
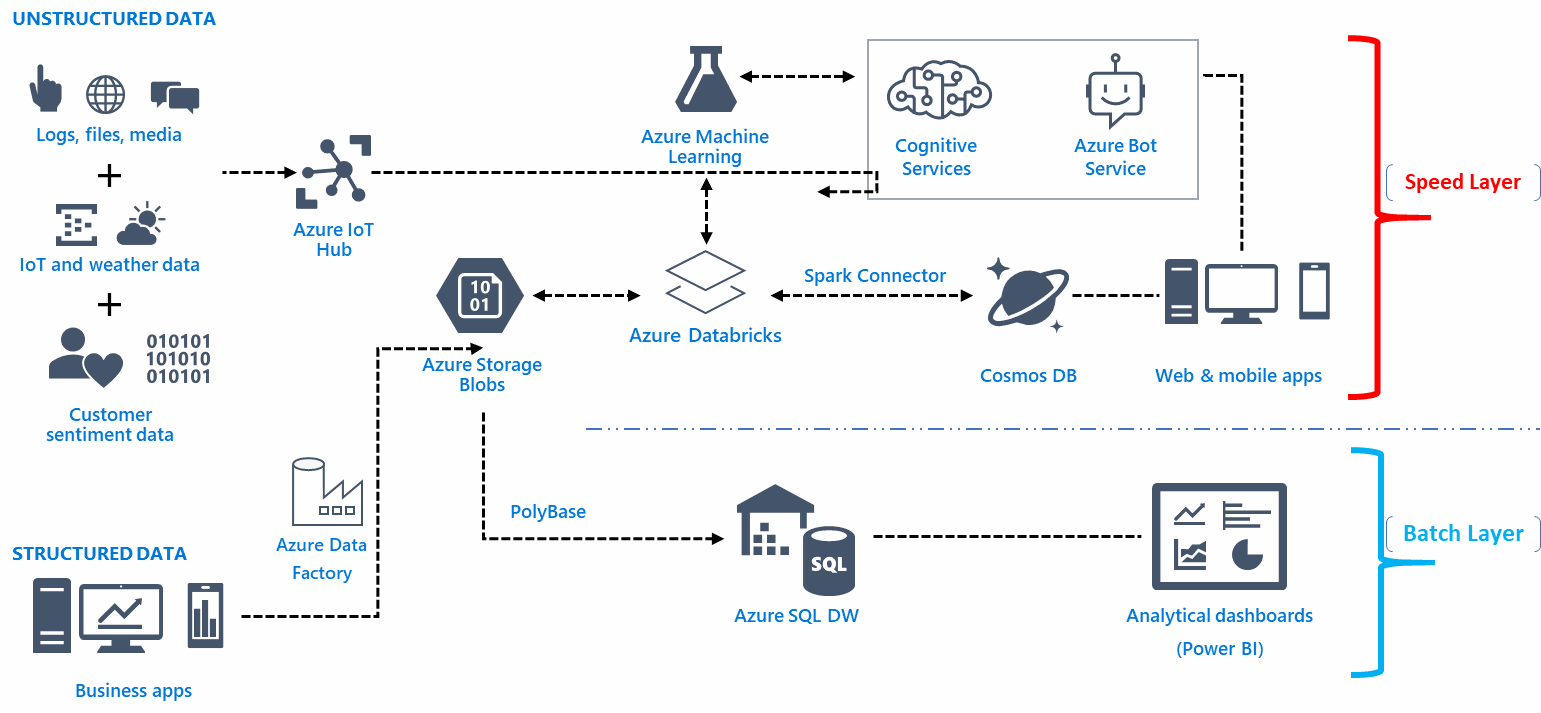
O que é um pipeline de dados?
Publicados: 2019-08-15O que é um pipeline de dados?
Um pipeline de dados funciona como um mecanismo de processamento que envia seus dados por meio de aplicativos, filtros e APIs transformadores instantaneamente.
Você pode pensar em um pipeline de dados como uma rota de transporte público. Você define onde seus dados saltam no barramento e quando saem do barramento.
Um pipeline de dados ingere uma combinação de fontes de dados, aplica a lógica de transformação (geralmente dividida em vários estágios sequenciais) e envia os dados para um destino de carga, como um data warehouse, por exemplo.
