
Что такое конвейер данных?
Опубликовано: 2019-08-15Что такое конвейер данных?
Конвейер данных служит механизмом обработки, который мгновенно отправляет ваши данные через преобразующие приложения, фильтры и API.
Вы можете думать о конвейере данных как о маршруте общественного транспорта. Вы определяете, где ваши данные переходят на шину и когда они покидают шину.
Конвейер данных принимает комбинацию источников данных, применяет логику преобразования (часто разделенную на несколько последовательных этапов) и отправляет данные в место назначения загрузки, например в хранилище данных.
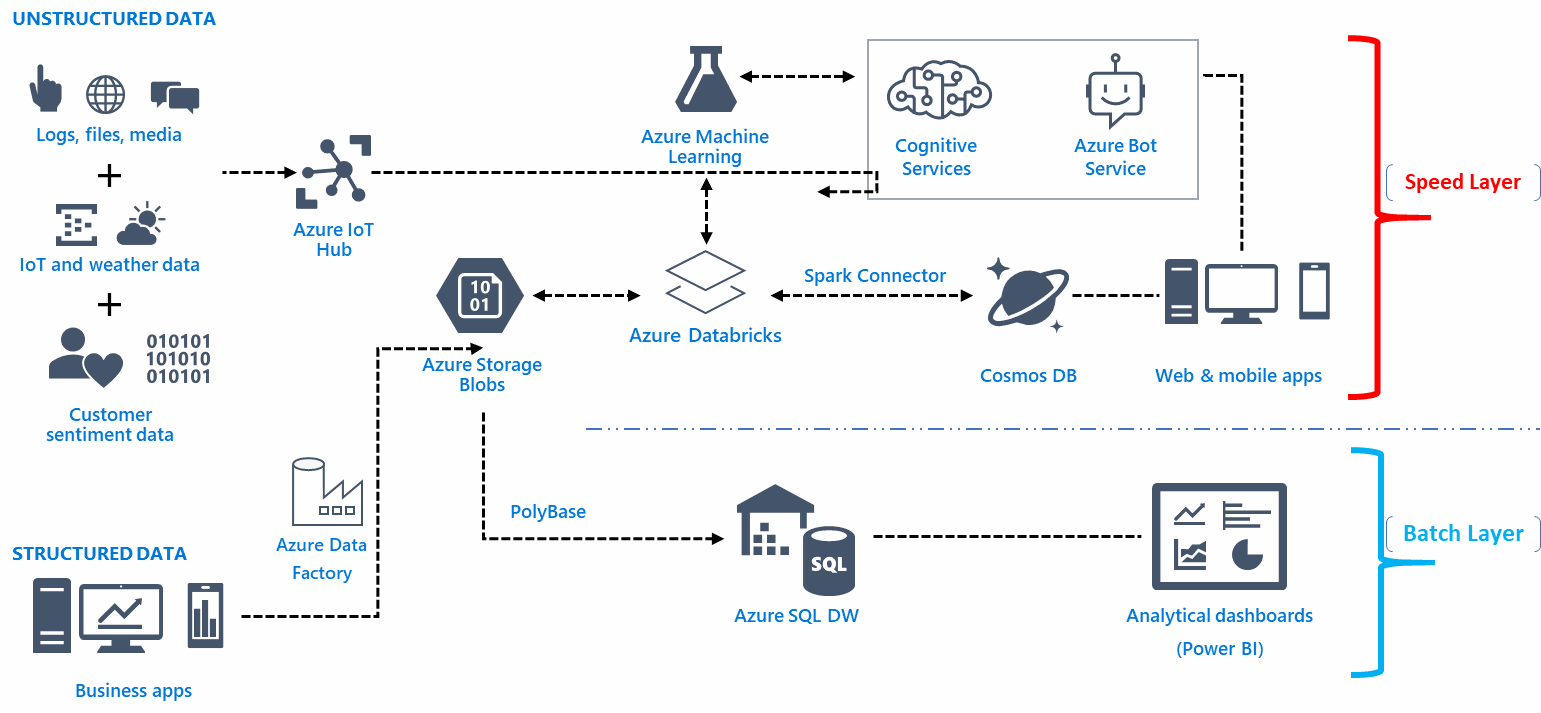
С появлением цифрового маркетинга и непрерывным технологическим прогрессом в ИТ-секторе конвейеры данных стали спасителями для сбора , преобразования , переноса и визуализации сложных данных.
