
Che cos'è una pipeline di dati?
Pubblicato: 2019-08-15Che cos'è una pipeline di dati?
Una pipeline di dati funge da motore di elaborazione che invia istantaneamente i dati tramite applicazioni, filtri e API trasformativi.
Puoi pensare a una pipeline di dati come a un percorso di trasporto pubblico. Definisci dove i tuoi dati saltano sul bus e quando lasciano il bus.
Una pipeline di dati acquisisce una combinazione di origini dati, applica la logica di trasformazione (spesso suddivisa in più fasi sequenziali) e invia i dati a una destinazione di caricamento, ad esempio un data warehouse.
Con l'avvento del marketing digitale e il continuo progresso tecnologico nel settore IT, le pipeline di dati sono diventate salvatrici per la raccolta , la conversione , la migrazione e la visualizzazione di dati complessi.
Secondo Adobe, solo il 35% dei marketer pensa che la propria pipeline sia efficiente. Qui a Improvado, abbiamo deciso di cambiarlo.
Improvado è la soluzione di pipeline di dati n. 1 per gli esperti di marketing. Uno strumento ETL utilizzato per estrarre, trasformare e caricare dati da oltre 150 diverse piattaforme di marketing in qualsiasi destinazione finale, come uno strumento di BI o un data warehouse. Scopri di più qui.
La natura semplificata e concentrata delle pipeline di dati consente schemi flessibili da origini statiche e in tempo reale. In definitiva, questa flessibilità si ricollega alla capacità delle pipeline di dati di suddividere i dati in piccole porzioni.
La relazione tra la gamma di dati e il suo impatto è diventata più vitale per le aziende di tutto il mondo. Allo stesso tempo, la comprensione di questo legame interconnesso aiuta i data scientist a risolvere latenza, colli di bottiglia, fonti non identificate e problemi di duplicazione.
È vero; le pipeline di dati ora completano la rete del sistema. Più la pipeline di dati è completa, migliore è l'applicabilità del sistema di rete: combinare servizi cloud e applicazioni ibride per il lavoro.
L'ascesa delle pipeline di dati
Inoltre, le pipeline di dati hanno aperto nuove porte per integrare numerosi strumenti e acquisire una quantità enorme di file XML e CSV di grandi dimensioni. L'elaborazione dei dati in tempo reale, tuttavia, è stata probabilmente il punto di svolta per le pipeline di dati.
Quel punto di svolta ha facilitato la necessità dell'ora di spostare grandi quantità di dati da un luogo all'altro senza modificare il formato. Di conseguenza, le aziende hanno ritrovato la libertà di modificare , spostare , segmentare , mostrare o trasferire i dati in un breve lasso di tempo.
Nel corso degli anni, l'obiettività del modo in cui operano le imprese è cambiata in modo significativo. L'obiettivo non è più quello di ottenere margini di profitto, ma di come i data scientist possono presentare soluzioni praticabili che si connettono con le persone. Inoltre, cosa ancora più importante, quei cambiamenti devono essere trasformativi , tracciabili e adattabili per cambiare le dinamiche future. Detto questo, le pipeline di dati hanno fatto molta strada dall'utilizzo di file flat, database e data lake alla gestione dei servizi su una piattaforma serverless.
Infrastruttura di pipeline di dati
L'infrastruttura architettonica di una pipeline di dati si basa su fondamenta per acquisire, organizzare, instradare o reindirizzare i dati per ottenere informazioni approfondite. Ecco il fatto, generalmente c'è un numero piuttosto significativo di punti di ingresso irrilevanti per i dati grezzi. Inoltre, è qui che l'infrastruttura della pipeline combina, personalizza, automatizza, visualizza, trasforma e sposta i dati da numerose risorse per raggiungere gli obiettivi prefissati.
Inoltre, l'infrastruttura architettonica di una pipeline di dati integra le funzionalità basate sull'analisi e sulla business intelligence precisa. La funzionalità dei dati significa ottenere informazioni preziose sul comportamento dei clienti, sul processo robotico, sul processo di automazione e sul modello dell'esperienza del cliente e sul modello del percorso degli utenti. Impari le tendenze e le informazioni in tempo reale attraverso la business intelligence e l'analisi tramite grandi blocchi di dati.
