
Introducere în extragerea datelor din PDF-uri: instrumente și tehnici
Publicat: 2024-03-21În lumea actuală bazată pe date, capacitatea de a extrage eficient informații din documente PDF este o necesitate pentru multe companii și cercetători. PDF-urile sunt unul dintre cele mai comune formate pentru distribuirea și partajarea documentelor, dar prezentarea lor structurată face adesea dificilă extragerea datelor. Această postare de blog analizează elementele fundamentale ale extragerii datelor din PDF-uri, explorând atât instrumentele, cât și tehnicile care pot simplifica acest proces.
De ce să extrageți date din PDF-uri?

Sursa: https://www.docsumo.com/blog/extract-data-from-pdf
În vastul întindere a erei digitale, documentele PDF reprezintă o dovadă a amestecului de consistență, fiabilitate și accesibilitate universală. Introdus de Adobe în anii 1990, formatul de document portabil (PDF) a devenit rapid standardul pentru distribuirea documentelor digitale care își păstrează formatarea indiferent de dispozitivul sau software-ul folosit pentru a le vizualiza. Astăzi, PDF-urile sunt omniprezente, servind drept vas pentru orice, de la lucrări academice și contracte legale până la manuale tehnice și rapoarte financiare. Cu toate acestea, sub suprafața lor statică și lustruită se află o mulțime de date, adesea blocate de acces ușor. Acest lucru ne aduce la întrebarea crucială: de ce este atât de vitală extragerea datelor din PDF-uri?
În centrul transformării digitale se află datele – date care informează, date care ghidează și date care rezolvă. În căutarea noastră neobosită de eficiență, înțelegere și inovație, extragerea datelor din PDF-uri servește ca o punte de la static la dinamic, de la informații la perspectivă. Fie că este vorba despre analiza tendințelor pieței din rapoartele de cercetare, digitizarea înregistrărilor istorice în scopuri de arhivare sau procesarea facturilor pentru reconcilierea financiară, extragerea datelor din PDF-uri le permite companiilor și cercetătorilor să convertească informații statice în informații utile.
Provocări în extragerea datelor PDF
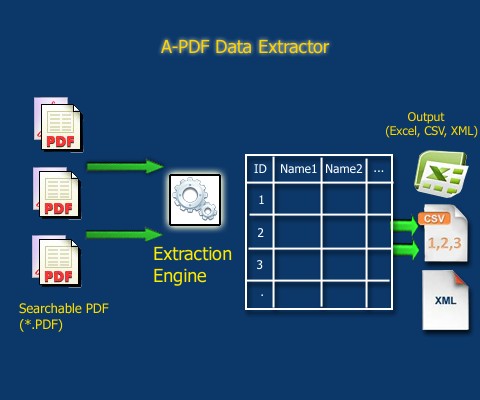
Sursa: https://www.a-pdf.com/data-extractor/index.htm
Extragerea datelor din documente PDF prezintă un set unic de provocări care pot complica procesul atât pentru companii, cât și pentru cercetători și dezvoltatori. În ciuda utilizării pe scară largă a PDF-urilor pentru documentația digitală, proprietățile lor inerente și formatele diverse adaugă straturi de complexitate eforturilor de extragere a datelor. Aici, analizăm unele dintre provocările cheie întâlnite în extracția datelor PDF, oferind informații despre motivul pentru care ceea ce pare a fi o sarcină simplă poate deveni adesea un efort complex.
Complexitatea inerentă a structurii PDF
PDF-urile sunt concepute în primul rând pentru prezentare, nu pentru stocarea sau manipularea datelor. De multe ori le lipsește o structură consistentă, ceea ce poate face dificilă extracția automată. Spre deosebire de HTML sau XML, unde etichetele și elementele definesc structura și ierarhia, PDF-urile poziționează elementele în machete fixe. Aceasta înseamnă că înțelegerea structurii logice a informațiilor, cum ar fi distincția între titluri, paragrafe și tabelele de date, necesită o interpretare sofisticată.
