
Как исправить «Дубликат, Google выбрал другой канонический, чем пользователь» в Google Search Console
Опубликовано: 2022-02-11Многие веб-сайты не могут оптимизировать свой дублированный контент с точки зрения SEO. На самом деле, согласно исследованию Томека Рудзки, статусы, связанные с дублированием контента, являются второй наиболее распространенной проблемой в Google Search Console для веб-сайтов любого размера.
Распространенная проблема SEO с дублированием контента возникает, когда Google не соглашается с пользователями, какая версия страницы является основной. В этом случае вы можете увидеть статус «Дубликат, Google выбрал другой канонический, чем пользовательский» в Google Search Console.
Вот что говорится в документации Google о «Дубликате, Google выбрал другой канонический код, чем пользователь»:
Эта страница помечена как каноническая для набора страниц, но Google считает, что другой URL делает ее более канонической. Google проиндексировал страницу, которую мы считаем канонической, а не эту. Мы рекомендуем явно пометить эту страницу как дубликат канонического URL. Эта страница была обнаружена без явного запроса на сканирование. Проверка этого URL должна показать выбранный Google канонический URL.источник: Гугл
Последствия индексации Google другого контента, чем вы предполагали, зависят от отдельных случаев. Самая серьезная из них — отговорить пользователей от посещения или пребывания на вашей странице , показывая им результаты, в которых, например, отсутствует важная часть информации, присутствующая в предпочитаемой вами версии.
В этой статье показаны возможные причины и решения для статуса «Дубликат, Google выбрал другой канонический статус, чем пользовательский».
Где вы можете найти статус «Дубликат, Google выбрал другой канонический статус, чем пользовательский»?
Вы можете проверить статус своей страницы в отчете о покрытии индекса в Google Search Console.
Отчет о покрытии индекса включает четыре группы вопросов:
- Ошибка,
- Действительно с предупреждениями,
- Действительный,
- Исключенный.
«Дубликат, Google выбрал другой канонический, чем пользователь» относится к категории « Исключено ». Исключенные URL -адреса не индексируются, и Google не считает это ошибкой.
Вы можете увидеть список URL-адресов с сообщением «Дублируется, Google выбрал другой канонический, чем пользователь» после нажатия на статус в разделе «Подробности».
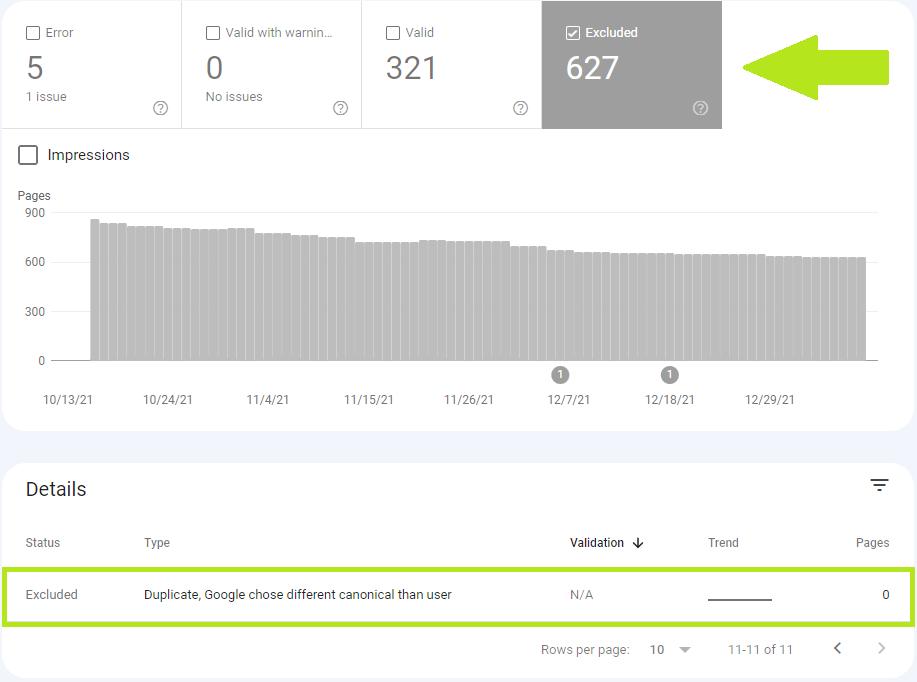
Список доступен для экспорта, но существует ограничение в 1000 URL-адресов. Однако если у вас более одной карты сайта, вы можете загрузить отчет для каждой карты сайта отдельно и увеличить количество экспортируемых URL-адресов.
