
Introdução à extração de dados de PDFs: ferramentas e técnicas
Publicados: 2024-03-21No mundo atual, orientado por dados, a capacidade de extrair informações de documentos PDF com eficiência é uma necessidade para muitas empresas e pesquisadores. Os PDFs são um dos formatos mais comuns para distribuição e compartilhamento de documentos, mas sua apresentação estruturada muitas vezes torna a extração de dados um desafio. Esta postagem do blog investiga os fundamentos da extração de dados de PDFs, explorando as ferramentas e técnicas que podem agilizar esse processo.
Por que extrair dados de PDFs?

Fonte: https://www.docsumo.com/blog/extract-data-from-pdf
Na vasta extensão da era digital, os documentos PDF são um testemunho da combinação de consistência, confiabilidade e acessibilidade universal. Introduzido pela Adobe na década de 1990, o Portable Document Format (PDF) rapidamente se tornou o padrão para distribuição de documentos digitais que mantêm sua formatação independentemente do dispositivo ou software usado para visualizá-los. Hoje, os PDFs são onipresentes, servindo como veículo para tudo, desde trabalhos acadêmicos e contratos jurídicos até manuais técnicos e relatórios financeiros. No entanto, por baixo da sua superfície estática e polida encontra-se uma riqueza de dados, muitas vezes impedidos de serem facilmente acessíveis. Isto nos leva à questão crucial: por que extrair dados de PDFs é tão vital?
No centro da transformação digital estão os dados – dados que informam, dados que orientam e dados que resolvem. Na nossa busca incessante por eficiência, compreensão e inovação, a extração de dados de PDFs serve como uma ponte entre o estático e o dinâmico, da informação ao insight. Seja analisando tendências de mercado a partir de relatórios de pesquisa, digitalizando registros históricos para fins de arquivamento ou processando faturas para reconciliação financeira, a extração de dados de PDFs permite que empresas e pesquisadores convertam informações estáticas em insights acionáveis.
Desafios na extração de dados PDF
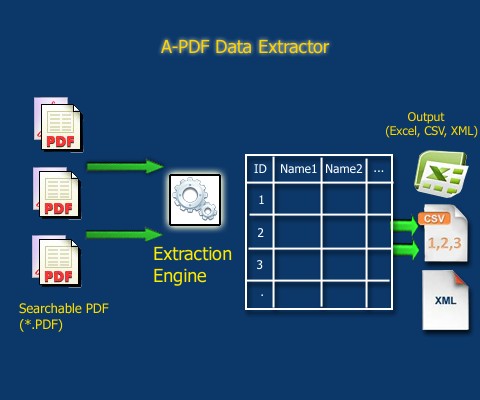
Fonte: https://www.a-pdf.com/data-extractor/index.htm
Extrair dados de documentos PDF apresenta um conjunto único de desafios que podem complicar o processo para empresas, pesquisadores e desenvolvedores. Apesar do uso generalizado de PDFs para documentação digital, suas propriedades inerentes e diversos formatos acrescentam camadas de complexidade aos esforços de extração de dados. Aqui, nos aprofundamos em alguns dos principais desafios encontrados na extração de dados PDF, oferecendo insights sobre por que o que parece ser uma tarefa simples pode muitas vezes se tornar um empreendimento complexo.
Complexidade inerente à estrutura do PDF
Os PDFs são projetados principalmente para apresentação, não para armazenamento ou manipulação de dados. Muitas vezes carecem de uma estrutura consistente, o que pode dificultar a extração automatizada. Ao contrário do HTML ou XML, onde tags e elementos definem estrutura e hierarquia, os PDFs posicionam os elementos em layouts fixos. Isto significa que a compreensão da estrutura lógica da informação, como a distinção entre títulos, parágrafos e tabelas de dados, requer uma interpretação sofisticada.
