
データパイプラインとは何ですか?
公開: 2019-08-15データパイプラインとは何ですか?
データパイプラインは、変換アプリケーション、フィルター、APIを介してデータを即座に送信する処理エンジンとして機能します。
データパイプラインは、公共交通機関のルートのように考えることができます。 データがバスのどこにジャンプするか、いつバスを離れるかを定義します。
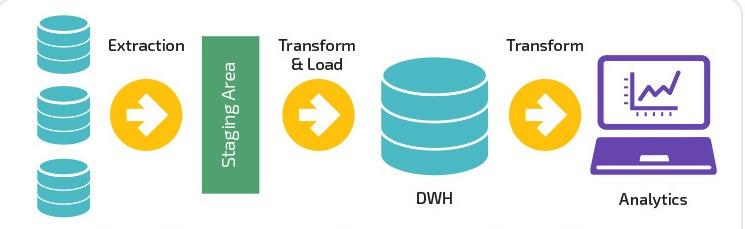
データパイプラインは、データソースの組み合わせを取り込み、変換ロジックを適用し(多くの場合、複数の順次ステージに分割されます)、データをデータウェアハウスなどのロード先に送信します。
ITセクターにおけるデジタルマーケティングの出現と継続的な技術の進歩により、データパイプラインは、複雑なデータの収集、変換、移行、および視覚化の救世主になりました。
アドビによると、マーケターのわずか35%が、パイプラインが効率的であると考えています。 ここImprovadoでは、それを変えるために着手しました。
Improvadoは、マーケターにとってナンバーワンのデータパイプラインソリューションです。 150を超えるさまざまなマーケティングプラットフォームから、BIツールやデータウェアハウスなどの最終的な宛先にデータを抽出、変換、および読み込むために使用されるETLツール。 詳細については、こちらをご覧ください。
データパイプラインの合理化と集中化により、静的およびリアルタイムのソースからの柔軟なスキーマが可能になります。 最終的に、この柔軟性は、データを小さな部分に分割するデータパイプラインの容量に結びつきます。
データの範囲とその影響の関係は、世界中の企業にとってより重要になっています。 同時に、この相互接続された結合を理解することは、データサイエンティストが遅延、ボトルネック、不明なソース、および重複の問題を整理するのに役立ちます。
それは本当です; データパイプラインがシステムネットワークを補完するようになりました。 より包括的なデータパイプラインであるほど、ネットワークシステムの適用性は、クラウドサービスとハイブリッドアプリケーションを組み合わせて作業することになるでしょう。
データパイプラインの台頭
さらに、データパイプラインは、多数のツールを統合し、圧倒的な量の大きなXMLおよびCSVファイルを取り込むための新しい扉を開きました。 ただし、リアルタイムでのデータの処理は、おそらくデータパイプラインの転換点でした。
その転換点により、フォーマットを変更せずに、データの大きなチャンクをある場所から別の場所に移動するための1時間の必要性が促進されました。 その結果、企業は、データを短期間で微調整、シフト、セグメント化、ショーケース、または転送するための新たな自由を見出しました。
何年にもわたって、ビジネスの運営方法の客観性は大きく変化しました。 焦点はもはや利益率の獲得に固執するのではなく、データサイエンティストが人々とつながる実行可能なソリューションをどのように提示できるかということです。 さらに、さらに重要なことに、これらの変更は、変革的で、追跡可能であり、将来のダイナミクスの変化に適応できる必要があります。 とはいえ、データパイプラインは、フラットファイル、データベース、データレイクの使用から、サーバーレスプラットフォームでのサービスの管理まで長い道のりを歩んできました。
データパイプラインインフラストラクチャ
データパイプラインのアーキテクチャインフラストラクチャは、洞察に満ちた情報を取得するために、データをキャプチャ、整理、ルーティング、または再ルーティングするための基盤に依存しています。 これが重要です。一般に、生データには無関係なエントリポイントがかなりの数あります。 さらに、これは、パイプラインインフラストラクチャが、設定された目標を達成するために、多数のリソースからのデータを結合、カスタマイズ、自動化、視覚化、変換、および移動する場所です。
