
Guia definitivo para Canonical Tag para SEO
Publicados: 2022-01-28As tags canônicas permitem especificar qual entre várias páginas duplicadas é a versão principal e preferida de uma página.
Qualquer site pode sofrer com problemas de conteúdo duplicado – e você pode não estar ciente de que parte do seu conteúdo é visto como duplicado.
Sem a tag canônica, você fica à mercê dos mecanismos de pesquisa – eles próprios selecionarão a versão canônica. E eles podem muito bem escolher um que você não veja como representativo do conteúdo fornecido. Isso pode afetar severamente sua visibilidade e classificações de pesquisa.
Este guia explica as características e práticas recomendadas para usar tags canônicas para resolver problemas de conteúdo duplicado em seu site.
O que são tags canônicas?
Uma tag canônica é um snippet de código que indica a versão principal (canônica) de uma página quando existe mais de uma versão dessa página.
Usando a tag canônica, você pode informar aos mecanismos de pesquisa qual URL deve ser indexado e aparecer nos resultados da pesquisa.
A técnica mais comum para implementar tags canônicas é adicionar o seguinte snippet de código ao HTML de uma página:
<link rel=“canonical” href=“https://example.com/sample-page/” />O código significa que a página canônica está localizada na URL especificada.
As tags canônicas são usadas para resolver problemas de conteúdo duplicado – mas qual conteúdo os mecanismos de pesquisa consideram duplicado e como eles o tratam?
Motores de busca e conteúdo duplicado
Os problemas com conteúdo duplicado surgem do simples fato de que os rastreadores dos mecanismos de pesquisa analisam as páginas de maneira diferente dos usuários.
Para um rastreador de mecanismo de pesquisa, cada um dos seguintes URLs é diferente:
- http://site.com
- https://site.com
- https://site.com/index.php
- http://site.com/index.php
- http://www.site.com
Enquanto um usuário presta atenção ao conteúdo de uma página, os rastreadores percebem cada endereço de URL como uma entidade separada, mesmo quando várias páginas têm conteúdo idêntico.
Problemas de conteúdo duplicado tendem a ser particularmente graves para sites de comércio eletrônico, mas não se limitam a eles. Muitos sites modernos adicionam automaticamente tags e parâmetros a URLs, por exemplo, para classificar ou filtrar páginas, e geralmente utilizam vários caminhos que levam ao mesmo conteúdo.
Várias versões de seus URLs também podem existir se você usar estruturas de URL diferentes – por exemplo, seus URLs vêm como www e não www, com e sem barras à direita, com protocolos HTTP e HTTPS e em quaisquer outros formatos.
Isso pode levar a conteúdo duplicado, que os mecanismos de pesquisa relutam em indexar.
Especificamente, quando os mecanismos de pesquisa encontram conteúdo duplicado, eles lutam para decidir:
- Qual página deve ser indexada,
- Qual página deve ser classificada para palavras-chave relevantes e
- Se eles devem consolidar os sinais de classificação em um URL ou dividi-los entre várias páginas.
Embora os mecanismos de pesquisa possam desduplicar páginas para fins de classificação, é arriscado deixá-los escolher o URL canônico – eles podem selecionar uma página que não seja a versão mais representativa do seu conteúdo.
Como o Google escolhe páginas canônicas?
É importante observar que o Googlebot nem sempre seguirá suas tags canônicas, pois elas servem apenas como sugestões de como um determinado URL deve ser tratado.
O Google analisa muitos outros fatores na página ao escolher a versão canônica.
Esses fatores incluem, entre outros:
- Redirecionamentos ,
- Links internos e externos,
- Mapas do site ,
- Estrutura de URL limpa,
- O uso do protocolo HTTPS.
Você pode verificar se o Google respeitou sua tag canônica ou selecionou uma diferente usando a ferramenta de inspeção de URL .
O Google usa as páginas canônicas como as principais fontes para avaliar conteúdo e qualidade. Um resultado da Pesquisa Google geralmente aponta para a página canônica, a menos que uma das duplicatas seja explicitamente mais adequada para um usuário. Por exemplo, o resultado da pesquisa provavelmente apontará para a página móvel se o usuário estiver em um dispositivo móvel, mesmo se a página para computador estiver marcada como canônica.fonte: documentação do Google
Assista a este vídeo que explica como o Google escolhe URLs canônicos.
