
Einführung in die Datenextraktion aus PDFs: Tools und Techniken
Veröffentlicht: 2024-03-21In der heutigen datengesteuerten Welt ist die Fähigkeit, Informationen effizient aus PDF-Dokumenten zu extrahieren, für viele Unternehmen und Forscher eine Notwendigkeit. PDFs sind eines der gebräuchlichsten Formate zum Verteilen und Teilen von Dokumenten, ihre strukturierte Darstellung macht das Extrahieren von Daten jedoch oft zu einer Herausforderung. Dieser Blogbeitrag befasst sich mit den Grundlagen der Datenextraktion aus PDFs und untersucht sowohl die Tools als auch die Techniken, die diesen Prozess optimieren können.
Warum Daten aus PDFs extrahieren?

Quelle: https://www.docsumo.com/blog/extract-data-from-pdf
In der Weite des digitalen Zeitalters sind PDF-Dokumente ein Beweis für die Mischung aus Konsistenz, Zuverlässigkeit und universeller Zugänglichkeit. Das in den 1990er Jahren von Adobe eingeführte Portable Document Format (PDF) entwickelte sich schnell zum Standard für die Verbreitung digitaler Dokumente, die ihre Formatierung unabhängig vom Gerät oder der Software, mit der sie angezeigt werden, beibehalten. Heutzutage sind PDFs allgegenwärtig und dienen als Träger für alles, von wissenschaftlichen Arbeiten und juristischen Verträgen bis hin zu technischen Handbüchern und Finanzberichten. Doch unter ihrer statischen und polierten Oberfläche verbirgt sich eine Fülle von Daten, die oft vor dem einfachen Zugriff geschützt sind. Dies bringt uns zu der entscheidenden Frage: Warum ist das Extrahieren von Daten aus PDFs so wichtig?
Im Mittelpunkt der digitalen Transformation stehen Daten – Daten, die informieren, Daten, die Orientierung geben, und Daten, die Lösungen bieten. In unserem unermüdlichen Streben nach Effizienz, Verständnis und Innovation dient die Extraktion von Daten aus PDFs als Brücke vom Statischen zum Dynamischen, von Informationen zu Erkenntnissen. Ganz gleich, ob es darum geht, Markttrends aus Forschungsberichten zu analysieren, historische Aufzeichnungen zu Archivierungszwecken zu digitalisieren oder Rechnungen für den Finanzabgleich zu verarbeiten: Durch das Extrahieren von Daten aus PDFs können Unternehmen und Forscher statische Informationen in umsetzbare Erkenntnisse umwandeln.
Herausforderungen bei der PDF-Datenextraktion
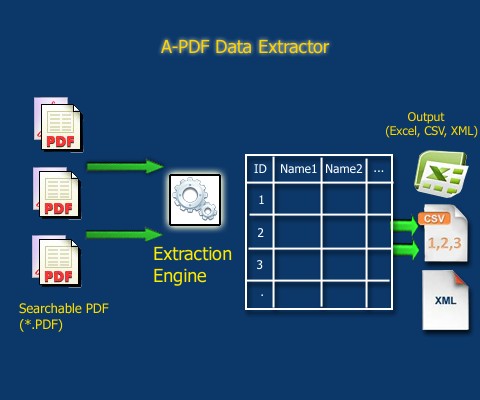
Quelle: https://www.a-pdf.com/data-extractor/index.htm
Das Extrahieren von Daten aus PDF-Dokumenten stellt eine Reihe einzigartiger Herausforderungen dar, die den Prozess für Unternehmen, Forscher und Entwickler gleichermaßen erschweren können. Trotz der weit verbreiteten Verwendung von PDFs für die digitale Dokumentation erhöhen ihre inhärenten Eigenschaften und unterschiedlichen Formate die Datenextraktionsbemühungen um ein Vielfaches. Hier befassen wir uns mit einigen der wichtigsten Herausforderungen bei der PDF-Datenextraktion und geben Einblicke, warum eine scheinbar unkomplizierte Aufgabe oft zu einem komplexen Unterfangen werden kann.