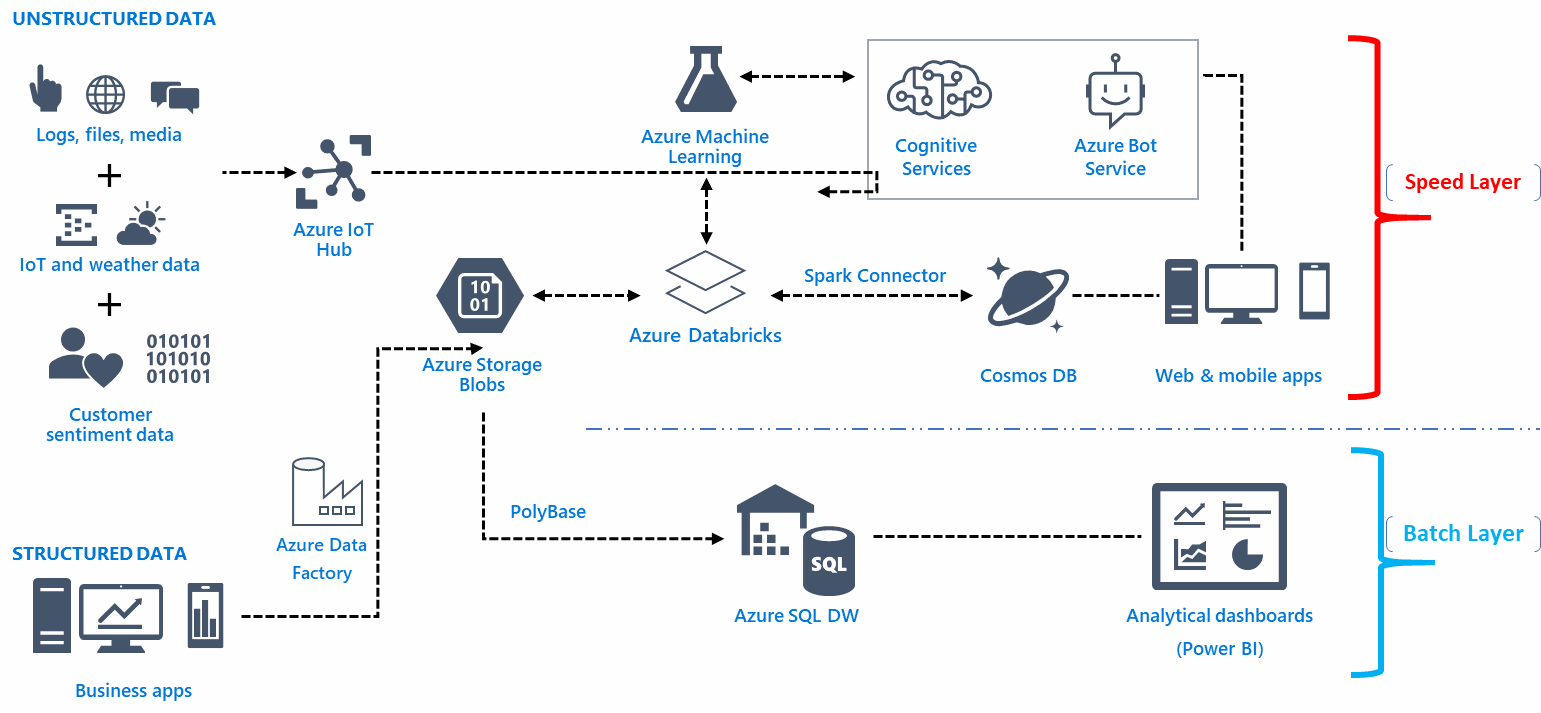
Scegliere il giusto team di ingegneria dei dati
Sarebbe saggio formare team di ingegneria dei big data sempre impegnati con i dettagli dell'applicazione. Assumi gli ingegneri dei dati che dovrebbero essere in grado di ottenere i dati strutturali e risolvere i problemi, comprendere tabelle complesse e implementare i dati funzionali in modo tempestivo.

