
ไปป์ไลน์ข้อมูลคืออะไร?
เผยแพร่แล้ว: 2019-08-15Data Pipeline คืออะไร?
ไปป์ไลน์ข้อมูลทำหน้าที่เป็นเครื่องมือประมวลผลที่ส่งข้อมูลของคุณผ่านแอปพลิเคชัน ตัวกรอง และ API ที่เปลี่ยนรูปแบบได้ในทันที
คุณสามารถนึกถึงไปป์ไลน์ข้อมูลเหมือนเส้นทางการขนส่งสาธารณะ คุณกำหนดว่าข้อมูลของคุณกระโดดไปที่ใดบนรถบัสและออกจากรถบัสเมื่อใด
ไปป์ไลน์ข้อมูลนำเข้าแหล่งข้อมูลผสมผสาน ใช้ตรรกะการแปลง (มักจะแบ่งออกเป็นหลายขั้นตอนตามลำดับ) และส่งข้อมูลไปยังปลายทางการโหลด เช่น คลังข้อมูล เป็นต้น
ด้วยการถือกำเนิดของการตลาดดิจิทัลและความก้าวหน้าทางเทคโนโลยีอย่างต่อเนื่องในภาคไอที - ไปป์ไลน์ข้อมูลได้กลายเป็นตัวช่วยในการ รวบรวม การแปลง การ ย้ายข้อมูล และ การแสดงภาพ ข้อมูลที่ซับซ้อน
จากข้อมูลของ Adobe มีเพียง 35% ของนักการตลาดที่คิดว่าไปป์ไลน์ของตนมีประสิทธิภาพ ที่ Improvado เรามุ่งมั่นที่จะเปลี่ยนแปลงสิ่งนั้น
Improvado คือโซลูชันไปป์ไลน์ข้อมูลอันดับ 1 สำหรับนักการตลาด เครื่องมือ ETL ที่ใช้ในการแยก แปลง และโหลดข้อมูลจากกว่า 150 แพลตฟอร์มการตลาดที่แตกต่างกันไปยังปลายทางสุดท้าย เช่น เครื่องมือ BI หรือคลังข้อมูล เรียนรู้เพิ่มเติมที่นี่
ลักษณะที่เพรียวลมและเข้มข้นของไปป์ไลน์ข้อมูลช่วยให้สคีมามีความยืดหยุ่นจากแหล่งที่มาแบบคงที่และแบบเรียลไทม์ ในท้ายที่สุด ความยืดหยุ่นนี้เชื่อมโยงกับความสามารถของไปป์ไลน์ข้อมูลเพื่อแยกข้อมูลออกเป็นส่วนเล็กๆ
ความสัมพันธ์ของช่วงข้อมูลและผลกระทบของข้อมูลมีความสำคัญต่อธุรกิจทั่วโลกมากขึ้น พร้อมกันนี้ ความเข้าใจเกี่ยวกับพันธะที่เชื่อมต่อถึงกันนี้ช่วยให้นักวิทยาศาสตร์ข้อมูลสามารถแยกแยะความหน่วงแฝง คอขวด แหล่งที่มาที่ไม่ปรากฏชื่อ และปัญหาการทำซ้ำได้
มันเป็นความจริง ไปป์ไลน์ข้อมูลตอนนี้เสริมเครือข่ายระบบ ยิ่งไปป์ไลน์ข้อมูลครอบคลุมมากขึ้น การบังคับใช้ระบบเครือข่ายที่ดียิ่งขึ้นคือการรวมบริการคลาวด์และแอปพลิเคชันไฮบริดสำหรับการทำงาน
การเพิ่มขึ้นของ Data Pipeline
ยิ่งไปกว่านั้น ไปป์ไลน์ข้อมูลได้เปิดประตูใหม่ในการผสานรวมเครื่องมือจำนวนมากและนำเข้า ไฟล์ XML และ CSV ขนาดใหญ่จำนวนมหาศาล อย่างไรก็ตาม การประมวลผลข้อมูลแบบเรียลไทม์อาจเป็นจุดเปลี่ยนสำหรับไปป์ไลน์ข้อมูล
จุดให้ทิปนั้นอำนวยความสะดวกในการย้ายข้อมูลจำนวนมากจากที่หนึ่งไปยังอีกที่หนึ่งโดยไม่ต้องเปลี่ยนรูปแบบ ด้วยเหตุนี้ ธุรกิจต่างๆ จึงพบอิสระใหม่ในการ ปรับแต่ง กะ แบ่งส่วน แสดง หรือ ถ่ายโอน ข้อมูลในช่วงเวลาสั้นๆ