Inhärente Komplexität der PDF-Struktur
PDFs dienen in erster Linie der Präsentation und nicht der Datenspeicherung oder -manipulation. Ihnen fehlt oft eine konsistente Struktur, was eine automatisierte Extraktion erschweren kann. Im Gegensatz zu HTML oder XML, wo Tags und Elemente Struktur und Hierarchie definieren, positionieren PDFs Elemente in festen Layouts. Das bedeutet, dass das Verständnis der logischen Struktur von Informationen, beispielsweise die Unterscheidung zwischen Titeln, Absätzen und Datentabellen, eine ausgefeilte Interpretation erfordert.
Variabilität in der Dokumentenqualität
Die Qualität von PDF-Dokumenten kann erheblich variieren, insbesondere wenn es sich um gescannte Dokumente handelt. Scans können zu Rauschen, Verzerrungen und Inkonsistenzen im Text führen, wodurch OCR-Prozesse (Optical Character Recognition) weniger genau werden. Faktoren wie die Auflösung des Scans, der Zustand des physischen Dokuments und das Vorhandensein von Markierungen oder Anmerkungen können die Datenextraktion zusätzlich erschweren.
Text- und Bildmischung
Viele PDFs enthalten eine Mischung aus Text und Bildern, und in einigen Fällen sind wichtige Informationen in Bilder eingebettet. Dies erfordert den Einsatz von OCR-Technologie zum Extrahieren von Text aus Bildern, was insbesondere bei komplexen Layouts, unterschiedlichen Schriftarten und unterschiedlicher Qualität der Bilder eine Herausforderung darstellen kann. Darüber hinaus kann die OCR-Genauigkeit die Qualität der extrahierten Daten erheblich beeinflussen.
Komplexe Layouts und Formate
PDFs weisen häufig komplexe Layouts auf, darunter Tabellen, mehrspaltigen Text, Fußnoten und Seitenleisten. Diese Elemente können die einfache Textextraktion stören und zu Datenverlust oder Fehlinterpretationen führen. Das Extrahieren von Daten aus Tabellen stellt beispielsweise eine besondere Herausforderung dar, da die räumliche Beziehung zwischen Elementen (und nicht eine logische oder hierarchische Struktur) die Datenorganisation definiert.
Verschlüsselte oder gesicherte PDFs
Einige PDFs sind verschlüsselt oder gesichert, um das Urheberrecht oder vertrauliche Informationen zu schützen, wodurch Aktionen wie Kopieren, Drucken oder Bearbeiten eingeschränkt werden. Das Extrahieren von Daten aus diesen PDFs erfordert eine Entschlüsselung, für die eine Genehmigung oder der entsprechende Entschlüsselungsschlüssel erforderlich ist. Dies fügt dem Extraktionsprozess eine zusätzliche Ebene an Komplexität und rechtlichen Überlegungen hinzu.
Vielfältige Kodierung und Komprimierung
PDF-Dateien können verschiedene Textkodierungen und Bildkomprimierungstechniken verwenden, von denen einige möglicherweise nicht einfach zu interpretieren oder zu dekodieren sind. Diese Vielfalt erfordert flexible und robuste Parsing-Tools, die in der Lage sind, unterschiedliche Kodierungen zu verarbeiten und Inhalte nach Bedarf für die Datenextraktion zu dekomprimieren.
Tools und Techniken für eine effektive Datenextraktion
PDF-Parsing-Bibliotheken
- Python-Bibliotheken : Python bietet mehrere Bibliotheken für die PDF-Datenextraktion, darunter PyPDF2 und PDFMiner für textbasierte PDFs und PyMuPDF für komplexere Dokumente.
- Apache PDFBox : Ein Java-Tool, das die Erstellung und Bearbeitung von PDF-Dokumenten, einschließlich Textextraktion, ermöglicht.