Quando você deve usar tags canônicas?
Não se esqueça de que simplesmente adicionar tags canônicas não resolverá todos os problemas com conteúdo duplicado ou fino.
Seu principal objetivo deve ser eliminar os principais problemas que causam esses problemas. Concentre-se em analisar se você pode remover ou melhorar o conteúdo em páginas duplicadas para torná-lo mais exclusivo e talvez fornecer mais valor ao usuário.
No entanto, marcar com precisão suas páginas com tags canônicas é um passo à frente para lidar com conteúdo duplicado.
Vamos analisar como você pode se beneficiar das tags canônicas e quando usá-las.
Os benefícios de usar tags canônicas
Ao adicionar tags canônicas, você pode:
Especifique qual página deve aparecer nos resultados da pesquisa
Os mecanismos de pesquisa visam fornecer a melhor experiência do usuário – é por isso que raramente mostram mais de uma versão do mesmo conteúdo nos resultados de pesquisa.
As tags canônicas oferecem a chance de aprimorar a visibilidade de pesquisa da versão de página mais representativa, o que pode aumentar o tráfego orgânico para esta página e se traduzir em benefícios comerciais.
Consolide os sinais de classificação para páginas duplicadas
Outros sites podem ter links para diferentes versões duplicadas de suas páginas, diluindo os sinais que os mecanismos de pesquisa consideram durante a classificação.
Ao usar uma tag canônica, você informa aos mecanismos de pesquisa que os sinais de classificação de URLs duplicados devem fluir para a página canônica.
Desencorajar o rastreamento de páginas duplicadas
Se você implementar tags canônicas, é menos provável que os mecanismos de pesquisa continuem rastreando as páginas canônicas sabendo que são cópias.
Ao mesmo tempo, a versão canônica deve ser rastreada com mais regularidade.
Esta é uma oportunidade para que suas páginas canônicas sejam rastreadas com mais eficiência, o que pode afetar positivamente o status de indexação do seu site .
Tipos de conteúdo para marcar com tags canônicas
Vamos analisar o conteúdo específico para o qual você deve selecionar uma página canônica.
Os tipos e aspectos de conteúdo a seguir geralmente não agregam valor ao seu site e podem resultar em quantidades maiores de conteúdo duplicado.
Conteúdo distribuído
Distribuição de conteúdo significa que um conteúdo foi republicado em outro domínio.
A implementação de uma tag canônica pode ajudar a atribuir a propriedade da peça ao editor original.
Filtragem e classificação de produtos
As opções de filtragem e classificação, típicas de sites de comércio eletrônico, geralmente utilizam strings de consulta que são adicionadas a URLs – isso pode criar grandes quantidades de conteúdo duplicado. A Canonicalização de filtragem e classificação de páginas ajudará sua versão canônica a ter uma classificação mais alta e impedirá que os mecanismos de pesquisa rastreiem conteúdo duplicado desnecessariamente,
Parâmetros redundantes em URLs
Os parâmetros podem ser redundantes para uma página se não forem usados para rastreamento, não alterarem o conteúdo e não adicionarem informações significativas ao URL.
Em vez disso, eles podem levar a um rastreamento ineficiente do seu site.
Variantes do produto
Um produto pode vir em diferentes variantes, onde a única característica que muda é sua cor, tamanho ou qualquer outro atributo aplicável. A canonização pode ajudá-lo a selecionar a principal variante do produto.
No entanto, considere se o produto permanece o mesmo. Por exemplo, no nicho de tecnologia, diferentes variantes de produtos, como smartphones, podem conter outras funcionalidades e, portanto, devem aparecer nos resultados de pesquisa.
Parâmetros de acompanhamento e IDs de sessão
Os parâmetros de rastreamento podem rastrear uma campanha ou jornada do usuário e não alteram o conteúdo de uma página, portanto, também devem ser canonizados.
Como as tags canônicas se comparam às tags noindex e aos redirecionamentos 301
Você pode estar se perguntando como as tags canônicas se comparam a outras soluções que podem afetar como os mecanismos de pesquisa indexam as páginas e se elas as indexam.
Vamos comparar as características e os casos de uso de SEO de tags canônicas, tags noindex e redirecionamentos 301.
Como usar tags canônicas x tags noindex
As tags Noindex são usadas para excluir páginas do índice, não para gerenciar qual página deve ser escolhida como canônica.