さらに、データパイプラインのアーキテクチャインフラストラクチャは、分析と正確なビジネスインテリジェンスに基づく機能を補完します。 データ機能とは、顧客の行動、ロボットプロセス、自動化プロセス、顧客体験のパターン、およびユーザーの旅のパターンに関する貴重な洞察を得ることを意味します。 大量のデータを介したビジネスインテリジェンスと分析を通じて、リアルタイムの傾向と情報について学びます。
適切なデータエンジニアリングチームの選択
アプリケーションの詳細で常に忙しいビッグデータエンジニアリングチームを編成するのが賢明です。 構造データを取得して解決し、問題のトラブルシューティングを行い、複雑なテーブルを理解し、機能データをタイムリーに実装できるデータエンジニアを雇います。

データパイプラインの機能
データパイプラインの機能は情報を収集する役割を果たしますが、技術的には、データの保存、アクセス、および拡散の方法は、構成によって異なります。
たとえば、データの移動を最小限に抑えることは、UI上のすべての情報を手動で移動することなく、抽象レイヤーを介してデータを分散させることができます。 ストレージメカニズムとAWSなどの選択されたベンダーの間で、Alluxioを使用して、複数のファイルシステムの抽象レイヤーを作成できます。
データパイプラインの機能は、ベンダーのデータベースシステムの慈悲に依存するべきではありません。 さらに、柔軟性のないエラーおよび階層化された無料のインフラストラクチャを作成することのポイントは何でしょうか? このことを念頭に置いて、データパイプラインは、データシステムの将来を保護するために、 AWSなどのストレージデバイスに完全な情報を収集できる必要があります。
データパイプライン機能は、完全に美的な選択に基づいてネットワークを構築するのではなく、ビジネス分析に対応する必要があります。 たとえば、ストリーミングインフラストラクチャの機能は管理が非常に難しく、一般に、複雑なエンジニアリングタスクを管理するには専門的な経験と強力なビジネスが必要です。
Dockersなどの主流のコンテナサービスを使用して作成できます データパイプライン。 コンテナを使用して、セキュリティの機能応答を微調整し、スケーラビリティの可能性を確認し、ソフトウェアコードを改善することができます。 機能的応答の作成中に一般的に行われる一般的な間違いは、操作の実行と分散が不均一になることです。 秘訣は、 SQLでメインの変換ファイルを使用しないようにし、 CTASメソッドを適応させて複数のファイルパラメーターと操作を設定することです。
SnowflakeやPrestoなどのデータベースは組み込みのSQLアクセスを提供しますが、大量のデータは必然的にUI時間を短縮します。 したがって、わずかな出力エラーが発生する速度重視のアルゴリズムを適用してください。
データパイプラインを構築するためのツール
データパイプラインの列ファイルシステムは、最終的な累積データを保存および圧縮できる必要があります。 データエンジンは、UIでのそのようなファイルシステムの使用を増やします。 また、魅力的な視覚化を実現するには、ノートブックとしてiPythonまたはJupyterを使用します。 特定のパラメータベースのノートブックテンプレートを作成して、データの監査、グラフィックの強調表示、関連するプロットのフォーカス、またはデータのレビューを行うための組み込み関数を取得することもできます。
この特定のデータのサブセットは、 Google Cloud Platform (GCP)、 Python 、 Kafkaなどのツールを使用してリモートの場所に転送できます。 最初にコードの最終バージョンを作成する必要はありません。PythonのFakerライブラリ機能を使用して開始し、データパイプラインでコードを記述してテストします。

データパイプラインとETLの違いは何ですか?