OCR-Tools
Beim Umgang mit gescannten PDFs oder bildbasierten Dokumenten sind OCR-Tools unerlässlich. Tesseract, eine Open-Source-OCR-Engine, wird häufig zum Konvertieren von Bildern in PDFs in bearbeitbare Textformate verwendet.
Kommerzielle PDF-Extraktionssoftware
Mehrere kommerzielle Tools bieten erweiterte Funktionen wie KI-basierte Lernalgorithmen, um komplexe Datenextraktionsaufgaben mit höherer Genauigkeit zu bewältigen. Beispiele hierfür sind Adobe Acrobat DC und ABBYY FineReader.
Best Practices für die PDF-Datenextraktion
- Vorverarbeiten von PDFs : Das Bereinigen von Dokumenten vor dem Extrahieren (z. B. Entfernen unnötiger Bilder oder leerer Seiten) kann die Genauigkeit erheblich verbessern.
- Benutzerdefinierte Skripte für die Automatisierung : Erwägen Sie für umfangreiche Extraktionsaufgaben das Schreiben benutzerdefinierter Skripte, die PDF-Parsing-Bibliotheken verwenden. Dies ermöglicht eine Automatisierung und Anpassung an spezifische Anforderungen.
- Validierung und Qualitätsprüfungen : Integrieren Sie immer einen Schritt zur Validierung der extrahierten Daten. Dies kann bis zu einem gewissen Grad automatisiert werden, erfordert jedoch häufig die Aufsicht eines Menschen.
Anwendungen aus der Praxis
- Finanzsektor : Banken und Finanzinstitute extrahieren Daten aus PDFs für Kreditanalysen, Risikobewertungen und Compliance-Berichte.
- Gesundheitswesen : Patientenakten, Forschungsartikel und Daten klinischer Studien werden häufig im PDF-Format gespeichert und müssen zur Analyse und Berichterstattung extrahiert werden.
- Akademische Forschung : Forscher extrahieren Daten aus wissenschaftlichen Artikeln und wissenschaftlichen Arbeiten für Literaturrecherchen und Metaanalysen.
Abschluss
Die Extraktion von Daten aus PDF-Dokumenten ist zwar eine Herausforderung, aber für die Datenanalyse, Berichterstattung und Entscheidungsfindung in verschiedenen Branchen von entscheidender Bedeutung. Durch den Einsatz der richtigen Tools und Techniken können Unternehmen die inhärenten Schwierigkeiten der PDF-Datenextraktion überwinden und wertvolle Erkenntnisse aus ihren Dokumenten gewinnen. Mit fortschreitender Technologie können wir mit weiteren Verbesserungen der Extraktionswerkzeuge rechnen, die den Prozess zugänglicher und effizienter machen.

Bei PromptCloud wissen wir, wie wichtig eine genaue und effiziente Datenextraktion ist. Unsere maßgeschneiderten Lösungen sind auf die spezifischen Bedürfnisse unserer Kunden zugeschnitten und stellen sicher, dass sie die in ihren PDF-Dokumenten enthaltenen Informationen optimal nutzen können. Ganz gleich, ob Sie Daten aus einer Handvoll Dokumente extrahieren oder den Extraktionsprozess aus Tausenden automatisieren möchten, wir sind hier, um Ihnen zu helfen.
Nutzen Sie die Macht der Daten mit PromptCloud. Kontaktieren Sie uns noch heute und erfahren Sie, wie wir Ihren PDF-Datenextraktionsprozess transformieren können. Kontaktieren Sie uns unter [email protected]
Häufig gestellte Fragen
Wie extrahiere ich bestimmte Daten aus einem PDF?
