
データ サイロとは何か、またそれが引き起こす問題とは?
公開: 2022-12-29データは競争上の優位性です。 プロセス、製品、および運用を改善して、競合他社よりも優れたビジネスを構築できます。 しかし、データは脆弱でもあり、適切なデータ ガバナンスがなければ、データの整合性が損なわれる可能性があります。
このブログ投稿では、データ整合性の問題の主な原因の 1 つであるデータ サイロについて説明します。 それらが何であるか、それらが存在する理由、およびそれらを分解する方法を掘り下げてみましょう.
重要ポイント
- データ サイロとは、組織内の他のユーザーがアクセスできない、個人または部門が保持するデータです。
- 組織の成長、不十分なデータ文化、適切なテクノロジの欠如が、サイロ化されたデータの主な原因です。
- ビジネスの可視性を制限し、データの整合性を脅かし、会社のリソースを浪費し、共同作業の少ない環境を作り出し、カスタマー エクスペリエンスを低下させ、データ セキュリティを危険にさらすため、データ サイロは問題となります。
- サイロ化されたデータの一般的な症状としては、ビジネスの可視性が不足しているため、洞察を得るまでの時間が遅い、または従業員が不満を感じていることがあります。
- データサイロを解体することは、長く困難なプロセスです。 さまざまなソースからデータを抽出して変換し、単一の信頼できるソース (SSOT) にプッシュする ETL パイプラインなどの自動化プラットフォームを使用すると、これをよりスムーズに行うことができます。
データ サイロとは
データ サイロは、部署や個人に属し、組織内の他のユーザーがアクセスできないビジネス データの島と考えてください。 その結果、分離された情報が生じ、最終的に組織のデータ品質が損なわれます。

データサイロが存在する理由
データサイロを作成する計画を開始する人は誰もいません。 しかし、一部の組織はそれらの影響を受けやすくなっています。
組織構造はサイロ化されたデータに適しています
ビジネスは、多くの場合、責任の分離から恩恵を受けます。 しかし、部門化は一部のデータの分離につながる可能性があります。 各部門が独自の目的のために独自のデータを収集することで、意図せずにデータ サイロが作成されます。
ビジネスには、優れたデータ品質の文化がありません
データ文化が未熟な組織は、データ サイロの問題を抱えている可能性が高くなります。 これらの企業は通常、ドキュメントとデータ ガバナンスが不足しているため、データの収集、管理、および保存に関する共通の理解がありません。
その結果、従業員は、収集したデータの共有に関する適切なガイダンスを受けられなくなります。
テクノロジーがデータ品質への取り組みを抑制している
テクノロジーは、高品質のデータを維持しようとする組織の取り組みを妨害することがあります。
企業がさまざまなソフトウェアを使用して業務を実行する場合、これらの異なるソフトウェアは相互に互換性がない場合があります。 これにより、データ共有が複雑になります。
あるいは、一部の組織では、異なるデータ ソース間の通信を優先するテクノロジにアクセスできず、必然的にデータ サイロの問題が発生します。
ビジネスの成長はデータ管理の実践を弱体化させる
ビジネスの成長は、拡大するビジネスをサポートするための新しい部門、新しい従業員、新しいプロセス、および新しいソフトウェアの形成につながります。
データ管理が優先事項ではない場合、これらの最近の変化はすべて、個人が作業を進めるにつれて物事を作り上げることになります。これは、ほとんどの場合、データ品質の問題、特にデータ サイロにつながります。
データ サイロの一般的な例
データは単独でサイロに収まることはありません。 データをサイロ化するのは、私たちがとる行動です。 ここでは、組織が (多くの場合意図せずに) データへのアクセスを制限する一般的なユース ケースを確認します。
ほとんどの業務でスプレッドシートを使用する
スプレッドシートは、多くの企業でデータを処理、クエリ、民主化するための最も一般的なツールです。 データチームの首の痛みになることがよくありますが.