ETLは、 Extract 、 Transform 、およびLoadに使用される一般的な頭字語です。 ETLの主な相違点は、データを抽出、変換、および特定のデータウェアハウスにロードするための1つのシステムに完全に焦点を合わせていることです。 または、 ETLはデータパイプラインに含まれるコンポーネントの1つにすぎません。
ETLパイプラインは、データをバッチで、調整された間隔で指定されたシステムに移動します。 比較すると、データパイプラインは、ストリーミングまたはリアルタイムを介してデータを変換および処理するための幅広い適用性を備えています。
データパイプラインは、必ずしもデータウェアハウスにデータをロードする必要はありませんが、 AmazonのS3 (Simple Storage Service)バケットなどの選択されたターゲットにロードするか、完全に異なるシステムに接続するかを選択できます。
利用可能なデータパイプラインソリューション
データパイプラインの性質と機能応答は、データを移行してリアルタイムソリューションに完全に使用するクラウドツールとは異なります。
- クラウドベース
クラウドベースのツールを使用してデータを統合することの費用便益比は非常に高くなります。 企業は、手段とリソースの使用を最小限に抑えて、最新のインフラストラクチャを維持することを学びました。 ただし、データパイプラインを管理するベンダーを選択するプロセスはまったく別の問題です。
- オープンソース
この用語は、顧客に代わってデータの使用を騙さない透過的なデータパイプラインを必要とするデータサイエンティストにとって強い意味を持っています。 オープンソースツールは、低コストでベンダーへの過度の依存を望んでいる中小企業の所有者にとって理想的です。 ただし、このようなツールの有用性には、ユーザーエクスペリエンスを調整および変更するための専門知識と機能の理解が必要です。
- リアルタイム処理
リアルタイム処理の実装は、規制されたストリーミングソースからのデータを処理したい企業にとって有益です。 さらに、金融市場とモバイルデバイスは、リアルタイム処理を行うために互換性があります。 とは言うものの、リアルタイム処理には、最小限の人間の操作、自動スケーリングオプション、および可能なパーティションが必要です。
- バッチの使用
バッチ処理により、企業はリアルタイムの可視性を必要とせずに、間隔を置いて大量のデータを簡単に転送できます。 このプロセスにより、多数のマーケティングデータを組み合わせて決定的な結果またはパターンを形成するアナリストが簡単になります。
自動化されたプロセス
それは、データの定義、抽出、ロード、および変換を繰り返す必要をなくします。 手動作業を入力する必要があるのはプログラムの開始時のみであり、システムがプロセス全体でそれを自動化することを忘れないでください。 ただし、自動化プロセスには、ビジネスのニーズを調整および調整できる翻訳者が必要です。

さらに、再現性の要素により、ユーザーは妥当なセキュリティでデータにアクセスするのに便利です。 ただし、プロセス全体がデバッグの影響を受けやすいことを理解する必要があります。 これは必然的に分析とデータのマージの変更につながります。
価値の高いプロジェクトの完了は、専門知識のレベルと、採用されたデータサイエンティストのトレーニングに完全に依存します。 ただし、一部の企業では、ハードウェアと人員を追加することは現実的な選択肢ではない場合があります。 それでも、データパイプラインの保守と改善のために、最終的には専門家チームのサービスを必要とします。
- 現代の統合
データパイプラインの構築に関しては、インフラストラクチャと機能のオプションは無限であり、Google AdWords、Analytics、Facebook広告、LinkedIn、およびYouTubeの統合と連携および統合されています。 つまり、コードに依存することなく、UIにアクセスしてデータパイプラインを開発できます。

ソース
デジタルマーケティングは過去数年で革命を起こしたかもしれませんが、データサイエンティストの役割もあります。データサイエンティストは、AdWordsデータとストリーミングコンテンツのデータセットの大部分を、選択したクラウドプラットフォームに数分で組み合わせることができるようになりました。 。
