
Introducción a la extracción de datos de archivos PDF: herramientas y técnicas
Publicado: 2024-03-21En el mundo actual basado en datos, la capacidad de extraer información de manera eficiente de documentos PDF es una necesidad para muchas empresas e investigadores. Los PDF son uno de los formatos más comunes para distribuir y compartir documentos, pero su presentación estructurada a menudo dificulta la extracción de datos. Esta publicación de blog profundiza en los fundamentos de la extracción de datos de archivos PDF, explorando tanto las herramientas como las técnicas que pueden agilizar este proceso.
¿Por qué extraer datos de archivos PDF?

Fuente: https://www.docsumo.com/blog/extract-data-from-pdf
En la vasta era de la era digital, los documentos PDF son un testimonio de la combinación de coherencia, confiabilidad y accesibilidad universal. Introducido por Adobe en la década de 1990, el formato de documento portátil (PDF) se convirtió rápidamente en el estándar para distribuir documentos digitales que conservan su formato independientemente del dispositivo o software utilizado para verlos. Hoy en día, los archivos PDF son omnipresentes y sirven como contenedor para todo, desde artículos académicos y contratos legales hasta manuales técnicos e informes financieros. Sin embargo, debajo de su superficie estática y pulida se encuentra una gran cantidad de datos que a menudo están bloqueados y no permiten un fácil acceso. Esto nos lleva a la pregunta crucial: ¿Por qué es tan vital extraer datos de archivos PDF?
En el corazón de la transformación digital se encuentran los datos: datos que informan, datos que guían y datos que resuelven. En nuestra incesante búsqueda de eficiencia, comprensión e innovación, la extracción de datos de archivos PDF sirve como puente entre lo estático y lo dinámico, desde la información hasta el conocimiento. Ya sea analizando tendencias del mercado a partir de informes de investigación, digitalizando registros históricos con fines de archivo o procesando facturas para conciliación financiera, extraer datos de archivos PDF permite a las empresas y a los investigadores convertir información estática en conocimientos prácticos.
Desafíos en la extracción de datos PDF
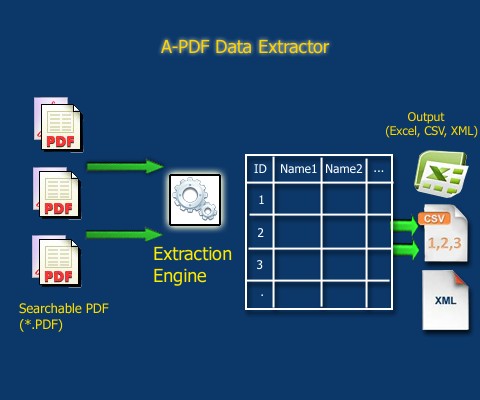
Fuente: https://www.a-pdf.com/data-extractor/index.htm
La extracción de datos de documentos PDF presenta un conjunto único de desafíos que pueden complicar el proceso tanto para empresas como para investigadores y desarrolladores. A pesar del uso generalizado de archivos PDF para documentación digital, sus propiedades inherentes y diversos formatos añaden capas de complejidad a los esfuerzos de extracción de datos. Aquí, profundizamos en algunos de los desafíos clave encontrados en la extracción de datos PDF, ofreciendo información sobre por qué lo que parece una tarea sencilla a menudo puede convertirse en una tarea compleja.
Complejidad inherente de la estructura del PDF
Los archivos PDF están diseñados principalmente para presentación, no para almacenamiento o manipulación de datos. A menudo carecen de una estructura coherente, lo que puede dificultar la extracción automatizada. A diferencia de HTML o XML, donde las etiquetas y los elementos definen la estructura y la jerarquía, los PDF colocan los elementos en diseños fijos. Esto significa que comprender la estructura lógica de la información, como distinguir entre títulos, párrafos y tablas de datos, requiere una interpretación sofisticada.