Das Extrahieren bestimmter Daten aus einer PDF-Datei erfordert eine Kombination von Werkzeugen und Techniken, die auf die Art der PDF-Datei (textbasiert oder gescannt/bildbasiert) und die spezifischen Daten, die Sie extrahieren möchten, zugeschnitten sind. Hier ist eine Schritt-für-Schritt-Anleitung, die Ihnen hilft, bestimmte Daten aus PDFs zu extrahieren:
Für textbasierte PDFs:
- Verwenden Sie Python-Bibliotheken wie PyPDF2 oder PDFMiner:
Mit diesen Bibliotheken können Sie Text aus PDFs extrahieren, die auswählbare Textebenen enthalten.
- PyPDF2 : Nützlich für die einfache Textextraktion und PDF-Bearbeitung (wie das Zusammenführen von PDFs).
PyPDF2 importieren
# Öffnen Sie die PDF-Datei
mit open('your_file.pdf', 'rb') als Datei:
Reader = PyPDF2.PdfReader(Datei)
# Text von der ersten Seite extrahieren
page = reader.pages[0]
text = page.extract_text()
drucken(Text)
PDFMiner : Anspruchsvoller, geeignet zum Extrahieren von Text aus komplexen Layouts.
aus pdfminer.high_level import extract_text
text = extract_text('your_file.pdf')
drucken(Text)
2. Extrahieren und verarbeiten Sie den Text:
Sobald Sie den Text haben, müssen Sie ihn möglicherweise verarbeiten, um die spezifischen Daten zu finden und zu extrahieren, an denen Sie interessiert sind. Dies kann Folgendes umfassen:
- Suche nach Schlüsselwörtern oder Mustern mithilfe regulärer Ausdrücke.
- Teilen Sie den Text zur kontextbezogenen Extraktion in Zeilen oder Absätze auf.
Für gescannte/bildbasierte PDFs:
1. Verwenden Sie OCR-Tools (Optical Character Recognition):
Bei PDFs, die im Wesentlichen aus Textbildern bestehen (z. B. gescannte Dokumente), müssen Sie eine OCR-Software verwenden, um die Bilder in auswählbaren Text umzuwandeln. Tesseract ist eine beliebte Open-Source-OCR-Engine.
- Pytesseract : Ein Python-Wrapper für Tesseract. Sie müssen außerdem PDF-Seiten in Bilder konvertieren, was mit pdf2image möglich ist.
aus pdf2image import_convert_from_path
Pytesseract importieren
# Konvertieren Sie PDF in eine Liste von Bildern
images = convert_from_path('your_scanned_file.pdf')
# Verwenden Sie Pytesseract, um OCR für das Bild durchzuführen
für i, Bild in enumerate(images):
text = pytesseract.image_to_string(image)
print(f“Seite {i+1} Text:“, Text)
2. Verarbeiten Sie den extrahierten Text:
Nach der OCR muss der Text wahrscheinlich bereinigt und verarbeitet werden, um die spezifischen Datenpunkte zu extrahieren, die Sie benötigen. Dies kann das Entfernen von durch OCR eingeführten Artefakten, das Analysieren des Texts auf Struktur und die Anwendung regulärer Ausdrücke zum Finden von Mustern umfassen.
Wie extrahiere ich Formulardaten aus einem PDF?
Das Extrahieren von Formulardaten aus einer PDF-Datei, insbesondere wenn das Formular ausgefüllt und gespeichert wird, erfordert spezielle Methoden, mit denen die PDF-Struktur analysiert und die in Formularfelder eingebetteten Daten extrahiert werden können. Es gibt mehrere Tools und Bibliotheken in verschiedenen Programmiersprachen, die diese Aufgabe erfüllen können, aber Python bleibt aufgrund von Bibliotheken wie PyPDF2 und PDFMiner für textbasierte PDFs und PyMuPDF (auch bekannt als Fitz) für mehr eine der zugänglichsten und beliebtesten Optionen komplexe Aufgaben. So können Sie mit Python Formulardaten aus einer PDF-Datei extrahieren:
Verwendung von PyMuPDF (Fitz)
PyMuPDF ist eine Python-Bindung für MuPDF – einen leichten PDF-, XPS- und E-Book-Viewer. Es bietet umfangreiche Funktionen für die Arbeit mit PDFs, einschließlich der Extraktion von Text, Bildern und Formulardaten.