По данным Adobe, только 35% маркетологов считают свою воронку эффективной. Здесь, в Improvado, мы решили изменить это.
Improvado — решение №1 для конвейера данных для маркетологов. Инструмент ETL, используемый для извлечения, преобразования и загрузки данных с более чем 150 различных маркетинговых платформ в любое конечное место назначения, например, инструмент BI или хранилище данных. Узнайте больше здесь.
Упрощенный и концентрированный характер конвейеров данных позволяет использовать гибкие схемы из статических источников и источников в реальном времени. В конечном счете, эта гибкость связана со способностью конвейеров данных разбивать данные на небольшие порции.
Взаимосвязь диапазона данных и их влияния стала более важной для бизнеса по всему миру. В то же время понимание этой взаимосвязанной связи помогает специалистам по обработке и анализу данных устранять задержки, узкие места, неопознанные источники и проблемы дублирования.
Это правда; конвейеры данных теперь дополняют системную сеть. Чем более всеобъемлющий конвейер данных, тем лучше применимость сетевой системы для объединения облачных сервисов и гибридных приложений для работы.
Рост конвейеров данных
Кроме того, конвейеры данных открыли новые возможности для интеграции многочисленных инструментов и обработки огромного количества больших файлов XML и CSV . Однако обработка данных в режиме реального времени, вероятно, стала переломным моментом для конвейеров данных.
Этот переломный момент способствовал необходимости перемещения больших блоков данных из одного места в другое без изменения формата. В результате предприятия обрели новую свободу в настройке , перемещении , сегментировании , демонстрации или передаче данных за короткий промежуток времени.
С годами объективность того, как работает бизнес, значительно изменилась. Основное внимание больше не сосредоточено на получении прибыли, а на том, как специалисты по данным могут предлагать жизнеспособные решения, которые связаны с людьми. Более того, что еще более важно, эти изменения должны быть трансформирующими , отслеживаемыми и адаптируемыми к изменяющейся будущей динамике. При этом конвейеры данных прошли долгий путь от использования плоских файлов, базы данных и озера данных до управления службами на бессерверной платформе.
Инфраструктура конвейера данных
Архитектурная инфраструктура конвейера данных опирается на основу для сбора, организации, маршрутизации или перенаправления данных для получения полезной информации. Вот в чем дело, вообще довольно значительное количество нерелевантных точек входа для сырых данных. Кроме того, здесь конвейерная инфраструктура объединяет, настраивает, автоматизирует, визуализирует, преобразовывает и перемещает данные из многочисленных ресурсов для достижения поставленных целей.
Кроме того, архитектурная инфраструктура конвейера данных дополняет функциональные возможности, основанные на аналитике и точной бизнес-аналитике. Функциональность данных означает получение ценной информации о поведении клиентов, роботизированных процессах, процессах автоматизации, а также о характере взаимодействия с клиентами и о пути пользователей. Вы узнаете о тенденциях и информации в реальном времени с помощью бизнес-аналитики и аналитики с помощью больших блоков данных.
Выбор правильной команды инженеров данных
Было бы разумно сформировать команды инженеров по работе с большими данными, которые всегда заняты деталями приложения. Нанимайте дата-инженеров, которые должны иметь возможность получать структурные данные и устранять проблемы, разбираться в сложных таблицах и своевременно внедрять функциональные данные.

Функциональность конвейера данных
Функциональность конвейера данных служит для сбора информации, но технически способ хранения, доступа и распространения данных может различаться в зависимости от конфигурации.
Например, минимизация перемещения данных возможна с помощью абстрактного слоя для рассредоточения данных без ручного перемещения каждой отдельной части информации в пользовательском интерфейсе. С помощью Alluxio вы можете создать абстрактный уровень для нескольких файловых систем между механизмом хранения и выбранным поставщиком, таким как AWS.
Функциональность конвейера данных не должна зависеть от системы баз данных поставщика. Кроме того, какой смысл создавать безошибочную и многоуровневую инфраструктуру без гибкости? Имея это в виду, ваш конвейер данных должен иметь возможность собирать полную информацию на устройстве хранения, таком как AWS , чтобы защитить будущее системы данных.
Функциональность конвейера данных должна обслуживать бизнес-аналитику, а не строить сеть исключительно на эстетическом выборе. Например, функции потоковой инфраструктуры довольно сложны в управлении и обычно требуют профессионального опыта и сильного бизнеса для решения сложных инженерных задач.
