
Introduzione all'estrazione dei dati dai PDF: strumenti e tecniche
Pubblicato: 2024-03-21Nel mondo odierno basato sui dati, la capacità di estrarre in modo efficiente informazioni dai documenti PDF è una necessità per molte aziende e ricercatori. I PDF sono uno dei formati più comuni per la distribuzione e la condivisione di documenti, ma la loro presentazione strutturata spesso rende difficile l'estrazione dei dati. Questo post del blog approfondisce i fondamenti dell'estrazione dei dati dai PDF, esplorando sia gli strumenti che le tecniche che possono semplificare questo processo.
Perché estrarre dati dai PDF?

Fonte: https://www.docsumo.com/blog/extract-data-from-pdf
Nella vasta distesa dell'era digitale, i documenti PDF rappresentano una testimonianza della combinazione di coerenza, affidabilità e accessibilità universale. Introdotto da Adobe negli anni '90, il Portable Document Format (PDF) è diventato rapidamente lo standard per la distribuzione di documenti digitali che mantengono la loro formattazione indipendentemente dal dispositivo o dal software utilizzato per visualizzarli. Oggi, i PDF sono onnipresenti e fungono da contenitore per qualsiasi cosa, dai documenti accademici ai contratti legali, dai manuali tecnici ai rapporti finanziari. Tuttavia, sotto la loro superficie statica e lucida si nasconde una grande quantità di dati, spesso bloccati e impediti da un facile accesso. Questo ci porta alla domanda cruciale: perché l’estrazione dei dati dai PDF è così vitale?
Al centro della trasformazione digitale ci sono i dati: dati che informano, dati che guidano e dati che risolvono. Nella nostra incessante ricerca di efficienza, comprensione e innovazione, l'estrazione dei dati dai PDF funge da ponte dallo statico al dinamico, dalle informazioni all'intuizione. Che si tratti di analizzare le tendenze del mercato da rapporti di ricerca, di digitalizzare documenti storici a fini di archiviazione o di elaborare fatture per la riconciliazione finanziaria, l'estrazione di dati dai PDF consente ad aziende e ricercatori di convertire informazioni statiche in informazioni fruibili.
Sfide nell'estrazione dei dati dai PDF
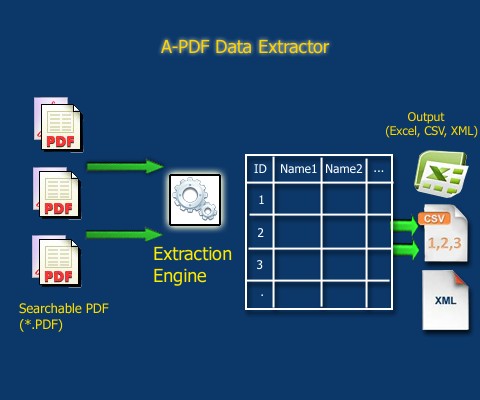
Fonte: https://www.a-pdf.com/data-extractor/index.htm
L'estrazione dei dati dai documenti PDF presenta una serie unica di sfide che possono complicare il processo per aziende, ricercatori e sviluppatori. Nonostante l’uso diffuso dei PDF per la documentazione digitale, le loro proprietà intrinseche e i diversi formati aggiungono livelli di complessità agli sforzi di estrazione dei dati. Qui, approfondiamo alcune delle principali sfide incontrate nell'estrazione dei dati PDF, offrendo approfondimenti sul perché quello che sembra un compito semplice può spesso diventare un'impresa complessa.
Complessità intrinseca della struttura PDF
I PDF sono progettati principalmente per la presentazione, non per l'archiviazione o la manipolazione dei dati. Spesso mancano di una struttura coerente, il che può rendere difficile l’estrazione automatizzata. A differenza di HTML o XML, dove tag ed elementi definiscono struttura e gerarchia, i PDF posizionano gli elementi in layout fissi. Ciò significa che comprendere la struttura logica delle informazioni, come distinguere tra titoli, paragrafi e tabelle di dati, richiede un'interpretazione sofisticata.
