
Guía definitiva de etiquetas canónicas para SEO
Publicado: 2022-01-28Las etiquetas canónicas le permiten especificar cuál de las múltiples páginas duplicadas es la versión principal y preferida de una página.
Cualquier sitio web puede sufrir problemas de contenido duplicado , y es posible que no sepa que parte de su contenido se ve como duplicado.
Sin la etiqueta canónica, estás a merced de los motores de búsqueda: ellos mismos seleccionarán la versión canónica. Y es muy posible que elijan uno que usted no considere representativo del contenido dado. Esto puede afectar gravemente la visibilidad y las clasificaciones de su búsqueda.
Esta guía explica las características y las mejores prácticas para usar etiquetas canónicas para abordar problemas de contenido duplicado en su sitio web.
¿Qué son las etiquetas canónicas?
Una etiqueta canónica es un fragmento de código que indica la versión principal (canónica) de una página cuando existe más de una versión de esa página.
Con la etiqueta canónica, puede decirle a los motores de búsqueda qué URL debe indexarse y aparecer en los resultados de búsqueda.
La técnica más común para implementar etiquetas canónicas es agregar el siguiente fragmento de código al HTML de una página:
<enlace rel=“canonical” href=“https://example.com/página-de-muestra/” />El código significa que la página canónica se encuentra en la URL especificada.
Las etiquetas canónicas se utilizan para abordar problemas de contenido duplicado, pero ¿qué contenido consideran duplicados los motores de búsqueda y cómo lo tratan?
Motores de búsqueda y contenido duplicado
Los problemas con el contenido duplicado surgen del simple hecho de que los rastreadores de los motores de búsqueda miran las páginas de manera diferente a los usuarios.
Para un rastreador de motor de búsqueda, cada una de las siguientes URL es diferente:
- http://sitio.com
- https://sitio.com
- https://sitio.com/index.php
- http://sitio.com/index.php
- http://www.sitio.com
Mientras que un usuario presta atención al contenido de una página, los rastreadores perciben cada dirección URL como una entidad separada, incluso cuando varias páginas tienen contenido idéntico.
Los problemas de contenido duplicado tienden a ser particularmente graves para los sitios de comercio electrónico, pero no se limitan a ellos. Muchos sitios web modernos agregan automáticamente etiquetas y parámetros a las URL, por ejemplo, para clasificar o filtrar páginas, y suelen utilizar numerosas rutas que conducen al mismo contenido.
También pueden existir múltiples versiones de sus URL si usa diferentes estructuras de URL ; por ejemplo, sus URL vienen como www y no www, con y sin barras inclinadas, con protocolos HTTP y HTTPS, y en cualquier otro formato.
Esto puede dar lugar a contenido duplicado, que los motores de búsqueda son reacios a indexar.
Específicamente, cuando los motores de búsqueda encuentran contenido duplicado, se esfuerzan por decidir:
- Qué página debe ser indexada,
- Qué página debería posicionarse para palabras clave relevantes, y
- Si deben consolidar las señales de clasificación en una URL o dividirlas entre varias páginas.
Aunque los motores de búsqueda pueden deduplicar páginas con fines de clasificación, es arriesgado permitirles elegir la URL canónica; pueden seleccionar una página que no sea la versión más representativa de su contenido.
¿Cómo elige Google las páginas canónicas?
Es importante tener en cuenta que Googlebot no siempre seguirá sus etiquetas canónicas, ya que solo sirven como sugerencias sobre cómo se debe tratar una URL determinada.
Google analiza muchos otros factores en la página al elegir la versión canónica.
Estos factores incluyen, entre otros:
- Redirecciones ,
- Enlace interno y externo,
- mapas del sitio ,
- Estructura de URL limpia,
- El uso del protocolo HTTPS.
Puedes verificar si Google respetó tu etiqueta canónica o seleccionó una diferente utilizando la herramienta de Inspección de URL .
Google utiliza las páginas canónicas como fuente principal para evaluar el contenido y la calidad. Un resultado de búsqueda de Google generalmente apunta a la página canónica, a menos que uno de los duplicados sea explícitamente más adecuado para un usuario. Por ejemplo, el resultado de la búsqueda probablemente apuntará a la página móvil si el usuario está en un dispositivo móvil, incluso si la página de escritorio está marcada como canónica.fuente: documentación de Google
Mire este video que explica cómo Google elige las URL canónicas.