非技術専門家 (マーケティング担当者や財務担当者など) は、スプレッドシートの数式をマスターし、単一の VLOOKUP で驚くべきことを実行できます。
使いやすさにもかかわらず、スプレッドシートはしばしばデータの墓場になります。 必要なクエリを実行した後、データは誰かのクラウドで失われ、集中ストレージに到達しません。
スプレッドシートは、プロトタイプから本番環境に移行するときにもデータ サイロになります。 ビジネス ロジックの一部がスプレッドシートを中心に展開している場合は、より実用的なものを考え出す必要があるという明確な兆候です。 スプレッドシートを避ける理由は複数あり、データの上限から、各スプレッドシートをデータ ガバナンス プロセスに含めることができないことまでさまざまです。
スプレッドシートからデータのサイロ化を解除する方法:ビジネス オペレーションの一部に不可欠な巨大なスプレッドシートを確認することから始めます。 それらは、サイズが大きく、その上に多数のマクロと数式が存在するため、おそらく非効率的です。
クラウド データ ウェアハウスなど、より持続可能なアーキテクチャにデータを転送する方法を見つけることで、データのアクセシビリティと、データを操作する各従業員の個々のパフォーマンスが向上します。
構造化されていない変換クエリ
財務データ、マーケティング データ、販売データなど、さまざまな種類のデータを集約して、信頼できる唯一の情報源を作成すると、少し面倒になります。
まず、異なるデータには異なる命名規則があり、意味をなすために整列する必要があります。 さらに、キャンペーンのパフォーマンスや収益の伸びなどに関するアドホック レポートを作成するには、以前のクエリに加えて追加のクエリを作成する必要があります。
最終的には、その所有者だけが意味を持つ 3 ページの長い SQL クエリを作成することになります。 変換ジョブが非常に複雑で、必要なデータの一部がデータ パイプラインに到達しない場合があります。
最悪の部分は、アナリストがメトリクスの大幅な減少/増加を見つけることができるが、このデータがどのようにクエリされたかを理解できないため、その背後にある理由を理解できないことです.
複雑なクエリからデータを分離する方法:この問題には 2 つの異なる方法でアプローチできます。
会社が社内で変換を実行する場合は、複雑なクエリを複数のチェックポイントに分割し、それらを中間データ品質チェック用のテーブルに格納します。 明確に定義された変換ステップと、各ステップ後のデータ品質の検証により、パイプラインからデータが抜け落ちることはありません。
もう 1 つのオプションは、さまざまな種類のデータに対して自動化された変換ソリューションを使用することです。 たとえば、自動化されたマーケティング データ パイプラインである Improvado は、事前定義されたレシピに従ってすべてのデータを変換します。 任意のレシピを選択して、変換プロセス後にデータがどのように見えるかを正確に知ることができます.
また、Improvado を使用すると、SQL に似た独自の変換クエリを、コード不要のスプレッドシートに似たインターフェイスで作成できます。 さまざまなデータ エントリ間の依存関係を明確に確認し、必要な方法でデータを変換できます。SQL クエリを記述する必要はありません。
データを人質に保つサードパーティのソリューション
今日の市場には、あらゆるソースからデータを抽出し、それを消化可能な形式に変換して、洞察力のあるダッシュボードに表示できる ETL ソリューションがあふれています。 ただし、これらのソリューションのほとんどには、ベンダー ロックインという大きな欠点があります。
例として、Datorama (Salesforce Marketing Cloud) を見てみましょう。 これは、マーケティング レポートを自動化し、何百ものソースからのデータを合理化する、大企業向けの包括的なソリューションです。 一見すると、それは各マーケターの夢です。 すべての一般的な広告プラットフォームからのデータに関するアドホック レポートを備えています。
データサイロの角度から見ると、事態は複雑になります。 Datorama から社内ストレージにデータをロードしたり、このデータを自分で収集したサードパーティの洞察とマージしたりすることはできません。 つまり、Datorama でしか利用できないデータにかなり縛られてしまい、プラットフォームの外部でも有用な洞察を共有することができなくなります。
このベンダーロックインにより、ベンダーに依存し、価格設定ポリシーの変更に対して脆弱になります. 価格の変更に同意しない場合、蓄積した履歴データがすべて失われるため、単純にプラットフォームをあきらめることはできません。 そのため、データをそのようなプラットフォームに委ねる前によく考える必要があります。
データがトラップされないようにする方法:サードパーティのプラットフォームを使用する場合は、データへの完全なアクセスを提供するベンダーを選択してください。
もう一度、Improvado を見てみましょう。 データを保存するさまざまな方法を提供します。 これは、Google Big Query などのクラウド データ ウェアハウスにロードするか、Improvado の環境からデータをクエリすることができます。 独自のデータ ウェアハウスやそれを管理するための専門知識がない場合は、Improvado がデータ ウェアハウス管理サービスを提供します。
こうすることで、どのような状況でもデータが保持され、社内のすべての従業員が完全にアクセスできるようにすることができます。
データ サイロが問題になるのはなぜですか?