Variabilidad en la calidad del documento
Los documentos PDF pueden variar significativamente en calidad, especialmente cuando se trata de documentos escaneados. Los escaneos pueden introducir ruido, distorsiones e inconsistencias en el texto, lo que hace que los procesos de OCR (reconocimiento óptico de caracteres) sean menos precisos. Factores como la resolución del escaneo, el estado del documento físico y la presencia de marcas o anotaciones pueden complicar aún más la extracción de datos.
Mezcla de texto e imagen
Muchos archivos PDF contienen una combinación de texto e imágenes y, en algunos casos, la información crucial está incrustada en las imágenes. Esto requiere el uso de tecnología OCR para extraer texto de las imágenes, lo que puede resultar complicado, especialmente con diseños complejos, fuentes variadas y calidad mixta de las imágenes. Además, la precisión del OCR puede afectar significativamente la calidad de los datos extraídos.
Diseños y formatos complejos
Los archivos PDF suelen presentar diseños complejos, que incluyen tablas, texto de varias columnas, notas al pie y barras laterales. Estos elementos pueden interrumpir la extracción sencilla de texto, provocando pérdida o mala interpretación de datos. Extraer datos de tablas, por ejemplo, es particularmente desafiante porque la relación espacial entre elementos (en lugar de una estructura lógica o jerárquica) define la organización de los datos.
PDF cifrados o protegidos
Algunos archivos PDF están cifrados o protegidos para proteger los derechos de autor o la información confidencial, lo que restringe acciones como copiar, imprimir o editar. La extracción de datos de estos archivos PDF requiere descifrado, para lo cual es necesario el permiso o la clave de descifrado adecuada. Esto añade una capa adicional de complejidad y consideraciones legales al proceso de extracción.
Codificación y compresión diversas
Los archivos PDF pueden utilizar una variedad de codificaciones de texto y técnicas de compresión de imágenes, algunas de las cuales pueden no ser sencillas de interpretar o decodificar. Esta diversidad requiere herramientas de análisis flexibles y robustas capaces de manejar diferentes codificaciones y descomprimir contenido según sea necesario para la extracción de datos.
Herramientas y técnicas para una extracción de datos eficaz
Bibliotecas de análisis de PDF
- Bibliotecas Python : Python ofrece varias bibliotecas para la extracción de datos PDF, incluidas PyPDF2 y PDFMiner para archivos PDF basados en texto y PyMuPDF para documentos más complejos.
- Apache PDFBox : una herramienta Java que permite la creación y manipulación de documentos PDF, incluida la extracción de texto.
Herramientas de reconocimiento óptico de caracteres
Cuando se trata de archivos PDF escaneados o documentos basados en imágenes, las herramientas de OCR son esenciales. Tesseract, un motor de OCR de código abierto, se utiliza ampliamente para convertir imágenes en archivos PDF a formatos de texto editables.
Software comercial de extracción de PDF
Varias herramientas comerciales ofrecen funciones avanzadas, como algoritmos de aprendizaje basados en inteligencia artificial, para manejar tareas complejas de extracción de datos con mayor precisión. Los ejemplos incluyen Adobe Acrobat DC y ABBYY FineReader.
Mejores prácticas para la extracción de datos PDF
- Preprocesar archivos PDF : limpiar los documentos antes de la extracción (por ejemplo, eliminar imágenes innecesarias o páginas en blanco) puede mejorar significativamente la precisión.
- Scripts personalizados para automatización : para tareas de extracción a gran escala, considere escribir scripts personalizados que utilicen bibliotecas de análisis de PDF. Esto permite la automatización y personalización según necesidades específicas.
- Validación y controles de calidad : incorpore siempre un paso para validar los datos extraídos. Esto puede automatizarse hasta cierto punto, pero a menudo requiere supervisión humana.
Aplicaciones del mundo real
- Sector financiero : los bancos y las instituciones financieras extraen datos de archivos PDF para análisis crediticio, evaluación de riesgos e informes de cumplimiento.