Com o advento do marketing digital e o avanço tecnológico contínuo no setor de TI – os pipelines de dados tornaram-se salvadores para coleta , conversão , migração e visualização de dados complexos.
De acordo com a Adobe, apenas 35% dos profissionais de marketing acham que seu pipeline é eficiente. Aqui no Improvado, nos propusemos a mudar isso.
Improvado é a solução de pipeline de dados nº 1 para profissionais de marketing. Uma ferramenta ETL usada para extrair, transformar e carregar dados de mais de 150 plataformas de marketing diferentes em qualquer destino final, como uma ferramenta de BI ou data warehouse. Saiba mais aqui.
A natureza simplificada e concentrada dos pipelines de dados permite esquemas flexíveis de fontes estáticas e em tempo real. Em última análise, essa flexibilidade está vinculada à capacidade dos pipelines de dados de dividir os dados em pequenas porções.
A relação da gama de dados e seu impacto tornou-se mais vital para as empresas em todo o mundo. Simultaneamente, a compreensão desse vínculo interconectado ajuda os cientistas de dados a resolver latência, gargalos, fontes não identificadas e problemas de duplicação.
É verdade; pipelines de dados agora complementam a rede do sistema. Quanto mais abrangente o pipeline de dados, melhor a aplicabilidade do sistema de rede seria combinar serviços em nuvem e aplicativos híbridos para o trabalho.
A ascensão dos pipelines de dados
Além disso, os pipelines de dados abriram novas portas para integrar várias ferramentas e ingerir uma quantidade enorme de arquivos XML e CSV grandes. O processamento de dados em tempo real, no entanto, foi provavelmente o ponto de inflexão para os pipelines de dados.
Esse ponto de inflexão facilitou a necessidade da hora de mover grandes blocos de dados de um lugar para outro sem alterar o formato. Como resultado, as empresas encontraram uma nova liberdade para ajustar , mudar , segmentar , exibir ou transferir dados em um curto espaço de tempo.
Ao longo dos anos, a objetividade de como as empresas operam mudou significativamente. O foco não está mais em ganhar margens de lucro, mas em como os cientistas de dados podem apresentar soluções viáveis que se conectam com as pessoas. Além disso, mais importante, essas mudanças precisam ser transformadoras , rastreáveis e adaptáveis para mudar as dinâmicas futuras. Dito isso, os pipelines de dados percorreram um longo caminho desde o uso de arquivos simples, banco de dados e data lake até o gerenciamento de serviços em uma plataforma sem servidor.
Infraestrutura de pipeline de dados
A infraestrutura arquitetônica de um pipeline de dados depende da base para capturar, organizar, rotear ou redirecionar dados para obter informações perspicazes. Aqui está a coisa, geralmente há um número bastante significativo de pontos de entrada irrelevantes para dados brutos. Além disso, é aqui que a infraestrutura de pipeline combina, personaliza, automatiza, visualiza, transforma e move dados de vários recursos para atingir as metas definidas.
Além disso, a infraestrutura arquitetônica de um pipeline de dados complementa a funcionalidade baseada em análises e inteligência de negócios precisa. A funcionalidade de dados significa obter informações valiosas sobre o comportamento do cliente, o processo robótico, o processo de automação e o padrão de experiência do cliente e o padrão da jornada do usuário. Você aprende sobre as tendências e informações em tempo real por meio de inteligência de negócios e análises por meio de grandes blocos de dados.
Escolhendo a equipe certa de engenharia de dados
Seria sensato formar equipes de engenharia de big data que estivessem sempre ocupadas com os detalhes do aplicativo. Contrate os engenheiros de dados que devem ser capazes de obter dados estruturais e resolver problemas, entender tabelas complexas e implementar dados funcionais em tempo hábil.

A funcionalidade do pipeline de dados
A funcionalidade de um pipeline de dados tem a função de coletar informações, mas tecnicamente, o método de armazenamento, acesso e disseminação de dados pode variar dependendo da configuração.
Minimizar a movimentação de dados, por exemplo, é possível por meio de uma camada abstrata para dispersar dados sem mover manualmente todas as informações na interface do usuário. Você pode criar uma camada abstrata para vários sistemas de arquivos com a ajuda do Alluxio entre o mecanismo de armazenamento e o fornecedor selecionado como AWS.