データ サイロは、組織やビジネスに広範囲に及ぶ非常に一般的な問題です。

ビジネスの可視性を制限する
関連するビジネス データを中央データベースに接続できない場合、意思決定者が到達する洞察は、ビジネス オペレーションの実際の状態を反映していません。 これは、利益よりも害を及ぼすビジネス上の決定につながる可能性があります。
また、アナリストが簡単にアクセスできないデータを必要とする場合、さまざまな場所からそれを見つけるのに多くの時間がかかります。 これにより、洞察を得るまでの時間、つまり実用的な洞察を導き出すのにかかる平均時間が短縮され、ビジネスの俊敏性が低下します。

一部の洞察は、部門間のデータ交換がなければ分析から完全に失われる可能性があります。
たとえば、セールスとマーケティングの連携なしに、リードを収益に結びつけ、最もパフォーマンスの高いチャネルを特定するにはどうすればよいでしょうか? または、カスタマー サクセス チームからの情報がなければ、顧客の LTV をどのように知ることができるでしょうか?
データの完全性を損なう
データ サイロは不完全なビジネス データをもたらし、データの整合性を危険にさらします。
これは、2 つの部門が異なる測定単位を使用していることを伝達できなかったため、マーズ クライメート オービターを紛失した後、NASA が学んだように、少なくともビジネス上の意思決定の誤りや、最悪の場合は大きな災害につながる可能性があります。
航空宇宙業界で働いていなくても、データ サイロによって引き起こされるバイアスに対して脆弱です。 関連する販売データなしで収益のためにキャンペーンを最適化しようとするマーケティング部門を想像してみてください。 最適化全体は当て推量にすぎません。
経営資源の無駄遣い
データ ストレージのコストは法外に高額になる可能性があります。 多くのデータ サイロには類似したデータや古いデータが格納されているため、組織は、組織に提供されなくなったデータ ストレージに予算リソースを割り当てています。
将来的には、このデータに基づくビジネス上の意思決定は、ビジネスの収益を損なう可能性さえあります。 たとえば、製品の発売時に不正確なデータがあると、電子メール サービス プロバイダー (EMS) が間違った電子メールを顧客に送信する可能性があります。 または間違ったセグメントに、または間違った日に。 これは顧客の信頼を損なうだけでなく、ROI にも影響を与えます。
従業員のコラボレーションを減らす
自由に共有されていないデータは、従業員と部門の間で対立を引き起こす可能性があります。
新しいメッセージが心に響き、見込み客に伝わるかどうかを知りたいとしましょう。 このためには、見込み客の質を評価し、見込み客から売上への転換率を検証する必要があります。
販売からこのデータを取得するのに長い時間がかかり、プロセスが遅くなる場合はどうすればよいでしょうか? これにより、あなたと営業部門の担当者との間にひどい感情が生まれる可能性があります。
同様に、データの透明性が欠如していると、異なる部門間のコラボレーションが妨げられます。 コラボレーションや協力が奨励されないため、良いアイデアが消えてしまう小さな島になってしまいます。
カスタマー エクスペリエンスの低下を増幅する
顧客がビジネスに関与するたびに、そのやり取りを記録できるソフトウェアが存在します。
これらの異なるツール間でデータを接続する方法がなかったらどうなるか想像してみてください。 多くのデータがサイロ化され、カスタマー ジャーニーのどの部分を最適化し、すべてのカスタマー エンゲージメントをどのようにパーソナライズできるかを理解するのに苦労することになります。
これは、ブランドから遠ざかるばらばらなカスタマー エクスペリエンスにさらにつながります。
データのセキュリティを侵害する
データが誰かのデジタル フォルダに保存され、集中型のデータ セキュリティ ネットワークからアクセスできない場合、組織がこれらのアーカイブにセキュリティ対策を講じることは困難になります。 ユーザーのアクセス許可を制御できないため、データ侵害の脅威が高まります。
データ サイロの問題があることをどうやって知ることができますか?