- Atención médica : los registros de pacientes, los artículos de investigación y los datos de ensayos clínicos a menudo se almacenan en formato PDF y requieren extracción para análisis e informes.
- Investigación académica : los investigadores extraen datos de artículos académicos y artículos académicos para revisiones de literatura y metanálisis.
Conclusión
La extracción de datos de documentos PDF, si bien es un desafío, es esencial para el análisis de datos, la generación de informes y la toma de decisiones en diversas industrias. Al aprovechar las herramientas y técnicas adecuadas, las organizaciones pueden superar las dificultades inherentes a la extracción de datos PDF y desbloquear información valiosa contenida en sus documentos. A medida que avanza la tecnología, podemos esperar mejoras continuas en las herramientas de extracción, haciendo que el proceso sea más accesible y eficiente.

En PromptCloud, entendemos la importancia de una extracción de datos precisa y eficiente. Nuestras soluciones personalizadas están diseñadas para satisfacer las necesidades específicas de nuestros clientes, garantizando que puedan aprovechar al máximo la información contenida en sus documentos PDF. Ya sea que esté buscando extraer datos de un puñado de documentos o automatizar el proceso de extracción en miles, estamos aquí para ayudarlo.
Aproveche el poder de los datos con PromptCloud. Comuníquese hoy para descubrir cómo podemos transformar su proceso de extracción de datos PDF. Póngase en contacto con [email protected]
Preguntas frecuentes
¿Cómo extraigo datos específicos de un PDF?
Extraer datos específicos de un PDF requiere una combinación de herramientas y técnicas, adaptadas a la naturaleza del archivo PDF (basado en texto o escaneado/basado en imágenes) y los datos específicos que desea extraer. Aquí hay una guía paso a paso para ayudarlo a extraer datos específicos de archivos PDF:
Para archivos PDF basados en texto:
- Utilice bibliotecas de Python como PyPDF2 o PDFMiner:
Estas bibliotecas pueden ayudarle a extraer texto de archivos PDF que contienen capas de texto seleccionables.
- PyPDF2 : útil para extracción de texto simple y manipulación de PDF (como fusionar archivos PDF).
importar PyPDF2
# Abra el archivo PDF
con open('your_file.pdf', 'rb') como archivo:
lector = PyPDF2.PdfReader(archivo)
# Extraer texto de la primera página
página = lector.páginas[0]
texto = página.extract_text()
imprimir (texto)
PDFMiner : Más sofisticado, adecuado para extraer texto de diseños complejos.
desde pdfminer.high_level importar extraer_texto
texto = extraer_texto('tu_archivo.pdf')
imprimir (texto)
2. Extraer y procesar el texto:
Una vez que tenga el texto, es posible que necesite procesarlo para buscar y extraer los datos específicos que le interesan. Esto puede implicar:
- Búsqueda de palabras clave o patrones mediante expresiones regulares.
- Dividir el texto en líneas o párrafos para una extracción basada en el contexto.
Para archivos PDF escaneados/basados en imágenes:
1. Utilice herramientas de OCR (reconocimiento óptico de caracteres):
Para archivos PDF que son esencialmente imágenes de texto (por ejemplo, documentos escaneados), deberá utilizar el software OCR para convertir las imágenes en texto seleccionable. Tesseract es un popular motor de OCR de código abierto.
- Pytesseract : un contenedor de Python para Tesseract. También necesitarás convertir páginas PDF en imágenes, lo que se puede hacer usando pdf2image.
desde pdf2image importar convert_from_path
importar pytesseract
# Convertir PDF a una lista de imágenes
imágenes = convert_from_path('su_archivo_escaneado.pdf')
# Usa pytesseract para hacer OCR en la imagen
para i, imagen en enumerar (imágenes):
texto = pytesseract.image_to_string(imagen)
print(f”Página {i+1} Texto:”, texto)
2. Procese el texto extraído:
Después del OCR, es probable que sea necesario limpiar y procesar el texto para extraer los puntos de datos específicos que necesita. Esto puede incluir eliminar artefactos introducidos por OCR, analizar la estructura del texto y aplicar expresiones regulares para encontrar patrones.
