
Web Scrape Quora Q&A ガイド
公開: 2022-02-17Quora のような Q&A サイトは、世界中のデジタル市民が最も重要な問題、疑問、トピックについて質問し、回答し、議論するためのオンライン ソーシャル ハブです。 これらのオンライン Q&A プラットフォームから大規模なデータを抽出することは、マーケティング担当者とデータ サイエンティストの両方に役立つ可能性があります。これは、多言語 Q&A Web サイトであるだけでなく、それ自体が多くのニッチ インフルエンサーを含むソーシャル ネットワークでもあるためです。 Quoraをスクレイピングする方法を詳しく学びましょう。
Quora Scrapingのユースケース
Quoraのスクレイピングがマーケティング担当者や企業にとって興味深い理由を強調するために、 Quoraの4つの重要な統計を簡単に見てみましょう。
- Quora には 3 億人の月間アクティブ ユーザーがいます。
- 平均的なユーザーは、毎日 4 分以上 Quora に費やしています。
- トラフィック量から、世界で 80 番目に人気のある Web サイトです。
- Google 検索では、Quora[dot]com の結果が 6,500 万件も表示されます。
#1: 感情分析
政治、ブランド、株式市場などに関連する質問をスクレイピングして、センチメント分析を実行できます。
#2: NLP と機械学習
Quora のユーザーのほとんどは実際のユーザーであり、プラットフォーム上で日常用語で質問と回答を行っています。 これは、ML モデルや自然言語処理 (NLP) のトレーニングに非常に役立ちます。
#3: インテリジェントなインフルエンサー マーケティング
Quoraでは広告を掲載できますが、特定のニッチなインフルエンサーをターゲットにしてブランドを宣伝することもできます. 特定のニッチから質問やユーザー プロファイルなどを収集することで、ブランドを宣伝する真の権限を持つ適切なインフルエンサーと提携することができます。