データ サイロの問題は、多くの場合、日常のビジネス オペレーションに現れます。 意思決定者から最前線の従業員まで、あらゆるレベルのすべての人に影響を与えます。
経営幹部は、意思決定に必要な情報を得るのに長い時間がかかります。 彼らは、ビジネス目標を達成するためにどのレバーを引くべきかを知りません。 このように業界の傾向が見えないということは、変化する顧客のニーズへの対応が遅れることが多いことを意味します。
販売とマーケティングの整合性の欠如も、データ サイロの問題の兆候である可能性があります。 仕事を遂行するための関連データへのアクセス権が与えられていないと個人が感じている場合、情報を「保留」している他の従業員を非難すると便利です。 これは、パフォーマンスの低下や収益の損失は言うまでもなく、不健全な競争や有毒な職場環境につながることがよくあります。
データサイロを打破する方法
データ サイロを解体することは、企業にとって最も困難なタスクの 1 つです。 彼らは企業文化に深く根付いているため、排除するのは困難です。 それらを分解することは、トップダウンのイニシアチブと全社的な教育プログラムでなければなりません。
それらが存在することを受け入れる
データサイロは、どの組織にも発生する可能性があります。 会社がこれを受け入れるのが早ければ早いほど、それらを排除するために必要な措置を早く講じることができます。
組織内で意思決定がどのように行われるかを理解する
あらゆる組織におけるデータの主な目的は、より良い意思決定を行うことです。 したがって、社内のデータ フローを理解するには、まず意思決定プロセスを明確に定義する必要があります。
Fresh FP&A の CEO であり、著名な金融インフルエンサーである Chris Ortega は、Decision Cycle と呼ばれるフレームワークの使用を提案しています。 このフレームワークによると、意思決定サイクルは意思決定を 5 つのコア ピラーに分割します。
- プロセス
- データ
- 情報
- 知識
- ビジネス上の意思決定
これらの柱は相互に関連しています。 つまり、プロセスはデータを駆動します。 その後、データは情報に変換されます。 その情報は、すべてのビジネス上の意思決定に影響を与える知識になります。
組織内で意思決定がどのように行われるかを理解すると、部門間のデータ サイロを特定し、データを知識に変換するプロセスを自動化し、意思決定プロセスにおける摩擦を減らすための適切なテクノロジを見つけることができます。
組織内のデータ サイロを特定する
データ サイロの問題の根本原因を特定します。 それは企業文化ですか? テクノロジー? プロセス? 次に、それらを統合、置換、または管理する計画を立てます。
組織内でサイロ化されたデータがある場合、部門はおそらく個別のビジネス ユニットとして機能しています。 つまり、各部門内のサイロ化されたデータを特定する必要があります。
あなたが正しい軌道に乗っていることを示すいくつかの兆候があります:
- 部門は、特定のビジネス活動に関するデータが不足していると不満を漏らすことがよくあります。
- 会社のビジネス プロセスに対する部門の影響を理解するには、データが不十分です (会社の取り組みの全体像に欠けているパズルのピースが 1 つ欠けていると想像してください)。
- 特定の部門の成功指標については不確実性があります。
- 部門のデータにすばやくアクセスできません。
また、IT チームに連絡して、各部門で使用されているシステムのリストを取得し、データが失われた場所をよりよく理解してください。
さまざまな部門や個人のデータ ニーズを特定する
データを必要とするさまざまなチームをリストアップし、彼らが何を必要とし、なぜそれを必要とするのかを理解します。 次に、そのデータをすでに記録している他の部署と、そのデータをどのように記録しているかを特定します。
すべてのデータとアプリケーションを統合
さまざまなビジネス アプリケーションを相互に通信させる方法を考えてください。 いくつかのアプリケーションを組み合わせることはできますか? データの共有を困難にするソフトウェアはありますか? 現在使用しているツールを置き換えることはできますか?
