
Ihr Leitfaden für Fragen und Antworten zu Web Scrape Quora
Veröffentlicht: 2022-02-17Q&A-Sites wie Quora sind Online-Sozialisierungszentren für digitale Bürger weltweit, um die wichtigsten Fragen, Zweifel und Themen zu stellen, zu beantworten und zu diskutieren. Das Extrahieren umfangreicher Daten aus diesen Online-Q&A-Plattformen kann für Vermarkter und Datenwissenschaftler gleichermaßen nützlich sein, da es sich nicht nur um eine mehrsprachige Q&A-Website handelt, sondern auch um ein soziales Netzwerk mit vielen Nischen-Influencern. Lassen Sie uns im Detail lernen, wie man Quora scrapt.
Anwendungsfälle von Quora Scraping
Um zu betonen, warum das Scraping von Quora für Vermarkter und Unternehmen interessant ist, werfen wir einen kurzen Blick auf 4 wichtige Quora-Statistiken :
- Quora ist die Heimat von 300 Millionen monatlich aktiven Benutzern.
- Im Durchschnitt verbringen Benutzer jeden Tag mehr als 4 Minuten auf Quora.
- Vom Verkehrsaufkommen ist es die 80. beliebteste Website der Welt.
- Die Google-Suche zeigt bis zu 65 Millionen Ergebnisse für Quora[dot]com.
#1: Stimmungsanalyse
Sie können Fragen in Bezug auf Politik, Marken, Börse usw. kratzen, um eine Stimmungsanalyse durchzuführen.
Nr. 2: NLP und maschinelles Lernen
Die meisten Benutzer auf Quora sind echte Benutzer, die in ihrer täglichen Sprache Fragen und Antworten auf der Plattform stellen. Dies könnte sehr nützlich sein, um ML-Modelle und die Verarbeitung natürlicher Sprache (NLP) zu trainieren.
#3: Intelligentes Influencer-Marketing
Mit Quora können Sie Anzeigen schalten, aber Sie können auch Influencer in einer bestimmten Nische ansprechen, um für Ihre Marke zu werben. Das Scraping von Fragen, Benutzerprofilen usw. aus einer bestimmten Nische würde es Ihnen ermöglichen, mit den richtigen Influencern zusammenzuarbeiten, die über echte Autorität verfügen, um Ihre Marken zu bewerben.
#4: Lead-Generierung & Content-Marketing
Fragen, die von Benutzern gestellt werden, können Ihnen dabei helfen, festzustellen, ob es sich um Ihre Ziel-Leads handelt. Wenn Sie beispielsweise ein IT-Dienstleistungsunternehmen sind, werden Personen, die Fragen stellen wie „Wie viel kostet es, eine E-Commerce-Website zu entwickeln?“ sind Ihre potentiellen Leads. Erkenntnisse aus dem Scraping von Quora Q&As können auch Ihr Tor zu einer herausragenden Content-Marketing-Strategie sein.