¿Cuándo deberías usar etiquetas canónicas?
No olvide que simplemente agregar etiquetas canónicas no solucionará todos los problemas con contenido duplicado o delgado.
Su objetivo principal debe ser eliminar los problemas centrales que causan estos problemas. Concéntrese en analizar si puede eliminar o mejorar el contenido de las páginas duplicadas para que sea más único y quizás proporcione más valor al usuario.
No obstante, marcar con precisión sus páginas con etiquetas canónicas es un paso adelante para lidiar con el contenido duplicado.
Analicemos cómo puede beneficiarse de las etiquetas canónicas y cuándo usarlas.
Los beneficios de usar etiquetas canónicas
Al agregar etiquetas canónicas, puede:
Especificar qué página debe aparecer en los resultados de búsqueda
Los motores de búsqueda tienen como objetivo brindar la mejor experiencia de usuario; por eso , rara vez mostrarán más de una versión del mismo contenido en los resultados de búsqueda.
Las etiquetas canónicas le brindan la oportunidad de mejorar la visibilidad de búsqueda de la versión de página más representativa, lo que puede aumentar el tráfico orgánico a esta página y traducirse en beneficios comerciales.
Consolide las señales de clasificación para páginas duplicadas
Otros sitios pueden vincularse a diferentes versiones duplicadas de sus páginas, diluyendo las señales que los motores de búsqueda consideran durante la clasificación.
Cuando usa una etiqueta canónica, le dice a los motores de búsqueda que las señales de clasificación de las URL duplicadas deben fluir a la página canónica.
Evitar el rastreo de páginas duplicadas
Si implementa etiquetas canónicas, es menos probable que los motores de búsqueda sigan rastreando las páginas canonizadas sabiendo que son copias.
Al mismo tiempo, la versión canónica debería rastrearse con más frecuencia.
Esta es una oportunidad para que sus páginas canónicas se rastreen de manera más eficiente, lo que puede afectar positivamente el estado de indexación de su sitio web .
Tipos de contenido para marcar con etiquetas canónicas
Repasemos el contenido específico para el que debe seleccionar una página canónica.
Los siguientes tipos de contenido y aspectos generalmente no agregan valor a su sitio web y pueden generar una mayor cantidad de contenido duplicado.
contenido sindicado
La sindicación de contenido significa que una parte del contenido se volvió a publicar en otro dominio.
La implementación de una etiqueta canónica puede ayudar a atribuir la propiedad de la pieza al editor original.
Filtrado y clasificación de productos.
Las opciones de filtrado y clasificación, típicas de los sitios de comercio electrónico, generalmente utilizan cadenas de consulta que se agregan a las URL; esto puede crear cantidades masivas de contenido duplicado. La canonicalización de las páginas de filtrado y clasificación ayudará a que su versión canónica se clasifique más alto y evitará que los motores de búsqueda rastreen innecesariamente contenido duplicado.
Parámetros redundantes en URL
Los parámetros pueden ser redundantes para una página si no se usan para el seguimiento, no cambian el contenido y no agregan información significativa a la URL.
En cambio, pueden conducir a un rastreo ineficiente de su sitio.
Variantes del producto
Un producto puede venir en diferentes variantes, donde la única característica que cambia es su color, tamaño o cualquier otro atributo aplicable. La canonicalización puede ayudarlo a seleccionar la variante principal del producto.
Sin embargo, considere si el producto sigue siendo el mismo. Por ejemplo, en el nicho tecnológico, diferentes variantes de productos, como los teléfonos inteligentes, en realidad pueden contener otras funcionalidades y, por lo tanto, deberían aparecer en los resultados de búsqueda.
Parámetros de seguimiento e ID de sesión
Los parámetros de seguimiento pueden rastrear una campaña o el viaje del usuario, y no cambian el contenido de una página, por lo que también deben canonicalizarse.
Cómo se comparan las etiquetas canónicas con las etiquetas sin índice y los redireccionamientos 301
Es posible que se pregunte cómo se comparan las etiquetas canónicas con otras soluciones que pueden afectar la forma en que los motores de búsqueda indexan las páginas y si las indexan en absoluto.
Comparemos las características y los casos de uso de SEO de las etiquetas canónicas, las etiquetas sin índice y las redirecciones 301.
Uso de etiquetas canónicas frente a etiquetas noindex
Las etiquetas Noindex se utilizan para excluir páginas del índice, no para administrar qué página debe elegirse como canónica.