Variabilidade na qualidade do documento
Os documentos PDF podem variar significativamente em qualidade, especialmente quando se trata de documentos digitalizados. As digitalizações podem introduzir ruído, distorções e inconsistências no texto, tornando os processos de OCR (reconhecimento óptico de caracteres) menos precisos. Fatores como a resolução da digitalização, a condição do documento físico e a presença de marcas ou anotações podem complicar ainda mais a extração de dados.
Mistura de texto e imagem
Muitos PDFs contêm uma mistura de texto e imagens e, em alguns casos, informações cruciais estão incorporadas nas imagens. Isso requer o uso da tecnologia OCR para extrair texto de imagens, o que pode ser desafiador, especialmente com layouts complexos, fontes variadas e qualidade mista das imagens. Além disso, a precisão do OCR pode impactar significativamente a qualidade dos dados extraídos.
Layouts e formatos complexos
Os PDFs geralmente apresentam layouts complexos, incluindo tabelas, texto com várias colunas, notas de rodapé e barras laterais. Esses elementos podem atrapalhar a extração simples de texto, levando à perda de dados ou à interpretação incorreta. Extrair dados de tabelas, por exemplo, é particularmente desafiador porque o relacionamento espacial entre os elementos (em vez de uma estrutura lógica ou hierárquica) define a organização dos dados.
PDFs criptografados ou protegidos
Alguns PDFs são criptografados ou protegidos para proteger direitos autorais ou informações confidenciais, restringindo ações como cópia, impressão ou edição. A extração de dados desses PDFs requer descriptografia, para a qual é necessária permissão ou a chave de descriptografia apropriada. Isto acrescenta uma camada adicional de complexidade e considerações legais ao processo de extração.
Codificação e compactação diversas
Os arquivos PDF podem usar uma variedade de codificações de texto e técnicas de compactação de imagens, algumas das quais podem não ser fáceis de interpretar ou decodificar. Essa diversidade requer ferramentas de análise flexíveis e robustas, capazes de lidar com diferentes codificações e descompactar conteúdo conforme necessário para a extração de dados.
Ferramentas e técnicas para extração eficaz de dados
Bibliotecas de análise de PDF
- Bibliotecas Python : Python oferece várias bibliotecas para extração de dados PDF, incluindo PyPDF2 e PDFMiner para PDFs baseados em texto e PyMuPDF para documentos mais complexos.
- Apache PDFBox : Uma ferramenta Java que permite a criação e manipulação de documentos PDF, incluindo extração de texto.
Ferramentas de OCR
Ao lidar com PDFs digitalizados ou documentos baseados em imagens, as ferramentas de OCR são essenciais. Tesseract, um mecanismo de OCR de código aberto, é amplamente utilizado para converter imagens em PDFs em formatos de texto editáveis.
Software comercial de extração de PDF
Várias ferramentas comerciais oferecem recursos avançados, como algoritmos de aprendizagem baseados em IA, para lidar com tarefas complexas de extração de dados com maior precisão. Os exemplos incluem Adobe Acrobat DC e ABBYY FineReader.
Melhores práticas para extração de dados PDF
- Pré-processar PDFs : Limpar documentos antes da extração (por exemplo, remover imagens desnecessárias ou páginas em branco) pode melhorar significativamente a precisão.
- Scripts personalizados para automação : para tarefas de extração em grande escala, considere escrever scripts personalizados que usem bibliotecas de análise de PDF. Isso permite automação e customização de acordo com necessidades específicas.
- Validação e verificações de qualidade : Sempre incorpore uma etapa para validar os dados extraídos. Isto pode ser automatizado até certo ponto, mas muitas vezes requer supervisão humana.
Aplicativos do mundo real
- Setor Financeiro : Bancos e instituições financeiras extraem dados de PDFs para análise de crédito, avaliação de risco e relatórios de conformidade.
- Assistência médica : registros de pacientes, artigos de pesquisa e dados de ensaios clínicos são frequentemente armazenados em formato PDF e exigem extração para análise e geração de relatórios.