So kratzen Sie Quora Q&A
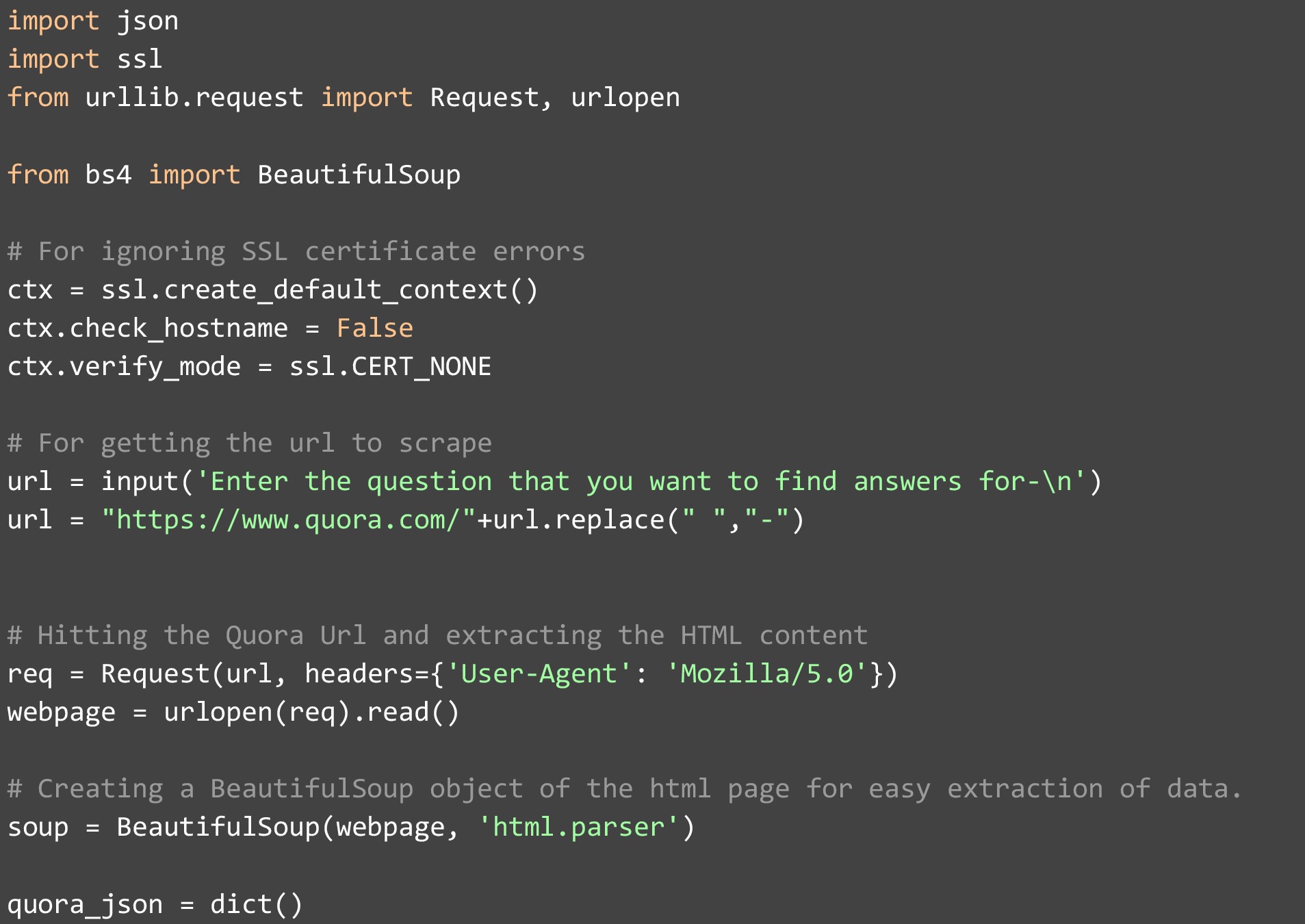
Wir werden Python 3.7 und die BeautifulSoup-Bibliothek verwenden, um Quora-Daten zu crawlen und in einer JSON-Datei zu speichern. Mit diesem Code können Sie Quora-Antworten und -Fragen einfach auslesen und extrahieren. Das einzige, was Sie noch brauchen, ist ein anständiger Texteditor. Wir haben PyCharm verwendet, eine vollwertige IDE, aber Sie können auch Atom verwenden, da es mit mehreren Plugins geliefert wird und leichter ist. Ich hoffe, dies hilft Ihnen zu verstehen, wie man Quora im Detail kratzt.
Um also mit dem Code zu beginnen, importieren wir zunächst die Bibliotheken, die wir benötigen, sowohl intern als auch extern. Sobald dies erledigt ist, müssen wir sicherstellen, dass wir den Verifizierungsmodus des SSL-Zertifikats auf „CERT_NONE“ setzen und den Hostnamen auf „False“ überprüfen, um zu vermeiden, dass wir SSL-Zertifikatsfehler erhalten, wenn wir mit dem Scraping von Daten beginnen. Sobald dies erledigt ist, ist unsere Einrichtung abgeschlossen und wir können eine Frage des Benutzers annehmen. Für diese Demo haben wir den folgenden Wert angegeben, als diese Frage gestellt wurde.


