
Qu'est-ce qu'un pipeline de données ?
Publié: 2019-08-15Qu'est-ce qu'un pipeline de données ?
Un pipeline de données sert de moteur de traitement qui envoie instantanément vos données via des applications transformatrices, des filtres et des API.
Vous pouvez considérer un pipeline de données comme un itinéraire de transport public. Vous définissez où vos données sautent sur le bus et quand elles quittent le bus.
Un pipeline de données ingère une combinaison de sources de données, applique une logique de transformation (souvent divisée en plusieurs étapes séquentielles) et envoie les données vers une destination de chargement, comme un entrepôt de données par exemple.
Avec l'avènement du marketing numérique et les progrès technologiques continus dans le secteur informatique, les pipelines de données sont devenus des sauveurs pour la collecte , la conversion , la migration et la visualisation de données complexes.
Selon Adobe, seulement 35 % des spécialistes du marketing pensent que leur pipeline est efficace. Chez Improvado, nous avons décidé de changer cela.
Improvado est la solution de pipeline de données n°1 pour les spécialistes du marketing. Un outil ETL utilisé pour extraire, transformer et charger des données de plus de 150 plates-formes marketing différentes vers n'importe quelle destination finale, comme un outil de BI ou un entrepôt de données. En savoir plus ici.
La rationalisation et la nature concentrée des pipelines de données permettent des schémas flexibles à partir de sources statiques et en temps réel. En fin de compte, cette flexibilité est liée à la capacité des pipelines de données à diviser les données en petites portions.
La relation entre la gamme de données et son impact est devenue plus vitale pour les entreprises du monde entier. Simultanément, la compréhension de ce lien interconnecté aide les scientifiques des données à résoudre les problèmes de latence, de goulots d'étranglement, de sources non identifiées et de duplication.
C'est vrai; des pipelines de données complètent désormais le réseau du système. Le pipeline de données plus complet, la meilleure applicabilité du système de réseau serait de combiner les services cloud et les applications hybrides pour le travail.
L'essor des pipelines de données
De plus, les pipelines de données ont ouvert de nouvelles portes pour intégrer de nombreux outils et ingérer une quantité écrasante de gros fichiers XML et CSV . Cependant, le traitement des données en temps réel a probablement été le point de basculement des pipelines de données.
Ce point de basculement a facilité le besoin de l'heure de déplacer de gros morceaux de données d'un endroit à un autre sans changer le format. En conséquence, les entreprises ont retrouvé la liberté de modifier , de déplacer , de segmenter , de présenter ou de transférer des données en un court laps de temps.
Au fil des ans, l'objectivité du fonctionnement des entreprises a considérablement changé. L'accent n'est plus mis sur l'obtention de marges bénéficiaires, mais sur la façon dont les scientifiques des données peuvent présenter des solutions viables qui se connectent avec les gens. De plus, plus important encore, ces changements doivent être transformateurs , traçables et adaptables aux dynamiques futures changeantes. Cela dit, les pipelines de données ont parcouru un long chemin depuis l'utilisation de fichiers plats, de bases de données et de lacs de données jusqu'à la gestion de services sur une plate-forme sans serveur.
Infrastructure de pipeline de données
L'infrastructure architecturale d'un pipeline de données repose sur une fondation pour capturer, organiser, acheminer ou rediriger les données afin d'obtenir des informations pertinentes. Voici le problème, il existe généralement un nombre assez important de points d'entrée non pertinents pour les données brutes. De plus, c'est là que l'infrastructure du pipeline combine, personnalise, automatise, visualise, transforme et déplace les données de nombreuses ressources pour atteindre les objectifs fixés.
De plus, l'infrastructure architecturale d'un pipeline de données complète les fonctionnalités basées sur l'analyse et l'intelligence d'affaires précise. La fonctionnalité des données signifie obtenir des informations précieuses sur le comportement des clients, le processus robotique, le processus d'automatisation, le modèle d'expérience client et le modèle de parcours des utilisateurs. Vous découvrez les tendances et les informations en temps réel grâce à la veille stratégique et à l'analyse via de gros volumes de données.
Choisir la bonne équipe d'ingénierie des données
Il serait judicieux de former des équipes d'ingénierie Big Data qui sont toujours occupées par les détails de l'application. Embauchez les ingénieurs de données qui devraient être en mesure de mettre la main sur les données structurelles et de résoudre les problèmes, de comprendre les tables complexes et de mettre en œuvre les données fonctionnelles en temps opportun.