- Pesquisa Acadêmica : Os pesquisadores extraem dados de artigos acadêmicos e trabalhos acadêmicos para revisões de literatura e meta-análises.
Conclusão
A extração de dados de documentos PDF, embora desafiadora, é essencial para análise de dados, relatórios e tomada de decisões em vários setores. Ao aproveitar as ferramentas e técnicas certas, as organizações podem superar as dificuldades inerentes à extração de dados PDF e desbloquear informações valiosas contidas nos seus documentos. À medida que a tecnologia avança, podemos esperar melhorias contínuas nas ferramentas de extração, tornando o processo mais acessível e eficiente.

Na PromptCloud, entendemos a importância da extração de dados precisa e eficiente. Nossas soluções customizadas são projetadas para atender às necessidades específicas de nossos clientes, garantindo que eles aproveitem ao máximo as informações contidas em seus documentos PDF. Esteja você procurando extrair dados de alguns documentos ou automatizar o processo de extração de milhares, estamos aqui para ajudar.
Aproveite o poder dos dados com PromptCloud. Entre em contato hoje mesmo para descobrir como podemos transformar seu processo de extração de dados PDF. Entre em contato em [email protected]
perguntas frequentes
Como extraio dados específicos de um PDF?
A extração de dados específicos de um PDF requer uma combinação de ferramentas e técnicas, adaptadas à natureza do arquivo PDF (baseado em texto ou digitalizado/baseado em imagem) e aos dados específicos que você deseja extrair. Aqui está um guia passo a passo para ajudá-lo a extrair dados específicos de PDFs:
Para PDFs baseados em texto:
- Use bibliotecas Python como PyPDF2 ou PDFMiner:
Essas bibliotecas podem ajudá-lo a extrair texto de PDFs que contêm camadas de texto selecionáveis.
- PyPDF2 : Útil para extração simples de texto e manipulação de PDF (como mesclar PDFs).
importar PyPDF2
# Abra o arquivo PDF
com open('your_file.pdf', 'rb') como arquivo:
leitor = PyPDF2.PdfReader(arquivo)
# Extraia o texto da primeira página
página = leitor.páginas[0]
texto = página.extract_text()
imprimir (texto)
PDFMiner : Mais sofisticado, adequado para extrair texto de layouts complexos.
de pdfminer.high_level importar extract_text
texto = extract_text('seu_arquivo.pdf')
imprimir (texto)
2. Extraia e processe o texto:
Assim que tiver o texto, pode ser necessário processá-lo para encontrar e extrair os dados específicos de seu interesse. Isso pode envolver:
- Pesquisando palavras-chave ou padrões usando expressões regulares.
- Dividir o texto em linhas ou parágrafos para extração baseada no contexto.
Para PDFs digitalizados/baseados em imagem:
1. Use ferramentas de OCR (reconhecimento óptico de caracteres):
Para PDFs que são essencialmente imagens de texto (por exemplo, documentos digitalizados), você precisará usar um software de OCR para converter as imagens em texto selecionável. Tesseract é um mecanismo OCR popular e de código aberto.
- Pytesseract : um wrapper Python para Tesseract. Você também precisará converter páginas PDF em imagens, o que pode ser feito usando pdf2image.
de pdf2image importar convert_from_path
importar pytesseract
# Converta PDF em uma lista de imagens
imagens = convert_from_path('seu_arquivo_digitalizado.pdf')
# Use pytesseract para fazer OCR na imagem
para i, imagem em enumerar (imagens):
texto = pytesseract.image_to_string(imagem)
print(f”Página {i+1} Texto:”, texto)
2. Processe o texto extraído:
Após o OCR, o texto provavelmente precisará de limpeza e processamento para extrair os pontos de dados específicos de que você precisa. Isso pode incluir a remoção de artefatos introduzidos pelo OCR, a análise da estrutura do texto e a aplicação de expressões regulares para encontrar padrões.