Você nunca deve usar a tag noindex para impedir que os mecanismos de pesquisa selecionem uma página canônica.
As páginas canonizadas geralmente consolidam os sinais de classificação em um URL, ao contrário das tags noindex – isso é causado pelo Google tratando as tags noindex e follow de longo prazo como noindex, nofollow .
A regra geral é que uma página não deve ser não indexada e canonizada. Por exemplo, páginas canonizadas para URLs não indexados serão removidas do índice.
John Mueller esclareceu durante o SEO Office Hours que não há risco de uma página noindexed e canonicalizada transferir o noindex para seu destino canônico, o que posteriormente removeria os dois endereços do índice.
No entanto, usar tags noindex e canonical envia sinais mistos para o Google. Isso significa que o Google pode interpretar as tags como quiser, e o resultado pode ser indesejado para você.
Como usar tags canônicas versus redirecionamentos 301
Os mecanismos de pesquisa e os usuários percebem as tags canônicas e os redirecionamentos 301 de maneira muito diferente.
Se você usar um redirecionamento 301, os usuários serão direcionados automaticamente para a página de destino e não verão a página original. Os redirecionamentos 301 também ajudam a economizar seu orçamento de rastreamento porque limitam o número de URLs que precisam ser rastreados.
Enquanto isso, com uma tag canônica, os usuários ainda poderão visitar os dois URLs. Além disso, os URLs duplicados ainda são rastreados pelos mecanismos de pesquisa, portanto, o número de páginas rastreáveis não diminui.
Embora as tags canônicas tendam a transmitir sinais de classificação para a versão principal de uma página, os redirecionamentos 301 são uma indicação mais forte para o Google de que os sinais de classificação devem ser transferidos para o URL de destino. Isso acontece porque o Google não vê conteúdo intermitente, como acontece com as tags canônicas.
Vamos esclarecer quando um redirecionamento 301 será mais adequado do que uma tag canônica.
É melhor usar redirecionamentos 301 para consolidar URLs:
- Contendo letras maiúsculas e minúsculas,
- Com e sem barras à direita,
- protocolos HTTP ou HTTPS,
- Existente com e sem www.
Se você estiver fazendo alterações em seu conteúdo – como durante a migração do site – e seus URLs mudarem, você deve redirecionar 301 URLs herdados para os novos. Além de redirecionar, certifique-se de que o novo URL de destino tenha uma tag canônica autorreferente.

Outra situação em que os redirecionamentos 301 serão ideais é quando os produtos são acessíveis em muitos URLs.
Nesse caso, altere sua estrutura de URL para que ela não inclua o nome da categoria à qual os produtos foram atribuídos. Em seguida, redirecione 301 a URL herdada. Se alguma categoria for redundante, você poderá removê-la e redirecioná-la para páginas alternativas relevantes.
Em geral, use um redirecionamento 301 se apenas um URL ainda estiver acessível aos usuários.
Como adicionar tags canônicas a uma página
Existem dois métodos principais para especificar páginas canônicas – nos cabeçalhos HTML ou HTTP de uma página. Você pode implementá-los manualmente ou usar uma das ferramentas que podem ajudá-lo a automatizar.
Por exemplo, você pode optar por um plugin de SEO se estiver usando um CMS. Plugins com a funcionalidade para especificar páginas canônicas incluem Yoast SEO ou All in One SEO.
Se você estiver usando o Shopify , poderá definir URLs canônicos personalizados, se necessário – a configuração padrão do Shopify é adicionar URLs canônicos de auto-referência para produtos e postagens de blog.
Não importa qual método você escolha, não se esqueça de implementar apenas tags canônicas em um lugar – não use esses métodos simultaneamente. Se o Google descobrir várias declarações da tag canônica, provavelmente ignorará todas elas.
Tag HTML
Adicionar uma tag canônica em seu HTML é a maneira mais comum de implementá-la.
Adicione o seguinte código à seção <head> de uma página duplicada do HTML e cole o URL da versão canônica:
<link rel="canonical" href="https://example.com" />Esse método funciona apenas para páginas HTML, portanto, use o cabeçalho HTTP se desejar canonizar outros tipos de arquivos.
Cabeçalho HTTP
Você pode implementar o cabeçalho HTTP “rel=canonical” para indicar a versão canônica de um URL:
Link: <http://www.example.com/downloads/white-paper.pdf>; rel="canônico"
Use o cabeçalho HTTP para especificar um canônico para documentos não HTML, como arquivos PDF.