Nunca debe usar la etiqueta noindex para evitar que los motores de búsqueda seleccionen una página canónica.
Las páginas canonicalizadas generalmente consolidan las señales de clasificación en una URL, a diferencia de las etiquetas noindex; esto se debe a que Google trata las etiquetas noindex, follow a largo plazo como noindex, nofollow .
La regla general es que una página no debe estar indexada y canonicalizada. Por ejemplo, las páginas canonicalizadas a URL no indexadas se eliminarán del índice.
John Mueller aclaró durante el horario de oficina de SEO que no hay riesgo de que una página no indexada y canonizada transfiera el noindex a su destino canónico, lo que posteriormente eliminaría ambas direcciones del índice.
Sin embargo, el uso de etiquetas canónicas y noindex envía señales contradictorias a Google. Esto significa que Google puede interpretar las etiquetas como quiera, y el resultado puede no ser el deseado para usted.
Uso de etiquetas canónicas frente a redireccionamientos 301
Los motores de búsqueda y los usuarios perciben las etiquetas canónicas y los redireccionamientos 301 de manera muy diferente.
Si usa una redirección 301, los usuarios serán llevados automáticamente a la página de destino y no verán la página original. Las redirecciones 301 también lo ayudan a ahorrar su presupuesto de rastreo porque limitan la cantidad de URL que deben rastrearse.
Mientras tanto, con una etiqueta canónica, los usuarios aún podrán visitar ambas URL. Además, los motores de búsqueda aún rastrean las URL duplicadas, por lo que la cantidad de páginas rastreables no disminuye.
Aunque las etiquetas canónicas tienden a transmitir señales de clasificación a la versión principal de una página, los redireccionamientos 301 son una indicación más fuerte para Google de que las señales de clasificación deben transferirse a la URL de destino. Esto sucede porque Google no ve contenido intermitente, como lo hace con las etiquetas canónicas.
Aclaremos cuándo una redirección 301 será más adecuada que una etiqueta canónica.
Es mejor usar redireccionamientos 301 para consolidar las URL:
- Contiene letras minúsculas y mayúsculas,
- Con y sin barras inclinadas,
- protocolos HTTP o HTTPS,
- Existente tanto con como sin www.
Si está realizando cambios en su contenido, como durante la migración del sitio , y sus URL cambian, debe redirigir 301 las URL heredadas a las nuevas. Además de redireccionar, asegúrese de que la nueva URL de destino tenga una etiqueta canónica autorreferencial.

Otra situación en la que los redireccionamientos 301 serán óptimos es cuando se puede acceder a los productos a través de muchas URL.
En este caso, cambie la estructura de su URL para que no incluya el nombre de la categoría a la que se asignaron los productos. Luego, redirija 301 la URL heredada. Si alguna categoría es redundante, puede eliminarla y redirigirla a páginas alternativas relevantes.
En general, use una redirección 301 si solo una URL debe seguir siendo accesible para los usuarios.
Cómo agregar etiquetas canónicas a una página
Hay dos métodos principales para especificar páginas canónicas: en los encabezados HTML o HTTP de una página. Puede implementarlos manualmente o usar una de las herramientas que pueden ayudarlo a automatizarlo.
Por ejemplo, puede optar por un complemento de SEO si está utilizando un CMS. Los complementos con la funcionalidad para especificar páginas canónicas incluyen Yoast SEO o All in One SEO.
Si está utilizando Shopify , puede configurar URL canónicas personalizadas si es necesario: la configuración predeterminada de Shopify es agregar URL canónicas de autorreferencia para productos y publicaciones de blog.
Independientemente del método que elija, no olvide implementar solo etiquetas canónicas en un solo lugar; no use estos métodos simultáneamente. Si Google descubre varias declaraciones de la etiqueta canónica, es probable que las ignore todas.
etiqueta HTML
Agregar una etiqueta canónica en su HTML es la forma más común de implementarlo.
Agrega el siguiente código a la sección <head> de una página duplicada del HTML y pega la URL de la versión canónica:
<enlace rel="canonical" href="https://ejemplo.com"/>Este método solo funciona para páginas HTML, así que use el encabezado HTTP si desea canonicalizar otros tipos de archivos.
Encabezado HTTP
Puede implementar el encabezado HTTP "rel=canonical" para indicar la versión canónica de una URL:
Enlace: <http://www.example.com/downloads/white-paper.pdf>; rel="canónico"
Utilice el encabezado HTTP para especificar un canónico para documentos que no sean HTML, como archivos PDF.
