
Введение в извлечение данных из PDF-файлов: инструменты и методы
Опубликовано: 2024-03-21В современном мире, управляемом данными, возможность эффективно извлекать информацию из PDF-документов является необходимостью для многих предприятий и исследователей. PDF-файлы — один из наиболее распространенных форматов для распространения и совместного использования документов, но их структурированное представление часто затрудняет извлечение данных. В этом сообщении блога рассматриваются основы извлечения данных из PDF-файлов, а также рассматриваются инструменты и методы, которые могут упростить этот процесс.
Зачем извлекать данные из PDF-файлов?

Источник: https://www.docsumo.com/blog/extract-data-from-pdf.
В эпоху цифровых технологий PDF-документы являются свидетельством сочетания последовательности, надежности и универсальной доступности. Формат переносимых документов (PDF), представленный компанией Adobe в 1990-х годах, быстро стал стандартом для распространения цифровых документов, которые сохраняют свое форматирование независимо от устройства или программного обеспечения, используемого для их просмотра. Сегодня PDF-файлы распространены повсеместно, служа хранилищем всего: от научных статей и юридических контрактов до технических руководств и финансовых отчетов. Тем не менее, под их статичной и полированной поверхностью скрывается огромное количество данных, часто скрытых от легкого доступа. Это подводит нас к важнейшему вопросу: почему извлечение данных из PDF-файлов так важно?
В основе цифровой трансформации лежат данные: данные, которые информируют, данные, которые направляют, и данные, которые решают. В нашем неустанном стремлении к эффективности, пониманию и инновациям извлечение данных из PDF-файлов служит мостом от статики к динамике, от информации к пониманию. Будь то анализ рыночных тенденций на основе исследовательских отчетов, оцифровка исторических записей для архивных целей или обработка счетов для финансовой сверки, извлечение данных из PDF-файлов позволяет предприятиям и исследователям преобразовывать статическую информацию в полезную информацию.
Проблемы извлечения данных PDF
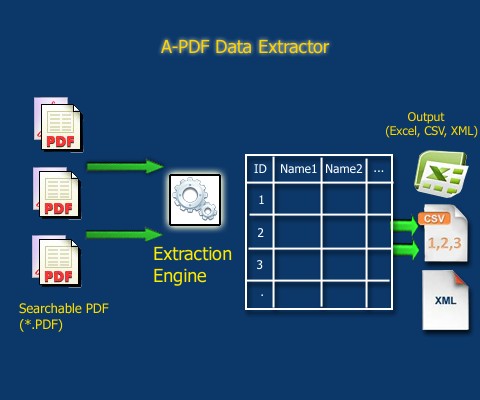
Источник: https://www.a-pdf.com/data-extractor/index.htm.
Извлечение данных из PDF-документов представляет собой уникальный набор задач, которые могут усложнить процесс как для предприятий, так и для исследователей и разработчиков. Несмотря на широкое использование PDF-файлов для цифровой документации, присущие им свойства и разнообразие форматов усложняют процесс извлечения данных. Здесь мы углубляемся в некоторые ключевые проблемы, возникающие при извлечении данных PDF, и предлагаем понимание того, почему то, что кажется простой задачей, часто может стать сложной задачей.
Присущая PDF-структуре сложность
PDF-файлы предназначены в первую очередь для представления, а не для хранения данных или манипулирования ими. Им часто не хватает последовательной структуры, что может затруднить автоматическое извлечение. В отличие от HTML или XML, где теги и элементы определяют структуру и иерархию, в PDF-файлах элементы располагаются в фиксированном макете. Это означает, что понимание логической структуры информации, например, различение заголовков, абзацев и таблиц данных, требует сложной интерпретации.
Различия в качестве документа
PDF-документы могут значительно различаться по качеству, особенно при работе со сканированными документами. Сканирование может привести к появлению шума, искажений и несоответствий в тексте, что делает процессы OCR (оптического распознавания символов) менее точными. Такие факторы, как разрешение сканирования, состояние физического документа и наличие пометок или аннотаций, могут еще больше усложнить извлечение данных.