Variabilità nella qualità dei documenti
I documenti PDF possono variare in modo significativo in termini di qualità, soprattutto quando si tratta di documenti scansionati. Le scansioni possono introdurre rumore, distorsioni e incoerenze nel testo, rendendo i processi OCR (riconoscimento ottico dei caratteri) meno accurati. Fattori come la risoluzione della scansione, le condizioni del documento fisico e la presenza di segni o annotazioni possono complicare ulteriormente l'estrazione dei dati.
Miscela di testo e immagini
Molti PDF contengono una combinazione di testo e immagini e, in alcuni casi, informazioni cruciali sono incorporate nelle immagini. Ciò richiede l'uso della tecnologia OCR per estrarre il testo dalle immagini, il che può essere impegnativo, soprattutto con layout complessi, caratteri diversi e qualità mista delle immagini. Inoltre, la precisione dell’OCR può avere un impatto significativo sulla qualità dei dati estratti.
Layout e formati complessi
I PDF spesso presentano layout complessi, tra cui tabelle, testo su più colonne, note a piè di pagina e barre laterali. Questi elementi possono interrompere l'estrazione semplice del testo, portando alla perdita di dati o a interpretazioni errate. L'estrazione dei dati dalle tabelle, ad esempio, è particolarmente impegnativa perché la relazione spaziale tra gli elementi (piuttosto che una struttura logica o gerarchica) definisce l'organizzazione dei dati.
PDF crittografati o protetti
Alcuni PDF sono crittografati o protetti per proteggere il copyright o le informazioni sensibili, limitando azioni come la copia, la stampa o la modifica. L'estrazione dei dati da questi PDF richiede la decrittografia, per la quale è necessaria l'autorizzazione o la chiave di decrittografia appropriata. Ciò aggiunge un ulteriore livello di complessità e considerazioni legali al processo di estrazione.
Codifica e compressione diverse
I file PDF possono utilizzare una varietà di codifiche di testo e tecniche di compressione delle immagini, alcune delle quali potrebbero non essere semplici da interpretare o decodificare. Questa diversità richiede strumenti di analisi flessibili e robusti in grado di gestire diverse codifiche e decomprimere i contenuti secondo necessità per l'estrazione dei dati.
Strumenti e tecniche per un'estrazione efficace dei dati
Librerie di analisi PDF
- Librerie Python : Python offre diverse librerie per l'estrazione dei dati PDF, tra cui PyPDF2 e PDFMiner per PDF basati su testo e PyMuPDF per documenti più complessi.
- Apache PDFBox : uno strumento Java che consente la creazione e la manipolazione di documenti PDF, inclusa l'estrazione del testo.
Strumenti dell'OCR
Quando si ha a che fare con PDF scansionati o documenti basati su immagini, gli strumenti OCR sono essenziali. Tesseract, un motore OCR open source, è ampiamente utilizzato per convertire le immagini nei PDF in formati di testo modificabili.
Software commerciale di estrazione PDF
Diversi strumenti commerciali offrono funzionalità avanzate come algoritmi di apprendimento basati sull’intelligenza artificiale per gestire attività complesse di estrazione dei dati con maggiore precisione. Gli esempi includono Adobe Acrobat DC e ABBYY FineReader.
Migliori pratiche per l'estrazione dei dati PDF
- Pre-elaborazione dei PDF : la pulizia dei documenti prima dell'estrazione (ad esempio, la rimozione di immagini non necessarie o pagine vuote) può migliorare significativamente la precisione.
- Script personalizzati per l'automazione : per attività di estrazione su larga scala, valuta la possibilità di scrivere script personalizzati che utilizzino le librerie di analisi PDF. Ciò consente l'automazione e la personalizzazione in base alle esigenze specifiche.
- Convalida e controlli di qualità : incorporare sempre un passaggio per convalidare i dati estratti. Questo può essere automatizzato in una certa misura, ma spesso richiede la supervisione umana.
Applicazioni del mondo reale
- Settore finanziario : le banche e gli istituti finanziari estraggono dati dai PDF per l'analisi del credito, la valutazione del rischio e il reporting di conformità.