Para usar esta solución, necesita acceso al servidor de su sitio web. También requiere algunas habilidades técnicas, ya que este método es más propenso a errores y más difícil de implementar que el HTML.
Mejores prácticas para usar etiquetas canónicas
Seguir las mejores prácticas de etiquetas canónicas ayuda a mitigar el riesgo de que los motores de búsqueda vean la versión incorrecta de la página como canónica.
Aquí está mi lista de recomendaciones para etiquetas canónicas:
Usar URL absolutas
En teoría, Google debería reconocer tanto las URL relativas como las absolutas. Sin embargo, las versiones absolutas de URL son menos propensas a errores y más fáciles de depurar.
Puede usar cualquiera, pero recomendaría usar URL absolutas para asegurarse de que se interpreten correctamente.
– johnmu.xml (personal) (@JohnMu) 24 de octubre de 2018
En otras palabras, use una URL completa en una etiqueta canónica:
<enlace rel=“canonical” href=“https://example.com/página-de-muestra/” />Y absténgase de incluir solo la ruta de la URL:
<enlace rel=“canonical” href=”/página-de-muestra/” />Usar etiquetas canónicas autorreferenciales
Aunque no es obligatorio, se recomienda usar etiquetas canónicas que apunten a las páginas en las que se encuentran.
Es esencial implementarlo si utiliza parámetros para realizar un seguimiento de las campañas. Al hacerlo, todas las URL con un parámetro de campaña se canonizarán a la URL estática de forma predeterminada y evitarán que se indexen.
Esto es lo que dijo John Mueller de Google durante el horario de oficina de SEO con respecto a los canónicos autorreferenciales:
No es fundamental tener una etiqueta canónica de autorreferencia en una página, pero nos facilita elegir exactamente la URL que desea haber elegido como canónica.Utilizamos una serie de factores para elegir una URL canónica, y rel=canonical juega un papel en eso.
Entonces, en particular, cosas como los parámetros de la URL, o si la URL está etiquetada de alguna manera en particular (tal vez tenga enlaces que van a esa página que están etiquetados para análisis, por ejemplo), entonces podría suceder que elijamos esa URL etiquetada como una canónico […]
fuente: John Müller
Envía señales claras a los motores de búsqueda
Enviar señales claras consiste en especificar solo un canon por página.
Evita especificar una URL como canónica y, al mismo tiempo, redirigir dicha URL a un destino diferente.
Otro caso se refiere a las canónicas agregadas usando JavaScript.
Si no se especifica una página canónica en el HTML y se agrega una etiqueta canónica con JavaScript, Google debe respetarla durante la representación. Pero, si se establece un canónico en el HTML y JavaScript lo cambia, está enviando señales contradictorias a Google.
El envío de señales contradictorias puede dar lugar a que los motores de búsqueda interpreten incorrectamente sus canónicas o elijan la versión incorrecta como canónica.
Asegúrese de utilizar la URL correcta al vincular internamente
Al colocar enlaces internos en su sitio, asegúrese de vincular a la URL canónica en lugar de a los duplicados.
Como se mencionó, es posible que Google no respete el canónico si las señales más fuertes apuntan a otra URL . Una de esas señales podría aumentar la vinculación a una URL duplicada que Google puede ver como la versión maestra.
No apunte la etiqueta canónica a la primera página de la paginación
Es un error común apuntar solo a indexar la primera página de paginación. Es posible que desee usarlo para evitar que los usuarios accedan a las páginas posteriores desde los resultados de búsqueda, pero es un enfoque incorrecto. Los motores de búsqueda pueden ignorar la canonicalización ya que estas páginas generalmente no son duplicados. Pero si respetan las etiquetas canónicas, la paginación puede ser canonicalizada.
Si la paginación contiene enlaces a productos únicos y no hay ningún otro enlace entre las páginas de productos, los enlaces a las páginas de productos en la paginación pueden ignorarse. En otras palabras, las páginas de productos indexables no tendrán enlaces internos de otras páginas.
En cambio, las páginas paginadas deben tener etiquetas canónicas autorreferenciales. El contenido de estas páginas no es idéntico y, al incluir etiquetas autorreferenciales, le dice a los motores de búsqueda que cada página es única. Si no desea que estas páginas se indexen, use etiquetas noindex.