Variabilitatea calității documentelor
Documentele PDF pot varia semnificativ în calitate, mai ales atunci când aveți de-a face cu documente scanate. Scanările pot introduce zgomot, distorsiuni și inconsecvențe în text, făcând procesele OCR (recunoaștere optică a caracterelor) mai puțin precise. Factori precum rezoluția scanării, starea documentului fizic și prezența semnelor sau adnotărilor pot complica și mai mult extragerea datelor.
Mix de text și imagine
Multe PDF-uri conțin o combinație de text și imagini și, în unele cazuri, informații cruciale sunt încorporate în imagini. Acest lucru necesită utilizarea tehnologiei OCR pentru a extrage text din imagini, ceea ce poate fi o provocare, în special cu aspectul complex, fonturile variate și calitatea mixtă a imaginilor. În plus, acuratețea OCR poate avea un impact semnificativ asupra calității datelor extrase.
Aspecte și formate complexe
PDF-urile prezintă adesea aspecte complexe, inclusiv tabele, text cu mai multe coloane, note de subsol și bare laterale. Aceste elemente pot perturba extragerea simplă a textului, ducând la pierderea datelor sau la interpretarea greșită. Extragerea datelor din tabele, de exemplu, este deosebit de dificilă deoarece relația spațială dintre elemente (mai degrabă decât o structură logică sau ierarhică) definește organizarea datelor.
PDF-uri criptate sau securizate
Unele PDF-uri sunt criptate sau securizate pentru a proteja drepturile de autor sau informațiile sensibile, limitând acțiuni precum copierea, imprimarea sau editarea. Extragerea datelor din aceste fișiere PDF necesită decriptare, pentru care este necesară permisiunea sau cheia de decriptare corespunzătoare. Acest lucru adaugă un strat suplimentar de complexitate și considerente juridice procesului de extracție.
Codificare și compresie diverse
Fișierele PDF pot folosi o varietate de codificări de text și tehnici de comprimare a imaginilor, dintre care unele pot să nu fie ușor de interpretat sau decodat. Această diversitate necesită instrumente de analiză flexibile și robuste, capabile să gestioneze diferite codificări și să decomprima conținutul după cum este necesar pentru extragerea datelor.
Instrumente și tehnici pentru extragerea eficientă a datelor
Biblioteci de analiză PDF
- Biblioteci Python : Python oferă mai multe biblioteci pentru extragerea datelor PDF, inclusiv PyPDF2 și PDFMiner pentru PDF-uri bazate pe text și PyMuPDF pentru documente mai complexe.
- Apache PDFBox : Un instrument Java care permite crearea și manipularea documentelor PDF, inclusiv extragerea textului.
Instrumente OCR
Când aveți de-a face cu PDF-uri scanate sau documente bazate pe imagini, instrumentele OCR sunt esențiale. Tesseract, un motor OCR open-source, este utilizat pe scară largă pentru conversia imaginilor din PDF-uri în formate de text editabile.
Software comercial de extragere PDF
Mai multe instrumente comerciale oferă funcții avansate, cum ar fi algoritmi de învățare bazați pe inteligență artificială, pentru a gestiona sarcini complexe de extragere a datelor cu o precizie mai mare. Exemplele includ Adobe Acrobat DC și ABBYY FineReader.
Cele mai bune practici pentru extragerea datelor PDF
- Preprocesează PDF-uri : curățarea documentelor înainte de extragere (de exemplu, eliminarea imaginilor inutile sau a paginilor goale) poate îmbunătăți semnificativ acuratețea.
- Scripturi personalizate pentru automatizare : pentru sarcini de extracție la scară largă, luați în considerare scrierea de scripturi personalizate care utilizează biblioteci de analiză PDF. Acest lucru permite automatizarea și personalizarea în funcție de nevoile specifice.
- Validare și verificări de calitate : includeți întotdeauna un pas pentru a valida datele extrase. Acest lucru poate fi automatizat într-o oarecare măsură, dar adesea necesită supraveghere umană.
Aplicații din lumea reală
- Sector financiar : băncile și instituțiile financiare extrag date din PDF-uri pentru analiza creditului, evaluarea riscurilor și raportarea conformității.
