
Kompletny przewodnik po tagach kanonicznych dla SEO
Opublikowany: 2022-01-28Tagi kanoniczne pozwalają określić, która spośród wielu zduplikowanych stron jest podstawową, preferowaną wersją strony.
Każda witryna może cierpieć z powodu problemów z duplikacją treści – i możesz nie zdawać sobie sprawy, że niektóre treści są postrzegane jako duplikaty.
Bez tagu kanonicznego jesteś na łasce wyszukiwarek – same wybiorą wersję kanoniczną. I mogą równie dobrze wybrać taki, którego nie uważasz za reprezentatywny dla danej treści. Może to poważnie wpłynąć na widoczność i rankingi wyszukiwania.
W tym przewodniku wyjaśniono cechy i sprawdzone metody korzystania z tagów kanonicznych w celu rozwiązania problemów z duplikacją treści w Twojej witrynie.
Czym są znaczniki kanoniczne?
Tag kanoniczny to fragment kodu, który wskazuje główną (kanoniczną) wersję strony, jeśli istnieje więcej niż jedna wersja tej strony.
Używając tagu kanonicznego, możesz wskazać wyszukiwarkom, który adres URL powinien być indeksowany i pojawiać się w wynikach wyszukiwania.
Najpopularniejszą techniką implementacji tagów kanonicznych jest dodanie następującego fragmentu kodu do kodu HTML strony:
<link rel="canonical" href="https://example.com/sample-page/" />Kod oznacza, że strona kanoniczna znajduje się pod określonym adresem URL.
Tagi kanoniczne są używane do rozwiązywania problemów z duplikatami treści – ale jakie treści wyszukiwarki uznają za duplikaty i jak je traktują?
Wyszukiwarki i duplikaty treści
Problemy ze zduplikowaną treścią wynikają z prostego faktu, że roboty wyszukiwarek traktują strony inaczej niż użytkownicy.
W przypadku robota wyszukiwarki każdy z następujących adresów URL jest inny:
- http://witryna.com
- https://site.com
- https://site.com/index.php
- http://site.com/index.php
- http://www.site.com
Podczas gdy użytkownik zwraca uwagę na treść na stronie, roboty indeksujące postrzegają każdy adres URL jako oddzielną jednostkę, nawet jeśli wiele stron ma identyczną treść.
Problemy z powielonymi treściami są szczególnie poważne w przypadku witryn handlu elektronicznego, ale nie ograniczają się do nich. Wiele nowoczesnych witryn automatycznie dodaje tagi i parametry do adresów URL, np. w celu sortowania lub filtrowania stron, i często wykorzystują wiele ścieżek prowadzących do tej samej treści.
Wiele wersji Twoich adresów URL może również istnieć, jeśli używasz różnych struktur adresów URL – np. Twoje adresy URL mają zarówno www, jak i bez www, z ukośnikami końcowymi i bez nich, z protokołami HTTP i HTTPS oraz w dowolnych innych formatach.
Może to prowadzić do powielania treści, które wyszukiwarki niechętnie indeksują.
W szczególności, gdy wyszukiwarki napotykają zduplikowane treści, mają trudności z podjęciem decyzji:
- Która strona powinna być indeksowana,
- Która strona powinna mieć ranking odpowiednich słów kluczowych oraz
- Czy mają skonsolidować sygnały rankingowe pod jednym adresem URL, czy podzielić je na wiele stron.
Chociaż wyszukiwarki mogą usuwać duplikaty stron na potrzeby rankingu, ryzykowne jest pozwalanie im na wybór kanonicznego adresu URL — mogą wybrać stronę, która nie jest najbardziej reprezentatywną wersją Twoich treści.
Jak Google wybiera strony kanoniczne?
Należy pamiętać, że Googlebot nie zawsze będzie podążał za tagami kanonicznymi, ponieważ służą one jedynie jako sugestie dotyczące sposobu traktowania danego adresu URL.
Wybierając wersję kanoniczną , Google bierze pod uwagę wiele innych czynników na stronie .
Czynniki te obejmują m.in.:
- Przekierowania ,
- Linkowanie wewnętrzne i zewnętrzne,
- mapy witryn ,
- Czysta struktura adresu URL,
- Wykorzystanie protokołu HTTPS.
Możesz sprawdzić, czy Google szanuje Twój tag kanoniczny, czy wybrał inny, korzystając z narzędzia do sprawdzania adresów URL .