- Sanità : le cartelle cliniche dei pazienti, gli articoli di ricerca e i dati degli studi clinici sono spesso archiviati in formato PDF e richiedono l'estrazione per l'analisi e la reportistica.
- Ricerca accademica : i ricercatori estraggono dati da articoli accademici e documenti accademici per revisioni della letteratura e meta-analisi.
Conclusione
L'estrazione dei dati dai documenti PDF, sebbene impegnativa, è essenziale per l'analisi dei dati, il reporting e il processo decisionale in vari settori. Sfruttando gli strumenti e le tecniche giusti, le organizzazioni possono superare le difficoltà intrinseche dell'estrazione dei dati PDF e sbloccare preziose informazioni contenute nei propri documenti. Con l’avanzare della tecnologia, possiamo aspettarci continui miglioramenti negli strumenti di estrazione, rendendo il processo più accessibile ed efficiente.

Noi di PromptCloud comprendiamo l'importanza di un'estrazione dei dati accurata ed efficiente. Le nostre soluzioni personalizzate sono progettate per soddisfare le esigenze specifiche dei nostri clienti, garantendo che possano sfruttare al meglio le informazioni contenute nei loro documenti PDF. Che tu stia cercando di estrarre dati da una manciata di documenti o di automatizzare il processo di estrazione di migliaia di documenti, siamo qui per aiutarti.
Sfrutta la potenza dei dati con PromptCloud. Contattaci oggi stesso per scoprire come possiamo trasformare il tuo processo di estrazione dei dati dai PDF. Mettiti in contatto con [email protected]
Domande frequenti
Come posso estrarre dati specifici da un PDF?
L'estrazione di dati specifici da un PDF richiede una combinazione di strumenti e tecniche, adattati alla natura del file PDF (basato su testo o scansionato/basato su immagini) e ai dati specifici che stai cercando di estrarre. Ecco una guida passo passo per aiutarti a estrarre dati specifici dai PDF:
Per PDF basati su testo:
- Utilizza librerie Python come PyPDF2 o PDFMiner:
Queste librerie possono aiutarti a estrarre testo da PDF che contengono livelli di testo selezionabili.
- PyPDF2 : utile per l'estrazione semplice del testo e la manipolazione dei PDF (come l'unione di PDF).
importa PyPDF2
#Apri il file PDF
con open('tuo_file.pdf', 'rb') come file:
lettore = PyPDF2.PdfReader(file)
# Estrai il testo dalla prima pagina
pagina = lettore.pagine[0]
testo = pagina.extract_text()
stampa(testo)
PDFMiner : più sofisticato, adatto per estrarre testo da layout complessi.
da pdfminer.high_level import extract_text
testo = extract_text('tuo_file.pdf')
stampa(testo)
2. Estrai ed elabora il testo:
Una volta ottenuto il testo, potrebbe essere necessario elaborarlo per trovare ed estrarre i dati specifici che ti interessano. Ciò può comportare:
- Ricerca di parole chiave o modelli utilizzando espressioni regolari.
- Suddivisione del testo in righe o paragrafi per un'estrazione sensibile al contesto.
Per PDF scansionati/basati su immagini:
1. Utilizzare gli strumenti OCR (riconoscimento ottico dei caratteri):
Per i PDF che sono essenzialmente immagini di testo (ad esempio, documenti scansionati), dovrai utilizzare il software OCR per convertire le immagini in testo selezionabile. Tesseract è un popolare motore OCR open source.
- Pytesseract : un wrapper Python per Tesseract. Dovrai anche convertire le pagine PDF in immagini, cosa che può essere eseguita utilizzando pdf2image.
da pdf2immagine importa convert_from_path
importa pytesseract
# Converti PDF in un elenco di immagini
immagini = convert_from_path('tuo_file_scansionato.pdf')
# Usa pytesseract per eseguire l'OCR sull'immagine
per i, immagine in enumerate(immagini):
testo = pytesseract.image_to_string(immagine)
print(f”Pagina {i+1} Testo:”, testo)
2. Elabora il testo estratto:
Dopo l'OCR, è probabile che il testo necessiti di pulizia ed elaborazione per estrarre i punti dati specifici di cui hai bisogno. Ciò può includere la rimozione degli artefatti introdotti dall'OCR, l'analisi della struttura del testo e l'applicazione di espressioni regolari per trovare modelli.