Para usar esta solução, você precisa acessar o servidor do seu site. Também requer algumas habilidades técnicas, pois esse método é mais propenso a erros e difícil de implementar do que o HTML.
Práticas recomendadas para usar tags canônicas
Seguir as práticas recomendadas de tags canônicas ajuda a mitigar o risco de os mecanismos de pesquisa verem a versão errada da página como canônica.
Aqui está minha lista de recomendações para tags canônicas:
Usar URLs absolutos
Em teoria, o Google deve reconhecer URLs relativos e absolutos. No entanto, as versões absolutas de URLs são menos propensas a erros e mais fáceis de depurar.
Você pode usar qualquer um, mas eu recomendo usar URLs absolutos para ter certeza de que eles são interpretados corretamente.
— johnmu.xml (pessoal) (@JohnMu) 24 de outubro de 2018
Em outras palavras, use um URL completo em uma tag canônica:
<link rel=“canonical” href=“https://example.com/sample-page/” />E evite incluir apenas o caminho da URL:
<link rel=“canonical” href="/sample-page/” />Use tags canônicas autorreferenciais
Embora não seja obrigatório, é recomendável usar tags canônicas que apontam para as páginas em que estão localizadas.
É essencial implementá-lo se você utilizar parâmetros para rastrear campanhas – isso deve tornar todos os URLs com um parâmetro de campanha canonizado para o URL estático por padrão e impedir que sejam indexados.
Aqui está o que John Mueller, do Google, disse durante o SEO Office Hours sobre canônicos auto-referenciais:
Não é fundamental ter uma tag canônica de auto-referência em uma página, mas torna mais fácil para nós escolher exatamente o URL que você deseja que seja escolhido como canônico.Usamos vários fatores para escolher um URL canônico, e o rel=canonical desempenha um papel nisso.
Então, em particular, coisas como parâmetros de URL, ou se o URL estiver marcado de alguma maneira específica - talvez você tenha links para essa página que estão marcados para análise, por exemplo - então pode acontecer de escolhermos esse URL marcado como um canônico […]
fonte: John Mueller
Envie sinais claros para os motores de busca
O envio de sinais claros consiste em especificar apenas um canônico por página.
Evite especificar uma URL como canônica e, ao mesmo tempo, redirecioná-la para um destino diferente.
Outro caso diz respeito a canônicos adicionados usando JavaScript.
Se nenhuma página canônica for especificada no HTML e uma tag canônica for adicionada com JavaScript, o Google deverá respeitá-la durante a renderização. Mas, se um canônico for definido no HTML e o JavaScript o alterar, você estará enviando sinais mistos para o Google.
O envio de sinais mistos pode resultar em mecanismos de pesquisa interpretando incorretamente seus canônicos ou escolhendo a versão errada como canônica.
Certifique-se de usar o URL correto ao vincular internamente
Ao colocar links internos em seu site, certifique-se de vincular ao URL canônico em vez das duplicatas.
Conforme mencionado, o Google pode não respeitar o canônico se os sinais mais fortes apontarem para outro URL . Um desses sinais pode ser o aumento do link para um URL duplicado que o Google pode ver como a versão principal.
Não aponte a tag canônica para a primeira página da paginação
É um erro comum apontar apenas para indexar a primeira página da paginação. Você pode querer usá-lo para impedir que os usuários acessem as páginas subsequentes dos resultados da pesquisa, mas é a abordagem errada. Os mecanismos de pesquisa podem ignorar a canonização, pois essas páginas geralmente não são duplicadas. Mas se respeitarem as tags canônicas, a paginação poderá ser canonizada.
Se a paginação contiver links para produtos exclusivos e não houver outro link entre as páginas do produto, os links para as páginas do produto na paginação poderão ser desconsiderados. Em outras palavras, as páginas de produtos indexáveis não terão links internos de outras páginas.
Em vez disso, as páginas paginadas devem ter tags canônicas autorreferenciais. O conteúdo dessas páginas não é idêntico e, ao incluir tags autorreferenciais, você informa aos mecanismos de pesquisa que cada página é única. Se você não quiser que essas páginas sejam indexadas, use tags noindex.
Aponte para a versão desktop de uma página
Se seu site para celular estiver localizado em um subdomínio, a tag canônica deve apontar para a versão para computador da página.