Como extraio dados de formulário de um PDF?
A extração de dados de formulário de um PDF, especialmente se o formulário for preenchido e salvo, envolve métodos específicos que podem analisar a estrutura do PDF e extrair os dados incorporados nos campos do formulário. Existem diversas ferramentas e bibliotecas em diferentes linguagens de programação que podem realizar essa tarefa, mas Python continua sendo uma das opções mais acessíveis e populares devido a bibliotecas como PyPDF2 e PDFMiner para PDFs baseados em texto, e PyMuPDF (também conhecido como Fitz) para mais. tarefas complexas. Veja como você pode extrair dados de formulário de um PDF usando Python:
Usando PyMuPDF (Fitz)
PyMuPDF é uma ligação Python para MuPDF – um visualizador leve de PDF, XPS e E-book. Ele oferece amplos recursos para trabalhar com PDFs, incluindo extração de texto, imagens e dados de formulários.
Instalação
Primeiro, certifique-se de ter o PyMuPDF instalado:
pip instalar pymupdf
Extraindo dados de formulário
importar fitz # PyMuPDF
def extract_form_data(caminho_pdf):
# Abra o PDF
doc=fitz.open(caminho_pdf)
dados_formulário = {}
para página no documento:
# Extraia anotações (os campos do formulário são um tipo de anotação)
anotações = página.annots()
se anotar:
para anotar em anotações:
info = anotação.info
tipo_campo = info.get(“assunto”)
nome_campo = info.get(“título”)
valor_campo = info.get(“conteúdo”)
se nome_campo e valor_campo:
# Preencha o dicionário com nomes e valores de campos
dados_formulário[nome_campo] = (valor_campo, tipo_campo)
retornar dados_do_formulário
# Substitua 'your_form.pdf' pelo caminho do seu formulário PDF
form_data = extract_form_data(“seu_form.pdf”)
para campo em form_data:
print(f”Campo: {campo}, Valor: {form_data[campo][0]}, Tipo: {form_data[campo][1]}”)
Este script abre um PDF e percorre cada página, verificando anotações (onde os campos do formulário PDF são categorizados). Para cada anotação, extrai o nome, valor e tipo do campo, armazenando-os em um dicionário.
Usando PyPDF2
PyPDF2 é outra biblioteca popular para trabalhar com PDFs em Python. Ele também pode lidar com a extração de dados de formulários, embora possa não ser tão abrangente quanto o PyMuPDF para PDFs complexos.
Instalação
Certifique-se de que o PyPDF2 esteja instalado:
pip instalar pypdf2
Extraindo dados de formulário
importar PyPDF2
def extract_form_data_py2(caminho_pdf):
com open(pdf_path, 'rb') como arquivo:
leitor = PyPDF2.PdfReader(arquivo)
dados_formulário = {}
# Acesse os dados do formulário do leitor
campos = leitor.get_fields()
para campo em campos:
form_data[campo] = campos[campo].get('/V', Nenhum)
retornar dados_do_formulário
# Substitua 'your_form.pdf' pelo caminho do seu formulário PDF
form_data = extract_form_data_py2(“seu_form.pdf”)
para campo em form_data:
print(f”Campo: {campo}, Valor: {form_data[campo]}”)
Esta função utiliza PyPDF2 para abrir um arquivo PDF e acessar diretamente seus campos de formulário. Ele itera pelos campos, extraindo o nome e o valor de cada um e armazenando-os em um dicionário.
Você pode extrair dados de um PDF?
Sim, você pode extrair dados de um PDF, mas a abordagem e as ferramentas necessárias dependem do tipo de PDF e da natureza dos dados que você deseja extrair. Os PDFs podem ser amplamente categorizados em dois tipos: baseados em texto e digitalizados/baseados em imagens. Cada tipo requer técnicas diferentes para extração de dados eficaz.