La funzionalità della pipeline di dati
La funzionalità di una pipeline di dati svolge il ruolo di raccolta di informazioni, ma tecnicamente il metodo per archiviare, accedere e diffondere i dati può variare a seconda della configurazione.
Ridurre al minimo lo spostamento dei dati, ad esempio, è possibile attraverso un livello astratto per disperdere i dati senza spostare manualmente ogni singola informazione sull'interfaccia utente. Puoi creare un livello astratto per più file system con l'aiuto di Alluxio tra il meccanismo di archiviazione e il fornitore selezionato come AWS.
La funzionalità di una pipeline di dati non dovrebbe fare affidamento sulla clemenza del sistema di database del fornitore. Inoltre, che senso avrebbe creare un'infrastruttura priva di errori e stratificata senza flessibilità? Tenendo presente questo, la tua pipeline di dati dovrebbe essere in grado di raccogliere informazioni complete in un dispositivo di archiviazione come AWS per salvaguardare il futuro del sistema di dati.
La funzionalità della pipeline di dati dovrebbe soddisfare l'analisi aziendale invece di costruire la rete interamente su scelte estetiche. Le funzioni di un'infrastruttura di streaming, ad esempio, sono piuttosto difficili da gestire e generalmente richiedono l'esperienza professionale e una solida attività per gestire complesse attività di ingegneria.
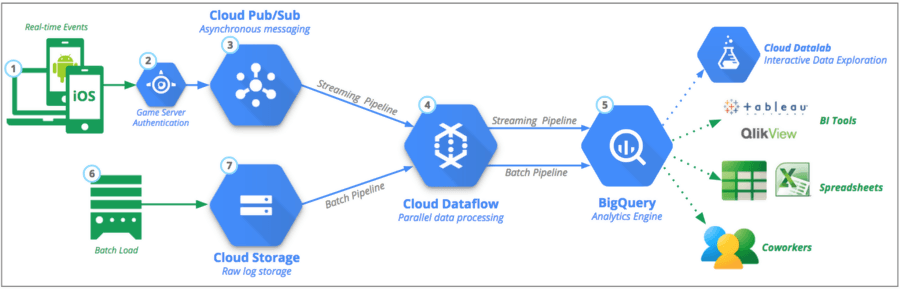
È possibile utilizzare un servizio contenitore tradizionale, come Dockers, per la creazione pipeline di dati. È possibile modificare la risposta funzionale della sicurezza, verificare il potenziale di scalabilità e migliorare il codice software con l'aiuto dei container. Un errore comune che le persone generalmente commettono durante la creazione di una risposta funzionale è eseguire e distribuire le operazioni in modo non uniforme. Il trucco è evitare di utilizzare il file di trasformazione principale in SQL e adattare il metodo CTAS per impostare più parametri e operazioni di file.
Sebbene i database come Snowflake e Presto forniscano l'accesso SQL integrato, una grande quantità di dati riduce inevitabilmente il tempo dell'interfaccia utente. Pertanto, applicare algoritmi incentrati sulla velocità che si traducono in un errore di output minore.
Strumenti per costruire una pipeline di dati
Il file system a colonne della pipeline di dati dovrebbe essere in grado di archiviare e comprimere i dati cumulativi finali. I motori di dati aumentano l'utilizzo di tali file system nell'interfaccia utente. Inoltre, per ottenere una visualizzazione convincente, usa iPython o Jupyter come notebook. Puoi persino creare modelli di notebook basati su parametri specifici per ottenere funzioni integrate per controllare i dati, evidenziare grafici, mettere a fuoco grafici rilevanti o rivedere i dati del tutto.
Puoi trasferire questo specifico sottoinsieme di dati in una posizione remota con l'aiuto di strumenti come Google Cloud Platform (GCP), Python o Kafka . Non è necessario creare una versione finalizzata del codice al primo tentativo: avviare con la funzionalità della libreria Faker in Python per scrivere e testare il codice nella pipeline di dati.