Identificar uma página canônica ao usar tags hreflang
Embora o Google não visualize versões diferentes do mesmo conteúdo traduzido para outros idiomas como duplicado, você ainda deve usar tags canônicas.
Diga aos mecanismos de pesquisa qual é a página canônica no mesmo idioma ou no melhor idioma substituto. As variantes de idioma devem ser autocanônicas.
Evitar problemas de orçamento de rastreamento
Os URLs canônicos ainda podem usar seu orçamento de rastreamento, mesmo se as tags canônicas forem implementadas corretamente.
Embora a taxa de rastreamento de URLs canonizados deva diminuir com o tempo, os mecanismos de pesquisa ainda podem se concentrar em buscar as duplicatas em vez de rastrear e indexar novas páginas.
Verifique os registros do seu servidor para ver como o Googlebot se comporta em seu site e identificar possíveis problemas de rastreamento.
Para mitigar problemas de orçamento de rastreamento, geralmente você deve:
- Reduza os links internos para versões de URL não canônicas,
- Use a ferramenta Parâmetro de URL no Google Search Console para instruir o Googlebot a rastrear as versões estáticas dos URLs.
Mas lembre-se de que problemas de orçamento de rastreamento ocorrem em sites muito grandes – o Google afirma que a maioria dos sites nunca precisará se preocupar com isso.
Eu recomendo que você leia o artigo do Google sobre erros comuns ao implementar “rel=canonical” para saber quais outras coisas evitar.
Como auditar tags canônicas
Para que suas tags canônicas sejam selecionadas, você precisa garantir que uma página tenha uma tag canônica que aponte para a página certa.
Você também precisa verificar se a página é rastreável e indexável – ela não deve ser bloqueada por robots.txt ou marcada com uma tag noindex.
Abaixo estão algumas maneiras úteis de auditar suas tags canônicas.
Como usar o Google Search Console para analisar tags canônicas
O Google Search Console contém algumas ferramentas úteis para auditar suas páginas canônicas: o relatório de cobertura de índice e a ferramenta de inspeção de URL.
O relatório de cobertura do índice
O relatório Cobertura de índice no Google Search Console é uma fonte valiosa de informações sobre sua condição de indexação – quais URLs são indexadas e quais não são indexáveis e por quê.
Para analisar os canônicos do seu site, navegue até a categoria Excluídos.
É aí que você pode encontrar alguns status relevantes para você:
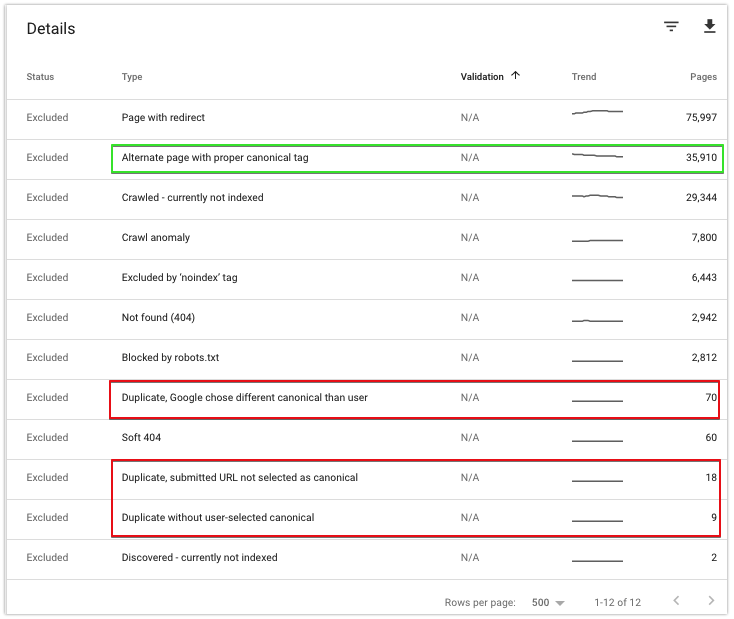
Página alternativa com tag canônica adequada
Os URLs marcados com esse status indicam páginas para as quais o Google respeita sua canonização para um URL.
Você pode esperar que o número desses URLs aumente se você canonizou recentemente algumas páginas. Você pode usar esta seção do relatório do Google para verificar se o Google não está rastreando as duplicatas mais do que o necessário.