Google używa stron kanonicznych jako głównych źródeł oceny treści i jakości. Wynik wyszukiwania Google zwykle wskazuje na stronę kanoniczną, chyba że jeden z duplikatów jest wyraźnie lepiej dopasowany do użytkownika. Na przykład wynik wyszukiwania prawdopodobnie będzie wskazywał stronę mobilną, jeśli użytkownik korzysta z urządzenia mobilnego, nawet jeśli strona na komputery jest oznaczona jako kanoniczna.źródło: dokumentacja Google
Obejrzyj ten film, który wyjaśnia, jak Google wybiera kanoniczne adresy URL.
Kiedy należy używać znaczników kanonicznych?
Nie zapominaj, że samo dodanie znaczników kanonicznych nie rozwiąże wszystkich problemów z duplikatami lub szczupłą zawartością.
Twoim głównym celem powinno być wyeliminowanie podstawowych problemów, które powodują te problemy. Skoncentruj się na przeanalizowaniu, czy możesz usunąć lub ulepszyć zawartość zduplikowanych stron, aby uczynić ją bardziej unikalną i być może zapewnić większą wartość dla użytkownika.
Niemniej jednak dokładne oznaczanie stron tagami kanonicznymi jest krokiem naprzód w radzeniu sobie z duplikatami treści.
Przeanalizujmy, w jaki sposób możesz skorzystać ze znaczników kanonicznych i kiedy ich używać.
Korzyści z używania znaczników kanonicznych
Dodając znaczniki kanoniczne, możesz:
Określ, która strona powinna pojawiać się w wynikach wyszukiwania
Wyszukiwarki mają na celu zapewnienie jak najlepszych wrażeń użytkownikom – dlatego rzadko wyświetlają w wynikach wyszukiwania więcej niż jedną wersję tej samej treści.
Tagi kanoniczne dają szansę na zwiększenie widoczności wyszukiwania najbardziej reprezentatywnej wersji strony, co może zwiększyć ruch organiczny na tej stronie i przełożyć się na korzyści biznesowe.
Skonsoliduj sygnały rankingowe dla zduplikowanych stron
Inne witryny mogą zawierać linki do różnych zduplikowanych wersji Twoich stron, osłabiając sygnały uwzględniane przez wyszukiwarki podczas rankingu.
Używając tagu kanonicznego, informujesz wyszukiwarki, że sygnały rankingowe ze zduplikowanych adresów URL powinny płynąć do strony kanonicznej.
Zniechęcaj do indeksowania zduplikowanych stron
Jeśli zaimplementujesz tagi kanoniczne, jest mniej prawdopodobne, że wyszukiwarki będą nadal indeksować strony kanoniczne, wiedząc, że są to kopie.
Jednocześnie wersja kanoniczna powinna być częściej indeksowana.
Daje to możliwość sprawniejszego indeksowania stron kanonicznych, co może pozytywnie wpłynąć na stan indeksowania witryny .
Rodzaje treści do oznaczania za pomocą znaczników kanonicznych
Przejdźmy przez konkretną treść, dla której powinieneś wybrać stronę kanoniczną.
Następujące typy treści i aspekty zazwyczaj nie dodają wartości do Twojej witryny i mogą skutkować zwiększoną liczbą duplikatów treści.
Treść syndykowana
Syndykacja treści oznacza, że część treści została ponownie opublikowana w innej domenie.
Wdrożenie tagu kanonicznego może pomóc w przypisaniu prawa własności do utworu oryginalnemu wydawcy.
Filtrowanie i sortowanie produktów
Opcje filtrowania i sortowania, typowe dla witryn eCommerce, zwykle wykorzystują ciągi zapytań, które są dodawane do adresów URL – może to powodować ogromne ilości duplikatów treści. Kanonizowanie filtrowania i sortowania stron pomoże Twojej wersji kanonicznej uzyskać wyższą pozycję w rankingu i zapobiegnie niepotrzebnemu indeksowaniu zduplikowanych treści przez wyszukiwarki,
Zbędne parametry w adresach URL
Parametry mogą być zbędne dla strony , jeśli nie są używane do śledzenia, nie zmieniają treści i nie dodają żadnych znaczących informacji do adresu URL.
Zamiast tego mogą prowadzić do nieefektywnego indeksowania Twojej witryny.
Warianty produktu
Produkt może występować w różnych wariantach, w których jedyną cechą, która się zmienia, jest jego kolor, rozmiar lub inny odpowiedni atrybut. Kanonizacja może pomóc w wyborze głównego wariantu produktu.