Микс текста и изображений
Многие PDF-файлы содержат смесь текста и изображений, а в некоторых случаях важная информация встроена в изображения. Это требует использования технологии оптического распознавания символов для извлечения текста из изображений, что может оказаться сложной задачей, особенно при сложных макетах, различных шрифтах и разном качестве изображений. Более того, точность оптического распознавания символов может существенно повлиять на качество извлеченных данных.
Сложные макеты и форматы
PDF-файлы часто содержат сложные макеты, включая таблицы, многоколоночный текст, сноски и боковые панели. Эти элементы могут нарушить прямое извлечение текста, что приведет к потере или неправильной интерпретации данных. Например, извлечение данных из таблиц является особенно сложной задачей, поскольку организацию данных определяют пространственные отношения между элементами (а не логическая или иерархическая структура).
Зашифрованные или защищенные PDF-файлы
Некоторые PDF-файлы зашифрованы или защищены для защиты авторских прав или конфиденциальной информации, что ограничивает такие действия, как копирование, печать или редактирование. Извлечение данных из этих PDF-файлов требует расшифровки, для чего необходимо разрешение или соответствующий ключ расшифровки. Это добавляет дополнительный уровень сложности и юридических вопросов к процессу извлечения.
Разнообразное кодирование и сжатие
PDF-файлы могут использовать различные методы кодирования текста и сжатия изображений, некоторые из которых могут быть сложны для интерпретации или декодирования. Такое разнообразие требует гибких и надежных инструментов синтаксического анализа, способных обрабатывать различные кодировки и распаковывать контент по мере необходимости для извлечения данных.
Инструменты и методы эффективного извлечения данных
Библиотеки разбора PDF-файлов
- Библиотеки Python : Python предлагает несколько библиотек для извлечения данных PDF, включая PyPDF2 и PDFMiner для текстовых PDF-файлов и PyMuPDF для более сложных документов.
- Apache PDFBox : инструмент Java, который позволяет создавать PDF-документы и манипулировать ими, включая извлечение текста.
Инструменты оптического распознавания символов
При работе с отсканированными PDF-файлами или документами на основе изображений инструменты оптического распознавания текста необходимы. Tesseract, механизм оптического распознавания символов с открытым исходным кодом, широко используется для преобразования изображений в PDF-файлах в редактируемые текстовые форматы.
Коммерческое программное обеспечение для извлечения PDF-файлов
Некоторые коммерческие инструменты предлагают расширенные функции, такие как алгоритмы обучения на основе искусственного интеллекта, позволяющие решать сложные задачи по извлечению данных с более высокой точностью. Примеры включают Adobe Acrobat DC и ABBYY FineReader.
Лучшие практики по извлечению данных PDF
- Предварительная обработка PDF-файлов . Очистка документов перед извлечением (например, удаление ненужных изображений или пустых страниц) может значительно повысить точность.
- Пользовательские сценарии для автоматизации . Для крупномасштабных задач извлечения рассмотрите возможность написания собственных сценариев, использующих библиотеки анализа PDF. Это позволяет автоматизировать и настраивать систему в соответствии с конкретными потребностями.
- Проверка и проверка качества . Всегда включайте этап проверки извлеченных данных. В некоторой степени это можно автоматизировать, но часто требуется человеческий контроль.
Реальные приложения
- Финансовый сектор : банки и финансовые учреждения извлекают данные из PDF-файлов для кредитного анализа, оценки рисков и составления отчетов о соответствии.
- Здравоохранение : записи пациентов, исследовательские статьи и данные клинических испытаний часто хранятся в формате PDF и требуют извлечения для анализа и составления отчетов.
- Академические исследования : Исследователи извлекают данные из научных статей и научных статей для обзоров литературы и метаанализа.