Apunta a la versión de escritorio de una página
Si su sitio móvil está ubicado en un subdominio, la etiqueta canónica debe apuntar a la versión de escritorio de la página.
Identifica una página canónica cuando usas etiquetas hreflang
Aunque Google no ve las diferentes versiones del mismo contenido traducido a otros idiomas como duplicado, aún debe usar etiquetas canónicas.
Dile a los motores de búsqueda cuál es la página canónica en el mismo idioma o en el mejor idioma sustituto. Las variantes del idioma deben ser autocanónicas.
Evitar problemas con el presupuesto de rastreo
Las URL canónicas aún pueden consumir su presupuesto de rastreo, incluso si las etiquetas canónicas se implementan correctamente.
Aunque la tasa de rastreo de las URL canonicalizadas debería disminuir con el tiempo, los motores de búsqueda aún pueden enfocarse en obtener los duplicados en lugar de rastrear e indexar nuevas páginas.
Verifique los registros de su servidor para ver cómo se comporta Googlebot en su sitio e identificar posibles problemas de rastreo.
Para mitigar los problemas de presupuesto de rastreo, generalmente debe hacer lo siguiente:
- Reducir los enlaces internos a versiones de URL no canónicas,
- Utilice la herramienta de parámetros de URL en Google Search Console para indicarle a Googlebot que rastree las versiones estáticas de las URL.
Pero tenga en cuenta que los problemas de presupuesto de rastreo ocurren en sitios muy grandes : Google afirma que la mayoría de los sitios nunca tendrán que preocuparse por eso.
Le recomiendo que lea el artículo de Google sobre errores comunes al implementar "rel=canonical" para saber qué otras cosas debe evitar.
Cómo auditar etiquetas canónicas
Para que se recojan sus etiquetas canónicas, debe asegurarse de que una página tenga una etiqueta canónica que apunte a la página correcta.
También debe verificar si la página se puede rastrear e indexar; no debe estar bloqueada por robots.txt o marcada con una etiqueta sin índice.
A continuación se muestran algunas formas útiles de auditar sus etiquetas canónicas.
Cómo usar Google Search Console para analizar etiquetas canónicas
Google Search Console contiene algunas herramientas útiles para auditar sus páginas canónicas: el informe de cobertura del índice y la herramienta de inspección de URL.
El informe de cobertura del índice
El informe de cobertura de índices en Google Search Console es una valiosa fuente de información sobre su condición de indexación: qué URL están indexadas y cuáles no, y por qué.
Para analizar los canónicos de su sitio, vaya a la categoría Excluidos.
Ahí es donde puede encontrar algunos estados que son relevantes para usted:
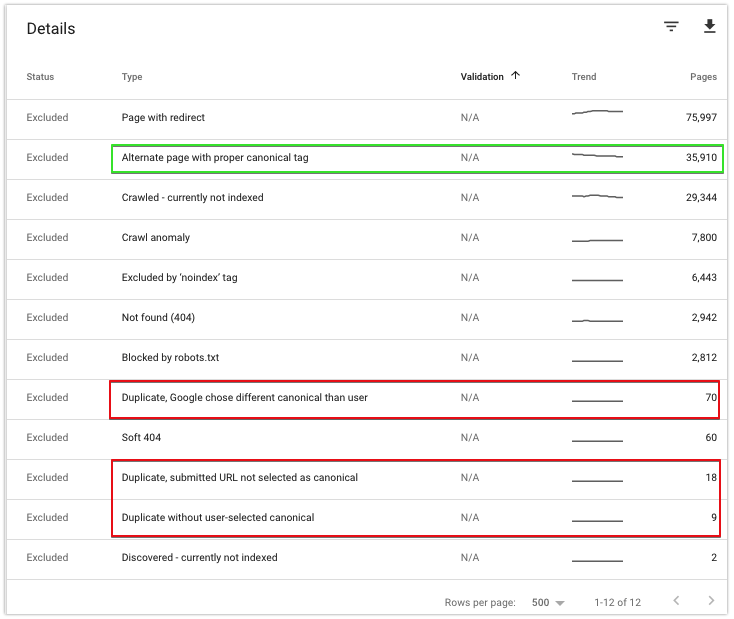
Página alternativa con la etiqueta canónica adecuada
Las URL marcadas con este estado indican páginas para las que Google respeta su canonicalización a una URL.