หลายปีที่ผ่านมา ความเที่ยงธรรมของการดำเนินธุรกิจได้เปลี่ยนแปลงไปอย่างมาก ความสนใจไม่ได้มุ่งไปที่การได้รับส่วนต่างกำไรอีกต่อไป แต่วิธีที่นักวิทยาศาสตร์ข้อมูลสามารถนำเสนอโซลูชันที่ใช้งานได้จริงซึ่งเชื่อมต่อกับผู้คน ยิ่งไปกว่านั้น ที่สำคัญกว่านั้น การเปลี่ยนแปลงเหล่านั้นจะต้องสามารถ เปลี่ยนแปลง ได้ ติดตามได้ และ ปรับเปลี่ยนได้ สำหรับการเปลี่ยนแปลงในอนาคต ที่กล่าวว่าไปป์ไลน์ข้อมูลมาไกลจากการใช้ไฟล์แฟลต ฐานข้อมูล และดาต้าเลค ไปจนถึงการจัดการบริการบนแพลตฟอร์มแบบไร้เซิร์ฟเวอร์
โครงสร้างพื้นฐานไปป์ไลน์ข้อมูล
โครงสร้างพื้นฐานทางสถาปัตยกรรมของไปป์ไลน์ข้อมูลอาศัยพื้นฐานในการดักจับ จัดระเบียบ กำหนดเส้นทาง หรือเปลี่ยนเส้นทางข้อมูลเพื่อรับข้อมูลเชิงลึก นี่คือสิ่งที่ โดยทั่วไปมีจุดเริ่มต้นที่ไม่เกี่ยวข้องจำนวนมากสำหรับข้อมูลดิบ นอกจากนี้ นี่คือที่ที่โครงสร้างพื้นฐานของไปป์ไลน์รวม ปรับแต่ง ทำให้เป็นอัตโนมัติ แสดงภาพ แปลง และย้ายข้อมูลจากทรัพยากรจำนวนมากเพื่อให้บรรลุเป้าหมายที่ตั้งไว้
นอกจากนี้ โครงสร้างพื้นฐานทางสถาปัตยกรรมของไปป์ไลน์ข้อมูลยังช่วยเสริมการทำงานโดยอิงจากการวิเคราะห์และระบบธุรกิจอัจฉริยะที่แม่นยำ ฟังก์ชันข้อมูลหมายถึงการได้รับข้อมูลเชิงลึกอันมีค่าเกี่ยวกับพฤติกรรมของลูกค้า กระบวนการหุ่นยนต์ กระบวนการอัตโนมัติ และรูปแบบของประสบการณ์ของลูกค้า และรูปแบบการเดินทางของผู้ใช้ คุณเรียนรู้เกี่ยวกับแนวโน้มและข้อมูลแบบเรียลไทม์ผ่านระบบธุรกิจอัจฉริยะและการวิเคราะห์ผ่านกลุ่มข้อมูลขนาดใหญ่
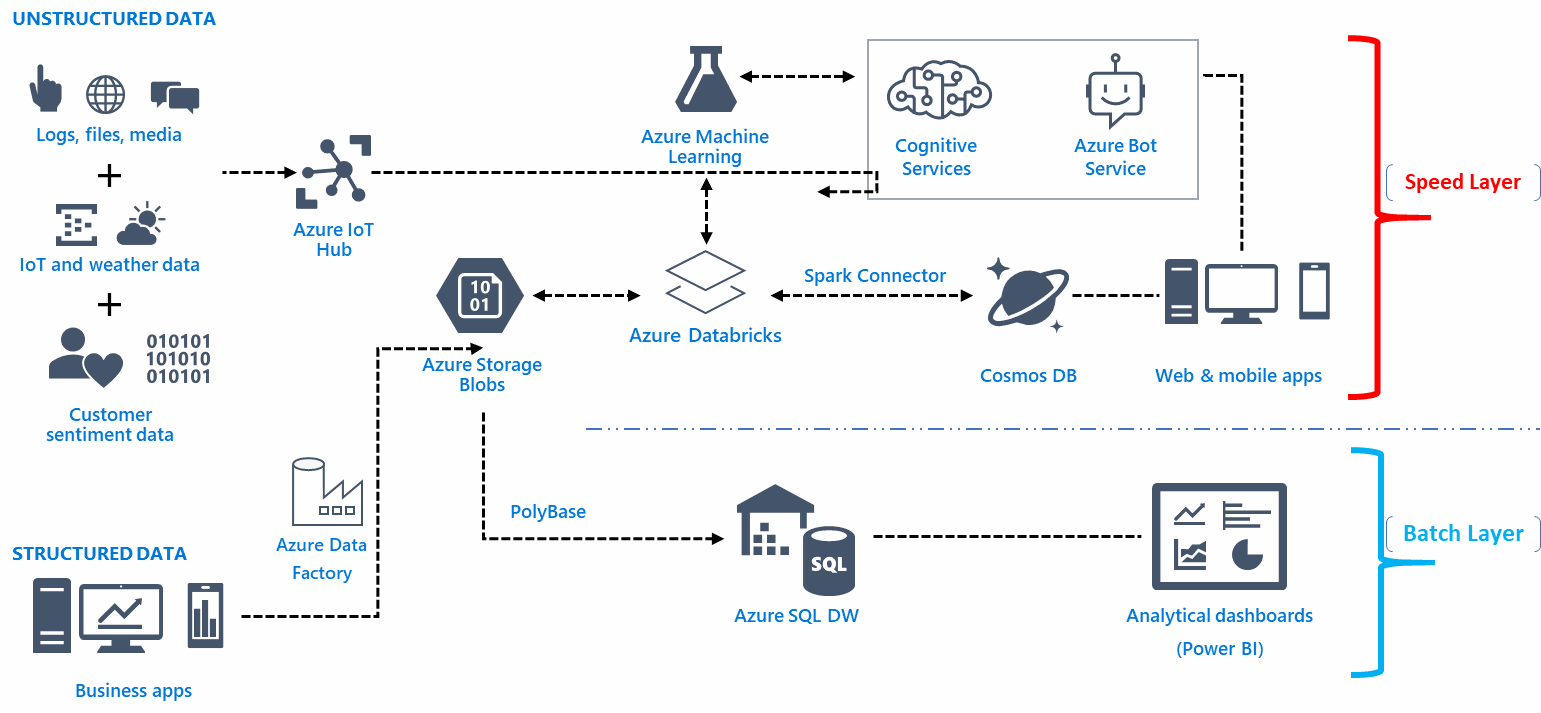
การเลือกทีมวิศวกรรมข้อมูลที่เหมาะสม
ควรจัดตั้งทีมวิศวกรรมข้อมูลขนาดใหญ่ที่มักจะยุ่งกับรายละเอียดการสมัครอยู่เสมอ จ้างวิศวกรข้อมูลที่สามารถเก็บข้อมูลโครงสร้างและแก้ไขปัญหา ทำความเข้าใจตารางที่ซับซ้อน และใช้ข้อมูลการทำงานได้ทันท่วงที

การทำงานของ Data Pipeline
ฟังก์ชันการทำงานของไปป์ไลน์ข้อมูลทำหน้าที่ในการรวบรวมข้อมูล แต่ในทางเทคนิค วิธีการในการจัดเก็บ เข้าถึง และการแพร่กระจายของข้อมูลอาจแตกต่างกันไปตามการกำหนดค่า
ตัวอย่างเช่น การย่อขนาดการเคลื่อนย้ายข้อมูลสามารถทำได้ผ่านเลเยอร์นามธรรมเพื่อกระจายข้อมูลโดยไม่ต้องย้ายข้อมูลทุกชิ้นบน UI ด้วยตนเอง คุณสามารถสร้างเลเยอร์นามธรรมสำหรับระบบไฟล์หลายระบบได้ด้วยความช่วยเหลือของ Alluxio ระหว่างกลไกการจัดเก็บและผู้จำหน่ายที่เลือก เช่น AWS
การทำงานของไปป์ไลน์ข้อมูลไม่ควรขึ้นอยู่กับความเมตตาของระบบฐานข้อมูลของผู้ขาย นอกจากนี้ อะไรคือจุดที่จะสร้างโครงสร้างพื้นฐานที่ปราศจากข้อผิดพลาดและเลเยอร์โดยไม่มีความยืดหยุ่น เมื่อคำนึงถึงเรื่องนี้ ไปป์ไลน์ข้อมูลของคุณควรรวบรวมข้อมูลที่สมบูรณ์ในอุปกรณ์จัดเก็บข้อมูล เช่น AWS เพื่อปกป้องอนาคตของระบบข้อมูล