A funcionalidade de um pipeline de dados não deve depender do sistema de banco de dados do fornecedor. Além disso, qual seria o objetivo de criar uma infraestrutura livre de erros e camadas sem flexibilidade? Tendo isso em mente, seu pipeline de dados deve ser capaz de reunir informações completas em um dispositivo de armazenamento como a AWS para proteger o futuro do sistema de dados.
A funcionalidade do pipeline de dados deve atender à análise de negócios em vez de construir a rede inteiramente com base em escolhas estéticas. As funções de uma infraestrutura de streaming, por exemplo, são bastante difíceis de gerenciar e geralmente exigem experiência profissional e negócios fortes para gerenciar tarefas complexas de engenharia.
Você pode usar um serviço de contêiner convencional, como Dockers, para criar pipelines de dados. Você pode ajustar a resposta funcional da segurança, verificar o potencial de escalabilidade e melhorar o código do software com a ajuda de contêineres. Um erro comum que as pessoas geralmente cometem durante a criação da resposta funcional é executar e distribuir as operações de forma desigual. O truque é evitar usar o arquivo de transformação principal no SQL e adaptar o método CTAS para definir vários parâmetros e operações de arquivo.
Embora bancos de dados como Snowflake e Presto forneçam acesso SQL integrado, uma grande quantidade de dados inevitavelmente diminui o tempo da interface do usuário. Portanto, aplique algoritmos focados na velocidade que resultam em um pequeno erro de saída.
Ferramentas para construir um pipeline de dados
O sistema de arquivos colunar de seu pipeline de dados deve ser capaz de armazenar e compactar dados acumulados finais. Os mecanismos de dados aumentam o uso desses sistemas de arquivos na interface do usuário. Além disso, para obter uma visualização atraente - use iPython ou Jupyter como notebooks. Você pode até criar modelos de notebook baseados em parâmetros específicos para obter funções integradas para auditar dados, destacar gráficos, focalizar gráficos relevantes ou revisar dados completamente.
Você pode transferir esse subconjunto específico de dados para um local remoto com a ajuda de ferramentas como Google Cloud Platform (GCP), Python ou Kafka . Você não precisa criar uma versão finalizada do código de primeira – inicie com o recurso da biblioteca Faker em Python para escrever e testar o código no pipeline de dados.

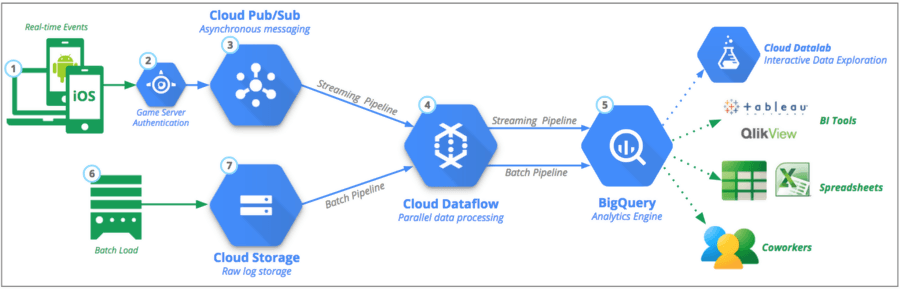
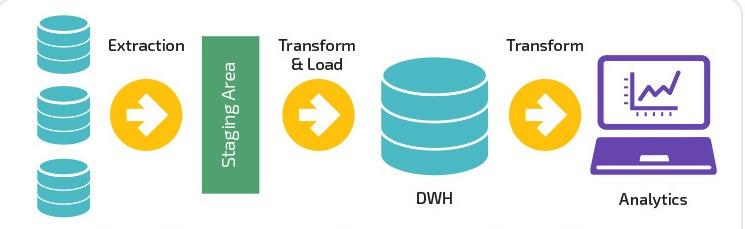
Qual é a diferença entre pipeline de dados e ETL?
ETL é um acrônimo comum usado para Extract , Transform e Load. A principal diferença do ETL é que ele se concentra inteiramente em um sistema para extrair, transformar e carregar dados em um data warehouse específico. Como alternativa, o ETL é apenas um dos componentes que se enquadram no pipeline de dados.
Os pipelines ETL movem os dados em lotes para um sistema especificado com intervalos regulamentados. Comparativamente, os pipelines de dados têm uma aplicabilidade mais ampla para transformar e processar dados por meio de streaming ou em tempo real.