Qual è la differenza tra pipeline di dati ed ETL?
ETL è un acronimo comune utilizzato per Extract , Transform e Load. La principale differenza di ETL è che si concentra interamente su un sistema per estrarre, trasformare e caricare i dati in un particolare data warehouse. In alternativa, ETL è solo uno dei componenti che rientrano nella pipeline di dati.
Le pipeline ETL spostano i dati in batch in un sistema specifico con intervalli regolamentati. In confronto, le pipeline di dati hanno un'applicabilità più ampia per trasformare ed elaborare i dati tramite streaming o in tempo reale.
Le pipeline di dati non devono necessariamente caricare i dati in un data warehouse, ma possono scegliere di caricare su un target selettivo come il bucket S3 (Simple Storage Service) di Amazon o addirittura collegarlo a un sistema completamente diverso.
Soluzioni di pipeline di dati disponibili
La natura e la risposta funzionale della pipeline di dati sarebbero diverse dagli strumenti cloud per migrare i dati per utilizzarli a titolo definitivo per una soluzione in tempo reale.
- Basato su cloud
Il rapporto costi-benefici dell'utilizzo di strumenti basati su cloud per amalgamare i dati è piuttosto elevato. Le aziende hanno imparato a mantenere un'infrastruttura aggiornata con un utilizzo minimo di mezzi e risorse. Tuttavia, il processo per la scelta dei fornitori per la gestione delle pipeline di dati è un'altra questione.
- Open Source
Il termine ha una forte connotazione per i data scientist che desiderano pipeline di dati trasparenti che non truffano l'utilizzo dei dati per conto dei clienti. Gli strumenti open source sono ideali per i proprietari di piccole imprese che desiderano costi inferiori e un'eccessiva dipendenza dai fornitori. Tuttavia, l'utilità di tali strumenti richiede esperienza e comprensione funzionale per personalizzare e modificare l'esperienza dell'utente.
- Elaborazione in tempo reale
L'implementazione dell'elaborazione in tempo reale è vantaggiosa per le aziende che desiderano elaborare i dati da una fonte di streaming regolamentata. Inoltre, il mercato finanziario e i dispositivi mobili sono compatibili per avere elaborazioni in tempo reale. Detto questo, l'elaborazione in tempo reale richiede un'interazione umana minima, opzioni di ridimensionamento automatico e possibili partizioni.
- L'uso del lotto
L'elaborazione in batch consente alle aziende di trasportare facilmente una grande quantità di dati a intervalli senza dover richiedere visibilità in tempo reale. Il processo rende più facile per gli analisti che combinano una moltitudine di dati di marketing per formare un risultato o un modello decisivo.
Il processo automatizzato
Bene, elimina la necessità di ripetere per definire , estrarre , caricare e trasformare i dati. Ricorda, è solo all'inizio del programma che devi inserire il lavoro manuale e il sistema lo automatizza per l'intero processo. Il processo di automazione, tuttavia, richiede un traduttore in grado di allineare e personalizzare le esigenze dell'azienda.

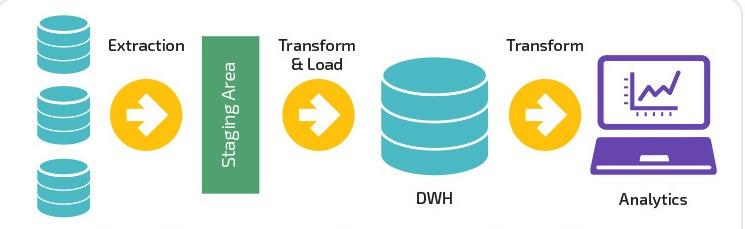
Inoltre, il fattore di riproducibilità consente agli utenti di accedere ai dati con una sicurezza plausibile. Tuttavia, è necessario comprendere che l'intero processo è soggetto a debug. Questo porta inevitabilmente a cambiamenti di analisi e fusioni di dati .