ฟังก์ชันไปป์ไลน์ข้อมูลควรรองรับการวิเคราะห์ธุรกิจ แทนที่จะสร้างเครือข่ายทั้งหมดด้วยตัวเลือกที่สวยงาม ตัวอย่างเช่น หน้าที่ของโครงสร้างพื้นฐานการสตรีมนั้นจัดการได้ยาก และโดยทั่วไปต้องการประสบการณ์ระดับมืออาชีพและธุรกิจที่แข็งแกร่งเพื่อจัดการงานวิศวกรรมที่ซับซ้อน
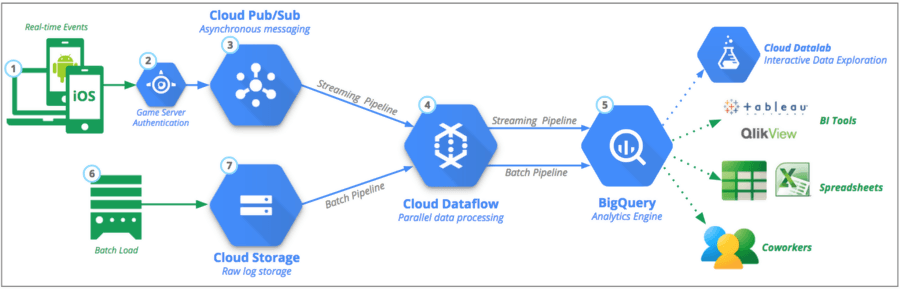
คุณสามารถใช้บริการคอนเทนเนอร์หลัก เช่น Dockers สำหรับการสร้าง ไปป์ไลน์ข้อมูล คุณสามารถปรับแต่งการตอบสนองการทำงานของความปลอดภัย ตรวจสอบศักยภาพในการขยายขนาด และปรับปรุงโค้ดซอฟต์แวร์ด้วยความช่วยเหลือของคอนเทนเนอร์ ข้อผิดพลาดทั่วไปที่ผู้คนมักทำระหว่างการสร้างการตอบสนองตามหน้าที่คือการดำเนินการและการกระจายการทำงานที่ไม่สม่ำเสมอ เคล็ดลับคือการหลีกเลี่ยงการใช้ไฟล์การแปลงหลักใน SQL และปรับวิธี CTAS เพื่อตั้งค่าพารามิเตอร์และการดำเนินการของไฟล์หลายรายการ
แม้ว่าฐานข้อมูลเช่น Snowflake และ Presto จะให้การเข้าถึง SQL ในตัวแก่คุณ ข้อมูลจำนวนมากจะลดเวลา UI ลงอย่างหลีกเลี่ยงไม่ได้ ดังนั้น ใช้อัลกอริธึมที่เน้นความเร็วซึ่งส่งผลให้เกิดข้อผิดพลาดเล็กน้อยในการส่งออก
เครื่องมือในการสร้างไปป์ไลน์ข้อมูล
ระบบไฟล์แบบเสาของไปป์ไลน์ข้อมูลของคุณควรจัดเก็บและบีบอัดข้อมูลสะสมขั้นสุดท้ายได้ เอ็นจิ้นข้อมูลเพิ่มการใช้งานของระบบไฟล์ดังกล่าวใน UI นอกจากนี้ เพื่อให้ได้ภาพที่สวยงาม - ใช้ iPython หรือ Jupyter เป็นโน้ตบุ๊ก คุณยังสามารถสร้างเทมเพลตสมุดบันทึกตามพารามิเตอร์เฉพาะเพื่อรับฟังก์ชันในตัวเพื่อตรวจสอบข้อมูล ไฮไลท์กราฟิก เน้นโครงเรื่องที่เกี่ยวข้อง หรือตรวจสอบข้อมูลทั้งหมด
คุณสามารถโอนชุดย่อยของข้อมูลเฉพาะนี้ไปยังตำแหน่งระยะไกลด้วยความช่วยเหลือของเครื่องมือต่างๆ เช่น Google Cloud Platform (GCP), Python หรือ Kafka คุณไม่จำเป็นต้องสร้างโค้ดเวอร์ชันสุดท้ายในครั้งแรก – เริ่มต้นด้วยฟีเจอร์ไลบรารี Faker ใน Python เพื่อเขียนและทดสอบโค้ดในไปป์ไลน์ข้อมูล

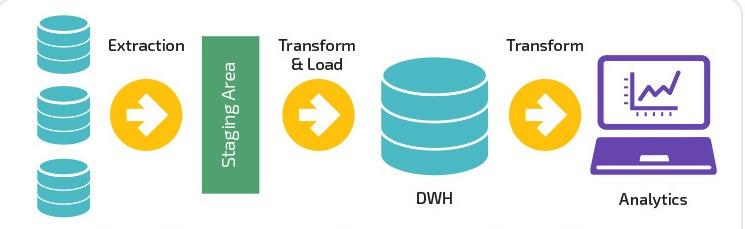
ความแตกต่างระหว่าง Data Pipeline และ ETL คืออะไร?
ETL เป็นตัวย่อทั่วไปที่ใช้สำหรับ Extract , Transform และ Load ความแตกต่างที่สำคัญของ ETL คือการมุ่งเน้นไปที่ระบบเดียวเพื่อแยก แปลง และโหลดข้อมูลไปยังคลังข้อมูลเฉพาะ อีกทางหนึ่ง ETL เป็นเพียงหนึ่งในองค์ประกอบที่อยู่ภายใต้ไปป์ไลน์ข้อมูล
ไปป์ไลน์ ETL จะย้ายข้อมูลเป็นแบทช์ไปยังระบบที่ระบุโดยมีช่วงเวลาที่กำหนด เมื่อเปรียบเทียบ ไปป์ไลน์ข้อมูลมีการบังคับใช้ที่กว้างกว่าในการแปลงและประมวลผลข้อมูลผ่านการสตรีมหรือเรียลไทม์
ไปป์ไลน์ข้อมูลไม่จำเป็นต้องโหลดข้อมูลไปยังคลังข้อมูล แต่สามารถเลือกโหลดไปยังเป้าหมายที่เลือกได้ เช่น บัคเก็ต S3 (Simple Storage Service) ของ Amazon หรือแม้แต่เชื่อมต่อกับระบบที่ต่างไปจากเดิมอย่างสิ้นเชิง