- Asistență medicală : Înregistrările pacienților, articolele de cercetare și datele din studiile clinice sunt adesea stocate în format PDF și necesită extragere pentru analiză și raportare.
- Cercetare academică : Cercetătorii extrag date din articolele academice și lucrările academice pentru recenzii de literatură și meta-analize.
Concluzie
Extragerea datelor din documente PDF, deși este o provocare, este esențială pentru analiza datelor, raportarea și luarea deciziilor în diverse industrii. Folosind instrumentele și tehnicile potrivite, organizațiile pot depăși dificultățile inerente ale extragerii datelor PDF și pot debloca informații valoroase conținute în documentele lor. Pe măsură ce tehnologia avansează, ne putem aștepta la îmbunătățiri continue ale instrumentelor de extracție, făcând procesul mai accesibil și mai eficient.

La PromptCloud, înțelegem importanța extragerii de date precise și eficiente. Soluțiile noastre personalizate sunt concepute pentru a satisface nevoile specifice ale clienților noștri, asigurându-se că aceștia pot profita la maximum de informațiile conținute în documentele lor PDF. Indiferent dacă doriți să extrageți date dintr-o mână de documente sau să automatizați procesul de extragere în mii, suntem aici pentru a vă ajuta.
Îmbrățișați puterea datelor cu PromptCloud. Luați legătura astăzi pentru a descoperi cum vă putem transforma procesul de extragere a datelor PDF. Luați legătura la [email protected]
întrebări frecvente
Cum extrag anumite date dintr-un PDF?
Extragerea anumitor date dintr-un PDF necesită o combinație de instrumente și tehnici, adaptate naturii fișierului PDF (pe bază de text sau scanat/bazat pe imagini) și a datelor specifice pe care doriți să le extrageți. Iată un ghid pas cu pas pentru a vă ajuta să extrageți date specifice din PDF-uri:
Pentru PDF-uri bazate pe text:
- Utilizați biblioteci Python precum PyPDF2 sau PDFMiner:
Aceste biblioteci vă pot ajuta să extrageți text din PDF-uri care conțin straturi de text selectabile.
- PyPDF2 : util pentru extragerea simplă a textului și manipularea PDF-urilor (cum ar fi îmbinarea PDF-urilor).
importa PyPDF2
# Deschideți fișierul PDF
cu open('your_file.pdf', 'rb') ca fișier:
cititor = PyPDF2.PdfReader(fișier)
# Extrageți textul de pe prima pagină
pagina = reader.pages[0]
text = page.extract_text()
print(text)
PDFMiner : Mai sofisticat, potrivit pentru extragerea textului din machete complexe.
din pdfminer.high_level import extract_text
text = extract_text('fișierul_dvs.pdf')
print(text)
2. Extrageți și procesați textul:
Odată ce aveți textul, poate fi necesar să-l procesați pentru a găsi și extrage datele specifice care vă interesează. Aceasta poate implica:
- Căutarea de cuvinte cheie sau modele folosind expresii regulate.
- Împărțirea textului în rânduri sau paragrafe pentru extragerea în funcție de context.
Pentru PDF-uri scanate/bazate pe imagini:
1. Utilizați instrumente OCR (recunoaștere optică a caracterelor):
Pentru PDF-urile care sunt în esență imagini de text (de exemplu, documente scanate), va trebui să utilizați software-ul OCR pentru a converti imaginile în text selectabil. Tesseract este un motor OCR popular, open-source.
- Pytesseract : un înveliș Python pentru Tesseract. De asemenea, va trebui să convertiți paginile PDF în imagini, ceea ce se poate face folosind pdf2image.
din pdf2image import convert_from_path
import pytesseract
# Convertiți PDF într-o listă de imagini
imagini = convert_from_path('your_scanned_file.pdf')
# Utilizați pytesseract pentru a face OCR pe imagine
pentru i, imagine în enumerate(imagini):
text = pytesseract.image_to_string(imagine)
print(f”Pagina {i+1} Text:”, text)
2. Procesați textul extras:
După OCR, textul va avea probabil nevoie de curățare și procesare pentru a extrage punctele de date specifice de care aveți nevoie. Aceasta poate include eliminarea artefactelor introduse de OCR, analizarea textului pentru structură și aplicarea expresiilor regulate pentru a găsi modele.