La fonctionnalité du pipeline de données
La fonctionnalité d'un pipeline de données sert à collecter des informations, mais techniquement, la méthode de stockage, d'accès et de diffusion des données peut varier en fonction de la configuration.
Minimiser le mouvement des données, par exemple, est possible grâce à une couche abstraite pour disperser les données sans déplacer manuellement chaque élément d'information sur l'interface utilisateur. Vous pouvez créer une couche abstraite pour plusieurs systèmes de fichiers à l'aide d'Alluxio entre le mécanisme de stockage et le fournisseur sélectionné comme AWS.
La fonctionnalité d'un pipeline de données ne doit pas dépendre de la merci du système de base de données du fournisseur. De plus, quel serait l'intérêt de créer une infrastructure sans erreur et sans couches sans flexibilité ? En gardant cela à l'esprit, votre pipeline de données doit être en mesure de collecter des informations complètes dans un périphérique de stockage comme AWS pour protéger l'avenir du système de données.
La fonctionnalité de pipeline de données devrait répondre aux besoins d'analyse commerciale au lieu de construire le réseau entièrement sur des choix esthétiques. Les fonctions d'une infrastructure de streaming, par exemple, sont assez difficiles à gérer et nécessitent généralement une expérience professionnelle et une solide activité pour gérer des tâches d'ingénierie complexes.
Vous pouvez utiliser un service de conteneur standard, tel que Dockers, pour créer canalisations de données. Vous pouvez modifier la réponse fonctionnelle de la sécurité, vérifier le potentiel d'évolutivité et améliorer le code logiciel à l'aide de conteneurs. Une erreur courante que les gens commettent généralement lors de la création d'une réponse fonctionnelle consiste à exécuter et à répartir les opérations de manière inégale. L'astuce consiste à éviter d'utiliser le fichier de transformation principal dans SQL et à adapter la méthode CTAS pour définir plusieurs paramètres et opérations de fichier.
Bien que des bases de données telles que Snowflake et Presto vous offrent un accès SQL intégré, une grande quantité de données réduit inévitablement le temps d'interface utilisateur. Par conséquent, appliquez des algorithmes axés sur la vitesse qui entraînent une erreur de sortie mineure.
Outils pour créer un pipeline de données
Le système de fichiers en colonnes de votre pipeline de données doit pouvoir stocker et compresser les données cumulées finales. Les moteurs de données augmentent l'utilisation de ces systèmes de fichiers dans l'interface utilisateur. De plus, pour obtenir une visualisation convaincante, utilisez iPython ou Jupyter comme blocs-notes. Vous pouvez même créer des modèles de bloc-notes spécifiques basés sur des paramètres pour obtenir des fonctions intégrées permettant d'auditer les données, de mettre en évidence des graphiques, de cibler des tracés pertinents ou d'examiner les données dans leur ensemble.
Vous pouvez transférer ce sous-ensemble spécifique de données vers un emplacement distant à l'aide d'outils tels que Google Cloud Platform (GCP), Python ou Kafka . Vous n'avez pas besoin de créer une version finalisée du code du premier coup - lancez-vous avec la fonctionnalité de bibliothèque Faker en Python pour écrire et tester le code dans le pipeline de données.

Quelle est la différence entre le pipeline de données et l'ETL ?
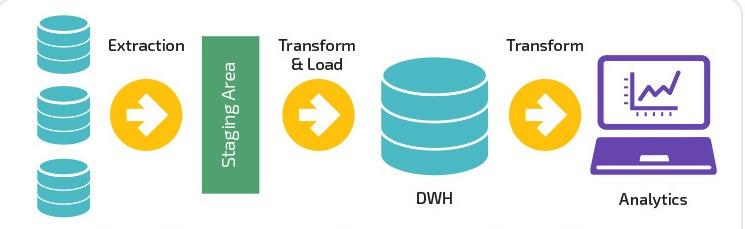
ETL est un acronyme courant utilisé pour Extract , Transform et Load. La principale différence d' ETL est qu'il se concentre entièrement sur un système pour extraire, transformer et charger des données dans un entrepôt de données particulier. Alternativement, ETL n'est qu'un des composants qui relèvent du pipeline de données.
Les pipelines ETL déplacent les données par lots vers un système spécifié avec des intervalles réglementés. Comparativement, les pipelines de données ont une applicabilité plus large pour transformer et traiter les données via le streaming ou en temps réel.
Les pipelines de données ne doivent pas nécessairement charger les données dans un entrepôt de données, mais peuvent choisir de les charger sur une cible sélective telle que le compartiment S3 (Simple Storage Service) d' Amazon ou même de les connecter à un système complètement différent.