Caso contrário, esses URLs não requerem sua atenção.
Duplicado, o Google escolheu um canônico diferente do usuário
O status indica que o Google ignorou seu canônico autorreferente ou canonização para outro canônico. Isso pode ocorrer se os sinais mais fortes estiverem apontando para outros URLs – por exemplo, pode haver um aumento de links internos para outras páginas.
Esse problema também pode apontar para problemas de conteúdo. Por exemplo, é possível que a parte exclusiva do conteúdo não tenha sido carregada ou você escolheu a página errada para canonizar, por exemplo, porque não há paridade de conteúdo suficiente entre páginas duplicadas e canônicas.
Se você não conseguir determinar como resolver esse problema, vá direto para o nosso guia sobre como corrigir a duplicata, o Google escolheu um problema canônico diferente do usuário.
URL enviado duplicado não selecionado como canônico
Isso significa que o Google encontrou páginas em seus sitemaps XML que considera duplicadas. Percorra o mapa do site e certifique-se de que todos os URLs encontrados nele sejam indexados.
Duplicar sem canônico selecionado pelo usuário
Esses são URLs duplicados sem nenhum URL rel=canonical especificado – determine as páginas canônicas mais adequadas para eles e adicione-as.
Ferramenta de inspeção de URL
Você pode usar a ferramenta de inspeção de URL para investigar melhor como o Googlebot visualiza os URLs excluídos do índice.
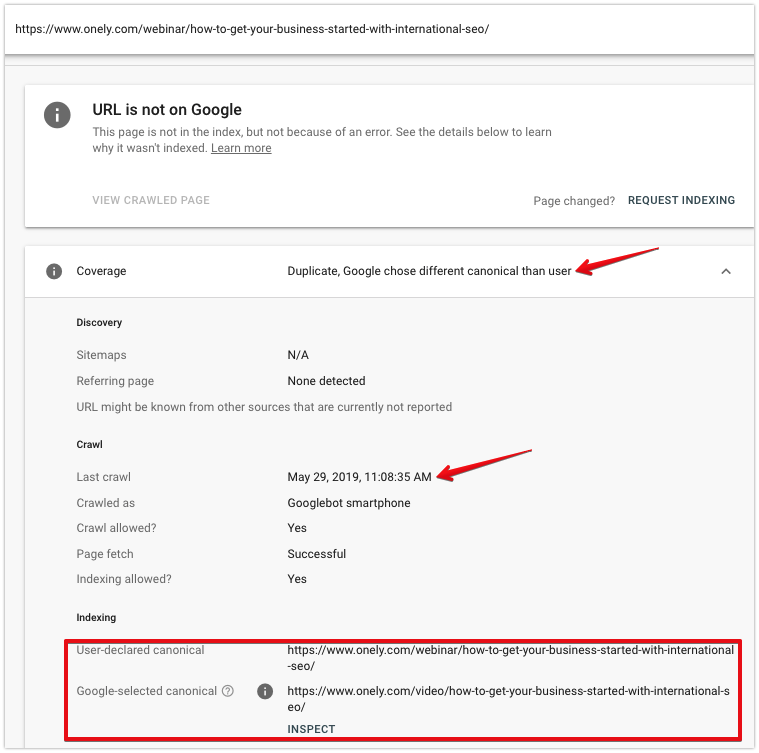
Ao inspecionar uma página, observe:
- Data do último rastreamento – última vez que o Googlebot buscou a página. Se uma tag canônica foi adicionada recentemente, é provável que o Googlebot não tenha rastreado o URL desde então.
- Canônico declarado pelo usuário – Isso deve mostrar o URL que você selecionou – verifique se é o URL correto.
- Canônico selecionado pelo Google – Se o Google escolheu uma página canônica diferente, você pode ver qual URL foi selecionado.
