
Pengantar Ekstraksi Data dari PDF: Alat dan Teknik
Diterbitkan: 2024-03-21Di dunia yang berbasis data saat ini, kemampuan mengekstrak informasi dari dokumen PDF secara efisien merupakan kebutuhan bagi banyak bisnis dan peneliti. PDF adalah salah satu format paling umum untuk mendistribusikan dan berbagi dokumen, namun presentasi terstrukturnya sering kali membuat penggalian data menjadi sulit. Entri blog ini menggali dasar-dasar ekstraksi data dari PDF, mengeksplorasi alat dan teknik yang dapat menyederhanakan proses ini.
Mengapa Mengekstrak Data dari PDF?

Sumber: https://www.docsumo.com/blog/extract-data-from-pdf
Di era digital yang sangat luas, dokumen PDF merupakan bukti perpaduan konsistensi, keandalan, dan aksesibilitas universal. Diperkenalkan oleh Adobe pada tahun 1990an, Portable Document Format (PDF) dengan cepat menjadi standar untuk mendistribusikan dokumen digital yang tetap mempertahankan formatnya terlepas dari perangkat atau perangkat lunak yang digunakan untuk melihatnya. Saat ini, PDF ada di mana-mana, berfungsi sebagai wadah untuk segala hal mulai dari makalah akademis dan kontrak hukum hingga manual teknis dan laporan keuangan. Namun, di balik permukaannya yang statis dan halus, terdapat banyak data yang sering kali terkunci sehingga tidak dapat diakses dengan mudah. Hal ini membawa kita pada pertanyaan krusial: Mengapa mengekstraksi data dari PDF sangat penting?
Inti dari transformasi digital adalah data – data yang memberi informasi, data yang memandu, dan data yang memecahkan masalah. Dalam upaya kami yang tiada henti untuk mencapai efisiensi, pemahaman, dan inovasi, ekstraksi data dari PDF berfungsi sebagai jembatan dari keadaan statis ke keadaan dinamis, dari informasi ke wawasan. Baik itu menganalisis tren pasar dari laporan penelitian, mendigitalkan catatan sejarah untuk tujuan pengarsipan, atau memproses faktur untuk rekonsiliasi keuangan, mengekstrak data dari PDF memungkinkan bisnis dan peneliti mengubah informasi statis menjadi wawasan yang dapat ditindaklanjuti.
Tantangan dalam Ekstraksi Data PDF
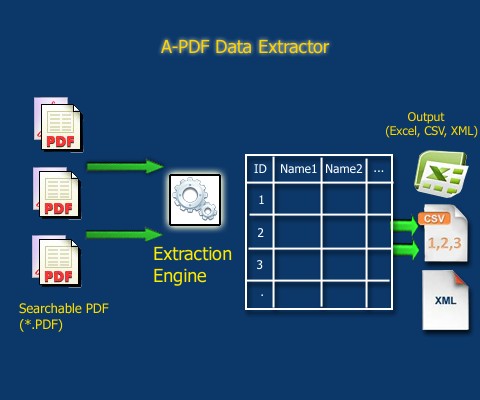
Sumber: https://www.a-pdf.com/data-extractor/index.htm
Ekstrak data dari dokumen PDF menghadirkan serangkaian tantangan unik yang dapat mempersulit proses bagi bisnis, peneliti, dan pengembang. Meskipun PDF digunakan secara luas untuk dokumentasi digital, properti bawaannya dan beragam formatnya menambah kerumitan pada upaya ekstraksi data. Di sini, kami menyelidiki beberapa tantangan utama yang dihadapi dalam ekstraksi data PDF, memberikan wawasan mengapa tugas yang tampak mudah seringkali bisa menjadi upaya yang rumit.
Kompleksitas Struktur PDF yang Inheren
PDF dirancang terutama untuk presentasi, bukan penyimpanan atau manipulasi data. Seringkali mereka tidak memiliki struktur yang konsisten, sehingga membuat ekstraksi otomatis menjadi sulit. Tidak seperti HTML atau XML, di mana tag dan elemen menentukan struktur dan hierarki, PDF memposisikan elemen dalam tata letak tetap. Artinya, memahami struktur logis informasi, seperti membedakan judul, paragraf, dan tabel data, memerlukan interpretasi yang canggih.