Как проверить, какую страницу Google выбрал в качестве канонической?
Статус «Дубликат, Google выбрал другую каноническую, чем пользовательскую» не показывает, какую страницу выбрал Google. Все, что вы можете видеть, это то, что это не та страница, которую вы хотели проиндексировать.
Чтобы увидеть, какую страницу выбрал Google, вам нужно перейти к инструменту проверки URL.
После ввода URL-адреса, который вы хотите проверить, вы увидите много различной информации, включая статус покрытия. Вы можете развернуть эту опцию, чтобы увидеть канонический файл, выбранный Google, и канонический файл, объявленный пользователем.
Благодаря API проверки URL- адресов теперь вы можете массово проверять до 2000 URL-адресов в день с помощью инструмента проверки URL-адресов и получать информацию о выбранном Google каноническом файле в файле JSON.
Добавленный доступ к API очень полезен для тех, кто борется с тем, что Google выбирает другой канонический файл, чем выбранный пользователем. Без API проверка выбранных Google канонических ссылок на большой выборке URL-адресов занимает очень много времени.
Как Google выбирает каноническую страницу?
Прежде чем я перейду к методам, которые Google использует для выбора канонической страницы, позвольте мне объяснить, почему для Google важно определить, какие страницы являются исходными:
Во- первых, в рекомендациях Google говорится , что поисковая система « старается индексировать и показывать страницы с четкой информацией. Вот почему, сталкиваясь с дублирующимся контентом, он выбирает канонический, который он считает наиболее полезным для своих пользователей. В противном случае пользователи увидят много разных результатов, ведущих к идентичному контенту.
Во- вторых, согласно документации Google, « дубликаты сканируются реже», чем канонические страницы. Это позволяет Google экономить свои ресурсы для сканирования более важных страниц и снизить нагрузку сканирования на ваш сервер.
Теперь давайте посмотрим, как Google выбирает каноническую страницу.
Мы пытаемся выбрать канонический URL-адрес, следуя двум общим рекомендациям: во-первых, какой URL-адрес выглядит так, как сайт хочет, чтобы мы его использовали ; Итак, каковы предпочтения сайта? А во-вторых, какой URL будет полезнее для пользователя?источник: Джон Мюллер
Вот некоторые из сигналов, на которые Google обращает внимание при определении канонической версии:
- Канонические теги,
- карты сайта,
- Внутренняя структура ссылок,
- HTTPS по протоколу HTTP,
- Более привлекательный URL,
- Перенаправляет.
Эти факторы являются подсказками, которые вы можете использовать, чтобы помочь Google понять, какую страницу вы хотите проиндексировать. Однако поисковая система не обязана их соблюдать.
Канонические теги
<link rel="canonical" href="https://example.com/original-page">Канонический тег — это фрагмент HTML-кода, размещенный в разделе <head>. Его атрибут href включает ссылку на каноническую версию страницы. Если рассматриваемая страница является дубликатом неканонической версии вашего контента, вы должны разместить ссылку на каноническую версию в атрибуте href.
Но вы также можете добавить самоссылающийся канонический тег. Самоссылающаяся страница содержит канонический тег с атрибутом href, указывающим на саму себя. Во время работы Google SEO Office Hours Джон Мюллер рекомендовал использовать самоссылающиеся канонические теги, даже если существует только одна версия страницы.
Я рекомендую делать этот самореферентный канонический, потому что он действительно дает нам понять, какую страницу вы хотите проиндексировать, или каким должен быть URL-адрес, когда он проиндексирован.Даже если у вас есть одна страница, иногда существуют разные варианты URL-адреса, которые могут поднять эту страницу. Например, с параметрами в конце, возможно, с заглавными строчными буквами или с www и без www, и все это можно как бы очистить с помощью тега rel canonical.
источник: Джон Мюллер
карты сайта
Файлы Sitemap — это простые текстовые файлы со списком URL-адресов, которые вы, как владелец сайта, хотите проиндексировать. Он служит дорожной картой для ботов поисковых систем, позволяя им быстро находить ценные URL-адреса без предварительного сканирования всего веб-сайта.
Файлы Sitemap должны включать только канонические URL-адреса. Размещение дубликатов страниц в карте сайта может привести к трате краулингового бюджета (количество URL-адресов, которые Google может и хочет сканировать на вашем веб-сайте) и сбить с толку поисковые системы.