Solutions de pipeline de données disponibles
La nature et la réponse fonctionnelle du pipeline de données seraient différentes des outils cloud pour migrer les données pour les utiliser directement pour une solution en temps réel.
- Basé sur le cloud
Le rapport coût-bénéfice de l'utilisation d'outils basés sur le cloud pour fusionner les données est assez élevé. Les entreprises ont appris à maintenir une infrastructure à jour avec une utilisation minimale des moyens et des ressources. Cependant, le processus de sélection des fournisseurs pour gérer les pipelines de données est une tout autre affaire.
- Open source
Le terme a une forte connotation pour les scientifiques des données qui veulent des pipelines de données transparents qui n'arnaquent pas l'utilisation des données au nom des clients. Les outils Open Source sont idéaux pour les propriétaires de petites entreprises qui souhaitent des coûts réduits et une dépendance excessive vis-à-vis des fournisseurs. Cependant, l'utilité de tels outils nécessite une expertise et une compréhension fonctionnelle pour adapter et modifier l'expérience utilisateur.
- Traitement en temps réel
La mise en œuvre du traitement en temps réel est bénéfique pour les entreprises qui souhaitent traiter des données à partir d'une source de streaming réglementée. De plus, le marché financier et les appareils mobiles sont compatibles pour avoir un traitement en temps réel. Cela dit, le traitement en temps réel nécessite une interaction humaine minimale, des options de mise à l'échelle automatique et des partitions possibles.
- L'utilisation du lot
Le traitement par lots permet aux entreprises de transporter facilement une grande quantité de données à intervalles sans avoir besoin d'une visibilité en temps réel. Le processus facilite la tâche des analystes qui combinent une multitude de données marketing pour former un résultat ou un modèle décisif.
Le processus automatisé
Eh bien, cela élimine le besoin de répéter pour définir , extraire , charger et transformer des données. N'oubliez pas que ce n'est qu'au début du programme que vous devez saisir le travail manuel et que le système l'automatisera pour l'ensemble du processus. Cependant, le processus d'automatisation nécessite un traducteur capable d'aligner et d'adapter les besoins de l'entreprise.

De plus, le facteur de reproductibilité permet aux utilisateurs d'accéder facilement aux données avec une sécurité plausible. Cependant, vous devez comprendre que l'ensemble du processus est susceptible d'être débogué. Cela conduit inévitablement à des analyses changeantes et à des fusions de données .
La réalisation de projets de grande valeur dépend entièrement du niveau d'expertise et de la formation du data scientist embauché. Pour certaines entreprises, cependant, l'ajout de matériel et de personnes peut ne pas être une option réalisable. Néanmoins, dans un souci de maintenance et d'amélioration du pipeline de données, vous devrez éventuellement faire appel aux services d'une équipe professionnelle.
- Intégrations contemporaines
Les options infrastructurelles et fonctionnelles sont infinies lorsqu'il s'agit de créer des pipelines de données, alignés et intégrés à l'intégration de Google AdWords, Analytics, Facebook Ads, LinkedIn et YouTube. Cela signifie que vous pouvez accéder à votre interface utilisateur pour développer des pipelines de données sans avoir à vous fier au code.

La source
Le marketing numérique a peut-être révolutionné ces dernières années, mais le rôle des data scientists l'a également été, qui ont désormais permis de combiner en quelques minutes de grandes parties de vos ensembles de données à partir de données AdWords et de contenu en streaming sur une plate-forme cloud choisie. .
Vous pouvez ingérer et traiter des ensembles de données pour définir des analyses en temps réel dans le monde entier et personnaliser également le flux sur différents projets. De même, vous pouvez relier les opérations de données et vérifier la facturation à la seconde. Cependant, il offre également un environnement de station de flux de travail transparent sur les clouds sur site et publics. En fin de compte, cela facilite l'exploration visuelle, la connectivité à l' IoT et le nettoyage des données structurées.
Adéquation et évolutivité des pipelines de données
L'évolutivité d'un pipeline de données devrait pouvoir marquer des milliards de points de données et considérablement plus d'échelles de produits. De plus, l'astuce consiste à stocker les données sur le système de manière à faciliter la disponibilité des requêtes.
De plus, un pipeline de données bien conçu se concentre sur les options d'adéquation et d'évolutivité. Plus le taux d'évolutivité est élevé, plus il serait compatible. De même, utilisez les rediffusions comme technique d'urgence efficace pour une éventuelle reformulation des données. Vous pouvez vérifier le point de contrôle en modifiant le code source pour reprendre le processus. Il vous permet pratiquement de passer par des pipelines ETL qui utilisent des métadonnées pour chaque point d'entrée pour vérifier l'état, les données collectées et la transformation globale.