Il completamento di progetti di alto valore dipende interamente dal livello di competenza e dalla formazione del data scientist assunto. Per alcune aziende, tuttavia, l'aggiunta di hardware e persone potrebbe non essere un'opzione praticabile. Tuttavia, per motivi di manutenzione e miglioramento della pipeline di dati, alla fine è necessario coinvolgere i servizi di un team di professionisti.
- Integrazioni contemporanee
Le opzioni infrastrutturali e funzionali sono infinite quando si tratta di costruire pipeline di dati, allineate e integrate con l'integrazione di Google AdWords, Analytics, Facebook Ads, LinkedIn e YouTube. Ciò significa che puoi accedere alla tua interfaccia utente per sviluppare pipeline di dati senza dover fare affidamento sul codice.

Fonte
Il marketing digitale potrebbe essere stato rivoluzionato negli ultimi anni, ma lo ha fatto anche il ruolo dei data scientist, che ora hanno reso possibile combinare grandi porzioni dei tuoi set di dati dai dati AdWords e dai contenuti in streaming su una piattaforma cloud prescelta in pochi minuti .
Puoi importare ed elaborare set di dati per impostare analisi in tempo reale in tutto il mondo e anche personalizzare lo streaming tra diversi progetti. Allo stesso modo, puoi ricollegare le operazioni sui dati e controllare la fatturazione al secondo. Tuttavia, offre anche un ambiente di workstation senza interruzioni su cloud locali e pubblici. In definitiva, questo semplifica notevolmente l'esplorazione visiva, la connettività all'IoT e la pulizia dei dati strutturati.
Idoneità e scalabilità delle pipeline di dati
La scalabilità di una pipeline di dati dovrebbe essere in grado di ottenere miliardi di punti dati e scale di prodotto considerevolmente maggiori. Inoltre, il trucco è archiviare i dati sul sistema in modo da rendere più semplice la disponibilità delle query.
Inoltre, una pipeline di dati ben progettata si concentra sulle opzioni di idoneità e scalabilità insieme. Maggiore è il rapporto di scalabilità, maggiore sarà la compatibilità. Allo stesso modo, usa le repliche come un'efficace tecnica di emergenza per una possibile riformulazione dei dati. Puoi controllare il checkpoint modificando il codice sorgente per riprendere il processo. Ti consente praticamente di passare attraverso pipeline ETL che utilizzano metadati per ogni punto di ingresso per controllare lo stato, i dati raccolti e la trasformazione generale.
La progettazione del cluster della pipeline di dati deve essere ridimensionata su ciascun carico anziché su un meccanismo fisso 24 ore su 24, 7 giorni su 7. AWS EMR (Elastic MapReduce), ad esempio, è un perfetto esempio di ridimensionamento automatico in cui i cluster ricevono un trigger per eseguire una sequenza ETL specifica e scartarli dopo il completamento. È importante notare che è sempre possibile aumentare o diminuire la scala a seconda della natura dei dati.
Inoltre, l'interfaccia utente (UI) dovrebbe essere sufficientemente chiara per monitorare le ripetizioni complete dei dati e lo stato del batch. Inoltre, puoi inserire query (UI) sul modello di dati primario per analizzare e rivedere la condizione della pipeline di dati. Apache Airflow, ad esempio, è un'opzione praticabile per monitorare lo stato, ma include l'utilizzo di dev-op e la scrittura di codice. Inoltre, è qui che l'uso dei metadati dell'architettura diventa essenziale per monitorare, controllare le convalide e ridurre i complicati problemi relativi ai dati sulla produttività.
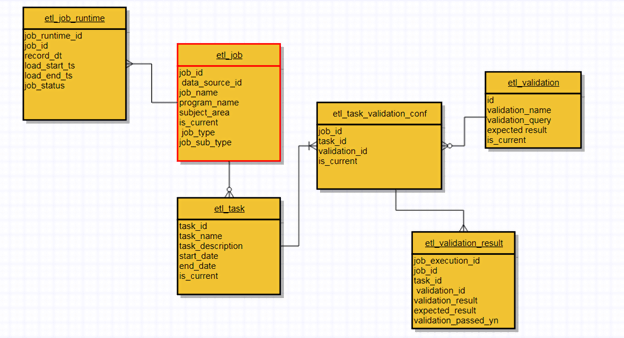
In che modo le pipeline di dati possono influenzare il processo decisionale
Oggi i decisori dipendono giustamente dalla cultura orientata ai dati. Inoltre, la combinazione di più dati analitici in una dashboard semplificata è sicuramente una delle ragioni principali del suo successo.