Installation
Stellen Sie zunächst sicher, dass PyMuPDF installiert ist:
pip installiere pymupdf
Formulardaten extrahieren
fitz # PyMuPDF importieren
def extract_form_data(pdf_path):
# Öffnen Sie das PDF
doc = fitz.open(pdf_path)
form_data = {}
für Seite im Dokument:
# Anmerkungen extrahieren (Formularfelder sind eine Art Anmerkung)
annots = page.annots()
wenn Anmerkungen:
für annot in annots:
info = annot.info
field_type = info.get(“subject”)
field_name = info.get(“title”)
field_value = info.get(“content”)
wenn field_name und field_value:
# Füllen Sie das Wörterbuch mit Feldnamen und Werten
form_data[field_name] = (field_value, field_type)
form_data zurückgeben
# Ersetzen Sie „Ihr_Formular.pdf“ durch den Pfad zu Ihrem PDF-Formular
form_data = extract_form_data(“your_form.pdf”)
für Feld in form_data:
print(f“Feld: {field}, Wert: {form_data[field][0]}, Typ: {form_data[field][1]}“)
Dieses Skript öffnet eine PDF-Datei, durchläuft jede Seite und sucht nach Anmerkungen (wo PDF-Formularfelder kategorisiert sind). Für jede Anmerkung werden der Feldname, der Wert und der Typ extrahiert und in einem Wörterbuch gespeichert.
Verwendung von PyPDF2
PyPDF2 ist eine weitere beliebte Bibliothek für die Arbeit mit PDFs in Python. Es kann auch Formulardaten extrahieren, obwohl es für komplexe PDFs möglicherweise nicht so umfassend ist wie PyMuPDF.
Installation
Stellen Sie sicher, dass PyPDF2 installiert ist:
pip installiere pypdf2
Formulardaten extrahieren
PyPDF2 importieren
def extract_form_data_py2(pdf_path):
mit open(pdf_path, 'rb') als Datei:
Reader = PyPDF2.PdfReader(Datei)
form_data = {}
# Greifen Sie über den Reader auf die Formulardaten zu
Felder = Reader.get_fields()
für Feld in Feldern:
form_data[field] = Felder[field].get('/V', None)
form_data zurückgeben
# Ersetzen Sie „Ihr_Formular.pdf“ durch den Pfad zu Ihrem PDF-Formular
form_data = extract_form_data_py2(“your_form.pdf”)
für Feld in form_data:
print(f“Feld: {field}, Wert: {form_data[field]}“)
Diese Funktion nutzt PyPDF2, um eine PDF-Datei zu öffnen und direkt auf deren Formularfelder zuzugreifen. Es durchläuft die Felder, extrahiert deren Namen und Werte und speichert sie in einem Wörterbuch.
Können Sie Daten aus einem PDF extrahieren?
Ja, Sie können Daten aus einer PDF-Datei extrahieren, aber der Ansatz und die Tools, die Sie benötigen, hängen von der Art der PDF-Datei und der Art der Daten ab, die Sie extrahieren möchten. PDFs können grob in zwei Typen eingeteilt werden: textbasiert und gescannt/bildbasiert. Jeder Typ erfordert unterschiedliche Techniken für eine effektive Datenextraktion.
Textbasierte PDFs
Diese PDFs enthalten auswählbaren Text. Sie können diesen Text markieren, kopieren und in ein anderes Dokument einfügen. Beim Daten-Scraping ist es im Allgemeinen einfacher, mit textbasierten PDFs zu arbeiten.
Tools und Bibliotheken:
- PyPDF2 und PDFMiner in Python sind beliebt zum Extrahieren von Text aus diesen PDFs. PyPDF2 ist unkompliziert und nützlich für die einfache Textextraktion und PDF-Bearbeitung, während PDFMiner eine detailliertere Kontrolle über Layout und Formatierung bietet und sich daher für komplexe Extraktionsanforderungen eignet.
