
Ghid suprem pentru eticheta canonică pentru SEO
Publicat: 2022-01-28Etichetele canonice vă permit să specificați care dintre mai multe pagini duplicat este versiunea principală și preferată a unei pagini.
Orice site web poate suferi de probleme de conținut duplicat – și este posibil să nu știți că o parte din conținutul dvs. este văzut ca fiind duplicat.
Fără eticheta canonică, ești la cheremul motoarelor de căutare – ei înșiși vor selecta versiunea canonică. Și, ei pot alege foarte bine unul pe care nu îl vedeți ca reprezentativ pentru conținutul dat. Acest lucru poate afecta grav vizibilitatea căutării și clasamentele dvs.
Acest ghid explică caracteristicile și cele mai bune practici pentru utilizarea etichetelor canonice pentru a rezolva problemele de conținut duplicat de pe site-ul dvs.
Ce sunt etichetele canonice?
O etichetă canonică este un fragment de cod care indică versiunea principală (canonică) a unei pagini atunci când există mai multe versiuni ale acelei pagini.
Folosind eticheta canonică, puteți spune motoarelor de căutare ce adresă URL ar trebui să fie indexată și să apară în rezultatele căutării.
Cea mai comună tehnică de implementare a etichetelor canonice este să adăugați următorul fragment de cod la codul HTML al unei pagini:
<link rel="canonical" href="https://example.com/sample-page/" />Codul înseamnă că pagina canonică se află la adresa URL specificată.
Etichetele canonice sunt folosite pentru a aborda problemele de conținut duplicat – dar ce conținut consideră motoarele de căutare duplicat și cum îl tratează?
Motoare de căutare și conținut duplicat
Problemele cu conținutul duplicat apar din simplul fapt că crawlerele motoarelor de căutare privesc paginile diferit decât utilizatorii.
Pentru un crawler de motor de căutare, fiecare dintre următoarele adrese URL este diferită:
- http://site.com
- https://site.com
- https://site.com/index.php
- http://site.com/index.php
- http://www.site.com
În timp ce un utilizator acordă atenție conținutului dintr-o pagină, crawlerele percep fiecare adresă URL ca o entitate separată, chiar și atunci când mai multe pagini au conținut identic.
Problemele de conținut duplicat tind să fie deosebit de grave pentru site-urile de comerț electronic, dar nu se limitează la acestea. Multe site-uri web moderne adaugă automat etichete și parametri la URL-uri, de exemplu, pentru sortarea sau filtrarea paginilor și folosesc adesea numeroase căi care duc la același conținut.
Mai multe versiuni ale adreselor URL pot exista, de asemenea, dacă utilizați structuri URL diferite – de exemplu, adresele URL sunt atât www, cât și non-www, cu și fără bare oblice, cu protocoale HTTP și HTTPS și în orice alte formate.
Acest lucru poate duce la conținut duplicat, pe care motoarele de căutare sunt reticente să-l indexeze.
Mai exact, atunci când motoarele de căutare dau peste conținut duplicat, se chinuie să decidă:
- Ce pagină ar trebui indexată,
- Ce pagină ar trebui să se claseze pentru cuvintele cheie relevante și
- Dacă ar trebui să consolideze semnalele de clasare sub o singură adresă URL sau să o împartă între mai multe pagini.
Deși motoarele de căutare pot deduplica paginile în scopuri de clasare, este riscant să le lași să aleagă adresa URL canonică - pot selecta o pagină care nu este cea mai reprezentativă versiune a conținutului tău.
Cum alege Google paginile canonice?
Este important să rețineți că Googlebot nu va urmări întotdeauna etichetele dvs. canonice, deoarece acestea servesc doar ca sugestii pentru modul în care ar trebui tratată o anumită adresă URL.
Google se uită la mulți alți factori de pe pagină atunci când alege versiunea canonică.
Acești factori includ, printre alții:
- redirecționări ,
- Legături interne și externe,
- Sitemaps ,
- Structura URL curată,
- Utilizarea protocolului HTTPS.
Puteți verifica dacă Google a respectat eticheta dvs. canonică sau a selectat una diferită utilizând instrumentul de inspecție URL .