โซลูชันไปป์ไลน์ข้อมูลที่มีอยู่
ลักษณะและการตอบสนองการทำงานของไปป์ไลน์ข้อมูลจะแตกต่างจากเครื่องมือระบบคลาวด์ในการย้ายข้อมูลไปใช้ทันทีสำหรับโซลูชันแบบเรียลไทม์
- บนคลาวด์
อัตราส่วนต้นทุนและผลประโยชน์ของการใช้เครื่องมือบนคลาวด์เพื่อรวมข้อมูลค่อนข้างสูง ธุรกิจได้เรียนรู้ที่จะรักษาโครงสร้างพื้นฐานที่ทันสมัยโดยใช้วิธีการและทรัพยากรน้อยที่สุด อย่างไรก็ตาม กระบวนการในการเลือกผู้ขายเพื่อจัดการไปป์ไลน์ข้อมูลเป็นอีกเรื่องหนึ่งโดยสิ้นเชิง
- โอเพ่นซอร์ส
คำนี้มีความหมายแฝงที่ชัดเจนสำหรับนักวิทยาศาสตร์ด้านข้อมูลที่ต้องการไปป์ไลน์ข้อมูลที่โปร่งใสซึ่งไม่หลอกลวงการใช้ข้อมูลในนามของลูกค้า เครื่องมือโอเพนซอร์สเหมาะอย่างยิ่งสำหรับเจ้าของธุรกิจขนาดเล็กที่ต้องการต้นทุนที่ต่ำกว่าและการพึ่งพาผู้ขายมากเกินไป อย่างไรก็ตาม ประโยชน์ของเครื่องมือดังกล่าวต้องอาศัยความเชี่ยวชาญและความเข้าใจในการใช้งานเพื่อปรับแต่งและปรับเปลี่ยนประสบการณ์ของผู้ใช้
- การประมวลผลตามเวลาจริง
การนำการประมวลผลตามเวลาจริงไปใช้เป็นประโยชน์สำหรับธุรกิจที่ต้องการประมวลผลข้อมูลจากแหล่งสตรีมมิงที่มีการควบคุม นอกจากนี้ ตลาดการเงินและอุปกรณ์มือถือยังรองรับการประมวลผลแบบเรียลไทม์ ที่กล่าวว่าการประมวลผลแบบเรียลไทม์ต้องการการโต้ตอบของมนุษย์น้อยที่สุด ตัวเลือกการปรับขนาดอัตโนมัติ และพาร์ติชั่นที่เป็นไปได้
- การใช้แบทช์
การประมวลผลแบบกลุ่มช่วยให้ธุรกิจสามารถขนส่งข้อมูลจำนวนมากในช่วงเวลาต่างๆ ได้อย่างง่ายดายโดยไม่ต้องมีการมองเห็นแบบเรียลไทม์ กระบวนการนี้ช่วยให้นักวิเคราะห์ที่รวมข้อมูลการตลาดจำนวนมากเข้าด้วยกันเพื่อสร้างผลลัพธ์หรือรูปแบบที่เด็ดขาดได้ง่ายขึ้น
กระบวนการอัตโนมัติ
ไม่จำเป็นต้องทำซ้ำเพื่อ กำหนด แยก โหลด และ แปลง ข้อมูล โปรดจำไว้ว่า คุณต้องป้อนงานด้วยตนเองในช่วงเริ่มต้นของโปรแกรมเท่านั้น และระบบจะทำให้กระบวนการทั้งหมดเป็นแบบอัตโนมัติ อย่างไรก็ตาม กระบวนการอัตโนมัตินั้นต้องการนักแปลที่สามารถปรับให้เข้ากับความต้องการของธุรกิจได้

นอกจากนี้ ปัจจัยการทำซ้ำยังทำให้สะดวกสำหรับผู้ใช้ในการเข้าถึงข้อมูลด้วยการรักษาความปลอดภัยที่น่าเชื่อถือ อย่างไรก็ตาม คุณต้องเข้าใจว่ากระบวนการทั้งหมดมีความอ่อนไหวต่อการดีบัก สิ่งนี้นำไปสู่การ เปลี่ยนแปลง การวิเคราะห์ และ การควบรวม ข้อมูล อย่างหลีกเลี่ยงไม่ได้
ความสำเร็จของโครงการที่มีมูลค่าสูงนั้นขึ้นอยู่กับระดับความเชี่ยวชาญและการฝึกอบรมของนักวิทยาศาสตร์ข้อมูลที่ได้รับการว่าจ้าง อย่างไรก็ตาม สำหรับบางธุรกิจ การเพิ่มฮาร์ดแวร์และบุคลากรอาจไม่ใช่ตัวเลือกที่เป็นไปได้ อย่างไรก็ตาม เพื่อประโยชน์ในการบำรุงรักษาและปรับปรุงไปป์ไลน์ข้อมูล ในที่สุดคุณต้องใช้บริการของทีมงานมืออาชีพ