Puede esperar que la cantidad de estas URL aumente si canonicalizó algunas páginas recientemente. Puede usar esta sección del informe de Google para verificar si Google no está rastreando los duplicados más de lo necesario.
De lo contrario, estas URL no requieren su atención.
Duplicado, Google eligió un canon diferente al usuario
El estado indica que Google ignoró su canonical autorreferencial o canonicalización a otro canonical. Esto puede ocurrir si las señales más fuertes apuntan a otras URL; por ejemplo, puede haber un aumento de los enlaces internos a otras páginas.
Este problema también puede indicar problemas de contenido. Por ejemplo, es posible que la parte única del contenido no se haya cargado o que haya elegido la página incorrecta para canonicalizar, por ejemplo, porque no hay suficiente paridad de contenido entre las páginas duplicadas y las canónicas.
Si no puede determinar cómo resolver este problema, vaya directamente a nuestra guía sobre cómo solucionar el Duplicado, Google eligió un problema canónico diferente al del usuario.
URL enviada duplicada no seleccionada como canónica
Significa que Google encontró páginas en sus mapas de sitio XML que considera duplicados. Revise su mapa del sitio y asegúrese de que todas las URL que se encuentran en él estén indexadas.
Duplicar sin canónico seleccionado por el usuario
Estas son URL duplicadas sin ninguna URL rel=canonical especificada: determine las páginas canónicas más adecuadas para ellas y agréguelas.
Herramienta de inspección de URL
Puede usar la herramienta de inspección de URL para investigar más a fondo cómo Googlebot ve las URL excluidas del índice.
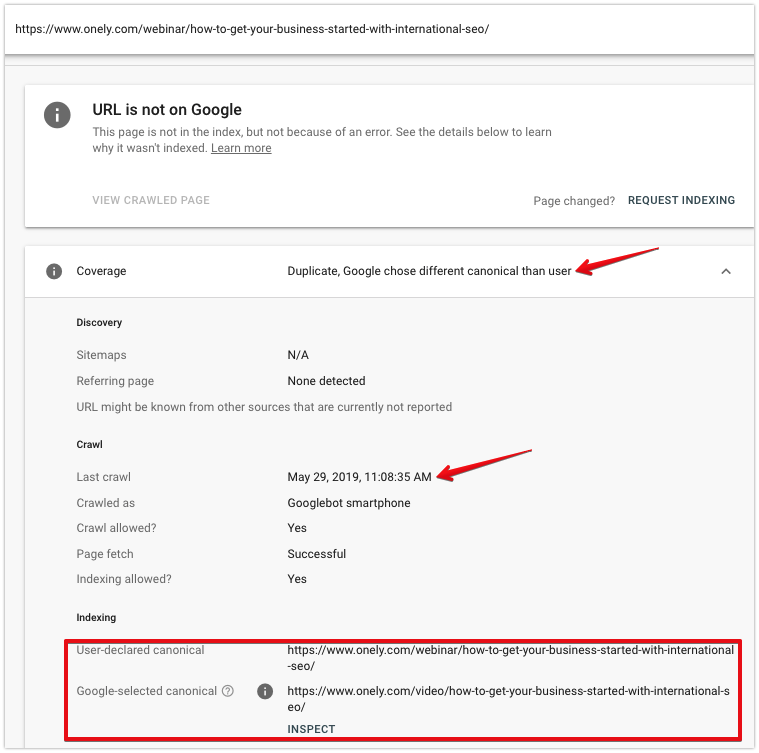
Al inspeccionar una página, mire:
- Fecha del último rastreo : la última vez que Googlebot buscó la página. Si se agregó una etiqueta canónica recientemente, es probable que Googlebot no haya rastreado la URL desde entonces.
- Canónica declarada por el usuario : debería mostrar la URL que seleccionó; verifique si es la URL correcta.
- Canónico seleccionado por Google : si Google eligió una página canónica diferente, puede ver qué URL se seleccionó.