Variabilitas dalam Kualitas Dokumen
Kualitas dokumen PDF dapat sangat bervariasi, terutama ketika berhadapan dengan dokumen yang dipindai. Pemindaian dapat menimbulkan noise, distorsi, dan inkonsistensi dalam teks, sehingga membuat proses OCR (Optical Character Recognition) menjadi kurang akurat. Faktor-faktor seperti resolusi pemindaian, kondisi fisik dokumen, dan keberadaan tanda atau anotasi dapat semakin mempersulit ekstraksi data.
Campuran Teks dan Gambar
Banyak PDF berisi campuran teks dan gambar, dan dalam beberapa kasus, informasi penting tertanam di dalam gambar. Hal ini memerlukan penggunaan teknologi OCR untuk mengekstrak teks dari gambar, yang dapat menjadi tantangan, terutama dengan tata letak yang rumit, font yang bervariasi, dan kualitas gambar yang beragam. Selain itu, akurasi OCR dapat berdampak signifikan pada kualitas data yang diekstraksi.
Tata Letak dan Format yang Kompleks
PDF sering kali menampilkan tata letak yang rumit, termasuk tabel, teks multi-kolom, catatan kaki, dan bilah sisi. Elemen-elemen ini dapat mengganggu ekstraksi teks secara langsung, sehingga menyebabkan hilangnya data atau salah tafsir. Mengekstraksi data dari tabel, misalnya, sangat menantang karena hubungan spasial antar elemen (bukan struktur logis atau hierarki) yang menentukan organisasi data.
PDF Terenkripsi atau Aman
Beberapa PDF dienkripsi atau diamankan untuk melindungi hak cipta atau informasi sensitif, membatasi tindakan seperti menyalin, mencetak, atau mengedit. Mengekstraksi data dari PDF ini memerlukan dekripsi, yang memerlukan izin atau kunci dekripsi yang sesuai. Hal ini menambah kompleksitas dan pertimbangan hukum pada proses ekstraksi.
Pengkodean dan Kompresi Beragam
File PDF dapat menggunakan berbagai pengkodean teks dan teknik kompresi gambar, beberapa di antaranya mungkin tidak mudah untuk diinterpretasikan atau didekode. Keragaman ini memerlukan alat penguraian yang fleksibel dan kuat yang mampu menangani berbagai pengkodean dan mendekompresi konten sesuai kebutuhan untuk ekstraksi data.
Alat dan Teknik Ekstraksi Data yang Efektif
Perpustakaan Penguraian PDF
- Perpustakaan Python : Python menawarkan beberapa perpustakaan untuk ekstraksi data PDF, termasuk PyPDF2 dan PDFMiner untuk PDF berbasis teks, dan PyMuPDF untuk dokumen yang lebih kompleks.
- Apache PDFBox : Alat Java yang memungkinkan pembuatan dan manipulasi dokumen PDF, termasuk ekstraksi teks.
Alat OCR
Saat menangani PDF yang dipindai atau dokumen berbasis gambar, alat OCR sangat penting. Tesseract, mesin OCR sumber terbuka, banyak digunakan untuk mengonversi gambar dalam PDF menjadi format teks yang dapat diedit.
Perangkat Lunak Ekstraksi PDF Komersial
Beberapa alat komersial menawarkan fitur-fitur canggih seperti algoritma pembelajaran berbasis AI untuk menangani tugas ekstraksi data yang kompleks dengan akurasi yang lebih tinggi. Contohnya termasuk Adobe Acrobat DC dan ABBYY FineReader.
Praktik Terbaik untuk Ekstraksi Data PDF
- PDF pra-proses : Membersihkan dokumen sebelum ekstraksi (misalnya, menghapus gambar yang tidak perlu atau halaman kosong) dapat meningkatkan akurasi secara signifikan.
- Skrip Khusus untuk Otomatisasi : Untuk tugas ekstraksi skala besar, pertimbangkan untuk menulis skrip khusus yang menggunakan pustaka penguraian PDF. Hal ini memungkinkan adanya otomatisasi dan penyesuaian sesuai dengan kebutuhan spesifik.
- Validasi dan Pemeriksaan Kualitas : Selalu sertakan langkah untuk memvalidasi data yang diekstraksi. Hal ini dapat diotomatisasi sampai batas tertentu tetapi sering kali memerlukan pengawasan manusia.
Aplikasi Dunia Nyata
- Sektor Keuangan : Bank dan lembaga keuangan mengekstrak data dari PDF untuk analisis kredit, penilaian risiko, dan pelaporan kepatuhan.
- Layanan Kesehatan : Catatan pasien, artikel penelitian, dan data uji klinis sering kali disimpan dalam format PDF dan memerlukan ekstraksi untuk analisis dan pelaporan.