- บูรณาการร่วมสมัย
ตัวเลือกโครงสร้างพื้นฐานและการทำงานนั้นไม่มีที่สิ้นสุดเมื่อพูดถึงการสร้างไปป์ไลน์ข้อมูล สอดคล้องและผสานรวมกับ Google AdWords, Analytics, โฆษณาบน Facebook, LinkedIn และ YouTube ซึ่งหมายความว่าคุณสามารถเข้าถึง UI ของคุณเพื่อพัฒนาไปป์ไลน์ข้อมูลโดยไม่ต้องพึ่งพาโค้ด

แหล่งที่มา
การตลาดดิจิทัลอาจมีการปฏิวัติในช่วงไม่กี่ปีที่ผ่านมา แต่บทบาทของนักวิทยาศาสตร์ข้อมูลก็เช่นกัน ซึ่งขณะนี้ทำให้สามารถรวมชุดข้อมูลจำนวนมากจากข้อมูล AdWords และการสตรีมเนื้อหาไปยังแพลตฟอร์มระบบคลาวด์ที่เลือกได้ในเวลาไม่กี่นาที .
คุณสามารถนำเข้าและประมวลผลชุดข้อมูลเพื่อตั้งค่าการวิเคราะห์แบบเรียลไทม์ทั่วโลก และปรับแต่งสตรีมตามโครงการต่างๆ ได้เช่นกัน ในทำนองเดียวกัน คุณสามารถเชื่อมโยงการดำเนินการข้อมูลอีกครั้ง และตรวจสอบการเรียกเก็บเงินต่อวินาที อย่างไรก็ตาม มันยังมีสภาพแวดล้อมของสถานีเวิร์กโฟลว์ที่ราบรื่นทั่วทั้งองค์กรและคลาวด์สาธารณะ ในที่สุด สิ่งนี้ทำให้การสำรวจด้วยภาพ การเชื่อมต่อกับ IoT และการล้างข้อมูลที่มีโครงสร้างง่ายขึ้นมาก
ความเหมาะสมและความสามารถในการปรับขนาดของไปป์ไลน์ข้อมูล
ความสามารถในการปรับขนาดของไปป์ไลน์ข้อมูลควรสามารถทำคะแนนข้อมูลได้หลายพันล้านจุดและขยายขนาดผลิตภัณฑ์ได้มากขึ้น นอกจากนี้ เคล็ดลับคือการจัดเก็บข้อมูลบนระบบในลักษณะที่ช่วยให้การสืบค้นง่ายขึ้น
ยิ่งไปกว่านั้น ไปป์ไลน์ข้อมูลที่ออกแบบมาอย่างดีจะเน้นที่ตัวเลือกความเหมาะสมและความสามารถในการปรับขนาดร่วมกัน ยิ่งอัตราส่วน scalability สูงเท่าไร ก็จะยิ่งเข้ากันได้มากขึ้นเท่านั้น ในทำนองเดียวกัน ใช้การฉายซ้ำเป็นเทคนิคฉุกเฉินที่มีประสิทธิภาพสำหรับการปรับปรุงข้อมูลใหม่ที่เป็นไปได้ คุณสามารถตรวจสอบจุดตรวจที่เปลี่ยนซอร์สโค้ดเพื่อดำเนินการต่อ ในทางปฏิบัติช่วยให้คุณสามารถดำเนินการผ่านไปป์ไลน์ ETL ที่ใช้ข้อมูลเมตาสำหรับจุดเริ่มต้นแต่ละรายการเพื่อตรวจสอบสถานะ ข้อมูลที่รวบรวม และการแปลงโดยรวม
การออกแบบคลัสเตอร์ของไปป์ไลน์ข้อมูลควรได้รับการปรับขนาดในการโหลดแต่ละครั้ง แทนที่จะเป็นกลไกคงที่ตลอด 24 ชั่วโมงทุกวัน ตัวอย่างเช่น AWS EMR (Elastic MapReduce) เป็นตัวอย่างที่สมบูรณ์แบบของการปรับขนาดอัตโนมัติโดยที่คลัสเตอร์ได้รับทริกเกอร์เพื่อดำเนินการผ่านลำดับ ETL เฉพาะและละทิ้งหลังจากเสร็จสิ้น สิ่งสำคัญที่ควรทราบคือ คุณสามารถปรับขนาดขึ้นหรือลงได้เสมอ ขึ้นอยู่กับลักษณะของข้อมูล