¿Cómo extraigo datos de formulario de un PDF?
La extracción de datos de un formulario de un PDF, especialmente si el formulario se completa y guarda, implica métodos específicos que pueden analizar la estructura del PDF y extraer los datos incrustados en los campos del formulario. Existen varias herramientas y bibliotecas en diferentes lenguajes de programación que pueden realizar esta tarea, pero Python sigue siendo una de las opciones más accesibles y populares debido a bibliotecas como PyPDF2 y PDFMiner para archivos PDF basados en texto, y PyMuPDF (también conocido como Fitz) para más. tareas complejas. Así es como puedes extraer datos de formulario de un PDF usando Python:
Usando PyMuPDF (Fitz)
PyMuPDF es un enlace de Python para MuPDF: un visor ligero de PDF, XPS y libros electrónicos. Ofrece amplias funciones para trabajar con archivos PDF, incluida la extracción de texto, imágenes y datos de formularios.
Instalación
Primero, asegúrese de tener PyMuPDF instalado:
pip instalar pymupdf
Extraer datos del formulario
importar fitz#PyMuPDF
def extraer_form_data(pdf_path):
#Abre el PDF
doc = fitz.open(ruta_pdf)
datos_formulario = {}
para la página en doc:
# Extraer anotaciones (los campos del formulario son un tipo de anotación)
anotaciones = página.annots()
si anota:
para annot en annots:
información = annot.info
tipo_campo = info.get(“asunto”)
nombre_campo = info.get(“título”)
valor_campo = info.get(“contenido”)
si nombre_campo y valor_campo:
# Complete el diccionario con nombres y valores de campos
form_data[nombre_campo] = (valor_campo, tipo_campo)
devolver formulario_datos
# Reemplace 'your_form.pdf' con la ruta a su formulario PDF
form_data = extraer_form_data(“tu_formulario.pdf”)
para el campo en form_data:
print(f”Campo: {campo}, Valor: {form_data[campo][0]}, Tipo: {form_data[campo][1]}”)
Este script abre un PDF y recorre cada página, buscando anotaciones (donde se clasifican los campos del formulario PDF). Para cada anotación, extrae el nombre, el valor y el tipo del campo y los almacena en un diccionario.
Usando PyPDF2
PyPDF2 es otra biblioteca popular para trabajar con archivos PDF en Python. También puede manejar la extracción de datos de formularios, aunque puede que no sea tan completo como PyMuPDF para archivos PDF complejos.
Instalación
Asegúrese de que PyPDF2 esté instalado:
instalación de pip pypdf2
Extraer datos del formulario
importar PyPDF2
def extraer_form_data_py2(ruta_pdf):
con open(pdf_path, 'rb') como archivo:
lector = PyPDF2.PdfReader(archivo)
datos_formulario = {}
# Acceder a los datos del formulario desde el lector.
campos = lector.get_fields()
para campo en campos:
form_data[campo] = campos[campo].get('/V', Ninguno)
devolver formulario_datos
# Reemplace 'your_form.pdf' con la ruta a su formulario PDF
form_data = extraer_form_data_py2(“tu_formulario.pdf”)
para el campo en form_data:
print(f”Campo: {campo}, Valor: {form_data[campo]}”)
Esta función utiliza PyPDF2 para abrir un archivo PDF y acceder directamente a los campos de su formulario. Recorre los campos, extrae el nombre y el valor de cada uno y los almacena en un diccionario.
¿Puedes extraer datos de un PDF?
Sí, puedes extraer datos de un PDF, pero el enfoque y las herramientas que necesitarás dependerán del tipo de PDF y la naturaleza de los datos que deseas extraer. Los archivos PDF se pueden clasificar ampliamente en dos tipos: basados en texto y basados en escaneados/imágenes. Cada tipo requiere diferentes técnicas para una extracción de datos eficaz.