La conception en cluster du pipeline de données doit être adaptée à chaque charge au lieu d'un mécanisme fixe 24h/24 et 7j/7. AWS EMR (Elastic MapReduce), par exemple, est un exemple parfait de mise à l'échelle automatique où les clusters reçoivent un déclencheur pour passer par une séquence ETL spécifique et la supprimer une fois terminée. Il est important de noter que vous pouvez toujours augmenter ou réduire la taille en fonction de la nature des données.
De plus, votre interface utilisateur (UI) doit être suffisamment claire pour surveiller les réexécutions complètes des données et l'état des lots. De plus, vous pouvez placer une requête (UI) sur le modèle de données principal pour analyser et examiner l'état du pipeline de données. L'Apache Airflow, par exemple, est une option viable pour surveiller l'état, mais il inclut l'utilisation de développement et l'écriture de code. De plus, c'est là que l'utilisation de métadonnées architecturales devient essentielle pour surveiller, vérifier les validations et résoudre les problèmes complexes de données de productivité.
Comment les pipelines de données peuvent influencer la prise de décision
Aujourd'hui, les décideurs sont légitimement dépendants de la culture data-oriented. De plus, la combinaison de multiples données analytiques dans un tableau de bord simplifié est certainement l'une des principales raisons de son succès.
Les données structurées confinées aident les propriétaires d'entreprise et les entrepreneurs à prendre des décisions optimales sur la base des preuves recueillies. Cependant, ce modèle est vrai pour les gestionnaires qui avaient l'habitude de prendre des décisions éclairées sur des conceptions de modélisation simples et des données statistiques descriptives.

La source
L'utilisation et la diversification des métriques pour les différentes entreprises dépendent également de la communication entre les employés et les managers. Les mêmes règles s'appliquent en ce qui concerne la capacité des employés et des gestionnaires à éliminer les doublons et à stocker les bons objectifs.
Bien que le fait demeure - l'évaluation des risques et la prise de décision audacieuse ont toujours été le besoin de l'heure pour être compétitif sur le marché. De plus, la liberté d'accéder à de gros volumes de données et de les visualiser fait toujours partie de la solution.
Cela dit, cette culture centrée sur les données impliquant des chiffres statistiques, des moyennes, des lignes de distribution et des médianes peut être difficile à comprendre pour un certain nombre de personnes. Et c'est la raison pour laquelle le fichier de vidage ne surcharge pas les personnes qui souhaitent prendre des décisions rapides et solides sur la base des données analytiques disponibles.
Alors que la culture croissante des données semble se développer, la prise de décision calculée est devenue plus dépendante de la confiance accordée à la collecte de données.
Pipelines de données et rôle de l'esthétique visuelle
Outre le processus fonctionnel, les pipelines doivent constituer la meilleure analyse visuelle qu'un esprit humain puisse percevoir grâce à une mise en parallèle, une visualisation et une conception précises. Une visualisation en couches complète l'objectif final de l'ensemble du processus. Et cela profite non seulement aux utilisateurs, mais également aux spécialistes du marketing.
Les mêmes règles s'appliquent à la vitalité de la communication. Quel serait l'intérêt de créer un réseau de neurones compliqué et de mettre en évidence des modèles de tendance s'il ne peut pas invoquer des modèles de base de base et la reconnaissance de la valeur parmi les gens ?
Bien sûr, les entreprises peuvent exécuter des mesures simples ou opter pour des modèles analytiques avancés ; tant que les gens peuvent naviguer et comprendre l'interface pour une analyse approfondie. De même, l'écart entre chaque pipeline codé doit être étroit afin que les utilisateurs puissent apporter certaines modifications selon leurs propres besoins.

Vous voudrez peut-être remarquer qu'il n'y a pas de style esthétique visuel défini. Il doit subir des changements, des révisions, des redécouvertes et des liens vers de nouvelles tendances captivantes. Cette corrélation est presque palpable pour les codeurs qui comprennent comment la simple surveillance peut faire toute la différence.
Avantages du pipeline de données
- Simple et Efficace
Bien que les pipelines de données puissent avoir une infrastructure et un processus de fonctionnement complexes, leur utilisation et leur navigation sont assez simples. De même, le processus d'apprentissage de la construction d'un pipeline de données est réalisable grâce à la pratique courante du langage Java Virtual Machine (JVM) pour lire et écrire les fichiers.