นอกจากนี้ อินเทอร์เฟซผู้ใช้ (UI) ของคุณควรมีความชัดเจนเพียงพอที่จะตรวจสอบการเรียกใช้ข้อมูลซ้ำทั้งหมดและสถานะแบตช์ นอกจากนี้ คุณสามารถวางแบบสอบถาม (UI) เหนือแบบจำลองข้อมูลหลักเพื่อวิเคราะห์และตรวจทานเงื่อนไขของไปป์ไลน์ข้อมูล ตัวอย่างเช่น apache Airflow เป็นตัวเลือกที่ใช้ได้ในการตรวจสอบสถานะ แต่รวมถึงการใช้ dev-op และการเขียนโค้ด นอกจากนี้ นี่คือจุดที่การใช้ข้อมูลเมตาทางสถาปัตยกรรมกลายเป็นสิ่งสำคัญในการตรวจสอบ ตรวจสอบความถูกต้อง และขจัดปัญหาข้อมูลการผลิตที่ซับซ้อน
ไปป์ไลน์ข้อมูลสามารถมีอิทธิพลต่อการตัดสินใจได้อย่างไร
ทุกวันนี้ ผู้มีอำนาจตัดสินใจต้องพึ่งพาวัฒนธรรมที่เน้นข้อมูลอย่างถูกต้อง นอกจากนี้ การรวมข้อมูลวิเคราะห์หลายรายการลงในแดชบอร์ดแบบง่ายเป็นหนึ่งในสาเหตุหลักของความสำเร็จอย่างแน่นอน
ข้อมูลที่มีโครงสร้างจำกัดช่วยให้เจ้าของธุรกิจและผู้ประกอบการตัดสินใจได้อย่างเหมาะสมที่สุดโดยอิงจากหลักฐานที่รวบรวมได้ อย่างไรก็ตาม รูปแบบนี้ถือเป็นจริงสำหรับผู้จัดการที่เคยตัดสินใจอย่างชาญฉลาดเกี่ยวกับการออกแบบแบบจำลองอย่างง่ายและข้อมูลสถิติเชิงพรรณนา

แหล่งที่มา
การใช้และการกระจายตัวของเมตริกสำหรับธุรกิจต่างๆ ยังขึ้นอยู่กับการสื่อสารระหว่างพนักงานและผู้จัดการด้วย กฎเดียวกันนี้มีผลบังคับใช้กับความสามารถของพนักงานและผู้จัดการในการละทิ้งการทำซ้ำและการจัดเก็บสินค้าให้ตรงตามวัตถุประสงค์
แม้ว่าข้อเท็จจริงจะยังคงอยู่ – การประเมินความเสี่ยงและการตัดสินใจอย่างกล้าหาญเป็นช่วงเวลาที่จำเป็นสำหรับการแข่งขันในตลาด นอกจากนี้ อิสระในการเข้าถึงข้อมูลจำนวนมากและการแสดงภาพยังคงเป็นส่วนหนึ่งของโซลูชัน
ที่กล่าวว่าวัฒนธรรมที่เน้นข้อมูลเป็นศูนย์กลางซึ่งเกี่ยวข้องกับตัวเลขทางสถิติ ค่าเฉลี่ย สายการแจกแจง และค่ามัธยฐานอาจเข้าใจยากสำหรับคนจำนวนหนึ่ง และนั่นคือเหตุผลที่ไฟล์ดัมพ์ไม่สร้างภาระให้กับบุคคลที่ต้องการทำการตัดสินใจที่รวดเร็วและมีประสิทธิภาพโดยอิงจากข้อมูลการวิเคราะห์ที่มีอยู่
ในขณะที่วัฒนธรรมของข้อมูลที่เติบโตขึ้นดูเหมือนจะขยายตัว การตัดสินใจเชิงคำนวณได้พึ่งพาความไว้วางใจที่หลั่งไหลเข้ามาในการรวบรวมข้อมูลมากขึ้น
Data Pipeline และบทบาทของ Visual Aesthetics
นอกเหนือจากกระบวนการทำงานแล้ว ไปป์ไลน์ควรสร้างการวิเคราะห์ภาพที่ดีที่สุดที่จิตใจมนุษย์สามารถรับรู้ได้ด้วยการเทียบเคียง ดู และออกแบบอย่างแม่นยำ การสร้างภาพข้อมูลแบบเลเยอร์ช่วยเสริมเป็นเป้าหมายสุดท้ายของกระบวนการทั้งหมด และนั่นไม่ใช่เพียงแค่ผู้ใช้เท่านั้น แต่ยังรวมถึงนักการตลาดด้วย
กฎเดียวกันนี้ใช้กับความมีชีวิตชีวาของการสื่อสาร อะไรจะเป็นจุดเริ่มต้นของการสร้างโครงข่ายประสาทเทียมที่ซับซ้อนและเน้นโมเดลที่กำลังเป็นที่นิยมหากไม่สามารถเรียกใช้รูปแบบอันเดอร์โทนพื้นฐานและการรับรู้คุณค่าของผู้คนได้