Вы можете использовать основную службу контейнеров, такую как Dockers, для создания конвейеры данных. Вы можете настроить функциональную реакцию безопасности, проверить потенциал масштабируемости и улучшить программный код с помощью контейнеров. Распространенной ошибкой, которую обычно совершают люди при создании функционального ответа, является неравномерное выполнение и распределение операций. Хитрость заключается в том, чтобы избежать использования основного файла преобразования в SQL и адаптировать метод CTAS для установки нескольких параметров файла и операций.
Хотя такие базы данных, как Snowflake и Presto, предоставляют вам встроенный доступ к SQL, большой объем данных неизбежно сокращает время пользовательского интерфейса. Поэтому применяйте алгоритмы, ориентированные на скорость, которые приводят к незначительной ошибке вывода.
Инструменты для построения конвейера данных
Столбчатая файловая система вашего конвейера данных должна иметь возможность хранить и сжимать окончательные накопительные данные. Механизмы данных увеличивают использование таких файловых систем в пользовательском интерфейсе. Кроме того, для достижения убедительной визуализации используйте iPython или Jupyter в качестве блокнотов. Вы даже можете создавать шаблоны записных книжек на основе определенных параметров, чтобы получить встроенные функции для аудита данных, выделения графиков, фокусировки соответствующих графиков или просмотра данных в целом.
Вы можете перенести это конкретное подмножество данных в удаленное место с помощью таких инструментов, как Google Cloud Platform (GCP), Python или Kafka . Вам не нужно создавать окончательную версию кода с первого раза — инициируйте с помощью функции библиотеки Faker в Python , чтобы написать и протестировать код в конвейере данных.

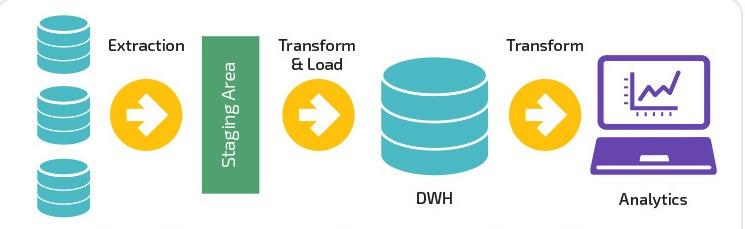
В чем разница между конвейером данных и ETL?
ETL — это общепринятая аббревиатура, используемая для извлечения , преобразования и загрузки. Основное отличие ETL заключается в том, что он полностью сосредоточен на одной системе для извлечения, преобразования и загрузки данных в конкретное хранилище данных. С другой стороны, ETL — это всего лишь один из компонентов конвейера данных.
Конвейеры ETL перемещают данные пакетами в указанную систему с регулируемыми интервалами. Для сравнения, конвейеры данных имеют более широкое применение для преобразования и обработки данных посредством потоковой передачи или в режиме реального времени.
Конвейеры данных не обязательно должны загружать данные в хранилище данных, но могут выбрать загрузку в выборочную цель, такую как корзина Amazon S3 (Simple Storage Service), или даже подключить ее к совершенно другой системе.
Доступные решения для передачи данных
Характер и функциональный ответ конвейера данных будет отличаться от облачных инструментов для переноса данных, чтобы напрямую использовать их для решения в реальном времени.
- Облачный
Соотношение затрат и выгод от использования облачных инструментов для объединения данных довольно велико. Бизнес научился поддерживать инфраструктуру в актуальном состоянии с минимальным использованием средств и ресурсов. Однако процесс выбора поставщиков для управления конвейерами данных — это совсем другое дело.
- Открытый источник
Этот термин имеет сильное значение для ученых, занимающихся данными, которым нужны прозрачные конвейеры данных, которые не мошеннически используют данные от имени клиентов. Инструменты с открытым исходным кодом идеально подходят для владельцев малого бизнеса, которые хотят снизить затраты и чрезмерно полагаться на поставщиков. Однако полезность таких инструментов требует опыта и функционального понимания для адаптации и изменения взаимодействия с пользователем.
- Обработка в реальном времени
Реализация обработки в реальном времени выгодна для предприятий, которые хотят обрабатывать данные из регулируемого источника потоковой передачи. Кроме того, финансовый рынок и мобильные устройства совместимы для обработки в реальном времени. Тем не менее, обработка в реальном времени требует минимального участия человека, параметров автоматического масштабирования и возможных разделов.