Google folosește paginile canonice ca surse principale pentru a evalua conținutul și calitatea. Un rezultat al Căutării Google indică de obicei pagina canonică, cu excepția cazului în care unul dintre duplicate este în mod explicit mai potrivit pentru un utilizator. De exemplu, rezultatul căutării va indica probabil pagina mobilă dacă utilizatorul se află pe un dispozitiv mobil, chiar dacă pagina desktop este marcată ca canonică.sursa: documentatia Google
Urmărește acest videoclip care explică modul în care Google alege adresele URL canonice.
Când ar trebui să utilizați etichetele canonice?
Nu uitați că simpla adăugare a etichetelor canonice nu va rezolva toate problemele legate de conținutul duplicat sau subțire.
Obiectivul dvs. principal ar trebui să fie eliminarea problemelor de bază care cauzează aceste probleme. Concentrați-vă pe analizarea dacă puteți elimina sau îmbunătăți conținutul paginilor duplicat pentru a-l face mai unic și poate oferi mai multă valoare utilizatorului.
Cu toate acestea, marcarea cu acuratețe a paginilor cu etichete canonice este un pas înainte în gestionarea conținutului duplicat.
Să analizăm cum poți beneficia de etichetele canonice și când să le folosești.
Beneficiile utilizării etichetelor canonice
Adăugând etichete canonice, puteți:
Specificați ce pagină ar trebui să apară în rezultatele căutării
Motoarele de căutare urmăresc să ofere cea mai bună experiență de utilizare – de aceea rareori vor afișa mai mult de o versiune a aceluiași conținut în rezultatele căutării.
Etichetele canonice vă oferă șansa de a îmbunătăți vizibilitatea căutării celei mai reprezentative versiuni de pagină, ceea ce poate crește traficul organic către această pagină și se poate traduce în beneficii pentru afaceri.
Consolidați semnalele de clasare pentru paginile duplicat
Alte site-uri pot trimite către diferite versiuni duplicate ale paginilor dvs., diluând semnalele pe care motoarele de căutare le iau în considerare în timpul clasamentului.
Când utilizați o etichetă canonică, le spuneți motoarelor de căutare că semnalele de clasare de la adresele URL duplicate ar trebui să circule către pagina canonică.
Descurajați accesarea cu crawlere a paginilor duplicate
Dacă implementați etichete canonice, este mai puțin probabil ca motoarele de căutare să continue să acceseze cu crawlere paginile canonizate știind că sunt copii.
În același timp, versiunea canonică ar trebui accesată cu crawlere mai regulat.
Aceasta este o oportunitate pentru ca paginile dvs. canonice să fie accesate cu crawlere mai eficient, ceea ce poate afecta pozitiv starea de indexare a site-ului dvs. web.
Tipuri de conținut de marcat cu etichete canonice
Să trecem prin conținutul specific pentru care ar trebui să selectați o pagină canonică.
Următoarele tipuri și aspecte de conținut nu adaugă, de obicei, nicio valoare site-ului dvs. și pot duce la creșterea cantității de conținut duplicat.
Conținut sindicalizat
Sindicarea conținutului înseamnă că o bucată de conținut a fost republicată pe alt domeniu.
Implementarea unei etichete canonice poate ajuta la atribuirea dreptului de proprietate asupra piesei editorului original.
Filtrarea și sortarea produselor
Opțiunile de filtrare și sortare, tipice pentru site-urile de comerț electronic, utilizează de obicei șiruri de interogări care sunt adăugate la adresele URL - acest lucru poate crea cantități masive de conținut duplicat. Canonizarea filtrelor și sortării paginilor va ajuta versiunea dvs. canonică să se claseze mai sus și va împiedica motoarele de căutare să acceseze cu crawlere inutil conținut duplicat,
Parametri redundanți în URL-uri
Parametrii pot fi redundanți pentru o pagină dacă nu sunt utilizați pentru urmărire, nu modifică conținutul și nu adaugă informații semnificative la adresa URL.
În schimb, acestea pot duce la accesarea cu crawlere ineficientă a site-ului dvs.
Variante de produs
Un produs poate veni în diferite variante, unde singura caracteristică care se schimbă este culoarea, mărimea sau orice alt atribut aplicabil. Canonicalizarea vă poate ajuta să selectați varianta principală a produsului.