Le but sous-jacent du motif décorateur , d'autre part, est de transformer une opération simplifiée en une opération robuste. Les programmeurs apprécient plus que quiconque la facilité d'accès aux données de tuyauterie.
- Compatibilité avec les applications
La nature intégrée des pipelines de données facilite leur utilisation pour les clients et les stratèges du marketing numérique. Sa compatibilité d'ajustement évite le besoin d'installer, d'avoir des fichiers de configuration ou de s'appuyer sur un serveur. Vous pouvez avoir un accès complet aux données en intégrant simplement la petite taille du pipeline de données dans une application.
- Flexibilité des métadonnées
La séparation des champs personnalisés et des enregistrements est l'une des caractéristiques efficaces du pipeline de données. Les métadonnées vous permettent de retrouver la source des données, le créateur , les balises , les instructions , les nouvelles modifications et les options de visibilité .
- Composants intégrés
Bien que l'option personnalisable vous soit accessible, les pipelines de données ont des composants intégrés qui vous permettent de faire entrer ou sortir vos données du pipeline. Après l'activation intégrée, vous pouvez commencer à travailler avec les données via les opérateurs de flux.

La source
- Segmentation rapide des données en temps réel
Que vos données soient stockées sous forme de fichier Excel, sur une plate-forme de médias sociaux en ligne ou sur une base de données distante, les pipelines de données peuvent décomposer les données en petits morceaux qui font fondamentalement partie du flux de travail de streaming plus large.
Et le fonctionnement en temps réel ne nécessite pas de temps supplémentaire pour traiter vos données. Par conséquent, cela vous laisse une marge de manœuvre pour traiter et déduire plus facilement les données disponibles.
- Traitement en mémoire
Grâce à la disponibilité des pipelines de données, vous n'avez pas besoin de stocker ou d'enregistrer les nouvelles modifications apportées aux données dans un fichier, un disque ou une base de données aléatoire. Les pipelines exercent une fonction en mémoire qui rend l'accessibilité des données plus rapide que leur stockage sur un disque.
L'ère des mégadonnées
L'utilisation du terme « big data » est souvent abusive. Il s'agit plutôt d'un terme plus large qui se rapporte à ce qui s'est passé au cours des deux dernières années dans le monde analytique. Mais le but des outils d'intégration de Big Data est en grande partie de rassembler des événements et une multitude de sources pour créer un tableau de bord complet. Maintenant, rappelez-vous, vous pouvez assembler, dupliquer, nettoyer, transformer et régénérer les données disponibles pour avoir une fonctionnalité de navigation fluide avec ces outils logiciels d'analyse de données.

La source
De plus, la majorité des outils disponibles peuvent communiquer avec des fichiers volumineux, des bases de données, de nombreux appareils mobiles, des IoT, des services de streaming et des API. Par la suite, ce processus de communication crée un enregistrement dans le stockage en nuage ou le logiciel sur site. Les outils ETL SaaS tels que l' analyse de chasse-neige , les données de point ou cinq tran, par exemple , sont livrés avec des pilotes et des plug-ins supplémentaires pour rendre l'intégration aussi fluide que possible.
Cela dit, les décideurs ont pris conscience que ces outils ne sont que des moyens pour arriver à leurs fins. Ils ont pour objectif de récupérer et de stocker des données non structurées. Les entreprises, d'autre part, ont commencé à comprendre que les pipelines de données ont peut-être ouvert de nouvelles portes pour assembler des données analytiques, mais la responsabilité de prendre des décisions logiques repose toujours sur elles.
Dernières pensées
La supériorité technologique des pipelines de données continuera d'augmenter pour accueillir des segments de données plus importants avec une capacité de transformation. Cela dit, la tendance futuriste des pipelines de données est presque aussi vitale qu'elle l'était il y a dix ans. Un nouveau processus pour un pipeline de données bien surveillé est toujours à l'horizon. Et ce besoin d'obtenir une conception impeccable, une conformité, une efficacité des performances, une évolutivité plus élevée et une conception attrayante est certainement en voie d'amélioration.
Improvado est la solution de pipeline de données n°1 pour les spécialistes du marketing. Un outil ETL utilisé pour extraire, transformer et charger des données de plus de 150 plates-formes marketing différentes vers n'importe quelle destination finale, comme un outil de BI ou un entrepôt de données. En savoir plus ici.
Notre recommandation :
Découvrez les meilleurs outils et logiciels d'analyse marketing pour 2022
14 meilleurs outils ETL pour les entreprises à essayer en 2021
Comment rationaliser les données de Snowflake vers Tableau [Two Easy Ways]