Однако размещение URL-адреса в карте сайта не гарантирует, что поисковые системы будут индексировать этот URL-адрес. Это просто подсказка, помогающая им понять, какие страницы вам интересны больше всего. В нашем Полном руководстве по XML-картам сайта вы можете узнать больше о создании и оптимизации вашей карты сайта.
Внутренняя перелинковка
То, как страницы связаны друг с другом, помогает поисковым системам находить все ценные страницы и определять их важность.
Чем ценнее страница, тем больше ссылок должно указывать на нее.
Давайте представим, что есть две одинаково ценные страницы. Один из них связан только с карты сайта. Другой легко найти в навигации и имеет ссылки, указывающие на него с других страниц сайта. В этом случае Google предполагает, что страница со ссылками более ценна, чем та, что находится только в карте сайта.
Структура внутренних ссылок является частью более сложной проблемы, называемой архитектурой веб-сайта. Если вы хотите узнать об этом больше, я рекомендую вам прочитать наше подробное руководство по архитектуре сайта, в котором подробно объясняется, что это такое и как создать идеальный дизайн для вашего сайта.
HTTPS через HTTP
HTTP — это протокол, определяющий передачу данных между сервером и клиентом. HTTPS — это зашифрованная версия протокола. Благодаря дополнительному уровню безопасности передача данных становится более безопасной, а риск манипулирования данными меньше.
HTTPS влияет на ранжирование ваших страниц.
Если у вас есть страница, доступная как в версиях HTTP, так и в версиях HTTPS, Google выберет для индексации версию HTTPS.
Более привлекательные URL-адреса
URL-адреса помогают пользователям и поисковым системам видеть, что содержит страница. Как владелец веб-сайта, вы можете контролировать, как выглядят ваши URL-адреса. Как сказал Джон Мюллер, если несколько URL-адресов ведут на одну и ту же страницу, Google может выбрать «более красивые».
Что именно означает более красивый URL-адрес? Google говорит , что «структура URL сайта должна быть максимально простой».
Давайте посмотрим на примеры двух URL-адресов:
- https://www.example.com/index.php?id_sezione=360&sid=sdr3bc
- https://www.example.com/summer/платье
Второй URL-адрес определенно «красивее». Это потому, что он короче и четко указывает, что содержит эта страница. Если вам интересно узнать больше о структуре URL-адресов, я рекомендую прочитать нашу статью о том, как создать SEO-дружественный URL-адрес.

перенаправляет
Использование перенаправления 301 — это один из способов объединить дублированный контент на вашем сайте. Если пользователь или бот поисковой системы заходит на страницу, он автоматически перенаправляет их на новую.
Вы можете использовать его, если хотите, чтобы на вашем веб-сайте оставалась доступна только одна версия вашей страницы. Например, если у вас есть версия с www и без www, вы можете использовать перенаправление 301, чтобы указать, какая из них должна оставаться доступной и индексироваться.
Причины и решения для статуса «Дубликат, Google выбрал не канонический, а пользовательский» статус
В некоторых случаях выбор канонического URL, отличного от пользователя, может не иметь последствий. Если две страницы идентичны, та, которую выбрал Google, может ранжироваться так же хорошо, как и та, которую вы выбрали.
Но есть вероятность, что вы выбрали каноническую страницу не просто так. Если страницы не идентичны, на той, которую выбрал Google, могут отсутствовать некоторые важные детали, что может отпугнуть пользователей от посещения вашего веб-сайта.
Итак, давайте рассмотрим возможные причины, по которым Google может не согласиться с вами в отношении канонической версии, и способы устранения проблемы.
Google может выбрать другую каноническую страницу, чем пользователь, по разным причинам, в том числе:
- Несогласованные сигналы,
- Самоссылающийся канонический тег без уникального содержания,
- Проблемы с рендерингом,
- Ориентация на разные страны с одинаковым/похожим языком.
Несогласованные сигналы
Как упоминалось в разделе «Как Google выбирает каноническую страницу?» В главе есть несколько сигналов, которые вы можете использовать, чтобы указать, какая страница является исходной. Однако, если вы используете их непоследовательно, это может запутать Google и привести к тому, что он выберет неправильный URL для индексации.
Давайте представим ситуацию, когда у вас есть три дубликата страниц:
- Все страницы имеют канонические теги, указывающие на страницу А,
- Страница B находится в карте сайта,
- Страница C имеет наибольшее количество внутренних ссылок, указывающих на нее.
В случае противоречивых сигналов Google необходимо угадать , какая из страниц является настоящей канонической.
Чем четче вы подаете свои сигналы, тем легче им доверять :). Например, если внутренние ссылки, карты сайта, атрибуты hreflang, rel-canonical и т. д. совпадают, гадать особо не о чем. Часто это довольно непоследовательно и труднее выбрать.