Cu toate acestea, luați în considerare dacă produsul rămâne același. De exemplu, în nișa tehnologică, diferite variante de produse, cum ar fi smartphone-urile, pot conține de fapt și alte funcționalități și astfel ar trebui să apară toate în rezultatele căutării.
Parametri de urmărire și ID-uri de sesiune
Parametrii de urmărire pot urmări o campanie sau călătoria unui utilizator și nu modifică conținutul unei pagini, așa că ar trebui să fie și canonizati.
Cum se compară etichetele canonice cu etichetele noindex și cu redirecționările 301
S-ar putea să vă întrebați cum se compară etichetele canonice cu alte soluții care pot afecta modul în care motoarele de căutare indexează paginile și dacă le indexează deloc.
Să comparăm caracteristicile și cazurile de utilizare SEO ale etichetelor canonice, etichetelor noindex și redirecționărilor 301.
Utilizarea etichetelor canonice vs. etichete noindex
Etichetele Noindex sunt folosite pentru a exclude pagini din index, nu pentru a gestiona ce pagină ar trebui aleasă drept canonică.
Nu trebuie să utilizați niciodată eticheta noindex pentru a împiedica motoarele de căutare să selecteze o pagină canonică.
Paginile canonizate consolidează, în general, semnalele de clasare sub o singură adresă URL, spre deosebire de etichetele noindex – acest lucru este cauzat de faptul că Google tratează etichetele noindex, follow pe termen lung ca noindex, nofollow .
Regula generală este că o pagină nu ar trebui să fie atât neindexată, cât și canonizată. De exemplu, paginile canonizate la adrese URL fără indexare vor fi eliminate din index.
John Mueller a clarificat în timpul programului SEO că nu există riscul ca o pagină noindexată și canonizată să transfere noindexul pe destinația sa canonică, ceea ce ar elimina ulterior ambele adrese din index.
Cu toate acestea, utilizarea atât a etichetelor noindex, cât și a etichetelor canonice trimite semnale mixte către Google. Aceasta înseamnă că Google poate interpreta etichetele așa cum alege, iar rezultatul ar putea fi nedorit pentru dvs.
Utilizarea etichetelor canonice vs. redirecționări 301
Motoarele de căutare și utilizatorii percep etichetele canonice și redirecționările 301 foarte diferit.
Dacă utilizați o redirecționare 301, utilizatorii vor fi direcționați automat la pagina de destinație și nu vor vedea pagina originală. Redirecționările 301 vă ajută, de asemenea, să vă economisiți bugetul de accesare cu crawlere, deoarece limitează numărul de adrese URL care trebuie accesate cu crawlere.
Între timp, cu o etichetă canonică, utilizatorii vor putea în continuare să viziteze ambele adrese URL. Mai mult, adresele URL duplicate sunt încă accesate cu crawlere de motoarele de căutare, astfel încât numărul de pagini care pot fi accesate cu crawlere nu scade.
Deși etichetele canonice tind să transmită semnale de clasare către versiunea principală a unei pagini, redirecționările 301 sunt un indiciu mai puternic pentru Google că semnalele de clasare ar trebui transferate la adresa URL de destinație. Acest lucru se întâmplă deoarece Google nu vede conținut intermitent, așa cum face cu etichetele canonice.
Să clarificăm când o redirecționare 301 va fi mai potrivită decât o etichetă canonică.
Cel mai bine este să utilizați redirecționări 301 pentru a consolida adresele URL:
- Conțin litere mici și mari,
- Cu și fără bare oblice,
- protocoale HTTP sau HTTPS,
- Există atât cu cât și fără www.
Dacă faceți modificări conținutului dvs., cum ar fi în timpul migrării site -ului, și adresele URL se modifică, ar trebui să redirecționați 301 adresele URL vechi către cele noi. În afară de redirecționare, asigurați-vă că noua adresă URL de destinație are o etichetă canonică autoreferențială.
O altă situație în care redirecționările 301 vor fi optime este atunci când produsele sunt accesibile sub mai multe adrese URL.