แน่นอนว่าธุรกิจต่างๆ สามารถดำเนินการเมตริกที่ตรงไปตรงมาหรือใช้โมเดลการวิเคราะห์ขั้นสูงได้ ตราบใดที่ผู้คนสามารถนำทางและเข้าใจอินเทอร์เฟซสำหรับการวิเคราะห์อย่างละเอียด ในทำนองเดียวกัน ช่องว่างระหว่างไปป์ไลน์ที่เข้ารหัสแต่ละอันควรแคบลง เพื่อให้ผู้ใช้สามารถทำการแก้ไขบางอย่างได้ตามความต้องการของตนเอง

คุณอาจต้องการสังเกตว่าไม่มีรูปแบบที่สวยงามของภาพที่ชัดเจน จำเป็นต้องได้รับการเปลี่ยนแปลง แก้ไข ค้นพบใหม่ และเชื่อมโยงกับแนวโน้มใหม่ที่น่าดึงดูด ความสัมพันธ์นี้แทบจะสังเกตเห็นได้ชัดสำหรับผู้เขียนโค้ดที่เข้าใจว่าการเฝ้าติดตามเพียงอย่างเดียวสามารถสร้างความแตกต่างได้อย่างไร
ประโยชน์ของ Data Pipeline
- เรียบง่ายและมีประสิทธิภาพ
แม้ว่าไปป์ไลน์ข้อมูลอาจมีโครงสร้างพื้นฐานที่ซับซ้อนและกระบวนการทำงาน แต่การใช้งานและการนำทางนั้นค่อนข้างตรงไปตรงมา ในทำนองเดียวกัน กระบวนการเรียนรู้ในการสร้างไปป์ไลน์ข้อมูลสามารถทำได้โดยใช้วิธีปฏิบัติทั่วไปของภาษา Java Virtual Machine (JVM) เพื่ออ่านและเขียนไฟล์
ในทางกลับกัน จุดประสงค์พื้นฐานของ รูปแบบ มัณฑนากร คือการเปลี่ยนการทำงานแบบง่ายให้กลายเป็นรูปแบบที่แข็งแกร่ง โปรแกรมเมอร์ชื่นชมความสะดวกในการเข้าถึงข้อมูลไพพ์มากกว่าใครๆ
- ความเข้ากันได้กับแอพ
ลักษณะที่ฝังตัวของไปป์ไลน์ข้อมูลทำให้ง่ายต่อการใช้งานสำหรับลูกค้าและนักยุทธศาสตร์การตลาดดิจิทัล ความเข้ากันได้ที่เหมาะสมทำให้ไม่จำเป็นต้องติดตั้ง มีไฟล์กำหนดค่า หรือพึ่งพาเซิร์ฟเวอร์ คุณสามารถเข้าถึงข้อมูลได้อย่างสมบูรณ์โดยเพียงแค่ฝังไปป์ไลน์ข้อมูลขนาดเล็กลงในแอป
- ความยืดหยุ่นของข้อมูลเมตา
การแยกฟิลด์และเร็กคอร์ดแบบกำหนดเองเป็นหนึ่งในลักษณะที่มีประสิทธิภาพของไปป์ไลน์ข้อมูล ข้อมูลเมตาช่วยให้คุณสามารถติดตาม แหล่งที่มา ของข้อมูล ผู้สร้าง แท็ก คำแนะนำ การเปลี่ยนแปลง ใหม่ และ ตัวเลือก การมองเห็น
- ส่วนประกอบในตัว
แม้ว่าคุณสามารถเข้าถึงตัวเลือกที่ปรับแต่งได้ แต่ไปป์ไลน์ข้อมูลก็มีส่วนประกอบในตัวที่ช่วยให้คุณดึงข้อมูลเข้าหรือออกจากไปป์ไลน์ได้ หลังจากเปิดใช้งานในตัว คุณสามารถเริ่มทำงานกับข้อมูลผ่านตัวดำเนินการสตรีม

แหล่งที่มา
- การแบ่งส่วนข้อมูลตามเวลาจริงอย่างรวดเร็ว
ไม่ว่าข้อมูลของคุณจะถูกจัดเก็บในรูปแบบไฟล์ excel ที่แพลตฟอร์มโซเชียลมีเดียออนไลน์ หรือบนฐานข้อมูลระยะไกล ไปป์ไลน์ข้อมูลสามารถแบ่งข้อมูลส่วนเล็กๆ ของข้อมูลซึ่งเป็นส่วนหนึ่งของเวิร์กโฟลว์การสตรีมที่ใหญ่ขึ้นได้
และการทำงานตามเวลาจริงไม่จำเป็นต้องใช้เวลามากเกินไปในการประมวลผลข้อมูลของคุณ ส่งผลให้พื้นที่ว่างในการประมวลผลและอนุมานข้อมูลได้ง่ายขึ้น
- การประมวลผลในหน่วยความจำ