Zastanów się jednak, czy produkt pozostaje taki sam. Na przykład w niszy technologicznej różne warianty produktów, takie jak smartfony, mogą w rzeczywistości zawierać inne funkcjonalności i dlatego wszystkie powinny pojawiać się w wynikach wyszukiwania.
Parametry śledzenia i identyfikatory sesji
Parametry śledzenia mogą śledzić kampanię lub ścieżkę użytkownika i nie zmieniają zawartości strony, dlatego też powinny być kanonizowane.
Porównanie tagów kanonicznych z tagami noindex i przekierowaniami 301
Być może zastanawiasz się, jak tagi kanoniczne wypadają w porównaniu z innymi rozwiązaniami, które mogą wpływać na to, jak wyszukiwarki indeksują strony i czy w ogóle je indeksują.
Porównajmy cechy i przypadki użycia SEO tagów kanonicznych, tagów noindex i przekierowań 301.
Używanie znaczników kanonicznych a znaczników noindex
Tagi Noindex służą do wykluczania stron z indeksu, a nie do zarządzania, która strona powinna być wybrana jako kanoniczna.
Nigdy nie należy używać tagu noindex, aby uniemożliwić wyszukiwarkom wybór strony kanonicznej.
Strony kanonizowane generalnie konsolidują sygnały rankingowe pod jednym adresem URL, w przeciwieństwie do tagów noindex – jest to spowodowane tym, że Google traktuje długoterminowe tagi noindex, follow tags jako noindex, nofollow .
Ogólna zasada jest taka, że strona nie powinna być jednocześnie bezindeksowana i kanonizowana. Na przykład strony kanonizowane do nieindeksowanych adresów URL zostaną usunięte z indeksu.
John Mueller wyjaśnił podczas godzin pracy SEO , że nie ma ryzyka, że strona noindex i kanonizowana przeniesie noindex do jego kanonicznego miejsca docelowego, co następnie usunie oba adresy z indeksu.
Jednak używanie zarówno tagów noindex, jak i canonical wysyła do Google mieszane sygnały. Oznacza to, że Google może interpretować tagi w dowolny sposób, a wynik może być dla Ciebie niepożądany.
Używanie tagów kanonicznych a przekierowań 301
Wyszukiwarki i użytkownicy bardzo różnie postrzegają tagi kanoniczne i przekierowania 301.
Jeśli użyjesz przekierowania 301, użytkownicy zostaną automatycznie przeniesieni na stronę docelową i nie zobaczą strony oryginalnej. Przekierowania 301 pomagają również zaoszczędzić budżet indeksowania , ponieważ ograniczają liczbę adresów URL, które należy zindeksować.
Tymczasem dzięki tagowi kanonicznemu użytkownicy nadal będą mogli odwiedzać oba adresy URL. Co więcej, zduplikowane adresy URL są nadal indeksowane przez wyszukiwarki, więc liczba możliwych do zaindeksowania stron nie zmniejsza się.
Chociaż tagi kanoniczne mają tendencję do przekazywania sygnałów rankingowych do podstawowej wersji strony, przekierowania 301 stanowią silniejszą wskazówkę dla Google , że sygnały rankingowe powinny być przekazywane do docelowego adresu URL. Dzieje się tak, ponieważ Google nie widzi sporadycznych treści, jak to ma miejsce w przypadku tagów kanonicznych.
Wyjaśnijmy, kiedy przekierowanie 301 będzie bardziej odpowiednie niż tag kanoniczny.
Najlepiej używać przekierowań 301 do konsolidacji adresów URL:
- Zawierające małe i wielkie litery,
- Z końcowymi ukośnikami i bez nich,
- protokoły HTTP lub HTTPS,
- Istniejące zarówno z www jak i bez.
Jeśli wprowadzasz zmiany w treści – na przykład podczas migracji witryny – i zmienią się Twoje adresy URL, powinieneś przekierować starsze adresy URL 301 na nowe. Oprócz przekierowania upewnij się, że nowy docelowy adres URL zawiera samoodwołujący się tag kanoniczny.
Inną sytuacją, w której przekierowania 301 będą optymalne, jest sytuacja, gdy produkty są dostępne pod wieloma adresami URL.