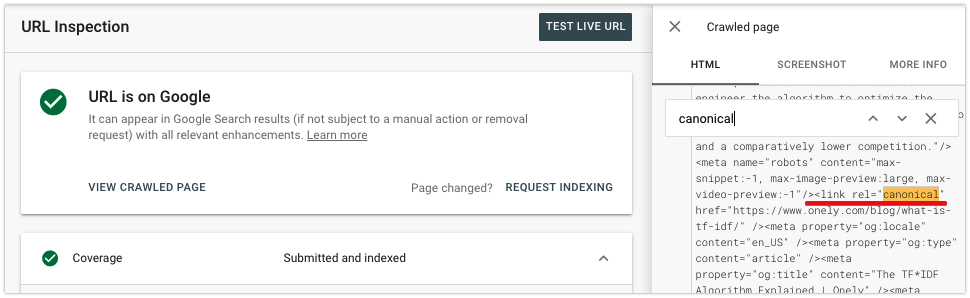
También puede verificar si la etiqueta canónica se agregó correctamente. Haga clic en Ver página rastreada para examinar el contenido renderizado y buscar la etiqueta canónica en la sección <head>.
En la pestaña Más información, puede consultar el encabezado de respuesta HTTP que recibió Googlebot.
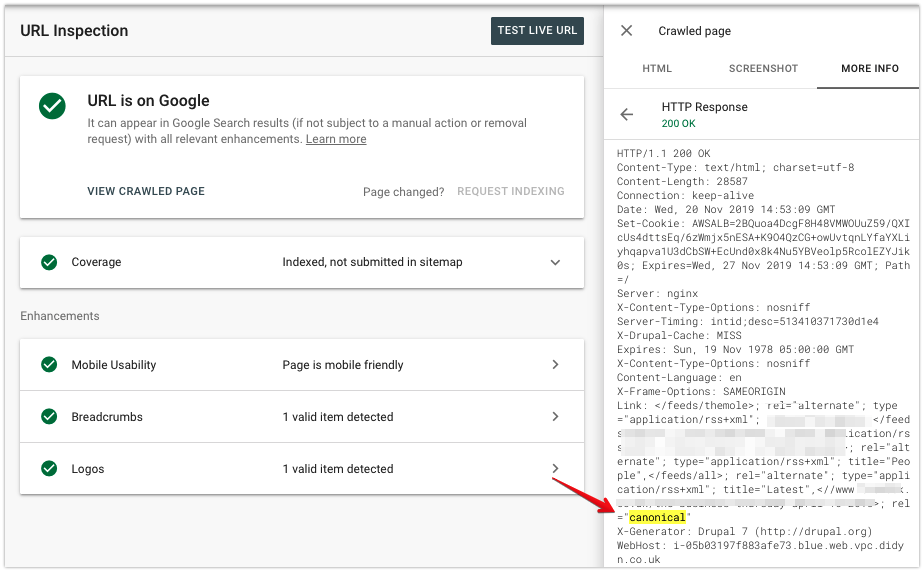
Asegúrese de que se alinee con la configuración deseada, incluso si está utilizando rel=canonical en el HTML de una página.
Realizar un rastreo del sitio para auditar las etiquetas canónicas
Un rastreo del sitio web puede ayudarlo a descubrir problemas con sus etiquetas canónicas.
Los rastreadores de sitios web le brindan detalles sobre la relación canónica frente a la no canónica. Le avisarán de cualquier canónico incorrecto, como páginas eliminadas o faltantes (HTTP 4xx), errores del servidor (HTTP 5xx) o redirecciones (HTTP 3xx) en etiquetas canónicas. En general, debe investigar cualquier código de estado que no sea HTTP 200.
Siga esta guía para aprender a auditar sus canónicos utilizando SEO Spider de Screaming Frog.
Terminando
La implementación de etiquetas canónicas le brinda la posibilidad de decirle a los motores de búsqueda qué URL representa la mejor versión de cada contenido. Luego puede influir en qué páginas aparecen en los resultados de búsqueda y cuáles se tratan como secundarias.
Los canónicos son meras señales que los motores de búsqueda no necesitan respetar. Pero, en muchos casos, puede aumentar las posibilidades de que se respeten sus etiquetas canónicas. ¿Cómo?
Siga las mejores prácticas descritas: aquí hay una lista resumida de mis recomendaciones:
- Identifique el contenido duplicado en sus páginas y elija qué versión de la página debe ser la principal, por ejemplo, porque es la página más representativa o valiosa,
- Asegúrese de enviar señales consistentes a los motores de búsqueda con respecto a sus canónicos,
- Use etiquetas canónicas autorreferenciales,
- Asegúrese de que su implementación del archivo robots.txt, las etiquetas noindex y el mapa del sitio se alinee con su canonicalización,
- Asegúrese de que haya suficiente paridad de contenido entre las páginas duplicadas y canónicas,
- Limite los enlaces internos a las páginas duplicadas.