
Web Scraping - uma parte integral da ciência de dados
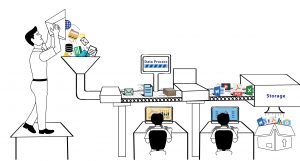
Publicados: 2020-02-21Web Scraping tornou-se parte integrante da Data Science é um ecossistema em si e o termo muitas vezes acaba sendo usado como substituto para aprendizado de máquina, inteligência artificial e outros. O ecossistema de ciência de dados consiste em cinco estágios diferentes que juntos compõem todo o ciclo de vida. Cada etapa consiste em várias opções usadas para concluir essa etapa.
Métodos de raspagem da Web:
Captura de dados
- Extração de dados usando processos como web scraping.
- Entrada manual de dados.
- Aquisição de dados - comprando conjuntos de dados.
- Capturando sinais de dispositivos IoT.

Processamento de dados
- Mineração de dados.
- Classificação ou agrupamento de dados brutos.
- Limpeza e normalização de dados.
- Modelagem de Dados.
Manutenção
- Data warehousing e data lake.
- Criação de infraestrutura para gerenciar e armazenar dados e fornecer disponibilidade máxima.
Comunicação das descobertas
- Visualização dos resultados usando gráficos.
- Resumindo as descobertas em um relatório textual.
- Inteligência de negócios e tomada de decisão.
Análise
- Análise exploratória e confirmatória.
- Análise preditiva.
- Regressão.
- Mineração de texto.
- Sentimento e análise qualitativa.

Como podemos ver na lista acima, nada aconteceria no campo da Ciência de Dados sem captura de dados, que é ter os dados nos quais você deseja executar seus algoritmos. Este primeiro passo é crucial e é o principal bloco de construção. A menos que você tenha seus sistemas que geram terabytes de dados utilizáveis todos os dias, a opção provável para você aqui é rastrear dados da web e armazená-los em bancos de dados, sobre os quais você pode executar seus algoritmos e construir seu mecanismo de previsão.
Quais são as ferramentas que um Cientista de Dados pode usar para Web-Scraping?
Caso você seja um cientista de dados e precise rastrear dados da Internet escrevendo seu código, você pode usar o Python para escrever seu código. Além de ter uma curva de aprendizado mais fácil, também permite que você interaja com sites de maneira automatizada por meio do seu código. Através do seu código, você pode interagir com os sites de forma que o site receba suas solicitações como receberia quando se usa um navegador da web. Você pode automatizar seus requisitos de raspagem, executar scripts oportunos ou até mesmo manter um feed constante de dados (de sites de mídia social como o Twitter) para criar seu conjunto de dados para seu projeto de ciência de dados. Aqui estão algumas das bibliotecas disponíveis em Python que ajudariam você a enfrentar diferentes desafios enfrentados pelas pessoas ao extrair dados para seus projetos-
solicitações de
Quando você deseja rastrear dados da Web por meio de código, o primeiro objetivo seria acessar sites usando código. É aí que entra a biblioteca de requisições . Ela é uma das favoritas da comunidade Python devido à facilidade com que você pode fazer chamadas para páginas da web e APIs. Isso abstrai muito do código padrão e torna as solicitações HTTP mais simples do que ao usar a biblioteca URLLib integrada. Ele inclui vários recursos, como verificação SSL no estilo do navegador, solicitações headless, decodificação automática de conteúdo, suporte a proxy e muito mais.


Sopa Linda
Uma vez que você tenha uma página da web, que você raspou da web, você precisa extrair dados de tags e atributos na página HTML. Para isso, você precisa analisar o conteúdo HTML de forma que todos os dados se tornem facilmente acessíveis. O BeautifulSoup permite uma análise fácil de documentos HTML e XML de uma maneira que simplifica a navegação, a pesquisa e a modificação. Ele trata o documento como uma árvore e você pode navegar da mesma maneira que navega em uma estrutura de dados em árvore.

Sopa Mecânica
Ao interagir com sites mais complexos. Pode haver a necessidade de recursos estendidos que ajudariam a rastrear muitas páginas da web. A Mechanical Soup auxilia na automação do armazenamento e envio de cookies, permite redirecionamentos e pode seguir links e até enviar formulários.