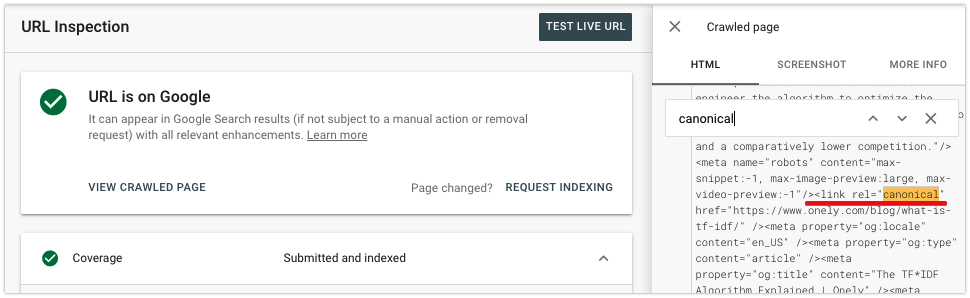
Você também pode verificar se a tag canônica foi adicionada corretamente. Clique em Exibir página rastreada para examinar o conteúdo renderizado e procurar a tag canônica na seção <head>.
Na guia Mais informações, você pode verificar o cabeçalho de resposta HTTP que o Googlebot recebeu.
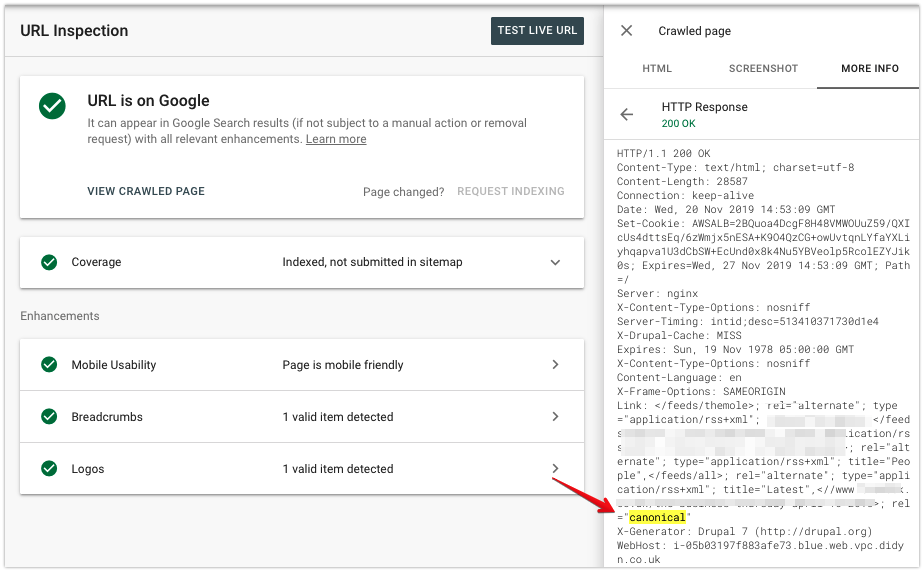
Certifique-se de que esteja alinhado com a configuração desejada, mesmo se você estiver usando rel=canonical no HTML de uma página.
Executando um rastreamento de site para auditar tags canônicas
Um rastreamento de site pode ajudar você a descobrir problemas com suas tags canônicas.
Os rastreadores de sites fornecem detalhes sobre a proporção canônica versus não canônica. Eles irão alertá-lo sobre quaisquer canônicos incorretos, como páginas removidas/ausentes (HTTP 4xx), erros de servidor (HTTP 5xx) ou redirecionamentos (HTTP 3xx) em tags canônicos. Geralmente, você deve investigar qualquer código de status diferente de HTTP 200.
Siga este guia para aprender como auditar seus canônicos usando o SEO Spider do Screaming Frog.
Empacotando
A implementação de tags canônicas oferece a possibilidade de informar aos mecanismos de pesquisa qual URL representa a melhor versão de cada conteúdo. Você pode então influenciar quais páginas aparecem nos resultados de pesquisa – e quais são tratadas como secundárias.
Canonicals são meros sinais que os motores de busca não precisam respeitar. Mas, em muitos casos, você pode aumentar as chances de suas tags canônicas serem respeitadas. Como?
Siga as práticas recomendadas descritas – aqui está uma lista condensada das minhas recomendações:
- Identifique conteúdo duplicado em suas páginas e escolha qual versão da página deve ser a principal – por exemplo, porque é a página mais representativa ou valiosa,
- Certifique-se de enviar sinais consistentes aos mecanismos de pesquisa sobre seus canônicos,
- Use tags canônicas autorreferenciais,
- Verifique se a implementação do arquivo robots.txt, as tags noindex e o mapa do site estão alinhados com sua canonização,
- Certifique-se de que haja paridade de conteúdo suficiente entre páginas duplicadas e canônicas,
- Limite os links internos às páginas duplicadas.