— Джон (личное) (@JohnMu) 28 февраля 2018 г.
Решение
Есть одно решение этой причины статуса «Дубликат, Google выбрал другой канонический статус, чем пользовательский»: будьте последовательны!
Вот несколько советов, которые следует учитывать при настройке канонических сигналов:
- Избегайте размещения неканонических страниц или страниц с переадресацией в карту сайта,
- Убедитесь, что ваши внутренние ссылки непротиворечивы и каждая ссылка указывает на каноническую версию,
- Канонические теги должны указывать на окончательную версию, не включать страницу, перенаправляющую на другую страницу,
- Избегайте канонических циклов (страница А имеет канонический тег, указывающий на страницу Б, а страница Б имеет канонический тег, указывающий на страницу А), и канонические цепочки (страница А имеет канонический тег, указывающий на страницу Б, а страница Б имеет канонический тег указывая на страницу С).
Самоссылающийся канонический тег без уникального содержания
Если у вас есть несколько страниц с самоссылающимися каноническими тегами, но Google решает, что они не содержат уникального значения, он может выбрать только одну страницу для индексации.
Обычно это происходит на сайтах электронной коммерции, когда несколько продуктов имеют одинаковое описание.
Если вы продаете одну и ту же модель кровати разных размеров, вы можете захотеть проиндексировать все страницы с разными размерами, чтобы пользователи могли легко найти то, что ищут. В конце концов, если они ищут большую двуспальную кровать и видят в результатах поиска только маленькие кровати, предназначенные для детей, они могут проигнорировать вашу страницу и вместо этого посетить веб-сайт вашего конкурента.
Если кто-то ищет фрагмент текста, который находится в этом дублированном описании на ваших страницах, то мы узнаем, что этот фрагмент текста находится на нескольких страницах вашего веб-сайта, и попытаемся выбрать, возможно, одну или две страницы. с вашего сайта, чтобы показать.источник: Джон Мюллер
Решение
Добавляйте уникальный контент на свои страницы.
Не полагайтесь только на самоссылающиеся канонические теги. Вместо этого убедитесь, что каждая страница имеет уникальное значение.
Джон Мюллер обратился к проблеме дублирующихся описаний во время работы Google SEO Office Hours. Он заявил, что у вас должна быть хотя бы какая-то дополнительная текстовая информация, указывающая на то, что продукты разные.
[…]если у вас в текстовом содержании вообще нет ничего, что покрывало бы визуальный элемент ваших продуктов, то нам было бы очень сложно правильно отобразить это в результатах поиска. […]Так что это точка зрения, которую я бы выбрал здесь, это нормально, если части описания дублируются. Но я бы определенно удостоверился, что у вас есть хотя бы что-то там, где действительно есть текст о визуальных элементах, которые уникальны для тех отдельных продуктов, которые вы продаете.
источник: Джон Мюллер
Проблема с рендерингом
Поисковые системы все еще не совершенны в рендеринге JavaScript. Поэтому, если вы сильно полагаетесь на него для отображения своего контента, у Google могут возникнуть проблемы с просмотром каждого элемента на вашей странице.
Рендеринг важен для Google и других поисковых систем, чтобы видеть и понимать содержание и макет нашего веб-сайта. Без рендеринга ваш контент не существует в сети. Мы давно прошли те времена, когда вы могли видеть свой контент, просто заглянув в HTML-код веб-сайта.источник: Рендеринг SEO-манифеста — почему JavaScript SEO недостаточно
Google может считать некоторые страницы дубликатами, потому что не может отобразить контент, который делает их уникальными.
Допустим, у вас есть три уникальные страницы. Каждый из них имеет самоссылающийся канонический тег. JavaScript генерирует их основной контент, и по какой-то причине Google его не отображает. Вместо этого он просто видит пустое место и несколько дополнительных элементов, таких как панель навигации, которые одинаковы для каждой страницы. Для Google эти страницы кажутся дубликатами, поэтому он выбирает для индексации только одну из них.
Вы можете проверить, как Google отображает вашу страницу, в инструменте проверки URL в Google Search Console. Инструмент предоставляет скриншоты вашей отображаемой страницы, которые позволяют вам получить представление о том, как Google видит вашу страницу. Если ваш контент отсутствует на скриншотах, это означает, что могут возникнуть проблемы с рендерингом.