PDF basados en texto
Estos archivos PDF contienen texto seleccionable. Puede resaltar, copiar y pegar este texto en otro documento. Generalmente es más fácil trabajar con archivos PDF basados en texto cuando se trata de extracción de datos.
Herramientas y bibliotecas:
- PyPDF2 y PDFMiner en Python son populares para extraer texto de estos archivos PDF. PyPDF2 es sencillo y útil para la extracción básica de texto y la manipulación de PDF, mientras que PDFMiner ofrece un control más granular sobre el diseño y el formato, lo que lo hace adecuado para necesidades de extracción complejas.
- Apache PDFBox , una biblioteca de Java, también puede extraer texto de archivos PDF y se utiliza en aplicaciones de nivel empresarial.
PDF escaneados/basados en imágenes
Estos archivos PDF son esencialmente imágenes de texto. Dado que el texto es parte de una imagen, no se puede seleccionar ni copiar directamente. La extracción de datos de estos archivos PDF requiere el reconocimiento óptico de caracteres (OCR) para convertir las imágenes de texto en texto real.
Herramientas y bibliotecas:
- Tesseract OCR es uno de los motores de OCR más potentes y utilizados. Se puede utilizar directamente o mediante contenedores como Pytesseract en Python.
- Adobe Acrobat Pro ofrece capacidades de OCR integradas y puede convertir archivos PDF escaneados en documentos de texto seleccionables y con capacidad de búsqueda.
¿Cómo extraigo automáticamente datos de un PDF?
La extracción automática de datos de un PDF implica el uso de herramientas de software que pueden interpretar el contenido del PDF y convertirlo a un formato estructurado. El proceso difiere dependiendo de si el PDF está basado en texto o en imágenes (escaneado). A continuación se explica cómo abordar la extracción automática de datos de ambos tipos de archivos PDF:
Para archivos PDF basados en texto
1. Usando bibliotecas de Python:
- PyPDF2 o PDFMiner son bibliotecas de Python populares para extraer texto de archivos PDF basados en texto. PyPDF2 es adecuado para tareas simples de extracción de texto, mientras que PDFMiner es más potente para diseños y codificación complejos.
- Ejemplo con PyPDF2:
importar PyPDF2
con open('example.pdf', 'rb') como archivo:
lector = PyPDF2.PdfReader(archivo)
texto = "
para la página en Reader.pages:
texto += página.extract_text()
imprimir (texto)
- Tabula o Camelot : si su objetivo es extraer datos de tablas de archivos PDF, estas bibliotecas están diseñadas específicamente para este propósito, y Camelot brinda más control sobre el proceso de extracción.
2. Usando herramientas de línea de comando:
- pdftotext es parte del conjunto de herramientas Xpdf y se puede utilizar para convertir documentos PDF en texto sin formato directamente desde la línea de comandos, lo que lo hace adecuado para el procesamiento por lotes.
Para archivos PDF escaneados/basados en imágenes
Los archivos PDF escaneados requieren reconocimiento óptico de caracteres (OCR) para convertir imágenes de texto nuevamente en texto seleccionable y con capacidad de búsqueda.
1. Usando Tesseract OCR:
- Tesseract es un motor de OCR de código abierto. Pytesseract, un contenedor de Python para Tesseract, le permite integrar capacidades de OCR en sus scripts.
- Ejemplo con Pytesseract:
desde la imagen de importación PIL
importar pytesseract
desde pdf2image importar convert_from_path
imágenes = convert_from_path('ejemplo_escaneado.pdf')
texto = "
para imagen en imágenes:
texto += pytesseract.image_to_string(imagen)
imprimir (texto)
2. Uso de servicios de OCR:
- Adobe Acrobat Pro ofrece capacidades de OCR integradas que pueden reconocer automáticamente el texto de los documentos escaneados.
- Servicios de OCR en línea : varias plataformas en línea brindan servicios de OCR que pueden procesar archivos PDF de forma masiva. Sin embargo, tenga en cuenta la privacidad y la seguridad al cargar documentos confidenciales.