- Использование пакетной обработки
Пакетная обработка позволяет компаниям легко передавать большие объемы данных через определенные промежутки времени, не требуя просмотра в реальном времени. Этот процесс упрощает работу аналитиков, которые объединяют множество маркетинговых данных для формирования решающего результата или модели.
Автоматизированный процесс
Ну, это избавляет от необходимости повторять определение , извлечение , загрузку и преобразование данных. Помните, что только в начале программы вы должны вводить ручную работу, и система автоматизирует ее для всего процесса. Однако процесс автоматизации требует переводчика, который может согласовать и адаптировать потребности бизнеса.

Кроме того, фактор воспроизводимости позволяет пользователям получать доступ к данным с достаточной безопасностью. Однако нужно понимать, что весь процесс подвержен отладке. Это неизбежно приводит к изменению анализа и объединению данных .
Завершение дорогостоящих проектов полностью зависит от уровня знаний и подготовки нанятого специалиста по данным. Однако для некоторых предприятий добавление оборудования и людей может оказаться неосуществимым вариантом. Тем не менее, для обслуживания и улучшения конвейера данных вам в конечном итоге потребуется прибегнуть к услугам профессиональной команды.
- Современные интеграции
Инфраструктурные и функциональные возможности безграничны, когда речь идет о создании конвейеров данных, согласованных и интегрированных с Google AdWords, Analytics, Facebook Ads, LinkedIn и интеграцией с YouTube. Это означает, что вы можете получить доступ к своему пользовательскому интерфейсу для разработки конвейеров данных, не полагаясь на код.

Источник
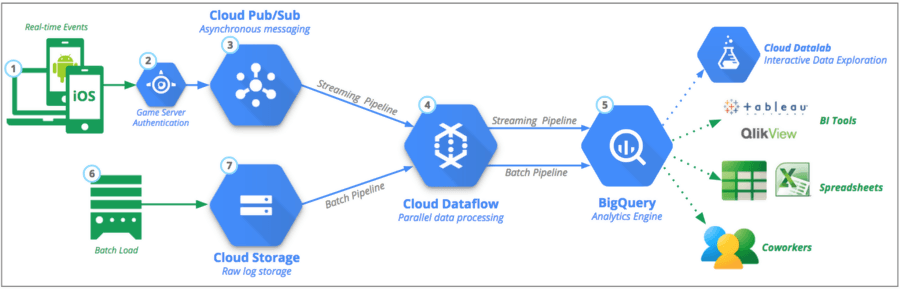
Цифровой маркетинг, возможно, произвел революцию за последние несколько лет, но роль специалистов по обработке и анализу данных также возросла, и теперь они позволяют объединять большие фрагменты ваших наборов данных из данных AdWords и потокового контента на выбранную облачную платформу за считанные минуты. .
Вы можете принимать и обрабатывать наборы данных для настройки аналитики в реальном времени по всему миру, а также персонализировать потоки в разных проектах. Точно так же вы можете повторно связать операции с данными и проверить посекундную тарификацию. Тем не менее, он также предлагает единую среду рабочих станций в локальной и общедоступной облачной среде. В конечном итоге это значительно упрощает визуальное исследование, подключение к Интернету вещей и очистку структурированных данных.
Пригодность и масштабируемость конвейеров данных
Масштабируемость конвейера данных должна обеспечивать миллиарды точек данных и значительно большее масштабирование продукта. Кроме того, хитрость заключается в том, чтобы хранить данные в системе таким образом, чтобы облегчить доступ к запросам.
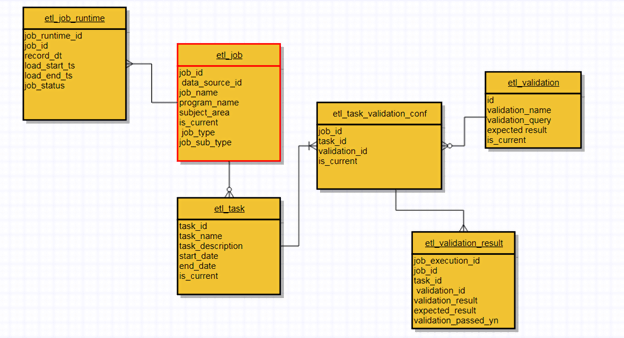
Более того, хорошо спроектированный конвейер данных фокусируется на параметрах пригодности и масштабируемости вместе. Чем выше коэффициент масштабируемости, тем более он будет совместим. Точно так же используйте повторы как эффективную технику на случай непредвиденных обстоятельств для возможного переформулирования данных. Вы можете проверить контрольную точку, изменив исходный код, чтобы возобновить процесс. Это практически позволяет вам проходить конвейеры ETL, которые используют метаданные для каждой точки входа для проверки состояния, собранных данных и общего преобразования.