În acest caz, modificați structura URL-ului, astfel încât să nu includă numele categoriei căreia i-au fost atribuite produsele. Apoi, 301 redirecționează adresa URL moștenită. Dacă anumite categorii sunt redundante, le puteți elimina și redirecționa către pagini alternative relevante.
În general, utilizați o redirecționare 301 dacă o singură adresă URL ar trebui să fie în continuare accesibilă utilizatorilor.
Cum să adăugați etichete canonice la o pagină
Există două metode principale de specificare a paginilor canonice – în anteturile HTML sau HTTP ale unei pagini. Puteți să le implementați manual sau să utilizați unul dintre instrumentele care vă pot ajuta să le automatizați.
De exemplu, puteți alege un plugin SEO dacă utilizați un CMS. Pluginurile cu funcționalitatea de a specifica pagini canonice includ Yoast SEO sau All in One SEO.
Dacă utilizați Shopify , puteți seta adrese URL canonice personalizate dacă este necesar – setarea implicită a Shopify este să adăugați adrese URL canonice cu auto-referință pentru produse și postări de blog.
Indiferent de metoda pe care o alegeți, nu uitați să implementați doar etichetele canonice într-un singur loc – nu utilizați aceste metode simultan. Dacă Google descoperă mai multe declarații ale etichetei canonice, probabil că le va ignora pe toate.
Etichetă HTML
Adăugarea unei etichete canonice în HTML este cel mai comun mod de a o implementa.
Adăugați următorul cod la secțiunea <head> a unei pagini duplicate din HTML și inserați adresa URL a versiunii canonice:
<link rel="canonical" href="https://example.com" />Această metodă funcționează numai pentru pagini HTML, așa că utilizați antetul HTTP dacă doriți să canonizați alte tipuri de fișiere.
Antet HTTP
Puteți implementa antetul HTTP „rel=canonical” pentru a indica versiunea canonică a unei adrese URL:
Link: <http://www.example.com/downloads/white-paper.pdf>; rel="canonic"
Utilizați antetul HTTP pentru a specifica un canonic pentru documentele non-HTML, cum ar fi fișierele PDF.
Pentru a utiliza această soluție, aveți nevoie de acces la serverul site-ului dvs. web. De asemenea, necesită unele abilități tehnice, deoarece această metodă este mai predispusă la erori și dificil de implementat decât HTML.
Cele mai bune practici pentru utilizarea etichetelor canonice
Respectarea celor mai bune practici pentru etichetele canonice ajută la atenuarea riscului ca motoarele de căutare să vadă versiunea greșită a paginii ca fiind canonică.
Iată lista mea de recomandări pentru etichetele canonice:
Utilizați adrese URL absolute
În teorie, Google ar trebui să recunoască atât adresele URL relative, cât și absolute. Cu toate acestea, versiunile absolute ale adreselor URL sunt mai puțin predispuse la erori și mai ușor de depanat.
Puteți utiliza oricare, dar vă recomand să utilizați adrese URL absolute, astfel încât să fiți sigur că sunt interpretate corect.
— johnmu.xml (personal) (@JohnMu) 24 octombrie 2018
Cu alte cuvinte, utilizați o adresă URL completă într-o etichetă canonică:
<link rel="canonical" href="https://example.com/sample-page/" />Și nu includeți doar calea URL:
<link rel=“canonical” href="/sample-page/” />Utilizați etichete canonice autoreferențiale
Deși nu este obligatoriu, se recomandă utilizarea etichetelor canonice care indică paginile pe care se află.
Este esențial să îl implementați dacă utilizați parametrii pentru a urmări campaniile – dacă faceți acest lucru, toate adresele URL cu un parametru de campanie ar trebui să fie canonizate în mod implicit la adresa URL statică și să le împiedice să fie indexate.
Iată ce a spus John Mueller de la Google în timpul programului de lucru SEO cu privire la canonicalele autoreferențiale:
Nu este esențial să avem o etichetă canonică cu auto-referință pe o pagină, dar ne face mai ușor să alegem exact adresa URL pe care doriți să o alegeți ca canonică.Folosim o serie de factori pentru a alege o adresă URL canonică, iar rel=canonical joacă un rol în acest sens.