Cum extrag datele formularului dintr-un PDF?
Extragerea datelor de formular dintr-un PDF, mai ales dacă formularul este completat și salvat, implică metode specifice care pot analiza structura PDF și extrage datele încorporate în câmpurile formularului. Există mai multe instrumente și biblioteci în diferite limbaje de programare care pot îndeplini această sarcină, dar Python rămâne una dintre cele mai accesibile și populare opțiuni datorită bibliotecilor precum PyPDF2 și PDFMiner pentru PDF-uri bazate pe text și PyMuPDF (cunoscut și sub numele de Fitz) pentru mai multe sarcini complexe. Iată cum puteți extrage datele formularului dintr-un PDF folosind Python:
Utilizarea PyMuPDF (Fitz)
PyMuPDF este o legare Python pentru MuPDF – un vizualizator ușor de PDF, XPS și E-book. Oferă funcții extinse pentru lucrul cu PDF-uri, inclusiv extragerea de text, imagini și date de formular.
Instalare
În primul rând, asigurați-vă că aveți instalat PyMuPDF:
pip install pymupdf
Extragerea datelor din formular
import fitz # PyMuPDF
def extract_form_data(pdf_path):
# Deschideți PDF-ul
doc = fitz.open(pdf_path)
form_data = {}
pentru pagina din document:
# Extrageți adnotări (câmpurile de formular sunt un tip de adnotare)
annots = page.annots()
dacă adnotări:
pentru annot în adnoturi:
info = annot.info
field_type = info.get(„subiect”)
field_name = info.get(„titlu”)
field_value = info.get(„conținut”)
dacă field_name și field_value:
# Completați dicționarul cu nume de câmpuri și valori
form_data[field_name] = (field_value, field_type)
returnează date_form
# Înlocuiți „formularul_dvs..pdf” cu calea către formularul dumneavoastră PDF
form_data = extract_form_data(„formul_dvs..pdf”)
pentru câmpul din form_data:
print(f”Câmp: {câmp}, Valoare: {form_date[câmp][0]}, Tip: {form_data[câmp][1]}”)
Acest script deschide un PDF și iterează prin fiecare pagină, verificând adnotări (unde sunt clasificate câmpurile de formular PDF). Pentru fiecare adnotare, extrage numele câmpului, valoarea și tipul, stocându-le într-un dicționar.
Folosind PyPDF2
PyPDF2 este o altă bibliotecă populară pentru lucrul cu PDF-uri în Python. De asemenea, poate gestiona extragerea datelor din formular, deși ar putea să nu fie la fel de cuprinzător ca PyMuPDF pentru PDF-uri complexe.
Instalare
Asigurați-vă că PyPDF2 este instalat:
pip install pypdf2
Extragerea datelor din formular
importa PyPDF2
def extract_form_data_py2(pdf_path):
cu open(pdf_path, 'rb') ca fișier:
cititor = PyPDF2.PdfReader(fișier)
form_data = {}
# Accesați datele formularului de la cititor
câmpuri = reader.get_fields()
pentru câmp în câmpuri:
form_data[field] = fields[field].get('/V', None)
returnează date_form
# Înlocuiți „formularul_dvs..pdf” cu calea către formularul dumneavoastră PDF
form_data = extract_form_data_py2(„form_dvs.pdf”)
pentru câmpul din form_data:
print(f”Câmp: {câmp}, Valoare: {form_date[câmp]}”)
Această funcție utilizează PyPDF2 pentru a deschide un fișier PDF și a accesa direct câmpurile de formular. Iterează prin câmpuri, extragând numele și valoarea fiecăruia și stochându-le într-un dicționar.
Puteți răzui date dintr-un PDF?
Da, puteți extrage date dintr-un PDF, dar abordarea și instrumentele de care veți avea nevoie depind de tipul de PDF și de natura datelor pe care doriți să le extrageți. PDF-urile pot fi clasificate pe scară largă în două tipuri: bazate pe text și scanate/bazate pe imagini. Fiecare tip necesită tehnici diferite pentru extragerea eficientă a datelor.