- Penelitian Akademis : Peneliti mengekstrak data dari artikel ilmiah dan makalah akademis untuk tinjauan literatur dan meta-analisis.
Kesimpulan
Ekstraksi data dari dokumen PDF, meskipun menantang, sangat penting untuk analisis data, pelaporan, dan pengambilan keputusan di berbagai industri. Dengan memanfaatkan alat dan teknik yang tepat, organisasi dapat mengatasi kesulitan yang melekat pada ekstraksi data PDF dan membuka wawasan berharga yang terkandung dalam dokumen mereka. Seiring kemajuan teknologi, kita dapat mengharapkan peningkatan berkelanjutan pada alat ekstraksi, sehingga prosesnya lebih mudah diakses dan efisien.
Di PromptCloud, kami memahami pentingnya ekstraksi data yang akurat dan efisien. Solusi khusus kami dirancang untuk memenuhi kebutuhan spesifik klien kami, memastikan bahwa mereka dapat memanfaatkan informasi yang terkandung dalam dokumen PDF mereka semaksimal mungkin. Baik Anda ingin mengekstrak data dari beberapa dokumen atau mengotomatiskan proses ekstraksi di ribuan dokumen, kami siap membantu.

Rangkullah kekuatan data dengan PromptCloud. Hubungi kami sekarang juga untuk mengetahui bagaimana kami dapat mengubah proses ekstraksi data PDF Anda. Hubungi [email protected]
Pertanyaan yang Sering Diajukan
Bagaimana cara mengekstrak data tertentu dari PDF?
Mengekstraksi data tertentu dari PDF memerlukan kombinasi alat dan teknik, yang disesuaikan dengan sifat file PDF (berbasis teks atau pindaian/berbasis gambar) dan data spesifik yang ingin Anda ekstrak. Berikut panduan langkah demi langkah untuk membantu Anda mengekstrak data tertentu dari PDF:
Untuk PDF berbasis teks:
- Gunakan Perpustakaan Python seperti PyPDF2 atau PDFMiner:
Pustaka ini dapat membantu Anda mengekstrak teks dari PDF yang berisi lapisan teks yang dapat dipilih.
- PyPDF2 : Berguna untuk ekstraksi teks sederhana dan manipulasi PDF (seperti menggabungkan PDF).
impor PyPDF2
# Buka file PDFnya
dengan open('file_Anda.pdf', 'rb') sebagai file:
pembaca = PyPDF2.PdfReader(file)
# Ekstrak teks dari halaman pertama
halaman = pembaca.halaman[0]
teks = halaman.extract_text()
mencetak (teks)
PDFMiner : Lebih canggih, cocok untuk mengekstrak teks dari tata letak yang rumit.
dari pdfminer.high_level impor ekstrak_teks
teks = ekstrak_teks('file_Anda.pdf')
mencetak (teks)
2. Ekstrak dan Proses Teks:
Setelah Anda mendapatkan teksnya, Anda mungkin perlu memprosesnya untuk menemukan dan mengekstrak data spesifik yang Anda minati. Hal ini dapat melibatkan:
- Mencari kata kunci atau pola menggunakan ekspresi reguler.
- Memisahkan teks menjadi beberapa baris atau paragraf untuk ekstraksi sadar konteks.
Untuk PDF yang Dipindai/Berbasis Gambar:
1. Gunakan Alat OCR (Pengenalan Karakter Optik):
Untuk PDF yang pada dasarnya berupa gambar teks (misalnya dokumen yang dipindai), Anda perlu menggunakan perangkat lunak OCR untuk mengonversi gambar menjadi teks yang dapat dipilih. Tesseract adalah mesin OCR sumber terbuka yang populer.
- Pytesseract : Pembungkus Python untuk Tesseract. Anda juga perlu mengonversi halaman PDF menjadi gambar, yang dapat dilakukan menggunakan pdf2image.
dari pdf2impor gambar convert_from_path
impor pytesseract
# Konversi PDF ke daftar gambar
gambar = convert_from_path('file_scan_Anda.pdf')
# Gunakan pytesseract untuk melakukan OCR pada gambar
untuk saya, gambar di enumerasi (gambar):
teks = pytesseract.image_to_string(gambar)
print(f”Halaman {i+1} Teks:”, teks)
2. Memproses Teks yang Diekstraksi:
Setelah OCR, teks mungkin perlu dibersihkan dan diproses untuk mengekstrak titik data spesifik yang Anda perlukan. Hal ini dapat mencakup penghapusan artefak yang diperkenalkan oleh OCR, penguraian teks untuk struktur, dan penerapan ekspresi reguler untuk menemukan pola.