Deci, în special, lucruri precum parametrii URL sau dacă adresa URL este etichetată într-un anumit mod – poate aveți linkuri care merg către pagina respectivă care sunt etichetate pentru analiză, de exemplu – atunci s-ar putea întâmpla să alegem acea adresă URL etichetată ca un canonic […]
sursa: John Mueller
Trimiteți semnale clare către motoarele de căutare
Trimiterea de semnale clare constă în specificarea unui singur canonic pe pagină.
Evitați să specificați o adresă URL ca fiind canonică și, în același timp, să redirecționați adresa URL către o altă destinație.
Un alt caz se referă la canonicalele adăugate folosind JavaScript.
Dacă nu este specificată nicio pagină canonică în HTML și este adăugată o etichetă canonică cu JavaScript, Google ar trebui să o respecte în timpul redării. Dar, dacă un canonic este setat în HTML și JavaScript îl modifică, trimiteți semnale mixte către Google.
Trimiterea de semnale mixte poate duce la ca motoarele de căutare să interpreteze incorect canonicalele dvs. sau să aleagă versiunea greșită drept canonică.
Asigurați-vă că utilizați adresa URL corectă când conectați intern
Când plasați link-uri interne pe site-ul dvs., asigurați-vă că trimiteți la adresa URL canonică și nu la duplicate.
După cum sa menționat, este posibil ca Google să nu respecte canonicul dacă semnalele mai puternice indică o altă adresă URL . Unul dintre astfel de semnale ar putea fi legat de o adresă URL duplicată pe care Google o poate vedea ca versiune principală.
Nu îndreptați eticheta canonică către prima pagină a paginației
Este o greșeală comună să urmărești doar indexarea primei pagini de paginare. Poate doriți să îl utilizați pentru a împiedica utilizatorii să acceseze paginile ulterioare din rezultatele căutării, dar este o abordare greșită. Motoarele de căutare pot ignora canonizarea deoarece aceste pagini nu sunt de obicei duplicate. Dar dacă respectă etichetele canonice, paginarea poate fi canonizată.
Dacă paginarea conține linkuri către produse unice și nu există nicio altă legătură între paginile de produse, linkurile către paginile de produse din paginare pot fi ignorate. Cu alte cuvinte, paginile de produse indexabile nu vor avea link-uri interne de la alte pagini.
În schimb, paginile paginate ar trebui să aibă etichete canonice autoreferențiale. Conținutul acestor pagini nu este identic și, prin includerea etichetelor auto-referențiale, le spuneți motoarelor de căutare că fiecare pagină este unică. Dacă nu doriți ca aceste pagini să fie indexate, utilizați etichete noindex.
Indicați spre versiunea desktop a unei pagini
Dacă site- ul dvs. mobil se află pe un subdomeniu, eticheta canonică ar trebui să indice versiunea pentru desktop a paginii.
Identificați o pagină canonică atunci când utilizați etichete hreflang
Deși Google nu vede diferite versiuni ale aceluiași conținut tradus în alte limbi ca fiind duplicate, ar trebui să utilizați totuși etichete canonice.
Spuneți motoarelor de căutare care este pagina canonică în aceeași limbă sau în cea mai bună limbă de înlocuire. Variantele de limbă ar trebui să fie auto-canonice.
Preveniți problemele legate de bugetul de accesare cu crawlere
Adresele URL canonizate pot folosi în continuare bugetul de accesare cu crawlere, chiar dacă etichetele canonice sunt implementate corect.
Deși rata de accesare cu crawlere a adreselor URL canonizate ar trebui să scadă în timp, motoarele de căutare se pot concentra în continuare pe preluarea duplicatelor în loc să acceseze cu crawlere și să indexeze pagini noi.
Verificați jurnalele serverului pentru a vedea cum se comportă Googlebot pe site-ul dvs. și pentru a identifica eventualele probleme de accesare cu crawlere.
Pentru a atenua problemele legate de bugetul de accesare cu crawlere, ar trebui, în general:
- Reduceți linkurile interne către versiuni URL non-canonice,
- Utilizați instrumentul pentru parametri URL din Google Search Console pentru a spune Googlebot să acceseze cu crawlere versiunile statice ale adreselor URL.
