
Votre guide pour les questions-réponses de Quora sur le scraping Web
Publié: 2022-02-17Les sites de questions-réponses comme Quora sont des centres de socialisation en ligne permettant aux citoyens numériques du monde entier de poser des questions, de répondre et de discuter des problèmes, des doutes et des sujets les plus importants. L'extraction de données à grande échelle à partir de ces plateformes de questions-réponses en ligne peut être utile aux spécialistes du marketing et aux scientifiques des données, car il ne s'agit pas seulement d'un site Web de questions-réponses multilingue, mais également d'un réseau social en soi avec de nombreux influenceurs de niche. Apprenons en détail comment gratter Quora.
Cas d'utilisation de Quora Scraping
Pour souligner pourquoi le scraping de Quora intéresse les spécialistes du marketing et les entreprises, jetons un coup d'œil à 4 statistiques essentielles de Quora :
- Quora compte 300 millions d'utilisateurs actifs par mois.
- En moyenne, les utilisateurs passent plus de 4 minutes sur Quora chaque jour.
- D'après les volumes de trafic, il s'agit du 80e site Web le plus populaire au monde.
- La recherche Google affiche jusqu'à 65 millions de résultats pour Quora[dot]com.
#1 : Analyse des sentiments
Vous pouvez gratter des questions liées à la politique, aux marques, au marché boursier, etc. pour effectuer une analyse des sentiments.
#2 : PNL et apprentissage automatique
La plupart des utilisateurs de Quora sont de vrais utilisateurs, qui posent des questions et des réponses sur la plateforme dans leur jargon quotidien. Cela pourrait être très utile pour la formation de modèles ML et le traitement du langage naturel (NLP).
#3 : Marketing d'influence intelligent
Quora vous permet de diffuser des publicités, mais vous pouvez également cibler des influenceurs dans un créneau particulier pour promouvoir votre marque. Récupérer des questions, des profils d'utilisateurs, etc. à partir d'un créneau spécifique vous permettrait de vous associer aux bons influenceurs qui ont une réelle autorité pour promouvoir vos marques.
#4 : Génération de leads et marketing de contenu