Bagaimana cara mengekstrak data formulir dari PDF?
Mengekstraksi data formulir dari PDF, terutama jika formulir diisi dan disimpan, melibatkan metode khusus yang dapat mengurai struktur PDF dan mengekstrak data yang tertanam di bidang formulir. Ada beberapa alat dan pustaka dalam berbagai bahasa pemrograman yang dapat menyelesaikan tugas ini, namun Python tetap menjadi salah satu opsi yang paling mudah diakses dan populer karena pustaka seperti PyPDF2 dan PDFMiner untuk PDF berbasis teks, dan PyMuPDF (juga dikenal sebagai Fitz) untuk lebih banyak lagi tugas yang kompleks. Berikut cara mengekstrak data formulir dari PDF menggunakan Python:
Menggunakan PyMuPDF (Fitz)
PyMuPDF adalah pengikatan Python untuk MuPDF – penampil PDF, XPS, dan E-book yang ringan. Ini menawarkan fitur ekstensif untuk bekerja dengan PDF, termasuk mengekstraksi teks, gambar, dan data formulir.
Instalasi
Pertama, pastikan Anda telah menginstal PyMuPDF:
pip instal pymupdf
Mengekstrak Data Formulir
impor fitz # PyMuPDF
def ekstrak_form_data(pdf_path):
# Buka PDFnya
doc = fitz.open(pdf_path)
formulir_data = {}
untuk halaman di dokumen:
# Ekstrak anotasi (bidang formulir adalah jenis anotasi)
annots = halaman.annots()
jika ada catatan:
untuk annot di annots:
info = annot.info
field_type = info.mendapatkan("subjek")
field_name = info.dapatkan("judul")
field_value = info.dapatkan("konten")
jika nama_bidang dan nilai_bidang:
# Isi kamus dengan nama dan nilai bidang
form_data[nama_bidang] = (nilai_bidang, tipe_bidang)
kembalikan form_data
# Ganti 'formulir_Anda.pdf' dengan jalur ke formulir PDF Anda
form_data = ekstrak_form_data(“form_Anda.pdf”)
untuk bidang di form_data:
print(f”Bidang: {field}, Nilai: {form_data[field][0]}, Jenis: {form_data[field][1]}”)
Skrip ini membuka PDF dan mengulangi setiap halaman, memeriksa anotasi (di mana bidang formulir PDF dikategorikan). Untuk setiap anotasi, ia mengekstrak nama bidang, nilai, dan jenis, lalu menyimpannya dalam kamus.
Menggunakan PyPDF2
PyPDF2 adalah perpustakaan populer lainnya untuk bekerja dengan PDF dengan Python. Ini juga dapat menangani ekstraksi data formulir, meskipun mungkin tidak sekomprehensif PyMuPDF untuk PDF yang kompleks.
Instalasi
Pastikan PyPDF2 diinstal:
pip instal pypdf2
Mengekstrak Data Formulir
impor PyPDF2
def ekstrak_form_data_py2(pdf_path):
dengan open(pdf_path, 'rb') sebagai file:
pembaca = PyPDF2.PdfReader(file)
formulir_data = {}
# Akses data formulir dari pembaca
bidang = pembaca.get_fields()
untuk bidang di bidang:
form_data[bidang] = bidang[bidang].get('/V', Tidak ada)
kembalikan form_data
# Ganti 'formulir_Anda.pdf' dengan jalur ke formulir PDF Anda
form_data = ekstrak_form_data_py2(“form_Anda.pdf”)
untuk bidang di form_data:
print(f”Bidang: {bidang}, Nilai: {form_data[bidang]}”)
Fungsi ini memanfaatkan PyPDF2 untuk membuka file PDF dan mengakses kolom formulirnya secara langsung. Itu mengulangi bidang, mengekstraksi nama dan nilai masing-masing, dan menyimpannya dalam kamus.
Bisakah Anda mengikis data dari PDF?
Ya, Anda dapat mengikis data dari PDF, namun pendekatan dan alat yang Anda perlukan bergantung pada jenis PDF dan sifat data yang ingin Anda ekstrak. PDF secara garis besar dapat dikategorikan menjadi dua jenis: berbasis teks dan berbasis pindaian/gambar. Setiap jenis memerlukan teknik berbeda untuk ekstraksi data yang efektif.