Wir erstellen die Quora-URL mit dieser Frage. Diese String-Manipulation ist erforderlich, da Quora seine URLs auf diese Weise formatiert.
Sobald wir die URL erstellt haben, verwenden wir die eingebaute Request-Funktion von urllib, um auf die Webseite zu gelangen, und stellen sicher, dass wir Firefox in den Header einfügen, damit die Website nicht nachvollziehen kann, dass wir über ein Stück Code darauf zugreifen. Dieser Teil ist wichtig, da die meisten Websites Scraper blockieren und wenn Sie den Header verpassen. Ihre IP wird wahrscheinlich gesperrt und es können weitere Maßnahmen gegen Sie eingeleitet werden.
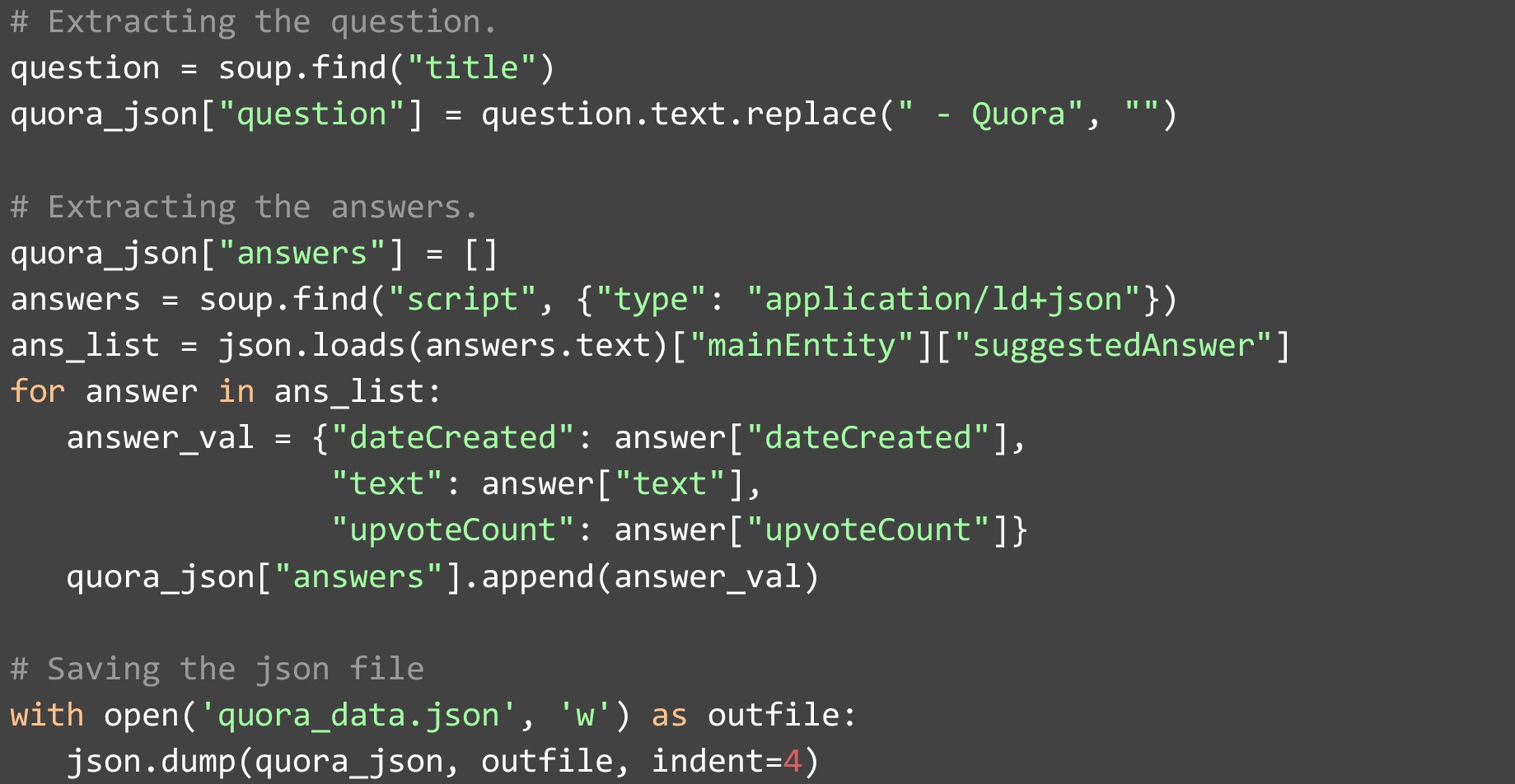
Nachdem wir die Webseite im HTML-Format erhalten und in einer Variablen gespeichert haben. Wir müssen es in ein BeautifulSoup-Objekt konvertieren, damit es einfacher ist, Daten zu analysieren und daraus zu extrahieren. Extrahieren Sie dann die Frage auf der Webseite aus dem ersten „Titel“-Tag auf der Seite. Wir müssen „ – Quora“ daraus entfernen, da alle Titel mit der folgenden Zeichenfolge kommen. Das Scraping der Antwort ist etwas komplizierter. Sie müssen das JSON extrahieren, das im Element vom Typ „script“ gespeichert ist und den Wert für „type“ als „application/ld+json“ hat. Sobald Sie diesen JSON erhalten haben, finden Sie eine Liste mit Antworten mit mehreren Feldern. Während für jede Antwort nur wenige Felder angegeben sind. Wir haben die wichtigsten herausgezogen:
- Das Datum, an dem die Antwort geschrieben wurde
- Die Antwort selbst
- Die Anzahl der Upvotes, die es erhalten hat
Sobald die Datenextraktion abgeschlossen ist, können wir sie an eine Liste mit Antworten anhängen und die endgültige Liste in einer JSON-Datei speichern.
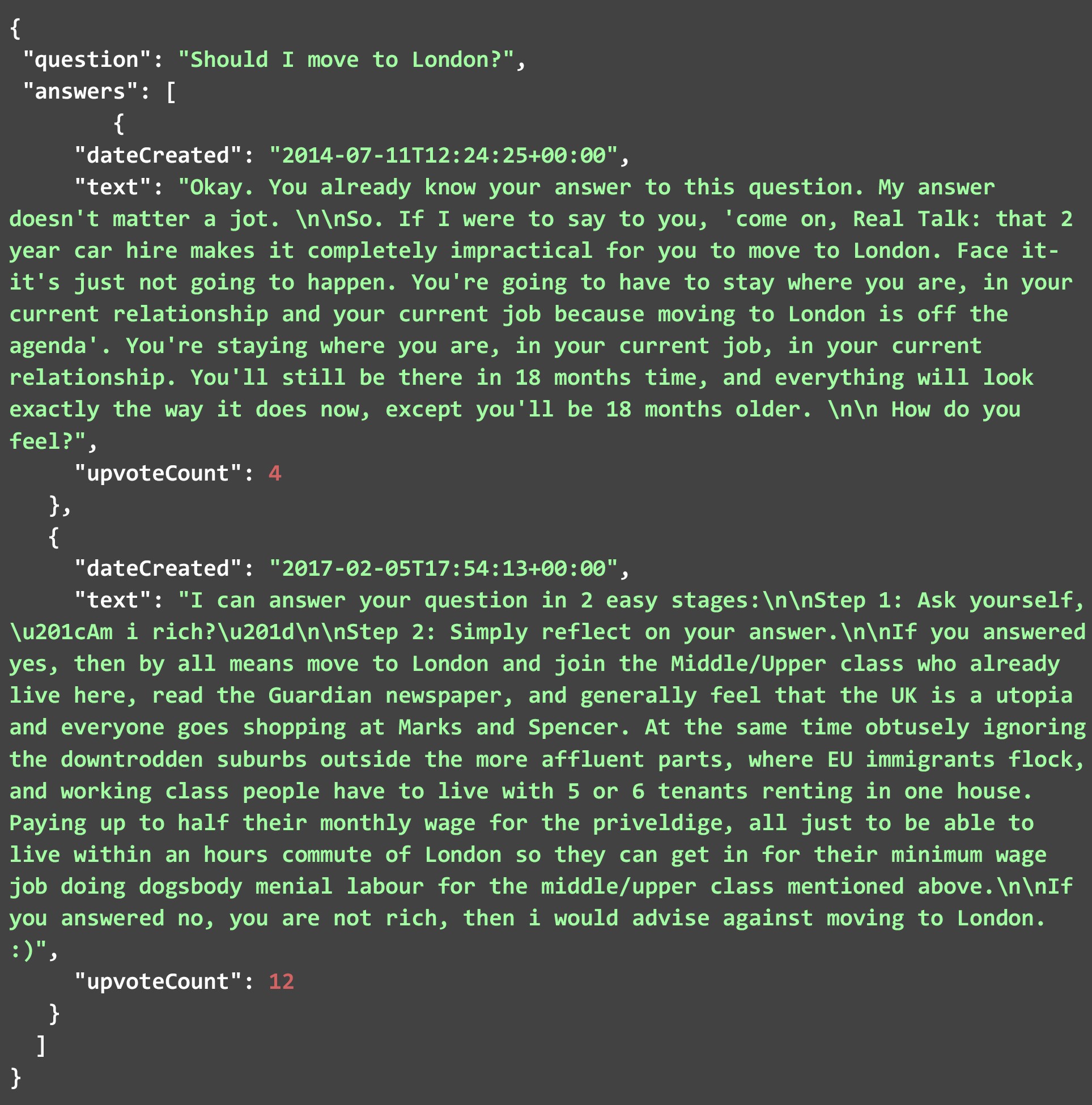
Die Ausgabe verstehen
Die unten angegebene JSON-Datei enthält einige der Antworten, die von der HTML-Seite abgekratzt wurden, als wir den Code mit der im letzten Abschnitt erwähnten Frage ausführten. Wie Sie sehen können, hat JSON zwei Felder, die Frage und die Antworten. Jede Antwort besteht aus den drei Parametern, die wir zuvor erwähnt haben. Während die Anzahl der Antworten für diese spezielle Frage zahlreich war. Nachfolgend haben wir nur einige davon gezeigt. Fühlen Sie sich frei, den Code selbst auszuführen und alle Antworten auf diese oder andere Fragen zu überprüfen.
Einschränkungen beim Scraping von Inhalten aus Quora
Dies mag zwar wie eine perfekte Lösung aussehen, um die Antworten auf alle Fragen zu Quora zu finden. Wie jeder andere DIY-Code hat er mehrere Einschränkungen. Ein wichtiger Aspekt ist, dass nicht jede