Come posso estrarre i dati del modulo da un PDF?
L'estrazione dei dati del modulo da un PDF, soprattutto se il modulo è compilato e salvato, implica metodi specifici in grado di analizzare la struttura del PDF ed estrarre i dati incorporati nei campi del modulo. Esistono diversi strumenti e librerie in diversi linguaggi di programmazione che possono svolgere questo compito, ma Python rimane una delle opzioni più accessibili e popolari grazie a librerie come PyPDF2 e PDFMiner per PDF basati su testo e PyMuPDF (noto anche come Fitz) per altri. compiti complessi. Ecco come puoi estrarre i dati del modulo da un PDF utilizzando Python:
Utilizzo di PyMuPDF (Fitz)
PyMuPDF è un collegamento Python per MuPDF: un visualizzatore leggero di PDF, XPS ed e-book. Offre funzionalità estese per lavorare con i PDF, inclusa l'estrazione di testo, immagini e dati dei moduli.
Installazione
Innanzitutto, assicurati di aver installato PyMuPDF:
pip installa pymupdf
Estrazione dei dati del modulo
importa fitz # PyMuPDF
def estratto_forma_data(percorso_pdf):
#Apri il PDF
doc = fitz.open(percorso_pdf)
dati_forma = {}
per la pagina nel documento:
# Estrai annotazioni (i campi del modulo sono un tipo di annotazione)
annoti = pagina.annoti()
se annota:
per annotare negli appunti:
info = annota.info
field_type = info.get(“oggetto”)
nome_campo = info.get(“titolo”)
field_value = info.get("contenuto")
se nome_campo e valore_campo:
# Compila il dizionario con nomi e valori di campo
form_data[nome_campo] = (valore_campo, tipo_campo)
restituisce dati_modulo
# Sostituisci "your_form.pdf" con il percorso del modulo PDF
form_data = extract_form_data("tuo_form.pdf")
per il campo in form_data:
print(f"Campo: {field}, Valore: {form_data[field][0]}, Tipo: {form_data[field][1]}")
Questo script apre un PDF e scorre ogni pagina, controllando le annotazioni (dove i campi del modulo PDF sono classificati in categorie). Per ogni annotazione, estrae il nome, il valore e il tipo del campo, memorizzandoli in un dizionario.
Utilizzando PyPDF2
PyPDF2 è un'altra libreria popolare per lavorare con PDF in Python. Può anche gestire l'estrazione dei dati dei moduli, anche se potrebbe non essere completo come PyMuPDF per PDF complessi.
Installazione
Assicurati che PyPDF2 sia installato:
pip installa pypdf2
Estrazione dei dati del modulo
importa PyPDF2
def extract_form_data_py2(percorso_pdf):
con open(pdf_path, 'rb') come file:
lettore = PyPDF2.PdfReader(file)
dati_forma = {}
# Accedi ai dati del modulo dal lettore
campi = lettore.get_fields()
per il campo nei campi:
form_data[campo] = campi[campo].get('/V', Nessuno)
restituisce dati_modulo
# Sostituisci "your_form.pdf" con il percorso del modulo PDF
form_data = extract_form_data_py2("tuo_form.pdf")
per il campo in form_data:
print(f"Campo: {campo}, Valore: {form_data[campo]}")
Questa funzione utilizza PyPDF2 per aprire un file PDF e accedere direttamente ai campi del modulo. Itera attraverso i campi, estraendo il nome e il valore di ciascuno e memorizzandoli in un dizionario.
Puoi raschiare dati da un PDF?
Sì, puoi estrarre dati da un PDF, ma l'approccio e gli strumenti di cui avrai bisogno dipendono dal tipo di PDF e dalla natura dei dati che desideri estrarre. I PDF possono essere generalmente classificati in due tipi: basati su testo e basati su scansione/immagine. Ciascun tipo richiede tecniche diverse per un'estrazione efficace dei dati.