PDF berbasis teks
PDF ini berisi teks yang dapat dipilih. Anda dapat menyorot, menyalin, dan menempelkan teks ini ke dokumen lain. PDF berbasis teks umumnya lebih mudah digunakan dalam hal pengikisan data.
Alat dan Perpustakaan:
- PyPDF2 dan PDFMiner dengan Python populer untuk mengekstrak teks dari PDF ini. PyPDF2 sangat mudah dan berguna untuk ekstraksi teks dasar dan manipulasi PDF, sementara PDFMiner menawarkan kontrol yang lebih terperinci atas tata letak dan pemformatan, sehingga cocok untuk kebutuhan ekstraksi yang kompleks.
- Apache PDFBox , perpustakaan Java, juga dapat mengekstrak teks dari PDF dan digunakan dalam aplikasi tingkat perusahaan.
PDF yang dipindai/berbasis gambar
PDF ini pada dasarnya adalah gambar teks. Karena teks adalah bagian dari gambar, teks tidak dapat dipilih atau disalin secara langsung. Mengekstraksi data dari PDF ini memerlukan Pengenalan Karakter Optik (OCR) untuk mengubah gambar teks menjadi teks sebenarnya.
Alat dan Perpustakaan:
- Tesseract OCR adalah salah satu mesin OCR yang paling kuat dan banyak digunakan. Ini dapat digunakan secara langsung atau melalui pembungkus seperti Pytesseract dengan Python.
- Adobe Acrobat Pro menawarkan kemampuan OCR bawaan dan dapat mengubah PDF yang dipindai menjadi dokumen teks yang dapat dipilih dan dicari.
Bagaimana cara mengekstrak data dari PDF secara otomatis?
Mengekstraksi data secara otomatis dari PDF melibatkan penggunaan alat perangkat lunak yang dapat menafsirkan konten PDF dan mengubahnya menjadi format terstruktur. Prosesnya berbeda-beda tergantung pada apakah PDF tersebut berbasis teks atau berbasis gambar (dipindai). Berikut cara mendekati ekstraksi data otomatis dari kedua jenis PDF:
Untuk PDF berbasis teks
1. Menggunakan Perpustakaan Python:
- PyPDF2 atau PDFMiner adalah pustaka Python populer untuk mengekstraksi teks dari PDF berbasis teks. PyPDF2 cocok untuk tugas ekstraksi teks sederhana, sedangkan PDFMiner lebih kuat untuk tata letak dan pengkodean yang kompleks.
- Contoh dengan PyPDF2:
impor PyPDF2
dengan open('example.pdf', 'rb') sebagai file:
pembaca = PyPDF2.PdfReader(file)
teks = ”
untuk halaman di reader.pages:
teks += halaman.extract_text()
mencetak (teks)
- Tabula atau Camelot : Jika tujuan Anda adalah mengekstrak data tabel dari PDF, perpustakaan ini dirancang khusus untuk tujuan ini, dengan Camelot memberikan kontrol lebih besar atas proses ekstraksi.
2. Menggunakan Alat Baris Perintah:
- pdftotext adalah bagian dari perangkat Xpdf dan dapat digunakan untuk mengubah dokumen PDF menjadi teks biasa langsung dari baris perintah, sehingga cocok untuk pemrosesan batch.
Untuk PDF yang Dipindai/Berbasis Gambar
PDF yang dipindai memerlukan Pengenalan Karakter Optik (OCR) untuk mengubah gambar teks kembali menjadi teks yang dapat dipilih dan dicari.
1. Menggunakan Tesseract OCR:
- Tesseract adalah mesin OCR sumber terbuka. Pytesseract, pembungkus Python untuk Tesseract, memungkinkan Anda mengintegrasikan kemampuan OCR ke dalam skrip Anda.
- Contoh dengan Pytesseract:
dari PIL mengimpor Gambar
impor pytesseract
dari pdf2impor gambar convert_from_path
gambar = convert_from_path('scanned_example.pdf')
teks = ”
untuk gambar dalam gambar:
teks += pytesseract.image_to_string(gambar)
mencetak (teks)
2. Menggunakan Layanan OCR:
- Adobe Acrobat Pro menawarkan kemampuan OCR bawaan yang dapat secara otomatis mengenali teks dalam dokumen yang dipindai.
- Layanan OCR online : Berbagai platform online menyediakan layanan OCR yang dapat memproses PDF secara massal. Namun, perhatikan privasi dan keamanan saat mengunggah dokumen sensitif.