これを理解したら、組織が収集するすべてのデータに対して 1 つの信頼できる情報源を構築します。 データ サイロを分解し、データを 1 つの形式に変換し、統合されたデータをデータ ウェアハウスにロードするのに役立つ ETL プラットフォームなど、柔軟でスケーラブルなツールを活用します。
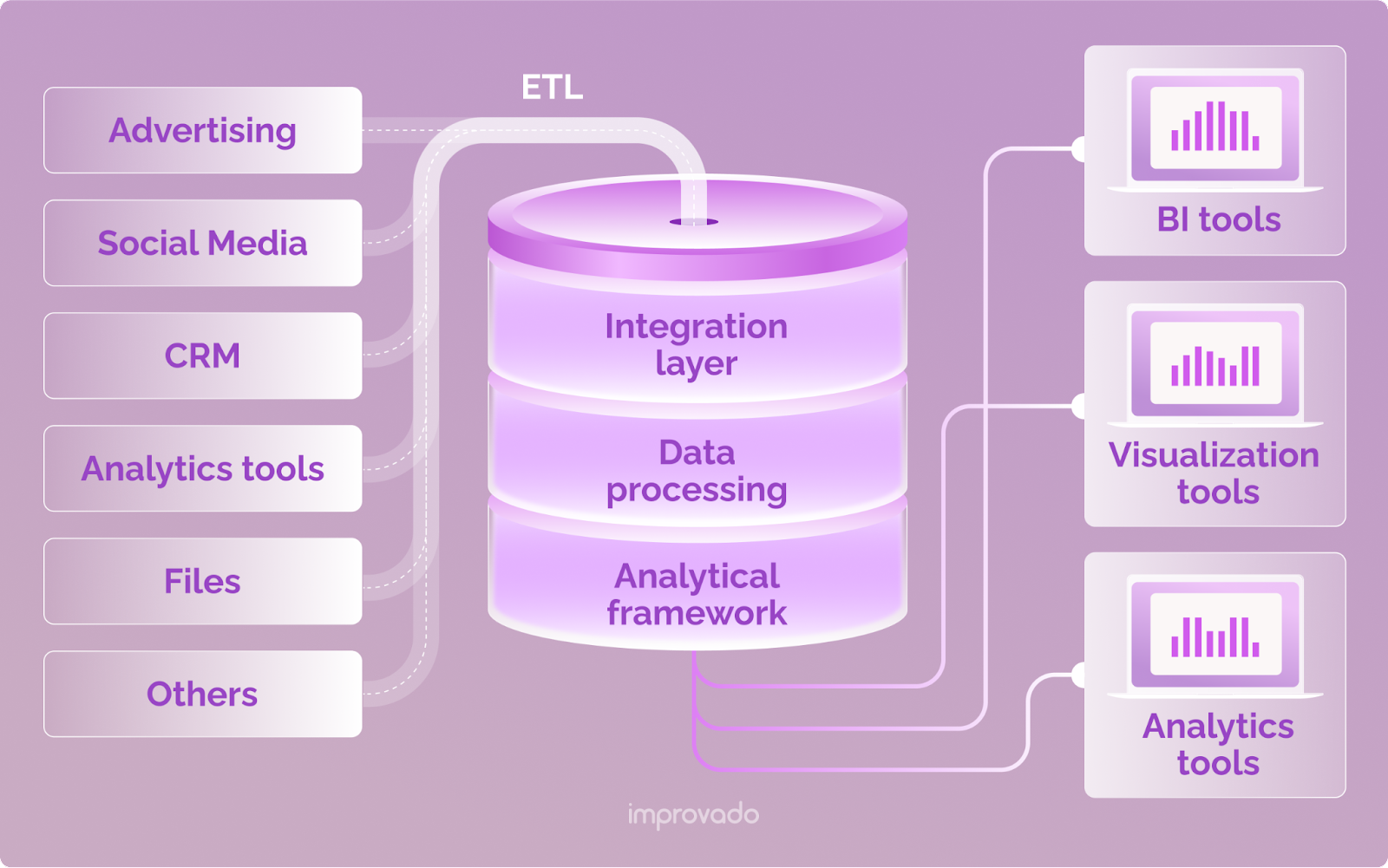
ビジネス コンテキストをデータに追加する
データ自体は非常に技術的な概念です。 テーブル、結合、共用体、およびその他の多くの専門用語があります。 しかし、ビジネス プロセスに関して言えば、データにはビジネス コンテキストが必要です。
「cost-flowchart-1.XML」という名前のデータベース テーブルがあるとします。 技術者でない人にとっては、それほど価値のあるものとは思えません。 しかし、この表がコスト センターの階層、または四半期中に引き付けられた見込み客のチャートであることが全員に知られると、一定の意味が得られます。
サイロ化されていないデータは、データ エンジニアにとって単なる一連の数値ではなく、会社全体の資産です。 そのため、操作する人にとって読みやすいものにする必要があります。
SAP のビジネス アプリケーションおよびプラットフォーム担当 SVP である Jagdish Sahasrabudhe 氏は、最近の講演で次のように述べています。 それがなければ、それはただのビットとバイトの集まりです。」
サイロ化されていないデータの戦略を策定する
データにアクセスできるようにすることは、デフォルトで優れています。 しかし、より大きなスケールで、「なぜ私の会社はそれを必要とするのか?」という質問を自問する必要があります。
それはイノベーションへのジャンプスタートであると同時に、成果を上げられなかったイニシアチブである可能性もあります。 そして、これらの結果の唯一の違いは戦略です。