Frage, die Sie eingeben, in Quora vorhanden ist. Sie werden Ihren Code jedes Mal brechen, wenn Sie eine Frage eingeben, die nicht existiert. Gleichzeitig müssen Sie Ihre Frage möglicherweise mehrmals eingeben, um herauszufinden, welche Version vorhanden ist. Eine bessere Implementierung wäre, die Frage zu finden, die der von Ihnen eingegebenen am nächsten kommt.
Ein weiterer zu berücksichtigender Aspekt bezieht sich auf die Bedenken beim Scraping von Quora-Daten und wie Sie sie verwenden. Sie müssen sicherstellen, dass Sie die robot.txt-Datei durchgehen und Daten kratzen und sie entsprechend verwenden. Jede kommerzielle Nutzung dieses Codes kann zu rechtlichen Problemen führen. Auch die Verwendung der gesammelten Daten für andere Zwecke als Forschungszwecke kann zu Problemen führen.
Zusammenfassend
Soziale Medien sind eine Goldgrube für nutzergenerierte Daten. Das Scraping von Quora Q&As ist wie der Zugang zu den Schmerzpunkten Ihrer Kunden, den Vorlieben/Abneigungen/Interessen Ihres Publikums. Die Verwendung eines intelligenten Scraping-Tools erspart Ihnen alle Mühen, die mit dem Scraping von Quora-Daten verbunden sind. Sobald Sie Ihre Daten extrahiert haben, können Sie auf neuronalen Netzwerken basierende ML-Algorithmen ausführen und geschäftskritische Erkenntnisse gewinnen.