W takim przypadku zmień strukturę adresu URL, aby nie zawierał nazwy kategorii, do której zostały przypisane produkty. Następnie 301 przekieruj starszy adres URL. Jeśli jakiekolwiek kategorie są zbędne, możesz je usunąć i przekierować do odpowiednich alternatywnych stron.

Ogólnie rzecz biorąc, użyj przekierowania 301, jeśli tylko jeden adres URL powinien być nadal dostępny dla użytkowników.
Jak dodać kanoniczne znaczniki do strony
Istnieją dwie główne metody określania stron kanonicznych — w nagłówkach HTML lub HTTP strony. Możesz je wdrożyć ręcznie lub skorzystać z jednego z narzędzi, które pomogą Ci to zautomatyzować.
Na przykład możesz wybrać wtyczkę SEO , jeśli korzystasz z CMS. Wtyczki z funkcją określania stron kanonicznych obejmują Yoast SEO lub All in One SEO.
Jeśli korzystasz z Shopify , możesz w razie potrzeby ustawić niestandardowe kanoniczne adresy URL — domyślnym ustawieniem Shopify jest dodanie odwołujących się do siebie kanonicznych adresów URL dla produktów i postów na blogu.
Bez względu na wybraną metodę nie zapomnij o zaimplementowaniu znaczników kanonicznych tylko w jednym miejscu – nie używaj tych metod jednocześnie. Jeśli Google wykryje wiele deklaracji tagu kanonicznego, prawdopodobnie zignoruje je wszystkie.
Znacznik HTML
Dodanie tagu kanonicznego w kodzie HTML jest najczęstszym sposobem jego implementacji.
Dodaj następujący kod do sekcji <head> duplikatu strony w kodzie HTML i wklej adres URL wersji kanonicznej:
<link rel="canonical" href="https://example.com" />Ta metoda działa tylko dla stron HTML, więc użyj nagłówka HTTP, jeśli chcesz kanonizować inne typy plików.
Nagłówek HTTP
Możesz zaimplementować nagłówek HTTP „rel=canonical”, aby wskazać kanoniczną wersję adresu URL:
Link: <http://www.example.com/downloads/white-paper.pdf>; rel="kanoniczny"
Użyj nagłówka HTTP, aby określić kanoniczny dla dokumentów innych niż HTML, takich jak pliki PDF.
Aby skorzystać z tego rozwiązania, potrzebujesz dostępu do serwera swojej witryny. Wymaga również pewnych umiejętności technicznych, ponieważ ta metoda jest bardziej podatna na błędy i trudna do wdrożenia niż HTML.
Najlepsze praktyki dotyczące używania znaczników kanonicznych
Postępowanie zgodnie z najlepszymi praktykami dotyczącymi tagów kanonicznych pomaga zmniejszyć ryzyko, że wyszukiwarki uznają niewłaściwą wersję strony za kanoniczną.
Oto moja lista zaleceń dotyczących tagów kanonicznych:
Użyj bezwzględnych adresów URL
Teoretycznie Google powinien rozpoznawać zarówno względne, jak i bezwzględne adresy URL. Jednak bezwzględne wersje adresów URL są mniej podatne na błędy i łatwiejsze do debugowania.
Możesz użyć obu, ale sugeruję używanie bezwzględnych adresów URL, aby mieć pewność, że są poprawnie interpretowane.
— johnmu.xml (osobisty) (@JohnMu) 24 października 2018 r.
Innymi słowy, użyj pełnego adresu URL w tagu kanonicznym:
<link rel="canonical" href="https://example.com/sample-page/" />I nie podawaj tylko ścieżki adresu URL:
<link rel="canonical" href="/sample-page/" />Używaj autoreferencyjnych tagów kanonicznych
Chociaż nie jest to wymagane, zaleca się używanie znaczników kanonicznych wskazujących strony, na których się znajdują.
Zaimplementowanie go jest niezbędne, jeśli używasz parametrów do śledzenia kampanii – powinno to spowodować, że wszystkie adresy URL z parametrem kampanii będą domyślnie kanonizowane na statyczny adres URL i uniemożliwić ich indeksowanie.
Oto, co John Mueller z Google powiedział podczas godzin pracy SEO na temat autoreferencyjnych kanonicznych:
Posiadanie na stronie odwołującego się do siebie tagu kanonicznego nie ma kluczowego znaczenia, ale ułatwia nam wybranie dokładnie adresu URL, który chcesz wybrać jako kanoniczny.Do wyboru kanonicznego adresu URL wykorzystujemy wiele czynników, a rel=canonical odgrywa w tym rolę.