ด้วยความพร้อมใช้งานของไปป์ไลน์ข้อมูล คุณไม่จำเป็นต้องจัดเก็บหรือบันทึกการเปลี่ยนแปลงใหม่ในข้อมูลในไฟล์ ดิสก์ หรือฐานข้อมูลแบบสุ่ม ไปป์ไลน์ออกแรงฟังก์ชั่นในหน่วยความจำที่ทำให้การเข้าถึงข้อมูลได้เร็วกว่าการเก็บไว้ในดิสก์
ยุคของบิ๊กดาต้า
มักใช้คำว่า ' ข้อมูล ขนาดใหญ่ ' ในทางที่ผิด เป็นคำที่กว้างกว่าซึ่งเกี่ยวข้องกับสิ่งที่เกิดขึ้นในช่วงสองสามปีที่ผ่านมาในโลกของการวิเคราะห์ แต่จุดประสงค์ของเครื่องมือการรวมข้อมูลขนาดใหญ่นั้นส่วนใหญ่เป็นการรวบรวมเหตุการณ์และแหล่งข้อมูลมากมายเพื่อสร้างแดชบอร์ดที่ครอบคลุม ตอนนี้ จำไว้ว่า คุณสามารถประกอบ ทำซ้ำ ล้าง แปลง และสร้างข้อมูลที่มีอยู่ใหม่เพื่อให้มีฟังก์ชันการนำทางที่ราบรื่นด้วยเครื่องมือซอฟต์แวร์วิเคราะห์ข้อมูลเหล่านี้

แหล่งที่มา
นอกจากนี้ เครื่องมือที่มีอยู่ส่วนใหญ่สามารถสื่อสารกับไฟล์ขนาดใหญ่ ฐานข้อมูล อุปกรณ์มือถือจำนวนมาก IoTs บริการสตรีมมิ่ง และ API ต่อจากนั้น กระบวนการสื่อสารนี้จะสร้างบันทึกในที่เก็บข้อมูลบนคลาวด์หรือซอฟต์แวร์ภายในองค์กร เครื่องมือ SaaS ETL เช่น การวิเคราะห์ เครื่องกวาดหิมะ ข้อมูล ตะเข็บ หรือ ห้า ท ราน มาพร้อมกับไดรเวอร์และปลั๊กอินเพิ่มเติมเพื่อให้การผสานรวมเป็นไปอย่างราบรื่นที่สุด
ที่กล่าวว่าผู้มีอำนาจตัดสินใจได้ตระหนักว่าเครื่องมือเหล่านี้เป็นเพียงหนทางสู่จุดจบ พวกเขาให้บริการตามเป้าหมายในการดึงและจัดเก็บข้อมูลที่ไม่มีโครงสร้าง ในทางกลับกัน ธุรกิจต่างๆ เริ่มเข้าใจว่าไปป์ไลน์ข้อมูลอาจเปิดประตูใหม่เพื่อรวบรวมข้อมูลการวิเคราะห์ แต่ความรับผิดชอบในการตัดสินใจเชิงตรรกะยังคงตกอยู่ที่พวกเขา
ความคิดสุดท้าย
ความเหนือกว่าทางเทคโนโลยีของไปป์ไลน์ข้อมูลจะเพิ่มขึ้นอย่างต่อเนื่องเพื่อรองรับกลุ่มข้อมูลขนาดใหญ่ขึ้นพร้อมความสามารถในการเปลี่ยนแปลง ที่กล่าวว่าแนวโน้มอนาคตของไปป์ไลน์ข้อมูลมีความสำคัญเกือบเท่ากับเมื่อทศวรรษที่แล้ว กระบวนการใหม่สำหรับไปป์ไลน์ข้อมูลที่ได้รับการตรวจสอบอย่างดีนั้นอยู่ในขอบฟ้าเสมอ และความจำเป็นในการบรรลุการออกแบบที่ไร้ที่ติ การปฏิบัติตามข้อกำหนด ประสิทธิภาพการทำงาน ความสามารถในการปรับขนาดที่สูงขึ้น และการออกแบบที่น่าดึงดูดกำลังมุ่งไปสู่การปรับปรุงอย่างแน่นอน
Improvado คือโซลูชันไปป์ไลน์ข้อมูลอันดับ 1 สำหรับนักการตลาด เครื่องมือ ETL ที่ใช้ในการแยก แปลง และโหลดข้อมูลจากกว่า 150 แพลตฟอร์มการตลาดที่แตกต่างกันไปยังปลายทางสุดท้าย เช่น เครื่องมือ BI หรือคลังข้อมูล เรียนรู้เพิ่มเติมที่นี่
คำแนะนำของเรา:
ตรวจสอบเครื่องมือและซอฟต์แวร์การวิเคราะห์การตลาดที่ดีที่สุดสำหรับปี 2022
14 เครื่องมือ ETL ที่ดีที่สุดสำหรับธุรกิจองค์กรที่น่าลองในปี 2021
วิธีปรับปรุงข้อมูลจาก Snowflake เป็น Tableau [สองวิธีง่ายๆ]