Les questions posées par les utilisateurs peuvent vous aider à identifier s'ils sont vos prospects cibles. Par exemple, si vous êtes une société de services informatiques, les personnes qui posent des questions telles que "Combien coûte le développement d'un site Web de commerce électronique ?" sont vos pistes potentielles. Les informations obtenues en grattant les questions-réponses de Quora peuvent également être votre passerelle vers une stratégie de marketing de contenu stellaire.
Comment gratter les questions et réponses de Quora
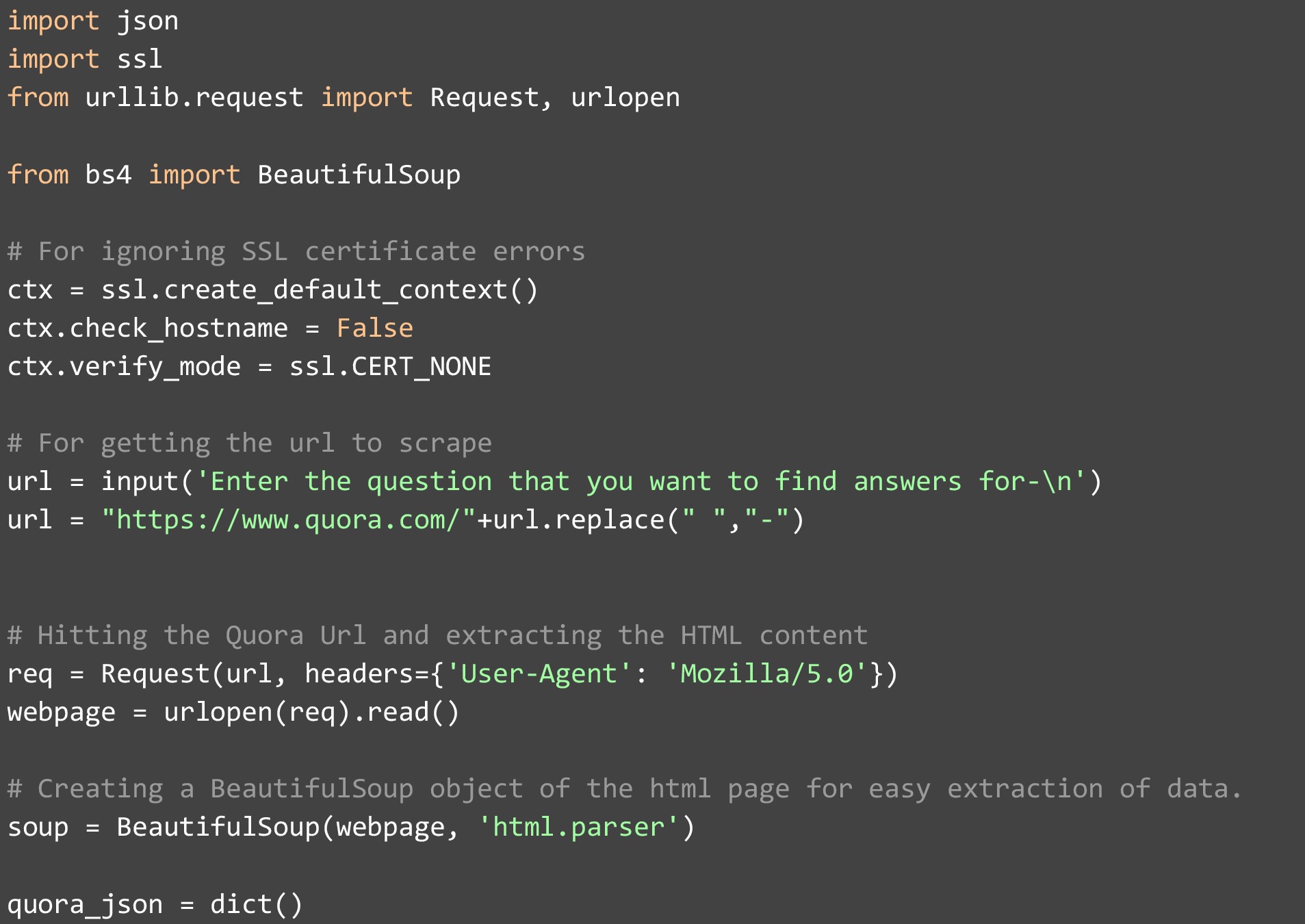
Nous utiliserons Python3.7 et la bibliothèque BeautifulSoup pour explorer les données Quora et les enregistrer dans un fichier JSON. En utilisant ce code, vous pourrez facilement récupérer et extraire les réponses et les questions de Quora. La seule autre chose dont vous aurez besoin est un éditeur de texte décent. Nous avons utilisé PyCharm, qui est un IDE complet, mais vous pouvez également utiliser Atom car il est livré avec plusieurs plugins et est plus léger. J'espère que cela vous aidera à comprendre comment gratter Quora en détail.
Donc, pour commencer par le code, nous commençons par importer les bibliothèques dont nous aurons besoin, à la fois internes et externes. Une fois cela fait, nous devons nous assurer que nous avons défini le mode de vérification du certificat SSL sur "CERT_NONE", et vérifier le nom d'hôte sur False, pour éviter d'obtenir des erreurs de certificat SSL lorsque nous commençons à récupérer des données. Une fois cela fait, notre configuration est terminée et nous pouvons accepter une question de l'utilisateur. Pour cette démo, nous avons fourni la valeur suivante lorsque cette question a été posée.


Nous créons l'URL Quora en utilisant cette question. Cette manipulation de chaîne est nécessaire car Quora formate ses URL de cette manière.
Une fois que nous avons créé l'URL, nous utilisons la fonction intégrée Request de urllib pour accéder à la page Web et nous assurer que nous ajoutons Firefox dans l'en-tête, afin que le site Web ne soit pas en mesure de savoir si nous y accédons à partir d'un morceau de code. Cette partie est importante car la plupart des sites Web bloquent les scrapers et si vous manquez l'en-tête. Votre adresse IP sera probablement bloquée et d'autres actions pourront être engagées contre vous.