A więc w szczególności takie rzeczy jak parametry adresu URL lub jeśli adres URL jest otagowany w określony sposób – na przykład masz linki prowadzące do tej strony, które są otagowane do celów analitycznych – wtedy może się zdarzyć, że wybierzemy ten otagowany adres URL jako kanoniczny […]
źródło: John Mueller
Wysyłaj wyraźne sygnały do wyszukiwarek
Wysyłanie wyraźnych sygnałów polega na określeniu tylko jednego kanonicznego na stronę.
Unikaj określania adresu URL jako kanonicznego i jednoczesnego przekierowywania go do innego miejsca docelowego.
Inny przypadek dotyczy kanonów dodawanych za pomocą JavaScript.
Jeśli w kodzie HTML nie określono strony kanonicznej, a tag kanoniczny został dodany za pomocą JavaScript, Google powinno go przestrzegać podczas renderowania. Ale jeśli w kodzie HTML jest ustawiony kanoniczny, a JavaScript go zmieni, wysyłasz mieszane sygnały do Google.
Wysyłanie mieszanych sygnałów może spowodować, że wyszukiwarki nieprawidłowo zinterpretują Twoje kanoniczne lub wybierze niewłaściwą wersję jako kanoniczną.
Upewnij się, że używasz prawidłowego adresu URL podczas tworzenia wewnętrznego linku
Umieszczając linki wewnętrzne w swojej witrynie, upewnij się, że linkujesz do kanonicznego adresu URL , a nie do duplikatów.
Jak wspomniano, Google może nie respektować wartości kanonicznej, jeśli silniejsze sygnały wskazują inny adres URL . Jednym z takich sygnałów może być zwiększenie liczby linków do zduplikowanego adresu URL, który Google może zamiast tego wyświetlić jako wersję główną.
Nie kieruj znacznika kanonicznego na pierwszą stronę paginacji
Częstym błędem jest dążenie do indeksowania tylko pierwszej strony paginacji. Możesz go użyć, aby uniemożliwić użytkownikom dostęp do kolejnych stron z wyników wyszukiwania, ale jest to niewłaściwe podejście. Wyszukiwarki mogą ignorować kanonizację, ponieważ te strony zwykle nie są duplikatami. Ale jeśli respektują znaczniki kanoniczne, paginacja może być kanonizowana.
Jeśli paginacja zawiera linki do unikalnych produktów i nie ma innych linków między stronami produktów, linki do stron produktów w paginacji mogą zostać zignorowane. Innymi słowy, indeksowalne strony produktów nie będą zawierać wewnętrznych linków z innych stron.
Zamiast tego strony podzielone na strony powinny mieć samoodnoszące się znaczniki kanoniczne. Treść tych stron nie jest identyczna, a dodając tagi samoodnoszące się, informujesz wyszukiwarki, że każda strona jest unikalna. Jeśli nie chcesz, aby te strony były indeksowane, użyj tagów noindex.
Wskaż komputerową wersję strony
Jeśli Twoja witryna mobilna znajduje się w subdomenie, tag kanoniczny powinien wskazywać komputerową wersję strony.
Zidentyfikuj stronę kanoniczną podczas używania tagów hreflang
Chociaż Google nie widzi różnych wersji tej samej treści przetłumaczonych na inne języki jako duplikatów, nadal należy używać tagów kanonicznych.
Poinformuj wyszukiwarki, jaka strona kanoniczna jest w tym samym języku lub najlepszym języku zastępczym. Warianty językowe powinny być samokanoniczne.
Zapobiegaj problemom z budżetem indeksowania
Kanonizowane adresy URL mogą nadal wykorzystywać budżet indeksowania, nawet jeśli tagi kanoniczne są prawidłowo zaimplementowane.
Chociaż szybkość indeksowania kanonizowanych adresów URL powinna z czasem spadać, wyszukiwarki mogą nadal skupiać się na pobieraniu duplikatów zamiast na przeszukiwaniu i indeksowaniu nowych stron.
Sprawdź dzienniki serwera, aby zobaczyć, jak Googlebot zachowuje się w Twojej witrynie, i zidentyfikować potencjalne problemy z indeksowaniem.
Aby złagodzić problemy z budżetem indeksowania, należy ogólnie:
- Ogranicz wewnętrzne linki do niekanonicznych wersji adresów URL,
- Użyj narzędzia Parametr adresu URL w Google Search Console, aby poinformować Googlebota, że ma indeksować statyczne wersje adresów URL.