Кластерный дизайн конвейера данных должен масштабироваться при каждой загрузке вместо фиксированного механизма 24/7. Например, AWS EMR (Elastic MapReduce) — прекрасный пример автоматического масштабирования, когда кластеры получают триггер для выполнения определенной последовательности ETL и отбрасывают ее после завершения. Важно отметить, что вы всегда можете увеличить или уменьшить масштаб в зависимости от характера данных.
Кроме того, ваш пользовательский интерфейс (UI) должен быть достаточно четким, чтобы отслеживать полные повторные запуски данных и статус пакета. Кроме того, вы можете поместить запрос (UI) в первичную модель данных, чтобы проанализировать и просмотреть состояние конвейера данных. Например, Apache Airflow является жизнеспособным вариантом для мониторинга состояния, но он включает в себя использование разработки и написания кода. Кроме того, именно здесь использование архитектурных метаданных становится необходимым для мониторинга, проверки валидации и устранения сложных проблем с данными о производительности.
Как конвейеры данных могут влиять на принятие решений
Сегодня лица, принимающие решения, по праву зависят от культуры, ориентированной на данные. Более того, объединение нескольких аналитических данных в упрощенную информационную панель, безусловно, является одной из основных причин его успеха.
Ограниченные структурированные данные помогают владельцам бизнеса и предпринимателям принимать оптимальные решения на основе собранных данных. Однако эта закономерность верна для менеджеров, которые привыкли принимать обоснованные решения на основе простых моделей моделирования и описательных статистических данных.

Источник
Использование и диверсификация метрик для разных предприятий также зависит от общения между сотрудниками и менеджерами. Те же правила применяются, когда речь идет о способности сотрудников и менеджеров отбрасывать дублирование и использовать запасы для достижения нужных целей.
Хотя факт остается фактом – оценка рисков и принятие смелых решений всегда были необходимостью, чтобы конкурировать на рынке. Кроме того, частью решения остается свобода доступа к большим массивам данных и визуализации.
Тем не менее, эта ориентированная на данные культура, включающая статистические цифры, средние значения, линии распределения и медианы, может быть трудна для понимания для многих людей. И именно поэтому файл дампа не перегружает людей, которые хотят принимать быстрые и надежные решения на основе доступных аналитических данных.
По мере того, как растущая культура данных, кажется, расширяется, расчетливое принятие решений становится все более зависимым от доверия к сбору данных.
Конвейеры данных и роль визуальной эстетики
Помимо функционального процесса, конвейеры должны формировать наилучший визуальный анализ, который человеческий разум может воспринять путем точного распараллеливания, просмотра и проектирования. Многоуровневая визуализация дополняет конечную цель всего процесса. И это в пользу не только пользователей, но и маркетологов.
Те же правила применимы и к жизненности общения. Какой смысл создавать сложную нейронную сеть и выделять трендовые модели, если она не может вызывать базовые полутоновые паттерны и узнавать ценности среди людей?
Конечно, предприятия могут использовать простые метрики или использовать продвинутые аналитические модели; до тех пор, пока люди могут ориентироваться и понимать интерфейс для тщательного анализа. Точно так же разрыв между каждым закодированным конвейером должен быть узким, чтобы пользователи могли вносить определенные изменения в соответствии со своими требованиями.

Вы можете заметить, что не существует определенного визуального эстетического стиля. Он должен претерпевать изменения, пересмотры, переоткрытия и привязку к новым увлекательным тенденциям. Эта корреляция почти осязаема для программистов, которые понимают, что просто мониторинг может иметь все значение.
Преимущества конвейера данных
- Просто и эффективно
Хотя конвейеры данных могут иметь сложную инфраструктуру и процесс функционирования, их использование и навигация довольно просты. Точно так же процесс обучения построению конвейера данных достижим с помощью обычной практики (JVM) языка виртуальной машины Java для чтения и записи файлов.