- Apache PDFBox , eine Java-Bibliothek, kann auch Text aus PDFs extrahieren und wird in Anwendungen auf Unternehmensebene verwendet.
Gescannte/bildbasierte PDFs
Bei diesen PDFs handelt es sich im Wesentlichen um Textbilder. Da der Text Teil eines Bildes ist, kann er nicht direkt ausgewählt oder kopiert werden. Das Extrahieren von Daten aus diesen PDFs erfordert die optische Zeichenerkennung (OCR), um die Textbilder in tatsächlichen Text umzuwandeln.
Tools und Bibliotheken:
- Tesseract OCR ist eine der leistungsstärksten und am weitesten verbreiteten OCR-Engines. Es kann direkt oder über Wrapper wie Pytesseract in Python verwendet werden.
- Adobe Acrobat Pro bietet integrierte OCR-Funktionen und kann gescannte PDFs in auswählbare und durchsuchbare Textdokumente konvertieren.
Wie extrahiere ich automatisch Daten aus einem PDF?
Das automatische Extrahieren von Daten aus einer PDF-Datei erfordert den Einsatz von Softwaretools, die den Inhalt der PDF-Datei interpretieren und in ein strukturiertes Format konvertieren können. Der Vorgang unterscheidet sich je nachdem, ob das PDF textbasiert oder bildbasiert (gescannt) ist. So gehen Sie bei der automatischen Datenextraktion aus beiden PDF-Typen vor:
Für textbasierte PDFs
1. Verwendung von Python-Bibliotheken:
- PyPDF2 oder PDFMiner sind beliebte Python-Bibliotheken zum Extrahieren von Text aus textbasierten PDFs. PyPDF2 eignet sich für einfache Textextraktionsaufgaben, während PDFMiner für komplexe Layouts und Kodierungen leistungsfähiger ist.
- Beispiel mit PyPDF2:
PyPDF2 importieren
mit open('example.pdf', 'rb') als Datei:
Reader = PyPDF2.PdfReader(Datei)
text = ”
für die Seite in „reader.pages“:
text += page.extract_text()
drucken(Text)
- Tabula oder Camelot : Wenn Sie Tabellendaten aus PDFs extrahieren möchten, sind diese Bibliotheken speziell für diesen Zweck konzipiert, wobei Camelot mehr Kontrolle über den Extraktionsprozess bietet.
2. Verwenden von Befehlszeilentools:
- pdftotext ist Teil des Xpdf-Toolsets und kann verwendet werden, um PDF-Dokumente direkt von der Befehlszeile aus in einfachen Text umzuwandeln, wodurch es für die Stapelverarbeitung geeignet ist.
Für gescannte/bildbasierte PDFs
Gescannte PDFs erfordern eine optische Zeichenerkennung (OCR), um Textbilder wieder in auswählbaren und durchsuchbaren Text umzuwandeln.
1. Verwendung von Tesseract OCR:
- Tesseract ist eine Open-Source-OCR-Engine. Pytesseract, ein Python-Wrapper für Tesseract, ermöglicht Ihnen die Integration von OCR-Funktionen in Ihre Skripte.
- Beispiel mit Pytesseract:
aus PIL-Importbild
Pytesseract importieren
aus pdf2image import_convert_from_path
Bilder = Convert_from_path('scanned_example.pdf')
text = ”
zum Bild in Bildern:
text += pytesseract.image_to_string(image)
drucken(Text)
2. Nutzung von OCR-Diensten:
- Adobe Acrobat Pro bietet integrierte OCR-Funktionen, die Text in gescannten Dokumenten automatisch erkennen können.
- Online-OCR-Dienste : Verschiedene Online-Plattformen bieten OCR-Dienste an, die PDFs in großen Mengen verarbeiten können. Achten Sie jedoch beim Hochladen vertraulicher Dokumente auf Datenschutz und Sicherheit.