Os pipelines de dados não precisam necessariamente carregar dados em um data warehouse, mas podem optar por carregar em um destino seletivo, como o bucket S3 (Simple Storage Service) da Amazon ou até mesmo conectá-lo a um sistema completamente diferente.
Soluções de pipeline de dados disponíveis
A natureza e a resposta funcional do pipeline de dados seriam diferentes das ferramentas de nuvem para migrar dados para usá-los em uma solução em tempo real.
- Baseado em nuvem
A relação custo-benefício do uso de ferramentas baseadas em nuvem para amalgamar dados é bastante alta. As empresas aprenderam a manter a infraestrutura atualizada com uso mínimo de meios e recursos. No entanto, o processo de escolha de fornecedores para gerenciar pipelines de dados é outra questão.
- Código aberto
O termo carrega uma forte conotação para cientistas de dados que desejam pipelines de dados transparentes que não burlem o uso de dados em nome dos clientes. As ferramentas de código aberto são ideais para proprietários de pequenas empresas que desejam custos mais baixos e dependência excessiva de fornecedores. No entanto, a utilidade de tais ferramentas requer conhecimento e compreensão funcional para adaptar e modificar a experiência do usuário.
- Processamento em tempo real
A implementação do processamento em tempo real é benéfica para empresas que desejam processar dados de uma fonte de streaming regulamentada. Além disso, o mercado financeiro e os dispositivos móveis são compatíveis para ter processamento em tempo real. Dito isso, o processamento em tempo real requer interação humana mínima, opções de dimensionamento automático e possíveis partições.
- O uso do lote
O processamento em lote permite que as empresas transportem facilmente uma grande quantidade de dados em intervalos sem a necessidade de visibilidade em tempo real. O processo torna mais fácil para os analistas que combinam uma infinidade de dados de marketing para formar um resultado ou padrão decisivo.
O processo automatizado
Bem, ele descarta a necessidade de repetir para definir , extrair , carregar e transformar dados. Lembre-se, é apenas no início do programa que você deve inserir o trabalho manual e o sistema o automatizará para todo o processo. O processo de automação, no entanto, requer um tradutor que possa alinhar e adequar as necessidades do negócio.

Além disso, o fator de reprodutibilidade torna conveniente para os usuários acessar os dados com segurança plausível. No entanto, você precisa entender que todo o processo é suscetível à depuração. Isso inevitavelmente leva a mudanças nas análises e fusões de dados .
A conclusão de projetos de alto valor depende inteiramente do nível de especialização e do treinamento do cientista de dados contratado. Para algumas empresas, no entanto, a adição de hardware e pessoas pode não ser uma opção viável. No entanto, por uma questão de manutenção e melhoria do pipeline de dados – você eventualmente precisa contratar os serviços de uma equipe profissional.
- Integrações Contemporâneas
As opções infraestruturais e funcionais são infinitas quando se trata de construir pipelines de dados, alinhados e integrados com Google AdWords, Analytics, Facebook Ads, LinkedIn e integração com o YouTube. Isso significa que você pode acessar sua interface do usuário para desenvolver pipelines de dados sem precisar depender de código.

Fonte
O marketing digital pode ter revolucionado nos últimos anos, mas também o papel dos cientistas de dados, que agora tornaram possível combinar grandes partes de seus conjuntos de dados de dados do AdWords e conteúdo de streaming em uma plataforma de nuvem escolhida em questão de minutos .
Você pode ingerir e processar conjuntos de dados para definir análises em tempo real em todo o mundo e personalizar o fluxo em diferentes projetos também. Da mesma forma, você pode vincular novamente as operações de dados e verificar o faturamento por segundo. No entanto, também oferece um ambiente de estação de fluxo de trabalho contínuo em nuvens locais e públicas. Por fim, isso facilita bastante a exploração visual, a conectividade com a IoT e a limpeza dos dados estruturados.
Adequação e escalabilidade de pipelines de dados
A escalabilidade de um pipeline de dados deve ser capaz de pontuar bilhões de pontos de dados e consideravelmente mais escalas de produtos. Além disso, o truque é armazenar os dados no sistema de uma forma que facilite a disponibilidade de consultas.