Заключение
Извлечение данных из PDF-документов, хотя и является сложной задачей, но важно для анализа данных, составления отчетов и принятия решений в различных отраслях. Используя правильные инструменты и методы, организации могут преодолеть трудности, присущие извлечению данных PDF, и получить ценную информацию, содержащуюся в их документах. По мере развития технологий мы можем ожидать дальнейшего совершенствования инструментов извлечения информации, что сделает процесс более доступным и эффективным.
В PromptCloud мы понимаем важность точного и эффективного извлечения данных. Наши индивидуальные решения разработаны с учетом конкретных потребностей наших клиентов, гарантируя, что они смогут максимально эффективно использовать информацию, содержащуюся в их PDF-документах. Если вы хотите извлечь данные из нескольких документов или автоматизировать процесс извлечения из тысяч документов, мы здесь, чтобы помочь.

Используйте возможности данных с помощью PromptCloud. Свяжитесь с нами сегодня, чтобы узнать, как мы можем преобразовать ваш процесс извлечения данных PDF. Свяжитесь с нами по адресу [email protected].
Часто задаваемые вопросы
Как извлечь определенные данные из PDF-файла?
Для извлечения определенных данных из PDF-файла требуется сочетание инструментов и методов, адаптированных к характеру PDF-файла (текстовый или отсканированный/изображенный) и конкретным данным, которые вы хотите извлечь. Вот пошаговое руководство, которое поможет вам извлечь определенные данные из PDF-файлов:
Для текстовых PDF-файлов:
- Используйте библиотеки Python, такие как PyPDF2 или PDFMiner:
Эти библиотеки могут помочь вам извлечь текст из PDF-файлов, содержащих доступные для выбора текстовые слои.
- PyPDF2 : полезен для простого извлечения текста и манипулирования PDF-файлами (например, объединения PDF-файлов).
импортировать PyPDF2
# Откройте PDF-файл
с open('your_file.pdf', 'rb') как файл:
читатель = PyPDF2.PdfReader(файл)
# Извлекаем текст с первой страницы
страница = читатель.страницы[0]
текст = страница.extract_text()
печать (текст)
PDFMiner : более сложный, подходит для извлечения текста из сложных макетов.
из pdfminer.high_level импорт Extract_text
текст = экстракт_текст('ваш_файл.pdf')
печать (текст)
2. Извлеките и обработайте текст:
Получив текст, вам может потребоваться его обработать, чтобы найти и извлечь конкретные данные, которые вас интересуют. Это может включать в себя:
- Поиск ключевых слов или шаблонов с использованием регулярных выражений.
- Разделение текста на строки или абзацы для контекстно-зависимого извлечения.
Для отсканированных PDF-файлов или файлов PDF на основе изображений:
1. Используйте инструменты OCR (оптического распознавания символов):
Для PDF-файлов, которые по сути представляют собой изображения текста (например, отсканированные документы), вам потребуется использовать программное обеспечение OCR для преобразования изображений в выбираемый текст. Tesseract — популярный механизм оптического распознавания символов с открытым исходным кодом.
- Pytesseract : оболочка Python для Tesseract. Вам также потребуется конвертировать PDF-страницы в изображения, что можно сделать с помощью pdf2image.
из импорта pdf2image Convert_from_path
импортировать питессеракт
# Преобразование PDF в список изображений
images = Convert_from_path('your_scanned_file.pdf')
# Используйте pytesseract для распознавания изображения на изображении
для меня изображение в перечислении (изображения):
текст = pytesseract.image_to_string(изображение)
print(f»Текст страницы {i+1}:», text)
2. Обработайте извлеченный текст:
После оптического распознавания текст, скорее всего, потребует очистки и обработки для извлечения конкретных данных, которые вам нужны. Это может включать в себя удаление артефактов, возникающих при распознавании текста, анализ структуры текста и применение регулярных выражений для поиска шаблонов.
