURL検査ツールで確認できます。 このツールは、レンダリングされたページのスクリーンショットを提供します。これにより、Googleがページをどのように認識しているかについての洞察を得ることができます。 スクリーンショットにコンテンツがない場合は、レンダリングに問題がある可能性があることを示しています。
解決
まず、Googleが必要なすべてのスクリプトにアクセスできることを確認する必要があります。 JavaScriptリソースがrobots.txt (クロールできるページを指定するために作成できるファイル)によってブロックされていないことを確認してください。
リソースにGoogleがアクセスできる場合は、スクリプトを評価する必要があります。 スクリプトのサイズや、ページを生成するためにすべてが必要かどうかなどの側面を考慮する必要があります。
SEOのレンダリングのトピックは広範であり、コーディングの経験がない場合は、より複雑な問題のいくつかを解決するために開発者の助けが必要になる場合があります。 詳細については、トピックを詳細に説明したレンダリングSEOマニフェストをご覧ください。
同じ/類似した言語で異なる国をターゲットにする
同じまたは類似の言語を話す特定の国(たとえば、米国と英国)を対象とするページがある場合、Googleがインデックスに登録する国を1つだけ選択した可能性があります。
同じ言語でさまざまな国をターゲットにしていることを示すために使用する唯一のソリューションが、エルフ参照の正規タグであるとします。 その場合、Googleは目的を理解せず、これらはすべて重複したページであると考える可能性があります。 その結果、インデックスを作成するためにそれらの1つだけが選択され、ユーザーは検索結果でさまざまな国に特化したページを見つける可能性があります。
これは、顧客が購入できなくなる可能性があるため、eコマースサイトにとって特に大きな問題になる可能性があります。
解決
hreflangタグが適切に配置されていることを常に確認する必要があります。
hreflangタグは、ページがターゲットとする言語と国を指定するのに役立つHTMLコードの一部です。
<link rel = "alternate" hreflang = " en-gb " href = "https://en-gb.example.com/item"> <link rel = "alternate" hreflang = " en-us " href = "https://en-us.example.com/item">
hreflangタグを使用すると、言語(en –英語)だけでなく国(gb –英国、米国–米国)も指定できます。
もう1つできることは、コンテンツが翻訳されるだけでなく、ローカライズされていることを確認することです。 言語が同じであっても、国によって文化は異なります。 特定の国のユーザー向けにページを調整してください。 この方法は、顧客に優れたユーザーエクスペリエンスを提供するだけでなく、これらのページがユニークであることをGoogleに納得させる可能性もあります。
最後になりましたが、上記の手法が失敗した場合に備えて、バックアップ計画を立てておく必要があります。 ユーザーの場所に基づいて表示されるJavaScriptバナーを作成します。 たとえば、英国のユーザーが米国のバージョンを入力したことが検出された場合は、より適切なバージョンが提案され、顧客は自分の地域に指定されたページに滞在するか訪問するかを決定できます。
「重複、Googleはユーザーとは異なる正規を選択しました」vs.「重複して送信されたURLは正規として選択されていません」vs.「ユーザーが選択した正規を使用せずに重複」
「重複、Googleはユーザーとは異なる正規を選択しました」は、インデックスカバレッジレポートの2つの異なるステータスと簡単に混同される可能性があります。
- 「重複して送信されたURLが正規として選択されていません」および
- 「ユーザーが選択した正規情報なしで複製します。」
これらのステータスは同じことを示しています。Googleは正規ではないと考えているため、ページはインデックスに登録されていません。
違いは、Googleがページをどのように見つけたか、およびユーザーが正規タグを宣言したかどうかにあります。
それらの主な違いは、「重複、Googleはユーザーとは異なる正規を選択した」ということは、Googleが取得しなかった正規タグをすでに指定していることです。 対照的に、他の2つのステータスには、ユーザーが定義した正規のタグはありませんでした。
さらに、サイトマップで送信することにより、「正規として選択されていない重複した送信済みURL」を報告するURLをインデックスに登録するように明示的に要求しました。
まとめ
「重複、Googleはユーザーとは異なる正規のステータスを選択しました」というステータスが表示され、Googleがインデックスに登録する適切なページを選択しなかったと思われる場合は、優先ページにインデックスが作成される可能性を最大限に高めるためにできることがいくつかあります。
- 正規の信号を送信する際に一貫性を保つ:正規のページのみがサイトマップにあり、内部リンクがそれを指していることを確認します。
- 各ページに固有の値があることを確認してください。 商品ページの説明が同じ場合は、商品が異なることを示すテキストコンテンツを追加します。
- URLインスペクションツールでコンテンツが正しくレンダリングされることを確認します。
- コンテンツをさまざまな言語に翻訳するだけでなく、ターゲットとする特定の国にローカライズします。
- 複数の国を対象とするコンテンツには、常にhreflangタグを追加することを忘れないでください。