PDF basati su testo
Questi PDF contengono testo selezionabile. Puoi evidenziare, copiare e incollare questo testo in un altro documento. I PDF basati su testo sono generalmente più facili da utilizzare quando si tratta di raschiare i dati.
Strumenti e librerie:
- PyPDF2 e PDFMiner in Python sono popolari per estrarre testo da questi PDF. PyPDF2 è semplice e utile per l'estrazione di testo di base e la manipolazione dei PDF, mentre PDFMiner offre un controllo più granulare sul layout e sulla formattazione, rendendolo adatto a esigenze di estrazione complesse.
- Apache PDFBox , una libreria Java, può anche estrarre testo da PDF e viene utilizzata in applicazioni di livello aziendale.
PDF scansionati/basati su immagini
Questi PDF sono essenzialmente immagini di testo. Poiché il testo fa parte di un'immagine, non può essere selezionato o copiato direttamente. L'estrazione dei dati da questi PDF richiede il riconoscimento ottico dei caratteri (OCR) per convertire le immagini del testo in testo reale.
Strumenti e librerie:
- Tesseract OCR è uno dei motori OCR più potenti e ampiamente utilizzati. Può essere utilizzato direttamente o tramite wrapper come Pytesseract in Python.
- Adobe Acrobat Pro offre funzionalità OCR integrate e può convertire i PDF scansionati in documenti di testo selezionabili e ricercabili.
Come posso estrarre automaticamente i dati da un PDF?
L'estrazione automatica dei dati da un PDF implica l'utilizzo di strumenti software in grado di interpretare i contenuti del PDF e convertirli in un formato strutturato. Il processo varia a seconda che il PDF sia basato su testo o su immagini (scansionato). Ecco come affrontare l'estrazione automatica dei dati da entrambi i tipi di PDF:
Per PDF basati su testo
1. Utilizzo delle librerie Python:
- PyPDF2 o PDFMiner sono popolari librerie Python per l'estrazione di testo da PDF basati su testo. PyPDF2 è adatto per semplici attività di estrazione del testo, mentre PDFMiner è più potente per layout e codifica complessi.
- Esempio con PyPDF2:
importa PyPDF2
con open('example.pdf', 'rb') come file:
lettore = PyPDF2.PdfReader(file)
testo = "
per la pagina in reader.pages:
testo += pagina.extract_text()
stampa(testo)
- Tabula o Camelot : se il tuo obiettivo è estrarre dati di tabelle da PDF, queste librerie sono appositamente progettate per questo scopo, con Camelot che fornisce un maggiore controllo sul processo di estrazione.
2. Utilizzo degli strumenti da riga di comando:
- pdftotext fa parte del set di strumenti Xpdf e può essere utilizzato per convertire documenti PDF in testo semplice direttamente dalla riga di comando, rendendolo adatto all'elaborazione batch.
Per PDF scansionati/basati su immagini
I PDF scansionati richiedono il riconoscimento ottico dei caratteri (OCR) per riconvertire le immagini di testo in testo selezionabile e ricercabile.
1. Utilizzo di Tesseract OCR:
- Tesseract è un motore OCR open source. Pytesseract, un wrapper Python per Tesseract, ti consente di integrare le funzionalità OCR nei tuoi script.
- Esempio con Pytesseract:
dall'immagine di importazione PIL
importa pytesseract
da pdf2immagine importa convert_from_path
immagini = convert_from_path('scanned_example.pdf')
testo = "
per l'immagine nelle immagini:
testo += pytesseract.image_to_string(immagine)
stampa(testo)
2. Utilizzo dei servizi OCR:
- Adobe Acrobat Pro offre funzionalità OCR integrate in grado di riconoscere automaticamente il testo nei documenti scansionati.
- Servizi OCR online : varie piattaforme online forniscono servizi OCR in grado di elaborare PDF in blocco. Tuttavia, presta attenzione alla privacy e alla sicurezza quando carichi documenti sensibili.