Pamiętaj jednak, że problemy z budżetem indeksowania występują w bardzo dużych witrynach – Google twierdzi, że większość witryn nigdy nie będzie musiała się tym martwić.
Polecam przeczytać artykuł Google o typowych błędach podczas wdrażania „rel=canonical” , aby dowiedzieć się, jakich innych rzeczy należy unikać.
Jak przeprowadzić audyt tagów kanonicznych
Aby Twoje znaczniki kanoniczne zostały pobrane, musisz upewnić się, że strona ma znacznik kanoniczny, który wskazuje właściwą stronę.
Należy również sprawdzić, czy strona jest indeksowalna i indeksowalna – nie powinna być blokowana przez plik robots.txt ani oznaczana tagiem noindex.
Poniżej znajduje się kilka przydatnych sposobów sprawdzania tagów kanonicznych.
Jak używać Google Search Console do analizowania tagów kanonicznych
Google Search Console zawiera kilka pomocnych narzędzi do audytu stron kanonicznych: raport Pokrycie indeksu i narzędzie do sprawdzania adresów URL.
Raport dotyczący pokrycia indeksu
Raport Pokrycie indeksu w Google Search Console jest cennym źródłem informacji o stanie indeksowania – które adresy URL są indeksowane, a które nie podlegają indeksowaniu i dlaczego.
Aby przeanalizować elementy kanoniczne swojej witryny, przejdź do kategorii Wykluczone.
Tutaj możesz znaleźć kilka stanów, które są dla Ciebie istotne:
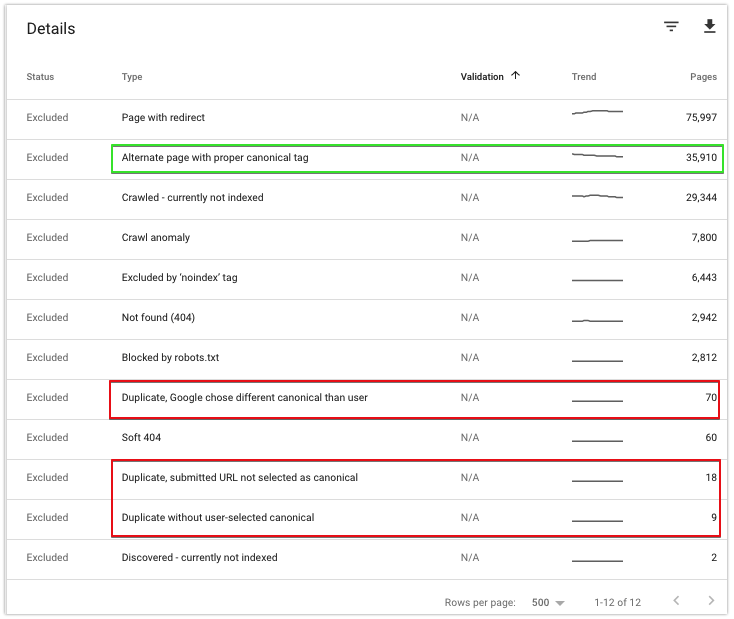
Alternatywna strona z odpowiednim znacznikiem kanonicznym
Adresy URL oznaczone tym stanem wskazują strony, w przypadku których Google respektuje Twoją kanonizację do adresu URL.
Możesz się spodziewać, że liczba tych adresów URL wzrośnie, jeśli ostatnio dokonałeś kanonizacji niektórych stron. Możesz użyć tej sekcji raportu Google, aby sprawdzić, czy Google nie indeksuje duplikatów więcej niż to konieczne.
W przeciwnym razie te adresy URL nie wymagają Twojej uwagi.
Duplikat, Google wybrał inny kanoniczny niż użytkownik
Stan wskazuje, że Google zignorowało Twoje samodzielne odsyłanie do kanonicznego lub przekształcenie kanoniczne na inny kanoniczny. Może się tak zdarzyć, jeśli silniejsze sygnały wskazują na inne adresy URL – na przykład może wystąpić zwiększona liczba wewnętrznych linków do innych stron.
Ten problem może również wskazywać na problemy z treścią. Na przykład może się zdarzyć, że unikatowa część treści nie została załadowana lub wybrałeś niewłaściwą stronę do kanonizacji, np. ponieważ nie ma wystarczającej parzystości treści między zduplikowanymi a kanonicznymi stronami.