データを使用してイノベーションを推進する場合は、経験と戦略のギャップを埋めるパートナーを見つけることを検討してください。 この責任をあなたや同僚に負わせる代わりに、さまざまな業界の複数の企業を支援してきたチームに委任してみませんか?
プロフェッショナル サービス フレームワークを通じて、Improvado はベンダーからパートナーへと進み、クライアント チームが洞察に満ちたダッシュボードを構築し、利用可能なデータに基づいて情報に基づいた意思決定を行うのを支援します。 新しいデータをどう処理するかについて明確な戦略を立てるには、プロセスの早い段階でガイダンスと専門知識を側に置くことが重要です。
データ品質プログラムを開発して動員する
データ品質は IT の問題と見なされることがよくありますが、実際には、責任の共有です。 データの所有権を奨励し、誰もが高品質のデータを作成して保存する責任を負うようにします。 データ ガバナンス プログラムを確実に成功させるには、社内の全員にとって明確で理解しやすいものにします。
最後に、データの透明性をビジネスの重要な側面にします。 部門間の競争の文化を止め、ビジネスの成長に向けたコラボレーションの重要性を強調します。
新しいデータ文化を管理する
新しいデータ品質システムを軌道に乗せるには時間がかかる場合があります。 一部の従業員は、古い慣行に戻ったり、何をすべきかについて混乱したりする可能性があります。
これらの欠点に備えてください。 チームがデータ管理への新しいアプローチに慣れるまでの間、今後のデータ管理方法について柔軟に対応してください。
あなたの番
データ サイロの解体は、完全なデータ管理プログラムの一部である必要があります。 組織がデータを収集、管理、保存する正確な方法について規制を設ければ、データ サイロが発生する可能性は低くなります。