Как извлечь данные формы из PDF-файла?
Извлечение данных формы из PDF-файла, особенно если форма заполнена и сохранена, включает в себя специальные методы, которые могут анализировать структуру PDF-файла и извлекать данные, встроенные в поля формы. Существует несколько инструментов и библиотек на разных языках программирования, которые могут выполнить эту задачу, но Python остается одним из наиболее доступных и популярных вариантов благодаря таким библиотекам, как PyPDF2 и PDFMiner для текстовых PDF-файлов, а также PyMuPDF (также известному как Fitz) для большего. сложные задачи. Вот как вы можете извлечь данные формы из PDF-файла с помощью Python:
Использование PyMuPDF (Фитц)
PyMuPDF — это привязка Python для MuPDF — облегченного средства просмотра PDF, XPS и электронных книг. Он предлагает обширные функции для работы с PDF-файлами, включая извлечение текста, изображений и данных форм.
Монтаж
Сначала убедитесь, что у вас установлен PyMuPDF:
pip установить pymupdf
Извлечение данных формы
импортировать фитц # PyMuPDF
защита extract_form_data(pdf_path):
# Откройте PDF-файл
документ = fitz.open(pdf_path)
form_data = {}
для страницы в документе:
# Извлечение аннотаций (поля формы — это тип аннотаций)
анноты = page.annots()
если аннотирует:
для аннот в аннотациях:
информация = annot.info
field_type = info.get («субъект»)
имя_поля = info.get("заголовок")
field_value = info.get("содержимое")
если имя_поля и значение_поля:
# Заполняем словарь именами полей и значениями
данные_формы[имя_поля] = (значение_поля, тип_поля)
вернуть form_data
# Замените «your_form.pdf» на путь к вашей PDF-форме.
form_data = Extract_form_data («ваша_форма.pdf»)
для поля в form_data:
print(f»Поле: {поле}, Значение: {form_data[поле][0]}, Тип: {form_data[поле][1]}»)
Этот сценарий открывает PDF-файл и проходит по каждой странице, проверяя наличие аннотаций (где поля формы PDF распределены по категориям). Для каждой аннотации он извлекает имя, значение и тип поля и сохраняет их в словаре.
Использование PyPDF2
PyPDF2 — еще одна популярная библиотека для работы с PDF-файлами на Python. Он также может обрабатывать извлечение данных из форм, хотя для сложных PDF-файлов он может быть не таким полным, как PyMuPDF.
Монтаж
Убедитесь, что PyPDF2 установлен:
pip установить pypdf2
Извлечение данных формы
импортировать PyPDF2
защита Extract_form_data_py2 (pdf_path):
с open(pdf_path, 'rb') как файлом:
читатель = PyPDF2.PdfReader(файл)
form_data = {}
# Доступ к данным формы из программы чтения
поля = reader.get_fields()
для поля в полях:
form_data[поле] = поля[поле].get('/V', нет)
вернуть form_data
# Замените «your_form.pdf» на путь к вашей PDF-форме.
form_data = extract_form_data_py2 («ваша_форма.pdf»)
для поля в form_data:
print(f»Поле: {поле}, Значение: {form_data[поле]}»)
Эта функция использует PyPDF2 для открытия PDF-файла и прямого доступа к его полям формы. Он перебирает поля, извлекая имя и значение каждого и сохраняя их в словаре.
Можете ли вы извлечь данные из PDF-файла?
Да, вы можете извлечь данные из PDF-файла, но подход и инструменты, которые вам понадобятся, зависят от типа PDF-файла и характера данных, которые вы хотите извлечь. PDF-файлы можно разделить на два типа: текстовые и отсканированные/изображенные. Каждый тип требует разных методов эффективного извлечения данных.