Jeśli nie możesz określić, jak rozwiązać ten problem, przejdź bezpośrednio do naszego przewodnika, jak naprawić duplikat, Google wybrał inny problem kanoniczny niż problem użytkownika.
Zduplikowany, przesłany adres URL nie został wybrany jako kanoniczny
Oznacza to, że Google znalazł w Twoich mapach witryn XML strony, które uważa za duplikaty. Przejrzyj mapę witryny i upewnij się, że wszystkie znalezione w niej adresy URL powinny być zindeksowane.
Duplikuj bez kanonicznego wybranego przez użytkownika
Są to zduplikowane adresy URL bez określonych adresów URL rel=canonical – określ najbardziej odpowiednie dla nich strony kanoniczne i dodaj je.
Narzędzie do sprawdzania adresów URL
Możesz użyć narzędzia do sprawdzania adresów URL, aby dokładniej zbadać, jak Googlebot widzi adresy URL wykluczone z indeksu.
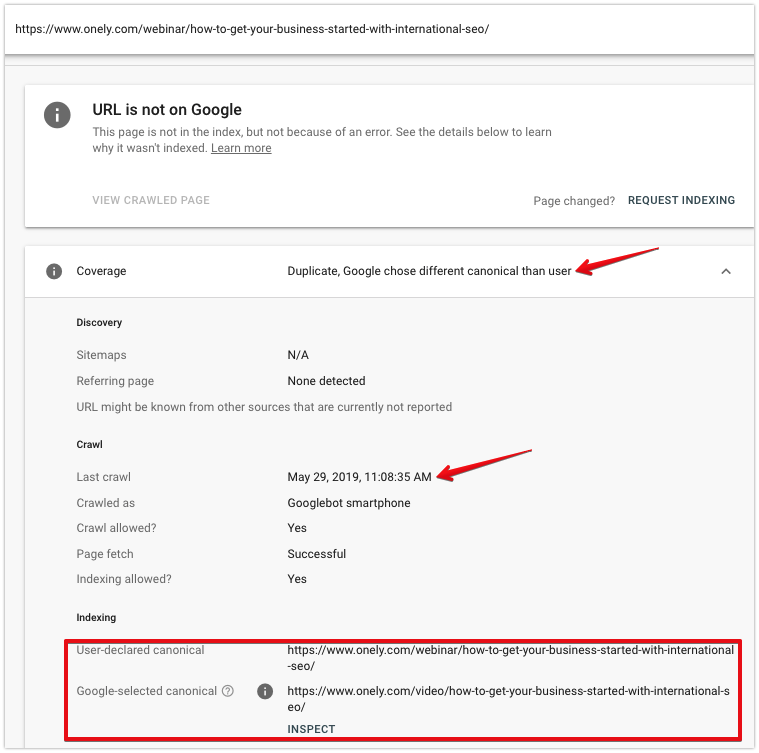
Sprawdzając stronę, spójrz na:
- Data ostatniego indeksowania – czas ostatniego pobrania strony przez Googlebota. Jeśli tag kanoniczny został niedawno dodany, prawdopodobnie Googlebot od tego czasu nie indeksował adresu URL.
- Kanoniczny deklarowany przez użytkownika — powinien pokazywać wybrany adres URL — sprawdź, czy jest to poprawny adres URL.
- Kanoniczna wybrana przez Google — jeśli Google wybrał inną stronę kanoniczną, możesz zobaczyć, który URL został wybrany.
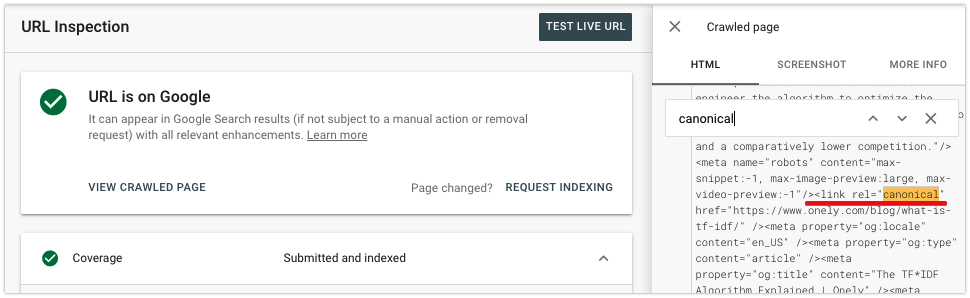
Możesz także sprawdzić, czy tag kanoniczny został dodany poprawnie. Kliknij opcję Wyświetl zindeksowaną stronę, aby sprawdzić wyrenderowaną treść i wyszukać tag kanoniczny w sekcji <head>.