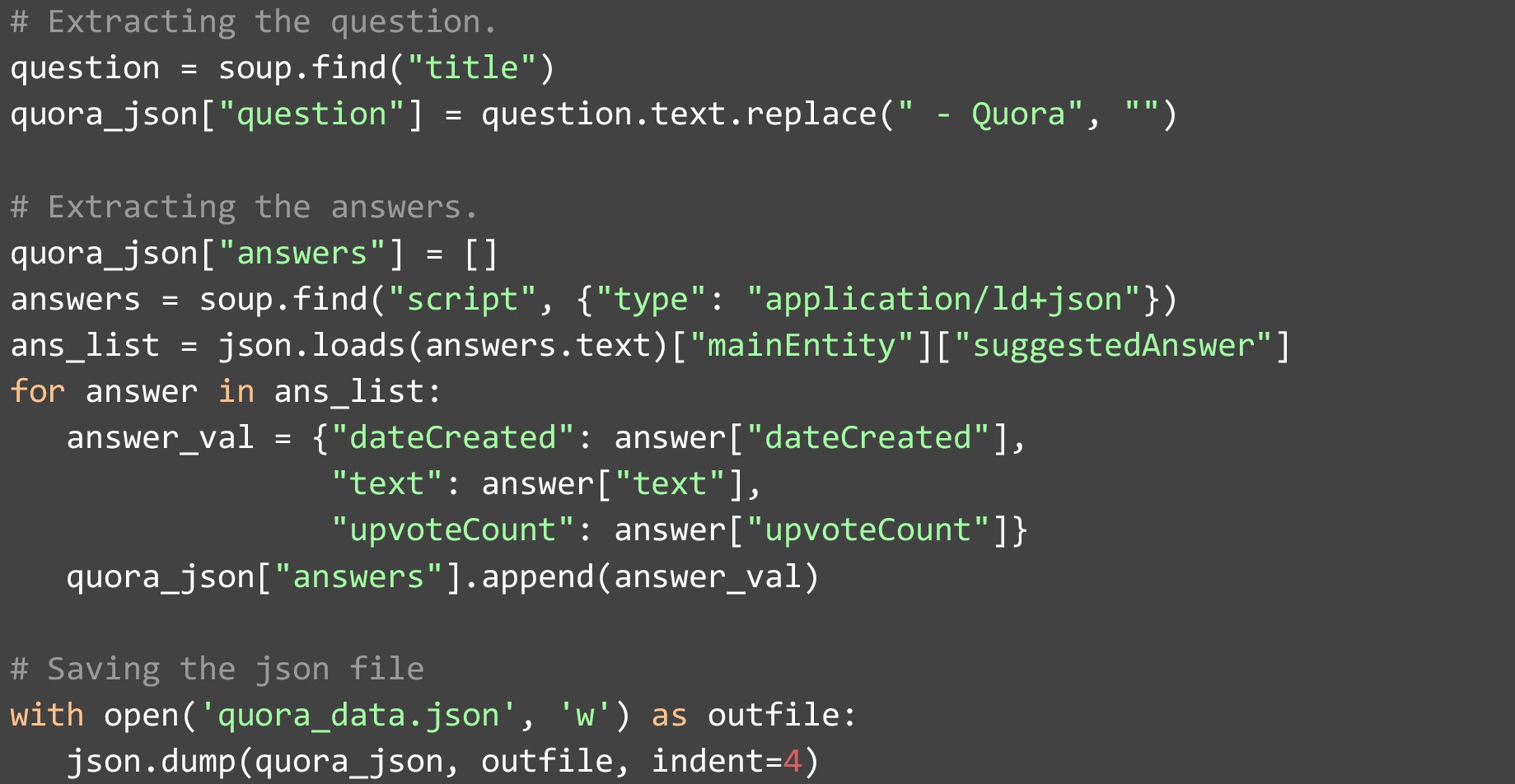
Après avoir obtenu la page Web au format HTML et l'avoir stockée dans une variable. Nous devons le convertir en un objet BeautifulSoup afin qu'il soit plus facile d'analyser et d'extraire des données. Extrayez ensuite la question sur la page Web à partir de la première balise « titre » de la page. Nous devons supprimer "- Quora" car tous les titres sont accompagnés de la chaîne suivante. Gratter la réponse est un peu plus compliqué. Vous devez extraire le JSON stocké dans l'élément de type "script" ayant la valeur de "type" comme "application/ld+json". Une fois que vous avez obtenu ce JSON, vous trouverez une liste de réponses avec plusieurs champs. Alors que peu de champs sont donnés pour chaque réponse. Nous avons extrait les plus importants :
- La date à laquelle la réponse a été rédigée
- La réponse elle-même
- Le nombre de votes positifs qu'il a reçus
Une fois l'extraction des données terminée, nous pouvons l'ajouter à une liste de réponses et enregistrer la liste finale dans un fichier JSON.