データセットを取り込んで処理し、世界中でリアルタイム分析を設定し、さまざまなプロジェクト間でストリームをパーソナライズすることもできます。 同様に、データ操作を再リンクして、1秒あたりの請求を確認できます。 ただし、オンプレミスとパブリッククラウドにまたがるシームレスなワークフローステーション環境も提供します。 最終的に、これにより、視覚的な探索、 IoTへの接続、および構造化データのクリーニングが非常に簡単になります。
データパイプラインの適合性とスケーラビリティ
データパイプラインのスケーラビリティは、数十億のデータポイントとかなり多くの製品スケールをスコアリングできる必要があります。 さらに、トリックは、クエリの可用性を容易にする方法でシステムにデータを保存することです。
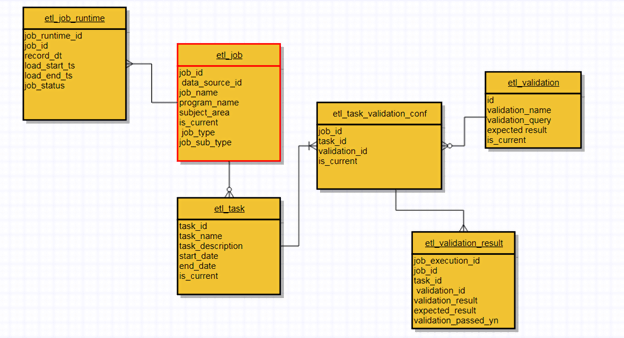
さらに、適切に設計されたデータパイプラインは、適合性とスケーラビリティのオプションを一緒に重視しているということです。 スケーラビリティーの比率が高いほど、互換性が高くなります。 同様に、データの言い換えの可能性に対する効果的な緊急時の手法として、再実行を使用します。 チェックポイントをチェックしてソースコードを変更し、プロセスを再開できます。 実際には、各エントリポイントのメタデータを使用するETLパイプラインを通過して、ステータス、収集されたデータ、および全体的な変換を確認できます。
データパイプラインのクラスター設計は、24時間年中無休の固定メカニズムではなく、負荷ごとにスケーリングする必要があります。 たとえば、AWS EMR(Elastic MapReduce)は、クラスターが特定のETLシーケンスを通過し、完了後に破棄するトリガーを受け取る自動スケーリングの完璧な例です。 データの性質に応じて、いつでもスケールアップまたはスケールダウンできることに注意してください。
さらに、ユーザーインターフェイス(UI)は、完全なデータの再実行とバッチステータスを監視するために十分に明確である必要があります。 さらに、プライマリデータモデルにクエリ(UI)を配置して、データパイプラインの状態を分析および確認できます。 たとえば、apache Airflowはステータスを監視するための実行可能なオプションですが、dev-opの使用とコードの記述が含まれています。 さらに、これは、検証を監視、チェックし、複雑な生産性データの問題を解決するために、アーキテクチャメタデータの使用が不可欠になる場所です。
データパイプラインが意思決定にどのように影響するか
今日、意思決定者は当然のことながらデータ指向の文化に依存しています。 さらに、複数の分析データを組み合わせて簡素化されたダッシュボードにすることは、確かにその成功の主な理由の1つです。
限定された構造化データは、ビジネスオーナーや起業家が収集した証拠に基づいて最適な意思決定を行うのに役立ちます。 ただし、このパターンは、単純なモデリング設計と記述統計データに基づいて情報に基づいた意思決定を行っていた管理者にも当てはまります。

ソース
さまざまなビジネスの指標の使用法と多様化は、従業員と管理者の間のコミュニケーションにも依存します。 重複を破棄し、適切な目的に在庫を確保する従業員と管理者の能力に関しても、同じ規則が適用されます。
事実は残っていますが、リスク評価と大胆な意思決定は常に市場で競争するための時間の必要性でした。 さらに、大量のデータにアクセスして視覚化する自由は、ソリューションの一部であり続けます。
とはいえ、統計値、平均、分布線、中央値を含むこのデータ中心の文化は、多くの人にとって理解するのが難しいかもしれません。 これが、利用可能な分析データに基づいて迅速かつ堅牢な決定を行いたい個人にダンプファイルが負担をかけない理由です。
成長するデータ文化が拡大しているように見えるため、計算上の意思決定は、データ収集に注がれる信頼にさらに依存するようになりました。
データパイプラインと視覚的美学の役割
機能的なプロセスとは別に、パイプラインは、正確な並列化、表示、および設計によって、人間の心が知覚できる最高の視覚的分析を形成する必要があります。 階層化された視覚化は、プロセス全体の最終目標として補完します。 そして、それはユーザーだけでなくマーケターにも有利です。
同じルールがコミュニケーションの活力にも当てはまります。 複雑なニューラルネットワークを作成し、トレンドモデルを強調することのポイントは、それが人々の間で基本的なアンダートーンパターンと価値認識を呼び出すことができない場合はどうなるでしょうか?