Na karcie Więcej informacji możesz sprawdzić nagłówek odpowiedzi HTTP otrzymany przez Googlebota.
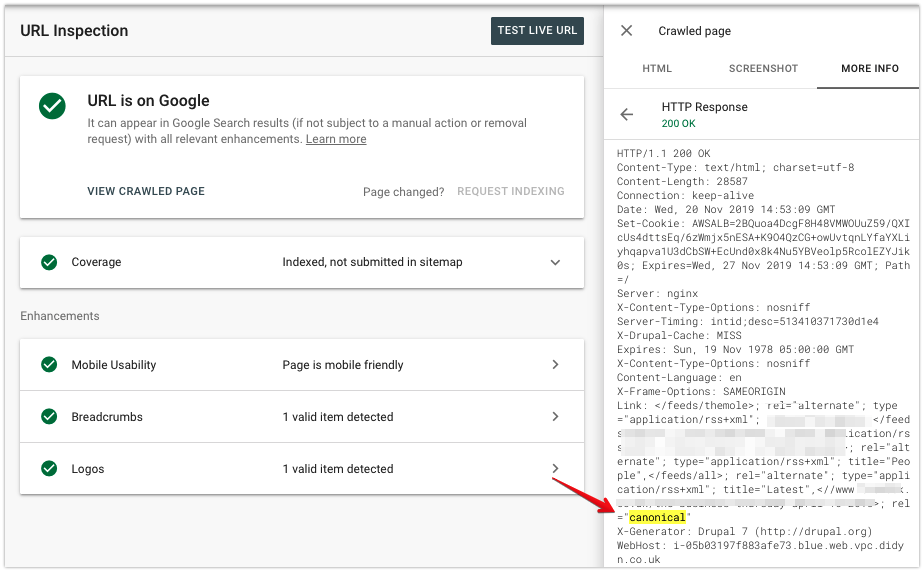
Upewnij się, że jest zgodny z żądaną konfiguracją, nawet jeśli używasz rel=canonical w kodzie HTML strony.
Przeprowadzanie indeksowania witryny w celu audytu tagów kanonicznych
Indeksowanie witryny może pomóc w wykryciu problemów z tagami kanonicznymi.
Roboty indeksujące witryny dostarczają szczegółowych informacji na temat stosunku kanonicznego do niekanonicznego. Będą Cię ostrzegać o wszelkich niepoprawnych znakach kanonicznych, takich jak usunięte/brakujące strony (HTTP 4xx), błędy serwera (HTTP 5xx) lub przekierowania (HTTP 3xx) w tagach kanonicznych. Ogólnie należy sprawdzić kody stanu inne niż HTTP 200.
Postępuj zgodnie z tym przewodnikiem, aby dowiedzieć się , jak przeprowadzić audyt swoich kanonów za pomocą SEO Spidera Screaming Frog.
Zawijanie
Wdrożenie znaczników kanonicznych daje możliwość wskazania wyszukiwarkom, który adres URL reprezentuje najlepszą wersję każdego elementu treści. Możesz wtedy wpłynąć na to, które strony pojawiają się w wynikach wyszukiwania – a które są traktowane jako drugorzędne.
Dane kanoniczne to tylko sygnały, których wyszukiwarki nie muszą szanować. Ale w wielu przypadkach możesz zwiększyć szanse, że Twoje znaczniki kanoniczne będą przestrzegane. Jak?
Postępuj zgodnie z przedstawionymi najlepszymi praktykami – oto skrócona lista moich zaleceń:
- Zidentyfikuj zduplikowane treści na swoich stronach i wybierz wersję podstawową – np. dlatego, że jest to najbardziej reprezentatywna lub wartościowa strona,
- Upewnij się, że wysyłasz spójne sygnały do wyszukiwarek dotyczące Twoich kanonicznych,
- Używaj autoreferencyjnych znaczników kanonicznych,
- Upewnij się, że implementacja pliku robots.txt, tagów noindex i mapy witryny jest zgodna z Twoją kanonizacją,
- Upewnij się, że istnieje wystarczająca parzystość treści między zduplikowanymi i kanonicznymi stronami,
- Ogranicz wewnętrzne linki do zduplikowanych stron.