Além disso, um pipeline de dados bem projetado concentra-se nas opções de adequação e escalabilidade juntas. Quanto maior o índice de escalabilidade, mais ele seria compatível. Da mesma forma, use reexecuções como uma técnica de contingência eficaz para uma possível reformulação dos dados. Você pode verificar o ponto de verificação alterando o código-fonte para retomar o processo. Ele praticamente permite que você passe por pipelines de ETL que usam metadados para cada ponto de entrada para verificar o status, os dados coletados e a transformação geral.
O design de cluster do pipeline de dados deve ser dimensionado em cada carga, em vez de um mecanismo fixo 24 horas por dia, 7 dias por semana. O AWS EMR (Elastic MapReduce), por exemplo, é um exemplo perfeito de escalonamento automático em que os clusters recebem um gatilho para passar por uma sequência ETL específica e descartar após a conclusão. É importante observar que você sempre pode aumentar ou diminuir a escala dependendo da natureza dos dados.
Além disso, sua interface de usuário (UI) deve ser clara o suficiente para monitorar reexecuções completas de dados e status do lote. Além disso, você pode colocar a consulta (UI) no modelo de dados primário para analisar e revisar a condição do pipeline de dados. O apache Airflow, por exemplo, é uma opção viável para monitorar o status, mas inclui o uso de desenvolvimento e escrita de código. Além disso, é aqui que o uso de metadados de arquitetura se torna essencial para monitorar, verificar validações e reduzir os complicados problemas de dados de produtividade.
Como os pipelines de dados podem influenciar a tomada de decisões
Hoje, os tomadores de decisão são legitimamente dependentes da cultura orientada a dados. Além disso, a combinação de vários dados analíticos em um painel simplificado é certamente um dos principais motivos de seu sucesso.
Os dados estruturados confinados ajudam os empresários e empreendedores a tomar decisões ideais com base em evidências coletadas. No entanto, esse padrão é válido para gerentes que costumavam tomar decisões informadas sobre projetos de modelagem simples e dados estatísticos descritivos.

Fonte
A utilização e diversificação de métricas para diferentes negócios também dependem da comunicação entre colaboradores e gestores. As mesmas regras se aplicam quando se trata da capacidade dos funcionários e gerentes de descartar duplicações e estocar os objetivos corretos.
Embora o fato permaneça – a avaliação de risco e a tomada de decisão ousada sempre foram a necessidade da hora para competir no mercado. Além disso, a liberdade de acessar grandes blocos de dados e visualizar continua sendo parte da solução.
Dito isso, essa cultura centrada em dados envolvendo números estatísticos, médias, linhas de distribuição e medianas pode ser difícil de compreender para várias pessoas. E é por isso que o arquivo de despejo não sobrecarrega os indivíduos que desejam tomar decisões rápidas e robustas com base nos dados analíticos disponíveis.
À medida que a crescente cultura de dados parece se expandir – a tomada de decisão calculista tornou-se mais dependente da confiança depositada na coleta de dados.
Pipelines de dados e o papel da estética visual
Além do processo funcional, os pipelines devem formar a melhor análise visual que uma mente humana pode perceber por paralelismo, visualização e design precisos. Uma visualização em camadas complementa como o objetivo final de todo o processo. E isso é a favor não apenas dos usuários, mas também dos profissionais de marketing.
As mesmas regras se aplicam à vitalidade da comunicação. Qual seria o sentido de criar uma rede neural complicada e destacar modelos de tendências se ela não puder invocar padrões básicos de subtom e reconhecimento de valor entre as pessoas?
Claro, as empresas podem executar métricas diretas ou seguir os modelos analíticos avançados; contanto que as pessoas possam navegar e entender a interface para uma análise completa. Da mesma forma, a lacuna entre cada pipeline codificado deve ser estreita para que os usuários possam fazer certas modificações de acordo com seus próprios requisitos.

Você pode querer notar que não há um estilo estético visual definido. Precisa passar por mudanças, revisões, redescobertas e vinculação a novas tendências cativantes. Essa correlação é quase palpável para codificadores que entendem como apenas o monitoramento pode fazer toda a diferença.
Benefícios do pipeline de dados
- Simples e Eficaz
Embora os pipelines de dados possam ter a infraestrutura e o processo de funcionamento complexos, seu uso e navegação são bastante diretos. Da mesma forma, o processo de aprendizado de construção de um pipeline de dados é alcançável por meio da prática comum da linguagem Java Virtual Machine (JVM) para ler e gravar os arquivos.