I dati strutturati confinati aiutano gli imprenditori e gli imprenditori a prendere decisioni ottimali sulla base delle prove raccolte. Tuttavia, questo modello vale per i manager che erano soliti prendere decisioni informate su semplici modelli di modelli e dati statistici descrittivi.

Fonte
L'utilizzo e la diversificazione delle metriche per le diverse attività dipendono anche dalla comunicazione tra dipendenti e dirigenti. Le stesse regole si applicano quando si tratta della capacità dei dipendenti e dei dirigenti di eliminare le duplicazioni e lo stoccaggio per gli obiettivi giusti.
Anche se il fatto rimane: la valutazione del rischio e il coraggioso processo decisionale sono sempre stati la necessità del momento per competere sul mercato. Inoltre, la libertà di accedere a grandi quantità di dati e di visualizzare rimane parte della soluzione.
Detto questo, questa cultura incentrata sui dati che coinvolge cifre statistiche, medie, linee di distribuzione e mediane forse è difficile da comprendere per un certo numero di persone. Ed è per questo che il file di dump non sovraccarica le persone che desiderano prendere decisioni rapide e solide basate sui dati analitici disponibili.
Man mano che la crescente cultura dei dati sembra espandersi, il processo decisionale calcolatore è diventato più dipendente dalla fiducia riposta nella raccolta dei dati.
Data Pipeline e il ruolo dell'estetica visiva
A parte il processo funzionale, le condutture dovrebbero formare la migliore analisi visiva che una mente umana può percepire attraverso un accurato parallelismo, visualizzazione e progettazione. Una visualizzazione a più livelli completa l'obiettivo finale dell'intero processo. E questo è a favore non solo degli utenti, ma anche dei marketer.
Le stesse regole si applicano alla vitalità della comunicazione. Che senso avrebbe creare una rete neurale complicata ed evidenziare modelli di tendenza se non può invocare modelli di sottotono di base e riconoscimento del valore tra le persone?
Certo, le aziende possono eseguire metriche semplici o utilizzare modelli analitici avanzati; purché le persone possano navigare e comprendere l'interfaccia per un'analisi approfondita. Allo stesso modo, il divario tra ciascuna pipeline codificata dovrebbe essere ridotto in modo che gli utenti possano apportare determinate modifiche in base alle proprie esigenze.

Potresti voler notare che non esiste uno stile estetico visivo definito. Ha bisogno di subire cambiamenti, revisioni, riscoperta e collegamento a nuove tendenze accattivanti. Questa correlazione è quasi palpabile per i programmatori che capiscono come il solo monitoraggio possa fare la differenza.
Vantaggi della pipeline di dati
- Semplice ed efficace
Sebbene le pipeline di dati possano avere un'infrastruttura complessa e un processo funzionante, il suo utilizzo e la sua navigazione sono piuttosto semplici. Allo stesso modo, il processo di apprendimento della creazione di una pipeline di dati è realizzabile attraverso la pratica comune del linguaggio Java Virtual Machine (JVM) per leggere e scrivere i file.
Lo scopo alla base del pattern decoratore , invece, è quello di trasformare un'operazione semplificata in una robusta. I programmatori apprezzano più di chiunque altro la facilità di accesso quando si tratta di piping dei dati.
- Compatibilità con le app
La natura incorporata delle pipeline di dati ne semplifica l'utilizzo sia per i clienti che per gli strateghi del marketing digitale. La sua compatibilità adatta evita la necessità di installare, avere file di configurazione o fare affidamento su un server. Puoi avere un accesso completo ai dati semplicemente incorporando le dimensioni ridotte della pipeline di dati in un'app.