Scrapy
Uma das bibliotecas de web scraping baseadas em Python mais poderosas, o Scrapy fornece uma estrutura colaborativa e de código aberto. É uma biblioteca de raspagem de alto nível usada para configurar operações de mineração de dados, aranhas automatizadas, rastreamento periódico da web. Scrapy usa algo chamado Spiders. São classes definidas pelo usuário usadas para extrair informações de páginas da web.

Selênio
Normalmente usado para testar páginas da web e suas funcionalidades, o Selenium também pode ser usado para tarefas manuais automáticas, como extrair dados da web usando capturas de tela, automatizar cliques e extrair os dados expostos e muito mais.

Web Scraping vs Outras Fontes de Dados:
Embora existam várias fontes de dados disponíveis hoje, o web scraping surgiu como um dos processos mais populares pelos quais as empresas estão adquirindo dados (que acabam sendo processados e convertidos em informações utilizáveis). Uma das maiores razões por trás disso é que quando você está trabalhando em um projeto de ciência de dados, você prefere ter novos dados não utilizados, usando os quais você pode construir uma tese ou prever um resultado, que não foi derivado antes. Embora os dados sejam o novo petróleo, o valor dos dados diminui com o tempo. Dessa forma, o web-scraping é uma dádiva de Deus, já que os dados na web são atualizados a cada segundo. É válido apenas enquanto não for substituído por novos dados. Por exemplo, o preço de um item em um site pode ser de US$ 1.000.
Você pode buscar um relatório para obter a lista de preços de uma fonte. Quando a lista de preços chegar até você com a marca de US$ 1.000, o preço do item pode ter diminuído para US$ 900. Portanto, sua decisão com base no preço que você tem em mãos acabaria sendo errada. Em vez disso, se você rastrear o preço de um item agora, obterá o preço no momento. Em seguida, você pode manter um raspador funcionando com frequência regular para capturar a mudança de preço a cada 10 segundos. Portanto, quando você se senta com os dados, para tomar uma decisão, você terá dados atualizados e históricos e isso pode melhorar os resultados. Um fluxo constante de dados sem fim é o que o web-scraping oferece. Essa é a principal razão para a Data Sciences, seja por um gerente de marketing ou por um cientista de pesquisa.
Os desafios de usar dados raspados em Data Science:
Enquanto os dados que você obtém pela web-scraping são enormes e regulares. Um fato importante é que os dados extraídos da web geralmente contêm uma grande quantidade de dados impuros e não estruturados . O que também se viu é a presença de duplicatas, bem como pontos de dados não verificados. Acertar suas fontes de dados é importante e, portanto, os dados sempre devem ser rastreados de sites verificados e conhecidos. Ao mesmo tempo, muitas fontes de dados usadas para confirmar dados. Limpando os dados e certificando-se de que as duplicatas estejam ausentes, são abordadas usando alguma codificação inteligente. Mas a conversão de dados não estruturados em dados estruturados continua sendo um dos problemas mais difíceis de raspagem da web e as soluções variam de caso para caso.
O outro grande problema surge da segurança, legalidade e privacidade. Com cada vez mais países determinando privacidade de dados e limites mais altos de acesso a dados, mais e mais sites são hoje acessíveis apenas por meio de uma página de login. A menos que você rastreie dados, existe a possibilidade de uma penalidade pelo mesmo. Pode começar desde o bloqueio do seu IP até uma ação judicial contra você.
Conclusão:
Toda oportunidade vem com seus desafios. Quanto maior o desafio, maior a recompensa. Portanto, o web scraping precisa se integrar ao fluxo de trabalho de sua empresa, e os projetos de ciência de dados precisam gerar informações utilizáveis a partir desses dados. Mas se você precisar de ajuda para extrair dados de sites para sua empresa ou startup, nossa equipe da PromptCloud fornece uma solução DaaS totalmente gerenciada onde você nos informa os requisitos e configuramos seu mecanismo de extração.