O propósito subjacente do padrão decorador , por outro lado, é transformar uma operação simplificada em uma operação robusta. Os programadores apreciam mais do que ninguém a facilidade de acesso quando se trata de dados de tubulação.
- Compatibilidade com aplicativos
A natureza incorporada dos pipelines de dados facilita o uso para clientes e estrategistas de marketing digital. Sua compatibilidade de encaixe evita a necessidade de instalar, ter arquivos de configuração ou depender de um servidor. Você pode ter acesso completo aos dados apenas incorporando o pequeno tamanho do pipeline de dados em um aplicativo.
- Flexibilidade de metadados
A separação de campos e registros personalizados é uma das características eficientes do pipeline de dados. Os metadados permitem rastrear a origem dos dados, criador , tags , instruções , novas alterações e opções de visibilidade .
- Componentes embutidos
Embora a opção personalizável seja acessível para você, os pipelines de dados têm componentes internos que permitem que você insira ou retire seus dados do pipeline. Após a ativação integrada, você pode começar a trabalhar com os dados por meio de operadores de fluxo.

Fonte
- Segmentação rápida de dados em tempo real
Quer seus dados sejam armazenados na forma de arquivo do Excel, em uma plataforma de mídia social online ou em um banco de dados remoto – os pipelines de dados podem dividir os pequenos pedaços de dados que são fundamentalmente parte do fluxo de trabalho de streaming maior.
E o funcionamento em tempo real não precisa de muito tempo para processar seus dados. Consequentemente, isso deixa uma margem de manobra para você processar e inferir dados disponíveis com mais facilidade.
- Processamento na memória
Com a disponibilidade de pipelines de dados, você não precisa armazenar ou salvar novas alterações nos dados em um arquivo, disco ou banco de dados aleatório. Os pipelines exercem uma função na memória que torna a acessibilidade dos dados mais rápida do que armazená-los em um disco.
A Era do Big Data
O uso do termo ' big data' é frequentemente mal utilizado. É mais um termo mais amplo que se relaciona com o que aconteceu nos últimos dois anos no mundo analítico. Mas o objetivo das ferramentas de integração de big data é em grande parte reunir eventos e uma infinidade de fontes para criar um painel abrangente. Agora, lembre-se, você pode montar, duplicar, limpar, transformar e regenerar os dados disponíveis para ter uma funcionalidade de navegação suave com essas ferramentas de software de análise de dados.

Fonte
Além disso, a maioria das ferramentas disponíveis pode se comunicar com arquivos grandes, bancos de dados, vários dispositivos móveis, IoTs, serviços de streaming e APIs. Posteriormente, esse processo de comunicação cria um registro no armazenamento em nuvem ou no software local. Ferramentas SaaS ETL, como análise de snowplow , dados de costura ou cinco tran, por exemplo , vêm com drivers e plug-ins adicionados para tornar a integração o mais suave possível.
Dito isso, os tomadores de decisão perceberam que essas ferramentas são apenas meios para um fim. Eles servem ao objetivo de recuperar e armazenar dados não estruturados. As empresas, por outro lado, começaram a entender que os pipelines de dados podem ter aberto novas portas para reunir dados analíticos, mas a responsabilidade de tomar decisões lógicas ainda recai sobre elas.
Pensamentos finais
A superioridade tecnológica dos pipelines de dados continuará aumentando para acomodar segmentos de dados maiores com capacidade transformacional. Dito isso, a tendência futurista dos pipelines de dados é quase tão vital quanto era há uma década. Um novo processo para um pipeline de dados bem monitorado está sempre no horizonte. E essa necessidade de alcançar um design impecável, conformidade, eficiência de desempenho, maior escalabilidade e design atraente certamente está se movendo em direção à melhoria.
Improvado é a solução de pipeline de dados nº 1 para profissionais de marketing. Uma ferramenta ETL usada para extrair, transformar e carregar dados de mais de 150 plataformas de marketing diferentes em qualquer destino final, como uma ferramenta de BI ou data warehouse. Saiba mais aqui.
Nossa recomendação:
Confira as melhores ferramentas e softwares de análise de marketing para 2022
14 melhores ferramentas de ETL para empresas corporativas experimentarem em 2021
Como simplificar os dados do Snowflake para o Tableau [duas maneiras fáceis]