Dar rețineți că problemele legate de bugetul de accesare cu crawlere apar pe site-uri foarte mari - Google afirmă că majoritatea site-urilor nu vor trebui niciodată să-și facă griji.
Vă recomand să citiți articolul Google despre greșelile comune atunci când implementați „rel=canonic” pentru a afla ce alte lucruri să evitați.
Cum să auditați etichetele canonice
Pentru ca etichetele dvs. canonice să fie preluate, trebuie să vă asigurați că o pagină are o etichetă canonică care indică pagina potrivită.
De asemenea, trebuie să verificați dacă pagina poate fi accesată cu crawlere și poate fi indexată – nu ar trebui să fie blocată de robots.txt sau marcată cu o etichetă noindex.
Mai jos sunt câteva modalități utile de a vă audita etichetele canonice.
Cum să utilizați Google Search Console pentru a analiza etichetele canonice
Google Search Console conține câteva instrumente utile pentru a vă audita paginile canonice: raportul Acoperirea indexului și instrumentul de inspecție a adreselor URL.
Raportul de acoperire a indicelui
Raportul Acoperirea indexării din Google Search Console este o sursă valoroasă de informații despre starea dvs. de indexare - ce adrese URL sunt indexate și care nu sunt indexabile și de ce.
Pentru a analiza canonicalele site-ului dvs., navigați la categoria Exclus.
Aici puteți găsi câteva stări care sunt relevante pentru dvs.:
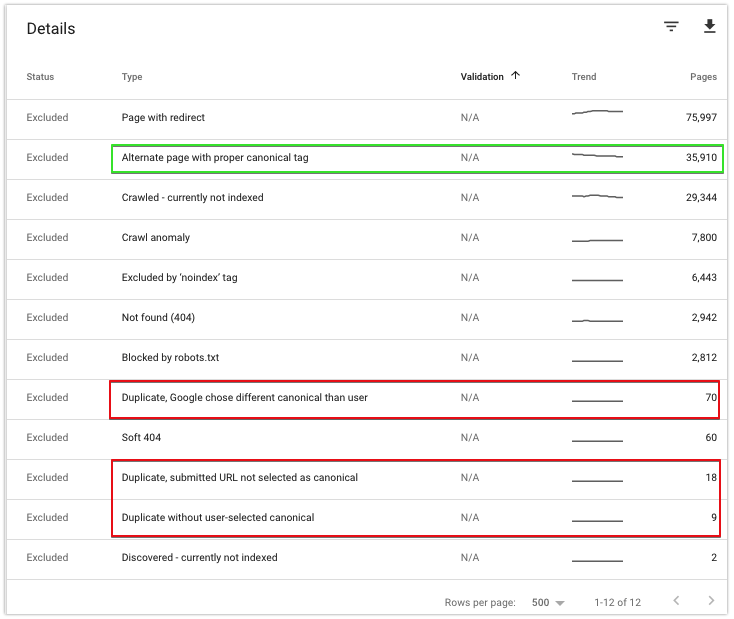
Pagina alternativă cu eticheta canonică adecvată
Adresele URL marcate cu această stare indică pagini pentru care Google respectă canonizarea dvs. la o adresă URL.
Vă puteți aștepta ca numărul acestor adrese URL să crească dacă ați canonizat recent unele pagini. Puteți folosi această secțiune a raportului Google pentru a verifica dacă Google nu accesează cu crawlere duplicatele mai mult decât este necesar.
În caz contrar, aceste adrese URL nu necesită atenția dvs.
Dublat, Google a ales diferit canonic decât utilizator
Starea indică faptul că Google a ignorat auto-referirea dvs. canonică sau canonicalizarea la un alt canonic. Acest lucru se poate întâmpla dacă semnale mai puternice indică către alte adrese URL – de exemplu, pot exista legături interne sporite către alte pagini.
Această problemă poate indica și probleme de conținut. De exemplu, este posibil ca partea unică a conținutului să nu se încarce sau să fi ales o pagină greșită pe care să o canonizezi, de exemplu, deoarece nu există o paritate suficientă a conținutului între paginile duplicate și cele canonice.
Dacă nu puteți determina cum să rezolvați această problemă, mergeți direct la ghidul nostru despre cum să remediați Duplicatul, Google a ales o altă problemă canonică decât cea a utilizatorului.