確かに、企業は単純なメトリックを実行することも、高度な分析モデルを使用することもできます。 人々が徹底的な分析のためにインターフェースをナビゲートして理解できる限り。 同様に、ユーザーが自分の要件に従って特定の変更を行えるように、コード化された各パイプライン間のギャップを狭くする必要があります。

明確な視覚的美的スタイルがないことに気付くかもしれません。 変更、改訂、再発見、そして新しい魅力的なトレンドへのリンクを経る必要があります。 この相関関係は、監視だけですべての違いが生まれることを理解しているコーダーにとってはほとんど明白です。
データパイプラインの利点
- シンプルで効果的
データパイプラインには複雑なインフラストラクチャと機能プロセスがある場合がありますが、その使用とナビゲーションは非常に簡単です。 同様に、データパイプラインを構築する学習プロセスは、ファイルの読み取りと書き込みを行う(JVM)Java仮想マシン言語の一般的な方法で実現できます。
一方、デコレータパターンの根本的な目的は、単純化された操作を堅牢な操作に変えることです。 プログラマーは、データのパイピングに関して、誰よりもアクセスのしやすさを高く評価しています。
- アプリとの互換性
データパイプラインの組み込みの性質により、顧客とデジタルマーケティングストラテジストの両方が使いやすくなります。 その適切な互換性により、インストール、構成ファイルの作成、またはサーバーへの依存が不要になります。 小さなサイズのデータパイプラインをアプリに埋め込むだけで、完全なデータアクセスが可能になります。
- メタデータの柔軟性
カスタムフィールドとレコードの分離は、データパイプラインの効率的な特性の1つです。 メタデータを使用すると、データのソース、作成者、タグ、指示、新しい変更、および表示オプションを追跡できます。
- 組み込みコンポーネント
カスタマイズ可能なオプションにアクセスできますが、データパイプラインには、パイプラインにデータを出し入れできるコンポーネントが組み込まれています。 組み込みのアクティベーションの後、ストリーム演算子を使用してデータの操作を開始できます。

ソース
- クイックリアルタイムデータセグメンテーション
データがExcelファイルの形式で保存されているか、オンラインのソーシャルメディアプラットフォームに保存されているか、リモートデータベースに保存されているかにかかわらず、データパイプラインは、基本的に大きなストリーミングワークフローの一部であるデータの小さなチャンクを分割できます。
また、リアルタイム機能は、データを処理するために余分な時間を必要としません。 その結果、これにより、手元のデータをより簡単に処理および推測できるようになります。
- インメモリ処理
データパイプラインが利用できるため、データの新しい変更をファイル、ディスク、またはランダムデータベースに保存または保存する必要はありません。 パイプラインは、データをディスクに保存するよりも速くデータにアクセスできるようにするメモリ内機能を発揮します。
ビッグデータの時代
「ビッグデータ」という用語の使用は、しばしば誤用されます。 これは、分析の世界で過去2年間に発生したものに関連するより広い用語です。 しかし、ビッグデータ統合ツールの目的は、主にイベントと多数のソースを収集して、包括的なダッシュボードを作成することです。 これらのデータ分析ソフトウェアツールを使用すると、利用可能なデータをアセンブル、複製、クレンジング、変換、および再生成して、スムーズなナビゲーション機能を利用できることを忘れないでください。

ソース
また、利用可能なツールの大部分は、大きなファイル、データベース、多数のモバイルデバイス、IoT、ストリーミングサービス、およびAPIと通信できます。 その後、この通信プロセスにより、クラウドストレージまたはオンプレミスのソフトウェアにレコードが作成されます。 たとえば、 snowplow analytics 、 stitch data 、 5tranなどのSaaSETLツールには、統合を可能な限りスムーズにするための追加のドライバーとプラグインが付属しています。
とはいえ、意思決定者は、これらのツールは単に目的を達成するための手段にすぎないことに気づきました。 これらは、非構造化データを取得して保存するという目的を果たします。 一方、企業は、データパイプラインが分析データを組み立てるための新しい扉を開いた可能性があることを理解し始めましたが、論理的な意思決定を行う責任は依然としてそれらにあります。
最終的な考え
データパイプラインの技術的優位性は、変革能力を備えたより大きなデータセグメントに対応するために上昇し続けます。 とはいえ、データパイプラインの未来的なトレンドは、10年前とほぼ同じくらい重要です。 十分に監視されたデータパイプラインの新しいプロセスは、常に視野に入っています。 そして、非の打ちどころのない設計、コンプライアンス、パフォーマンス効率、より高いスケーラビリティ、および魅力的な設計を実現するためのこの必要性は、確かに改善に向かって進んでいます。
Improvadoは、マーケターにとってナンバーワンのデータパイプラインソリューションです。 150を超えるさまざまなマーケティングプラットフォームから、BIツールやデータウェアハウスなどの最終的な宛先にデータを抽出、変換、および読み込むために使用されるETLツール。 詳細については、こちらをご覧ください。
私たちの推奨事項:
2022年の最高のマーケティング分析ツールとソフトウェアをチェックしてください
エンタープライズビジネスが2021年に試すのに最適な14のETLツール
SnowflakeからTableauにデータを合理化する方法[2つの簡単な方法]