#4: リード生成とコンテンツ マーケティング
ユーザーからの質問は、ターゲット リードであるかどうかを特定するのに役立ちます。 たとえば、IT サービス会社の場合、「e コマース Web サイトを開発するのにいくらかかりましたか?」などの質問をする人がいます。 あなたの潜在的なリードです。 Quora Q&A をスクレイピングして得た洞察は、優れたコンテンツ マーケティング戦略への入り口にもなります。
Quora Q&Aをスクレイプする方法
Python3.7 と BeautifulSoup ライブラリを使用して Quora データをクロールし、JSON ファイルに保存します。 このコードを使用すると、Quora の回答と質問を簡単にスクレイピングして抽出できます。 他に必要なものはまともなテキスト エディタだけです。 本格的な IDE である PyCharm を使用しましたが、複数のプラグインが付属しており、より軽量であるため、Atom を使用することもできます。 これが、Quora を詳細にスクレイピングする方法を理解するのに役立つことを願っています。

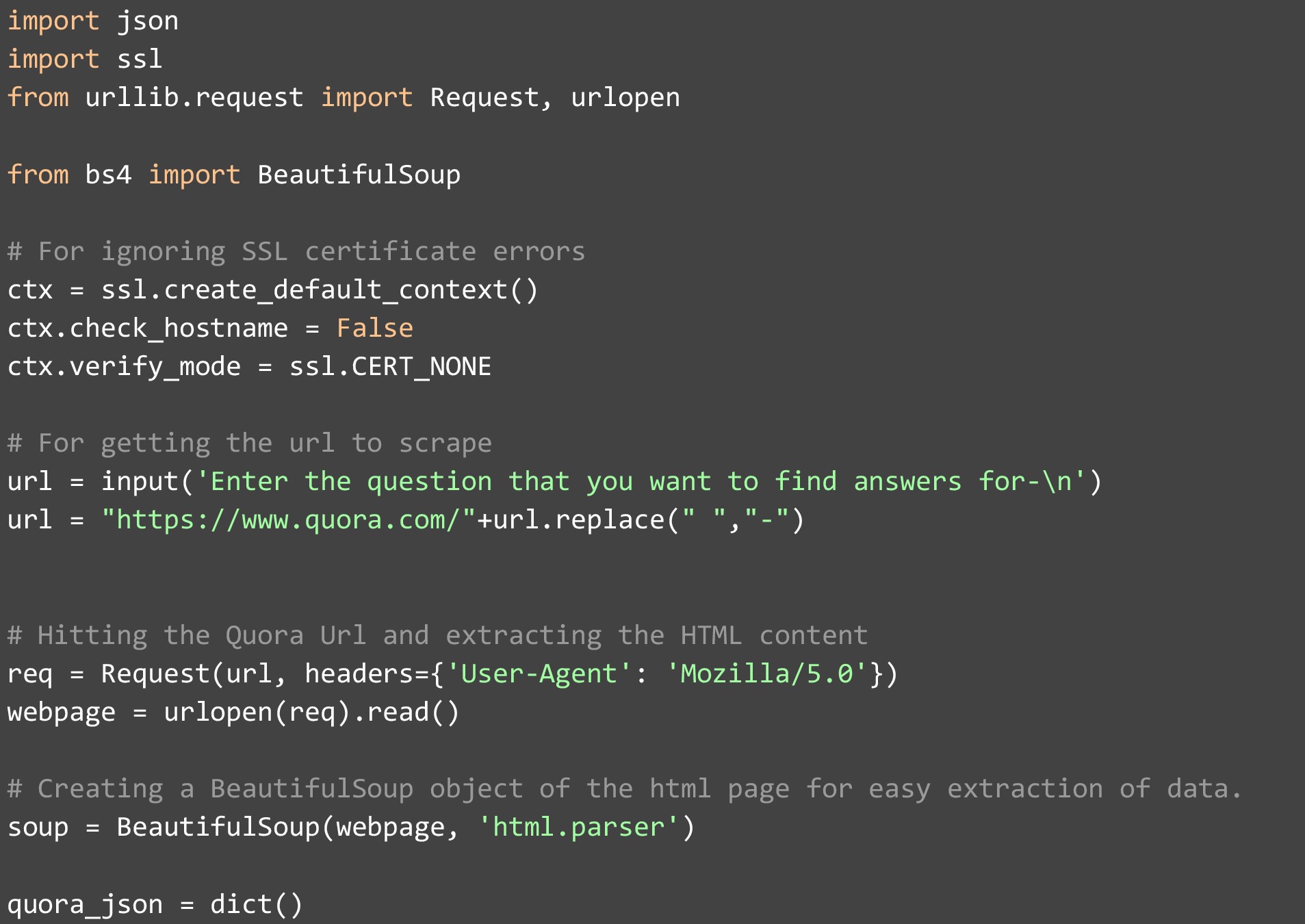
コードから始めるには、内部と外部の両方で必要になるライブラリをインポートすることから始めます。 完了したら、データのスクレイピングを開始するときに SSL 証明書エラーが発生しないように、SSL 証明書の検証モードを「CERT_NONE」に設定し、ホスト名を False にチェックする必要があります。 これが完了すると、セットアップが完了し、ユーザーからの質問を受け入れることができます。 このデモでは、この質問が行われたときに次の値を提供しました。

この質問を使用して Quora URL を作成します。 Quora は URL をこのようにフォーマットするため、この文字列操作が必要です。