Duplicat, adresa URL trimisă nu a fost selectată ca canonică
Înseamnă că Google a găsit pagini în sitemapurile dvs. XML pe care le consideră duplicate. Parcurgeți harta site-ului și asigurați-vă că toate adresele URL găsite în acesta ar trebui să fie indexate.
Duplicați fără canonice selectate de utilizator
Acestea sunt URL-uri duplicate fără niciun URL rel=canonical specificat – determinați cele mai potrivite pagini canonice pentru ele și adăugați-le.
Instrument de inspecție URL
Puteți folosi instrumentul de inspecție URL pentru a investiga în continuare modul în care Googlebot vede adresele URL excluse din index.
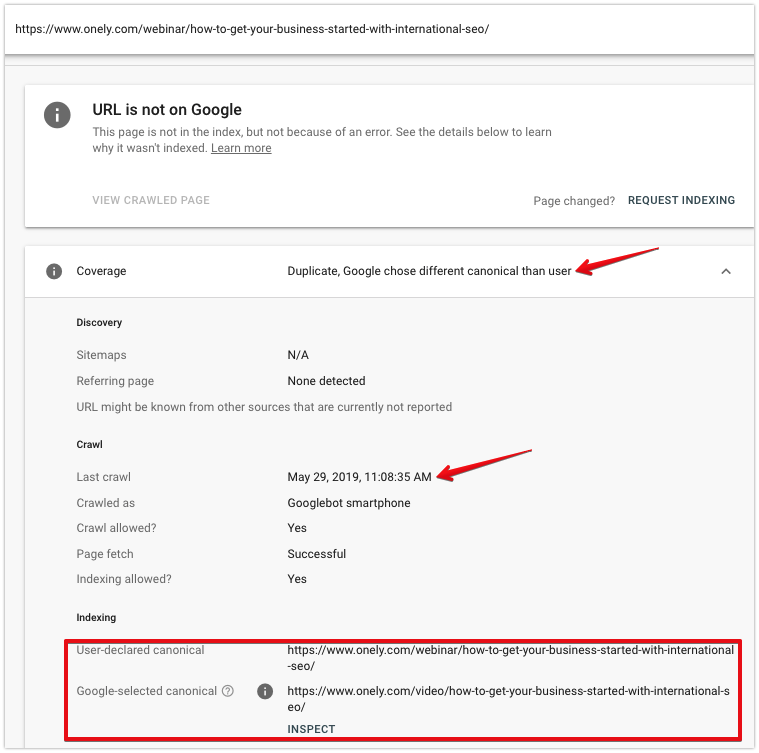
Când inspectați o pagină, uitați-vă la:
- Data ultimei accesări cu crawlere – Ultima dată când Googlebot a preluat pagina. Dacă o etichetă canonică a fost adăugată recent, este probabil ca Googlebot să nu fi accesat cu crawlere adresa URL de atunci.
- Canonic declarat de utilizator – Aceasta ar trebui să arate adresa URL pe care ați selectat-o – verificați dacă este adresa URL corectă.
- Canonic selectat de Google – Dacă Google a ales o altă pagină canonică, puteți vedea ce adresă URL a fost selectată.
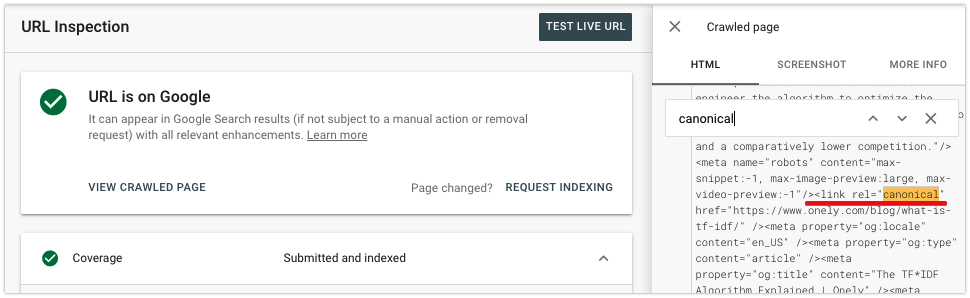
De asemenea, puteți verifica dacă eticheta canonică a fost adăugată corect. Faceți clic pe Vizualizare pagina accesată cu crawlere pentru a examina conținutul redat și a căuta eticheta canonică în secțiunea <head>.