Решение
Во-первых, вы должны убедиться, что у Google есть доступ ко всем необходимым скриптам. Убедитесь, что ваши ресурсы JavaScript не заблокированы robots.txt (файл, который вы можете создать, чтобы указать, какие страницы можно сканировать).
Если ваши ресурсы доступны для Google, вам необходимо оценить сценарии. Вы должны учитывать такие аспекты, как размер вашего скрипта и нужно ли вам все это для создания страницы.
Тема рендеринга SEO обширна, и если у вас нет опыта программирования, вам может понадобиться помощь ваших разработчиков для решения некоторых более сложных вопросов. Для получения дополнительной информации посетите наш манифест SEO-рендеринга, где мы подробно объяснили эту тему.
Ориентация на разные страны с одинаковым/похожим языком
Если у вас есть страницы, ориентированные на определенные страны, говорящие на одном или похожем языке (например, США и Великобритания), может случиться так, что Google выбрал для индексации только одну из них.
Предположим, что единственным решением, которое вы используете, чтобы указать, что вы ориентируетесь на разные страны с одним и тем же языком, является канонический тег со ссылкой на эльфа. В этом случае Google может не понять цели и решить, что это все повторяющиеся страницы. В результате он выберет для индексации только одну из них, и ваши пользователи могут найти в результатах поиска страницы, посвященные разным странам.
Это может быть особенно большой проблемой для сайтов электронной коммерции, поскольку это может привести к тому, что клиенты не смогут совершить покупку.
Решение
Вы всегда должны убедиться, что у вас есть теги hreflang .
Тег hreflang – это фрагмент HTML-кода, который помогает указать язык и страну, на которые ориентирована страница.
<link rel="alternate" hreflang=" en-gb " href="https://en-gb.example.com/item"> <link rel="alternate" hreflang=" en-us " href="https://en-us.example.com/item">
Тег hreflang позволяет указать не только язык (en — английский), но и страну (gb — Великобритания, us — США).
Еще одна вещь, которую вы можете сделать, это убедиться, что ваш контент не только переведен, но и локализован. Даже если язык один и тот же, в разных странах разные культуры. Обязательно настройте свои страницы для пользователей из определенной страны. Эта практика не только обеспечивает лучший пользовательский интерфейс для ваших клиентов, но также может убедить Google, что эти страницы уникальны.
И последнее, но не менее важное: у вас должен быть запасной план на случай, если упомянутые выше методы не сработают. Создайте баннер JavaScript , который отображается в зависимости от местоположения пользователя. Если он обнаружит, например, что пользователь из Великобритании вводит версию для США, он предложит более подходящую версию и позволит клиенту решить, хочет ли он остаться или посетить страницу, предназначенную для его региона.
«Дублировать, Google выбрал другой канонический, чем пользовательский» в сравнении с «Дублировать, отправленный URL не выбран в качестве канонического» или «Дублировать без выбранного пользователем канонического»
«Дубликат, Google выбрал не канонический, а пользовательский» можно легко спутать с двумя разными статусами в отчете об индексировании:
- «Повторяющийся отправленный URL не выбран как канонический» и
- «Дублировать без выбранного пользователем канонического».
Эти статусы говорят об одном и том же: страница не проиндексирована, потому что Google считает ее неканоничной.
Разница заключается в том, как Google узнал о странице и объявил ли пользователь канонический тег или нет.
Основное различие между ними заключается в том, что «Дублировать, Google выбрал другой канонический, чем пользовательский» уже указан канонический тег, который Google не уловил. Напротив, у двух других статусов не было никаких канонических тегов, определенных пользователем.
Кроме того, вы явно попросили проиндексировать URL-адрес с сообщением «Дублирующийся отправленный URL-адрес, не выбранный как канонический», отправив его в свою карту сайта.
Подведение итогов
Если вы видите статус «Дубликат, Google выбрал другой канонический, чем пользовательский» статус и считаете, что Google выбрал не ту страницу для индексации, вы можете сделать несколько вещей, чтобы повысить шансы индексации предпочитаемой вами страницы:
- Будьте последовательны в отправке канонических сигналов: убедитесь, что в вашей карте сайта указана только каноническая страница, а внутренние ссылки указывают на нее,
- Убедитесь, что каждая страница имеет уникальное значение. Если ваши страницы продуктов имеют одинаковое описание, добавьте текстовое содержание, указывающее, что продукты разные,
- Убедитесь, что ваш контент правильно отображается в инструменте проверки URL,
- Не только переводите контент на разные языки, но и локализуйте его для конкретной целевой страны,
- Всегда не забывайте добавлять теги hreflang для контента, ориентированного на несколько стран.