URL を作成したら、urllib の組み込み Request 関数を使用して Web ページにアクセスし、ヘッダーに Firefox を追加して、コードからアクセスしていることを Web サイトが追跡できないようにします。 ほとんどの Web サイトはスクレーパーをブロックし、ヘッダーを見逃すと、この部分が重要になります。 あなたの IP はブロックされる可能性が高く、あなたに対してさらなるアクションが開始される可能性があります。
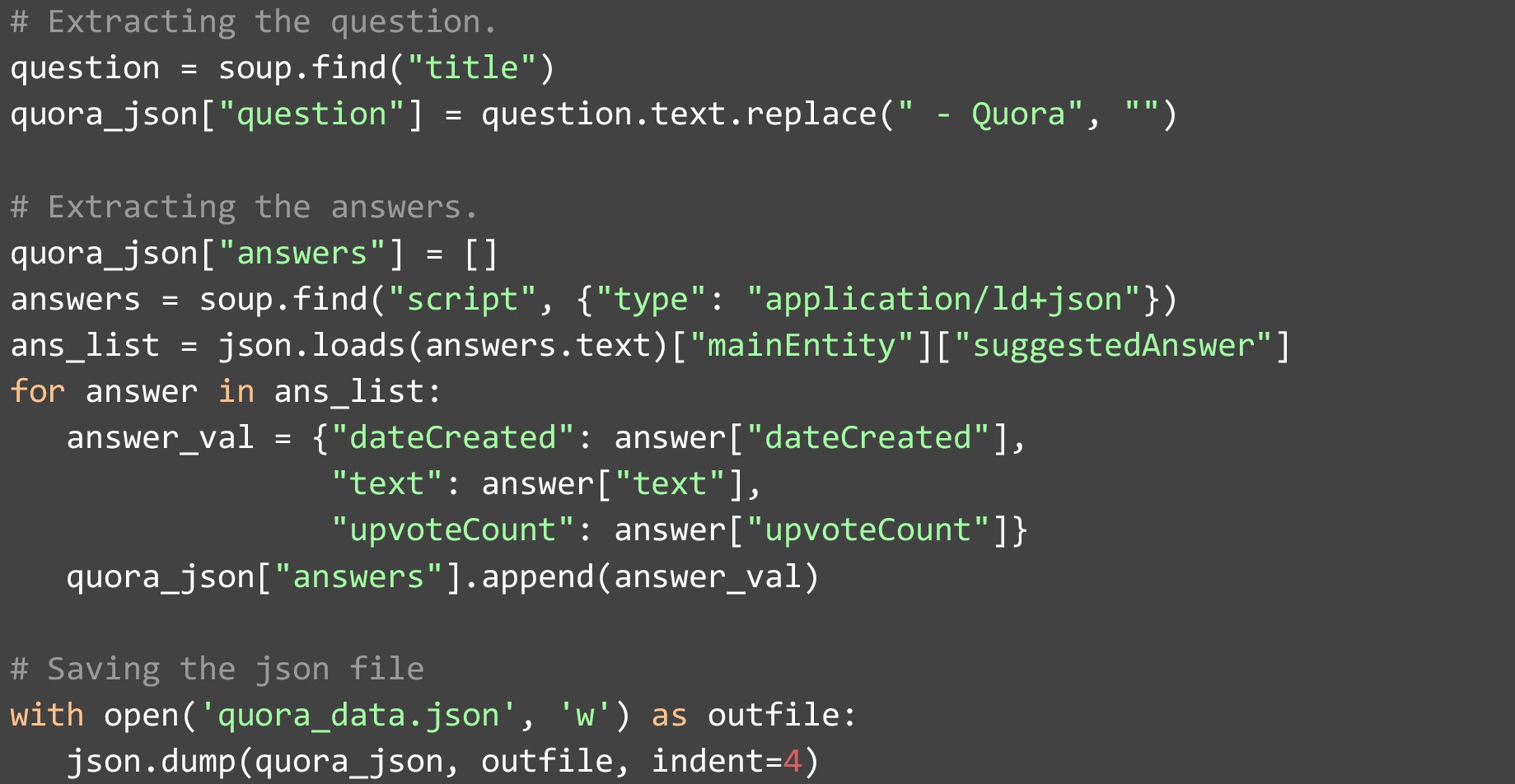
Web ページを HTML 形式で取得し、変数に格納した後。 データの解析と抽出が容易になるように、これを BeautifulSoup オブジェクトに変換する必要があります。 次に、ページの最初の「タイトル」タグから Web ページの質問を抽出します。 すべてのタイトルには次の文字列が付いているため、「 – Quora 」を削除する必要があります。 答えをスクレイピングするのは少し複雑です。 「type」の値が「application/ld+json」であるタイプ「script」の要素に格納されている JSON を抽出する必要があります。 この JSON を取得すると、複数のフィールドを含む回答のリストが表示されます。 各回答にいくつかのフィールドが与えられていますが。 最も重要なものを抽出しました。
- 回答を書いた日付
- 答え自体
- 受け取った賛成票の数
データ抽出が完了したら、それを回答のリストに追加し、最終的なリストを JSON ファイルに保存できます。
出力を理解する
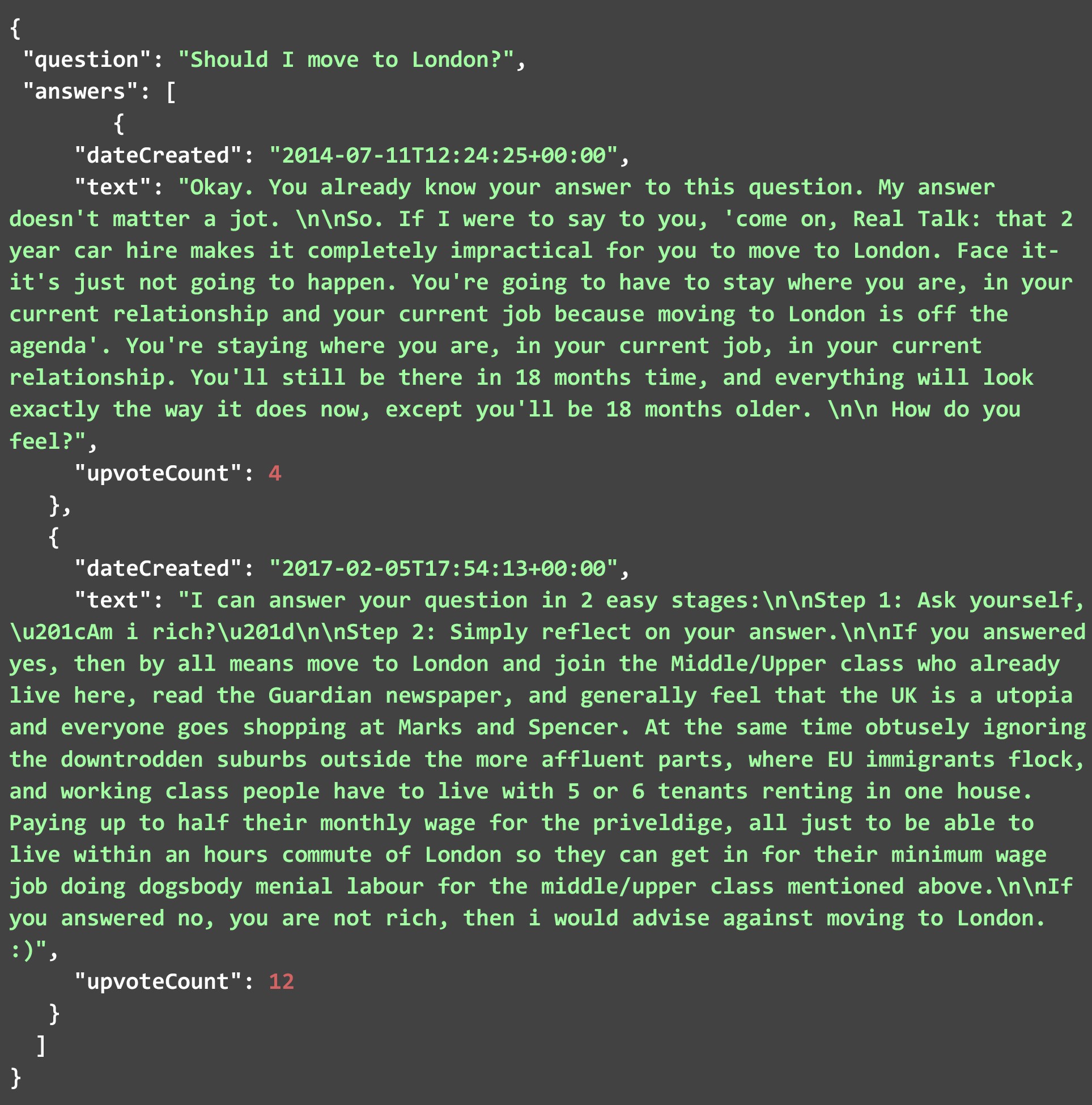