În fila Mai multe informații, puteți verifica antetul de răspuns HTTP primit de Googlebot.
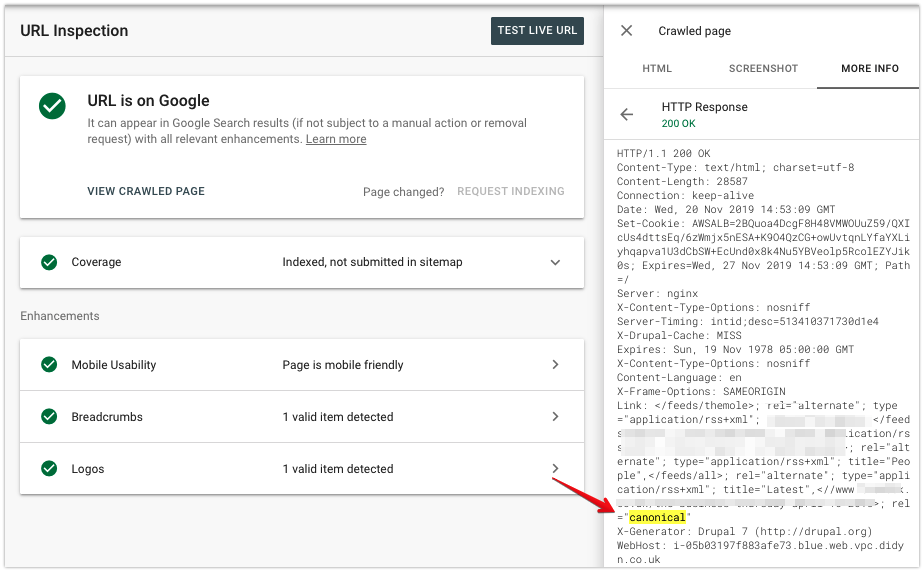
Asigurați-vă că se aliniază cu configurația dorită, chiar dacă utilizați rel=canonic în HTML-ul unei pagini.
Efectuarea unei accesări cu crawlere a site-ului pentru a audita etichetele canonice
O accesare cu crawlere a site-ului web vă poate ajuta să descoperiți probleme cu etichetele dvs. canonice.
Crawlerele site-urilor web vă oferă detalii despre raportul canonic vs. non-canonic. Vă vor avertiza cu privire la orice canonical incorect, cum ar fi paginile eliminate/lipsă (HTTP 4xx), erorile de server (HTTP 5xx) sau redirecționările (HTTP 3xx) în etichetele canonice. În general, ar trebui să investigați orice coduri de stare, altele decât HTTP 200.
Urmați acest ghid pentru a afla cum să vă auditați canonicalele folosind Screaming Frog's SEO Spider.
Încheierea
Implementarea etichetelor canonice vă oferă posibilitatea de a spune motoarelor de căutare care URL reprezintă cea mai bună versiune a fiecărui conținut. Puteți influența apoi ce pagini apar în rezultatele căutării – și care sunt tratate ca secundare.
Canonicalele sunt simple semnale pe care motoarele de căutare nu trebuie să le respecte. Dar, în multe cazuri, puteți crește șansele ca etichetele dvs. canonice să fie respectate. Cum?
Urmați cele mai bune practici prezentate – iată o listă scurtă a recomandărilor mele:
- Identificați conținutul duplicat pe paginile dvs. și alegeți ce versiune a paginii ar trebui să fie principală - de exemplu, deoarece este cea mai reprezentativă sau mai valoroasă pagină,
- Asigurați-vă că trimiteți semnale consecvente către motoarele de căutare cu privire la canonicalele dvs.
- Folosiți etichete canonice autoreferențiale,
- Asigurați-vă că implementarea fișierului robots.txt, a etichetelor noindex și a sitemap-ului se aliniază cu canonizarea dvs.,
- Asigurați-vă că există o paritate suficientă a conținutului între paginile duplicate și cele canonice,
- Limitați legătura internă la paginile duplicate.