Текстовые PDF-файлы
Эти PDF-файлы содержат выбираемый текст. Вы можете выделить, скопировать и вставить этот текст в другой документ. С текстовыми PDF-файлами, как правило, легче работать, когда дело доходит до очистки данных.
Инструменты и библиотеки:
- PyPDF2 и PDFMiner на Python популярны для извлечения текста из этих PDF-файлов. PyPDF2 прост и полезен для базового извлечения текста и манипулирования PDF-файлами, а PDFMiner предлагает более детальный контроль над макетом и форматированием, что делает его подходящим для сложных задач извлечения.
- Apache PDFBox , библиотека Java, также может извлекать текст из PDF-файлов и используется в приложениях корпоративного уровня.
PDF-файлы со сканами/изображениями
Эти PDF-файлы по сути представляют собой изображения текста. Поскольку текст является частью изображения, его нельзя выделить или скопировать напрямую. Для извлечения данных из этих PDF-файлов требуется оптическое распознавание символов (OCR) для преобразования изображений текста в реальный текст.
Инструменты и библиотеки:
- Tesseract OCR — один из самых мощных и широко используемых механизмов OCR. Его можно использовать напрямую или через оболочки, такие как Pytesseract в Python.
- Adobe Acrobat Pro предлагает встроенные возможности оптического распознавания символов и может конвертировать отсканированные PDF-файлы в текстовые документы с возможностью выбора и поиска.
Как автоматически извлечь данные из PDF-файла?
Автоматическое извлечение данных из PDF-файла предполагает использование программных инструментов, которые могут интерпретировать содержимое PDF-файла и преобразовывать его в структурированный формат. Процесс различается в зависимости от того, является ли PDF-файл текстовым или графическим (отсканированным). Вот как можно подойти к автоматическому извлечению данных из обоих типов PDF-файлов:
Для текстовых PDF-файлов
1. Использование библиотек Python:
- PyPDF2 или PDFMiner — популярные библиотеки Python для извлечения текста из текстовых PDF-файлов. PyPDF2 подходит для простых задач извлечения текста, а PDFMiner более эффективен для сложных макетов и кодирования.
- Пример с PyPDF2:
импортировать PyPDF2
с open('example.pdf', 'rb') как файл:
читатель = PyPDF2.PdfReader(файл)
текст = ”
для страницы в read.pages:
текст += page.extract_text()
печать (текст)
- Tabula или Camelot : если ваша цель — извлечь табличные данные из PDF-файлов, эти библиотеки специально разработаны для этой цели, а Camelot обеспечивает больший контроль над процессом извлечения.
2. Использование инструментов командной строки:
- pdftotext является частью набора инструментов Xpdf и может использоваться для преобразования PDF-документов в обычный текст непосредственно из командной строки, что делает его пригодным для пакетной обработки.
Для отсканированных PDF-файлов или файлов PDF на основе изображений
Отсканированные PDF-файлы требуют оптического распознавания символов (OCR) для преобразования изображений текста обратно в текст, доступный для выбора и поиска.
1. Использование Tesseract OCR:
- Tesseract — это механизм оптического распознавания символов с открытым исходным кодом. Pytesseract, оболочка Python для Tesseract, позволяет интегрировать возможности оптического распознавания символов в ваши сценарии.
- Пример с Pytesseract:
из изображения импорта PIL
импортировать питессеракт
из импорта pdf2image Convert_from_path
изображения = Convert_from_path('scanned_example.pdf')
текст = ”
для изображения в изображениях:
текст += pytesseract.image_to_string(изображение)
печать (текст)
2. Использование служб OCR:
- Adobe Acrobat Pro предлагает встроенные возможности оптического распознавания символов, которые позволяют автоматически распознавать текст в отсканированных документах.
- Онлайн-сервисы OCR : различные онлайн-платформы предоставляют услуги OCR, которые могут обрабатывать PDF-файлы в больших объемах. Однако помните о конфиденциальности и безопасности при загрузке конфиденциальных документов.