以下の JSON ファイルには、前のセクションで説明した質問でコードを実行したときに HTML ページからスクレイピングされた回答の一部が含まれています。 ご覧のとおり、JSON には質問と回答の 2 つのフィールドがあります。 各回答は、前述の 3 つのパラメーターで構成されます。 この特定の質問に対してスクレイピングされた回答の数は多くありましたが. 以下にそれらのほんの一部を示しました。 自分でコードを実行して、この質問またはその他の質問に対するすべての回答を確認してください。
Quoraからコンテンツをスクレイピングする際の制限
これは、Quora で質問に対する答えを見つけるための完璧な解決策のように見えるかもしれません。 他のすべての DIY コードと同様に、いくつかの制限があります。 重要な点の 1 つは、入力したすべての質問が Quora に存在するわけではないということです。 存在しない質問を入力するたびに、コードが壊れます。 同時に、存在するバージョンを見つけるために、質問を複数回入力する必要がある場合があります。 より適切な実装は、入力した質問に最も近い質問を見つけることです。
考慮すべきもう1つの側面は、Quoraデータをスクレイピングする際の不安と、それをどのように使用するかに関するものです. robot.txt ファイルを調べてデータをスクレイピングし、それに応じて使用する必要があります。 このコードを商業的に使用すると、法的な問題が発生する可能性があります。 また、収集したデータを研究目的以外に使用することも問題を引き起こす可能性があります。
要約すれば
ソーシャル メディアは、ユーザー生成データの宝庫です。 Quora の Q&A をスクレイピングすることは、顧客の問題点、聴衆の好き/嫌い/興味にアクセスするようなものです。 インテリジェントなスクレイピング ツールを使用すると、 Quora データのスクレイピングに関連するすべての問題が解消されます。 データを抽出したら、ニューラル ネットワークを利用した ML アルゴリズムを実行して、ビジネスに不可欠な洞察を得ることができます。