PDFs baseados em texto
Esses PDFs contêm texto selecionável. Você pode destacar, copiar e colar este texto em outro documento. PDFs baseados em texto geralmente são mais fáceis de trabalhar quando se trata de extração de dados.
Ferramentas e bibliotecas:
- PyPDF2 e PDFMiner em Python são populares para extrair texto desses PDFs. PyPDF2 é simples e útil para extração básica de texto e manipulação de PDF, enquanto PDFMiner oferece controle mais granular sobre layout e formatação, tornando-o adequado para necessidades complexas de extração.
- Apache PDFBox , uma biblioteca Java, também pode extrair texto de PDFs e é usada em aplicativos de nível empresarial.
PDFs digitalizados/baseados em imagens
Esses PDFs são essencialmente imagens de texto. Como o texto faz parte de uma imagem, ele não pode ser selecionado ou copiado diretamente. A extração de dados desses PDFs requer reconhecimento óptico de caracteres (OCR) para converter as imagens de texto em texto real.
Ferramentas e bibliotecas:
- Tesseract OCR é um dos mecanismos de OCR mais poderosos e amplamente utilizados. Ele pode ser usado diretamente ou por meio de wrappers como Pytesseract em Python.
- Adobe Acrobat Pro oferece recursos integrados de OCR e pode converter PDFs digitalizados em documentos de texto selecionáveis e pesquisáveis.
Como extraio dados automaticamente de um PDF?
A extração automática de dados de um PDF envolve o uso de ferramentas de software que podem interpretar o conteúdo do PDF e convertê-lo em um formato estruturado. O processo difere dependendo se o PDF é baseado em texto ou imagem (digitalizado). Veja como abordar a extração automática de dados de ambos os tipos de PDFs:
Para PDFs baseados em texto
1. Usando bibliotecas Python:
- PyPDF2 ou PDFMiner são bibliotecas Python populares para extrair texto de PDFs baseados em texto. PyPDF2 é adequado para tarefas simples de extração de texto, enquanto PDFMiner é mais poderoso para layouts e codificação complexos.
- Exemplo com PyPDF2:
importar PyPDF2
com open('example.pdf', 'rb') como arquivo:
leitor = PyPDF2.PdfReader(arquivo)
texto = ”
para página em reader.pages:
texto += página.extract_text()
imprimir (texto)
- Tabula ou Camelot : Se o seu objetivo é extrair dados de tabelas de PDFs, essas bibliotecas são projetadas especificamente para esse fim, com Camelot proporcionando mais controle sobre o processo de extração.
2. Usando ferramentas de linha de comando:
- pdftotext faz parte do conjunto de ferramentas Xpdf e pode ser usado para converter documentos PDF em texto simples diretamente da linha de comando, tornando-o adequado para processamento em lote.
Para PDFs digitalizados/baseados em imagens
PDFs digitalizados requerem reconhecimento óptico de caracteres (OCR) para converter imagens de texto novamente em texto selecionável e pesquisável.
1. Usando o Tesseract OCR:
- Tesseract é um mecanismo de OCR de código aberto. Pytesseract, um wrapper Python para Tesseract, permite integrar recursos de OCR em seus scripts.
- Exemplo com Pytesseract:
da imagem de importação PIL
importar pytesseract
de pdf2image importar convert_from_path
imagens = convert_from_path('scanned_example.pdf')
texto = ”
para imagem em imagens:
texto += pytesseract.image_to_string(imagem)
imprimir (texto)
2. Usando serviços de OCR:
- Adobe Acrobat Pro oferece recursos integrados de OCR que podem reconhecer automaticamente texto em documentos digitalizados.
- Serviços de OCR online : Várias plataformas online fornecem serviços de OCR que podem processar PDFs em massa. No entanto, esteja atento à privacidade e segurança ao enviar documentos confidenciais.