Comprendre la sortie
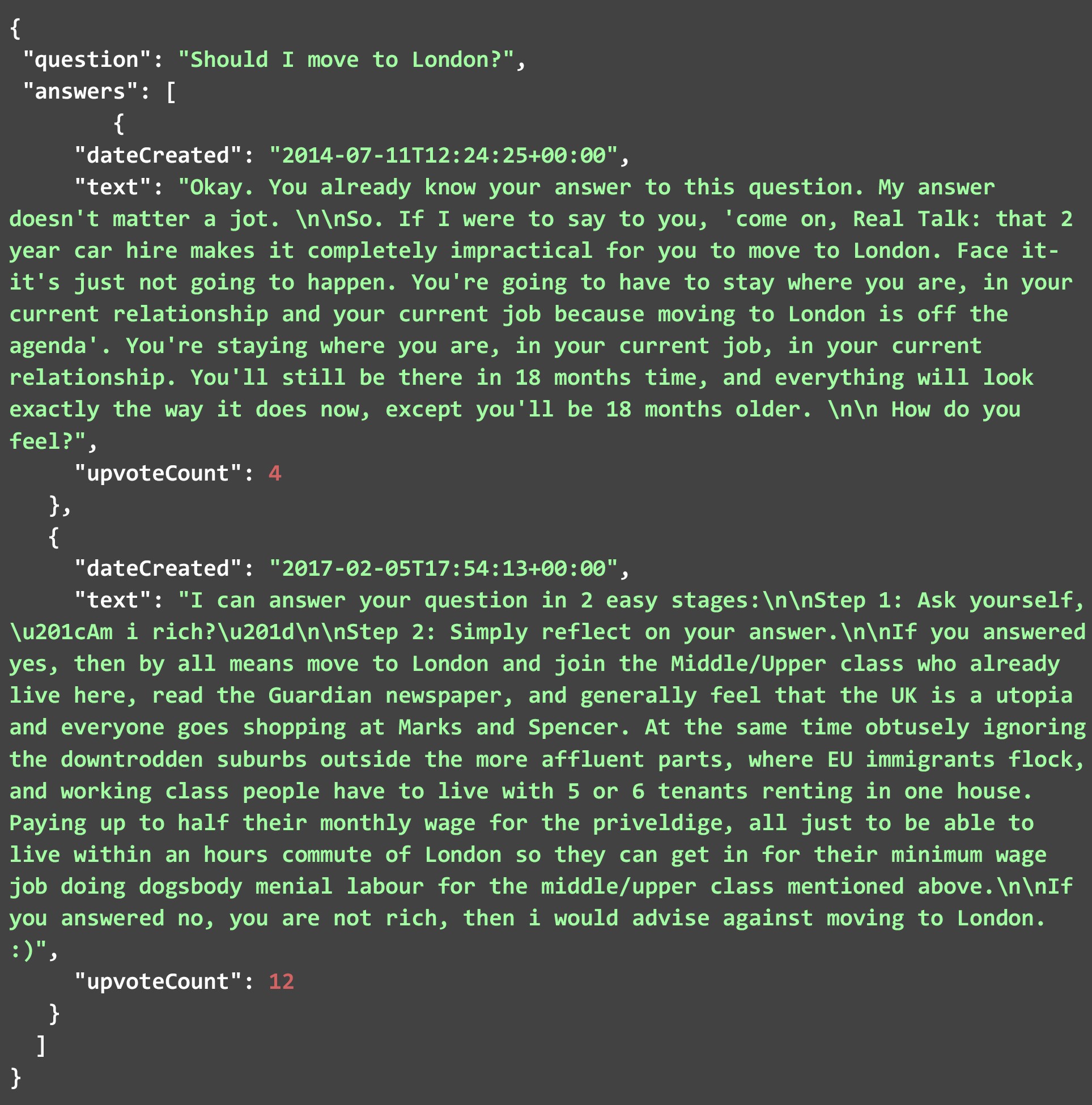
Le fichier JSON ci-dessous contient certaines des réponses extraites de la page HTML lorsque nous avons exécuté le code avec la question mentionnée dans la dernière section. Comme vous pouvez le voir, le JSON a deux champs, la question et les réponses. Chaque réponse se compose des trois paramètres que nous avons mentionnés précédemment. Alors que le nombre de réponses grattées pour cette question particulière était nombreux. Nous n'en avons montré que quelques-uns ci-dessous. N'hésitez pas à exécuter le code vous-même et à vérifier toutes les réponses à cette question, ou à toute autre.
Limitations du grattage du contenu de Quora
Bien que cela puisse sembler être une solution parfaite pour trouver les réponses à n'importe quelle question sur Quora. Comme tout autre morceau de code DIY, il est livré avec de multiples limitations. Un aspect important est que toutes les questions que vous tapez n'existeront pas dans Quora. Vous aurez votre code break chaque fois que vous tapez une question qui n'existe pas. En même temps, vous devrez peut-être taper votre question plusieurs fois pour trouver quelle version existe. Une meilleure implémentation serait de trouver la question qui correspond à celle que vous avez entrée la plus proche.
Un autre aspect à prendre en compte est celui lié aux scrupules liés au grattage des données Quora et à la manière dont vous choisissez de les utiliser. Vous devez vous assurer que vous parcourez le fichier robot.txt et que vous récupérez les données, et que vous l'utilisez en conséquence. Toute utilisation commerciale de ce code peut vous conduire à des problèmes juridiques. Et l'utilisation des données collectées à d'autres fins que la recherche peut également causer des problèmes.
En résumé
Les médias sociaux sont une mine d'or pour les données générées par les utilisateurs. Gratter les questions-réponses de Quora, c'est comme avoir accès aux points faibles de vos clients, aux goûts/aversions/intérêts de votre public. L'utilisation d'un outil de grattage intelligent élimine toutes les difficultés associées au grattage des données Quora . Une fois que vous avez extrait vos données, vous pouvez exécuter des algorithmes de ML alimentés par des réseaux de neurones et obtenir des informations critiques pour l'entreprise.