Основная цель шаблона декоратора , с другой стороны, состоит в том, чтобы превратить упрощенную операцию в надежную. Программисты больше, чем кто-либо, ценят простоту доступа к данным конвейера.
- Совместимость с приложениями
Встроенная природа конвейеров данных упрощает их использование как для клиентов, так и для специалистов по цифровому маркетингу. Его подходящая совместимость избавляет от необходимости устанавливать, иметь файлы конфигурации или полагаться на сервер. Вы можете получить полный доступ к данным, просто внедрив небольшой конвейер данных в приложение.
- Гибкость метаданных
Разделение настраиваемых полей и записей — одна из эффективных черт конвейера данных. Метаданные позволяют отслеживать источник данных, создателя , теги , инструкции , новые изменения и параметры видимости .
- Встроенные компоненты
Хотя настраиваемый параметр доступен для вас, конвейеры данных имеют встроенные компоненты, которые позволяют вам получать данные в конвейер или из него. После встроенной активации вы можете начать работать с данными через потоковые операторы.

Источник
- Быстрая сегментация данных в реальном времени
Независимо от того, хранятся ли ваши данные в виде файла Excel, на онлайн-платформе социальных сетей или в удаленной базе данных, конвейеры данных могут разбивать данные на небольшие фрагменты, которые являются фундаментальной частью более крупного потокового рабочего процесса.
А работа в режиме реального времени не требует лишнего времени на обработку ваших данных. Следовательно, это оставляет вам пространство для маневра, чтобы вам было легче обрабатывать и делать выводы из имеющихся данных.
- Обработка в памяти
Благодаря наличию конвейеров данных вам не нужно хранить или сохранять новые изменения данных в файле, на диске или в произвольной базе данных. Конвейеры реализуют функцию в памяти, которая обеспечивает более быстрый доступ к данным, чем их хранение на диске.
Эпоха больших данных
Использование термина « большие данные» часто используется неправильно. Это более широкий термин, относящийся к тому, что произошло за последние пару лет в аналитическом мире. Но цель инструментов интеграции больших данных в основном состоит в том, чтобы собирать события и множество источников для создания комплексной информационной панели. Теперь помните, что вы можете собирать, дублировать, очищать, преобразовывать и регенерировать доступные данные, чтобы иметь плавную навигацию с помощью этих программных инструментов для анализа данных.

Источник
Кроме того, большинство доступных инструментов могут взаимодействовать с большими файлами, базами данных, многочисленными мобильными устройствами, IoT, потоковыми сервисами и API. Впоследствии этот процесс связи создает запись в облачном хранилище или локальном программном обеспечении. Инструменты SaaS ETL, такие как аналитика снегоочистителя , данные о стежках или пять транзакций, например , поставляются с дополнительными драйверами и подключаемыми модулями, чтобы сделать интеграцию максимально плавной.
Тем не менее, лица, принимающие решения, пришли к пониманию, что эти инструменты — всего лишь средства для достижения цели. Они служат для извлечения и хранения неструктурированных данных. Бизнес, с другой стороны, начал понимать, что конвейеры данных, возможно, открыли новые возможности для сбора аналитических данных, но ответственность за принятие логических решений по-прежнему лежит на них.
Последние мысли
Технологическое превосходство конвейеров данных будет продолжать расти, чтобы обеспечить возможность преобразования больших сегментов данных. Тем не менее, футуристическая тенденция конвейеров данных почти так же важна, как и десять лет назад. Новый процесс для хорошо контролируемого конвейера данных всегда на горизонте. И эта потребность в безупречном дизайне, соответствии нормативным требованиям, эффективности производительности, высокой масштабируемости и привлекательном дизайне, безусловно, находится в процессе улучшения.
Improvado — решение №1 для конвейера данных для маркетологов. Инструмент ETL, используемый для извлечения, преобразования и загрузки данных с более чем 150 различных маркетинговых платформ в любое конечное место назначения, например, инструмент BI или хранилище данных. Узнайте больше здесь.
Наша рекомендация:
Ознакомьтесь с лучшими инструментами и программным обеспечением для маркетинговой аналитики на 2022 год.
14 лучших инструментов ETL для корпоративных предприятий, которые стоит попробовать в 2021 году
Как упростить данные из Snowflake в Tableau [два простых способа]