PDF-uri bazate pe text
Aceste PDF-uri conțin text care poate fi selectat. Puteți evidenția, copia și lipi acest text într-un alt document. PDF-urile bazate pe text sunt, în general, mai ușor de lucrat atunci când vine vorba de data scraping.
Instrumente și biblioteci:
- PyPDF2 și PDFMiner în Python sunt populare pentru extragerea textului din aceste PDF-uri. PyPDF2 este simplu și util pentru extragerea textului de bază și manipularea PDF, în timp ce PDFMiner oferă un control mai granular asupra aspectului și formatării, făcându-l potrivit pentru nevoi complexe de extracție.
- Apache PDFBox , o bibliotecă Java, poate extrage, de asemenea, text din PDF-uri și este folosită în aplicații la nivel de întreprindere.
PDF-uri scanate/bazate pe imagini
Aceste PDF-uri sunt în esență imagini de text. Deoarece textul face parte dintr-o imagine, nu poate fi selectat sau copiat direct. Extragerea datelor din aceste fișiere PDF necesită recunoașterea optică a caracterelor (OCR) pentru a converti imaginile textului în text real.
Instrumente și biblioteci:
- Tesseract OCR este unul dintre cele mai puternice și mai utilizate motoare OCR. Poate fi folosit direct sau prin pachete precum Pytesseract în Python.
- Adobe Acrobat Pro oferă capabilități OCR încorporate și poate converti PDF-urile scanate în documente text selectabile și căutate.
Cum extrag automat date dintr-un PDF?
Extragerea automată a datelor dintr-un PDF implică utilizarea instrumentelor software care pot interpreta conținutul PDF-ului și le pot converti într-un format structurat. Procesul diferă în funcție de faptul dacă PDF-ul este bazat pe text sau pe imagini (scanat). Iată cum să abordați extragerea automată a datelor din ambele tipuri de PDF-uri:
Pentru PDF-uri bazate pe text
1. Folosind bibliotecile Python:
- PyPDF2 sau PDFMiner sunt biblioteci populare Python pentru extragerea textului din PDF-uri bazate pe text. PyPDF2 este potrivit pentru sarcini simple de extragere a textului, în timp ce PDFMiner este mai puternic pentru aspecte și codări complexe.
- Exemplu cu PyPDF2:
importa PyPDF2
cu open('example.pdf', 'rb') ca fișier:
cititor = PyPDF2.PdfReader(fișier)
text = ”
pentru pagina din reader.pages:
text += page.extract_text()
print(text)
- Tabula sau Camelot : Dacă scopul dvs. este să extrageți date de tabel din PDF-uri, aceste biblioteci sunt concepute special pentru acest scop, Camelot oferind mai mult control asupra procesului de extracție.
2. Utilizarea instrumentelor din linia de comandă:
- pdftotext face parte din setul de instrumente Xpdf și poate fi folosit pentru a converti documente PDF în text simplu direct din linia de comandă, făcându-l potrivit pentru procesarea în serie.
Pentru PDF-uri scanate/bazate pe imagini
PDF-urile scanate necesită recunoaștere optică a caracterelor (OCR) pentru a converti imaginile textului înapoi în text care poate fi selectat și căutat.
1. Folosind Tesseract OCR:
- Tesseract este un motor OCR open-source. Pytesseract, un wrapper Python pentru Tesseract, vă permite să integrați capabilități OCR în scripturile dvs.
- Exemplu cu Pytesseract:
din imaginea de import PIL
import pytesseract
din pdf2image import convert_from_path
imagini = convert_from_path('scanned_example.pdf')
text = ”
pentru imaginea din imagini:
text += pytesseract.image_to_string(imagine)
print(text)
2. Utilizarea serviciilor OCR:
- Adobe Acrobat Pro oferă capabilități OCR încorporate care pot recunoaște automat textul din documentele scanate.
- Servicii OCR online : diverse platforme online oferă servicii OCR care pot procesa PDF-uri în vrac. Cu toate acestea, aveți grijă de confidențialitate și securitate atunci când încărcați documente sensibile.