- Flessibilità dei metadati
La separazione di campi e record personalizzati è una delle caratteristiche efficienti della pipeline di dati. I metadati consentono di rintracciare l' origine dei dati, il creatore , i tag , le istruzioni , le nuove modifiche e le opzioni di visibilità .
- Componenti integrati
Sebbene l'opzione personalizzabile sia accessibile a te, le pipeline di dati hanno componenti integrati che ti consentono di inserire o uscire i tuoi dati dalla pipeline. Dopo l'attivazione integrata, puoi iniziare a lavorare con i dati tramite operatori di flusso.

Fonte
- Segmentazione rapida dei dati in tempo reale
Indipendentemente dal fatto che i tuoi dati siano archiviati sotto forma di file excel, su una piattaforma di social media online o su un database remoto, le pipeline di dati possono suddividere i piccoli blocchi di dati che sono fondamentalmente parte del flusso di lavoro di streaming più ampio.
E il funzionamento in tempo reale non ha bisogno di una quantità estranea di tempo per elaborare i tuoi dati. Di conseguenza, questo lascia un margine di manovra per elaborare e dedurre i dati a portata di mano più facilmente.
- Elaborazione in memoria
Con la disponibilità di pipeline di dati, non è necessario archiviare o salvare nuove modifiche ai dati in un file, disco o database casuale. Le pipeline esercitano una funzione in memoria che rende l'accessibilità dei dati più rapida rispetto alla memorizzazione su disco.
L'era dei big data
L'uso del termine " big data" è spesso utilizzato in modo improprio. È più un termine più ampio che si riferisce a ciò che è emerso negli ultimi due anni nel mondo analitico. Ma lo scopo degli strumenti di integrazione dei big data è in gran parte quello di raccogliere eventi e una moltitudine di fonti per creare una dashboard completa. Ora, ricorda, puoi assemblare, duplicare, pulire, trasformare e rigenerare i dati disponibili per avere una funzionalità di navigazione fluida con questi strumenti software di analisi dei dati.

Fonte
Inoltre, la maggior parte degli strumenti disponibili può comunicare con file di grandi dimensioni, database, numerosi dispositivi mobili, IoT, servizi di streaming e API. Successivamente, questo processo di comunicazione crea un record nell'archivio cloud o nel software locale. Strumenti SaaS ETL come analisi spazzaneve , dati punto o cinque tran, ad esempio , vengono forniti con driver e plug-in aggiuntivi per rendere l'integrazione il più agevole possibile.
Detto questo, i decisori si sono resi conto che questi strumenti sono solo mezzi per raggiungere un fine. Servono all'obiettivo di recuperare e archiviare dati non strutturati. Le aziende, d'altra parte, hanno iniziato a capire che le pipeline di dati potrebbero aver aperto nuove porte per assemblare dati analitici, ma la responsabilità di prendere decisioni logiche resta su di loro.
Pensieri finali
La superiorità tecnologica delle pipeline di dati continuerà a crescere per accogliere segmenti di dati più ampi con capacità di trasformazione. Detto questo, la tendenza futuristica delle pipeline di dati è vitale quasi quanto lo era dieci anni fa. Un nuovo processo per una pipeline di dati ben monitorata è sempre all'orizzonte. E questa esigenza di ottenere un design impeccabile, conformità, efficienza delle prestazioni, maggiore scalabilità e design accattivante è sicuramente in movimento verso il miglioramento.
Improvado è la soluzione di pipeline di dati n. 1 per gli esperti di marketing. Uno strumento ETL utilizzato per estrarre, trasformare e caricare dati da oltre 150 diverse piattaforme di marketing in qualsiasi destinazione finale, come uno strumento di BI o un data warehouse. Scopri di più qui.
La nostra raccomandazione:
Dai un'occhiata ai migliori strumenti e software di analisi di marketing per il 2022
14 migliori strumenti ETL per le aziende aziendali da provare nel 2021
Come ottimizzare i dati da Snowflake a Tableau [Due semplici modi]