
Web Scrape Quora Q&A 가이드
게시 됨: 2022-02-17Quora와 같은 Q&A 사이트는 전 세계 디지털 시민이 가장 두드러진 문제, 의심 및 주제를 묻고, 답변하고, 토론할 수 있는 온라인 사회화 허브입니다. 이러한 온라인 Q&A 플랫폼에서 대규모 데이터를 추출하는 것은 다국어 Q&A 웹사이트일 뿐만 아니라 많은 틈새 인플루언서가 있는 그 자체로 소셜 네트워크이기 때문에 마케터와 데이터 과학자 모두에게 유용할 수 있습니다. Quora 긁는 방법에 대해 자세히 알아봅시다.
Quora 스크래핑의 사용 사례
Quora 스크래핑이 마케터와 비즈니스에 관심이 있는 이유를 강조하기 위해 4가지 중요한 Quora 통계 를 간단히 살펴보겠습니다 .
- Quora의 월간 활성 사용자는 3억 명입니다.
- 평균적으로 사용자는 매일 Quora에서 4분 이상을 보냅니다.
- 트래픽 양에서 세계에서 80번째로 인기 있는 웹사이트입니다.
- Google 검색 은 Quora[dot]com에 대해 최대 6,500만 개의 결과를 보여줍니다.
#1: 감정 분석
정치, 브랜드, 주식 시장 등과 관련된 질문을 스크랩하여 감성 분석을 수행할 수 있습니다.
#2: NLP 및 기계 학습
Quora의 사용자 대부분은 일상적인 용어로 플랫폼에서 질문과 답변을 하는 실제 사용자입니다. 이는 ML 모델 및 NLP(자연어 처리) 교육에 매우 유용할 수 있습니다.
#3: 지능형 인플루언서 마케팅
Quora를 사용하면 광고를 실행할 수 있지만 특정 틈새 시장의 인플루언서를 타겟팅하여 브랜드를 홍보할 수도 있습니다. 특정 틈새 시장에서 질문, 사용자 프로필 등을 스크랩하면 브랜드를 홍보할 실제 권한을 가진 올바른 영향력 있는 사람과 파트너가 될 수 있습니다.
#4: 리드 생성 및 콘텐츠 마케팅
사용자가 묻는 질문은 대상 리드인지 식별하는 데 도움이 될 수 있습니다. 예를 들어 IT 서비스 회사인 경우 "전자 상거래 웹사이트를 개발하는 데 비용이 얼마나 드나요?"와 같은 질문을 하는 사람들이 있습니다. 당신의 잠재적인 리드입니다. Quora Q&A를 스크랩하여 얻은 통찰력은 뛰어난 콘텐츠 마케팅 전략의 관문이 될 수도 있습니다.
Quora Q&A를 스크랩하는 방법
우리는 Python3.7과 BeautifulSoup 라이브러리를 사용하여 Quora 데이터를 크롤링하고 JSON 파일에 저장할 것입니다. 이 코드를 사용하면 Quora의 답변과 질문을 쉽게 스크랩하고 추출할 수 있습니다. 당신이 필요로하는 유일한 다른 것은 괜찮은 텍스트 편집기입니다. 우리는 완전한 IDE인 PyCharm을 사용했지만 여러 플러그인이 함께 제공되고 더 가볍기 때문에 Atom을 사용할 수도 있습니다. 이것이 Quora를 자세히 긁는 방법을 이해하는 데 도움이 되기를 바랍니다.

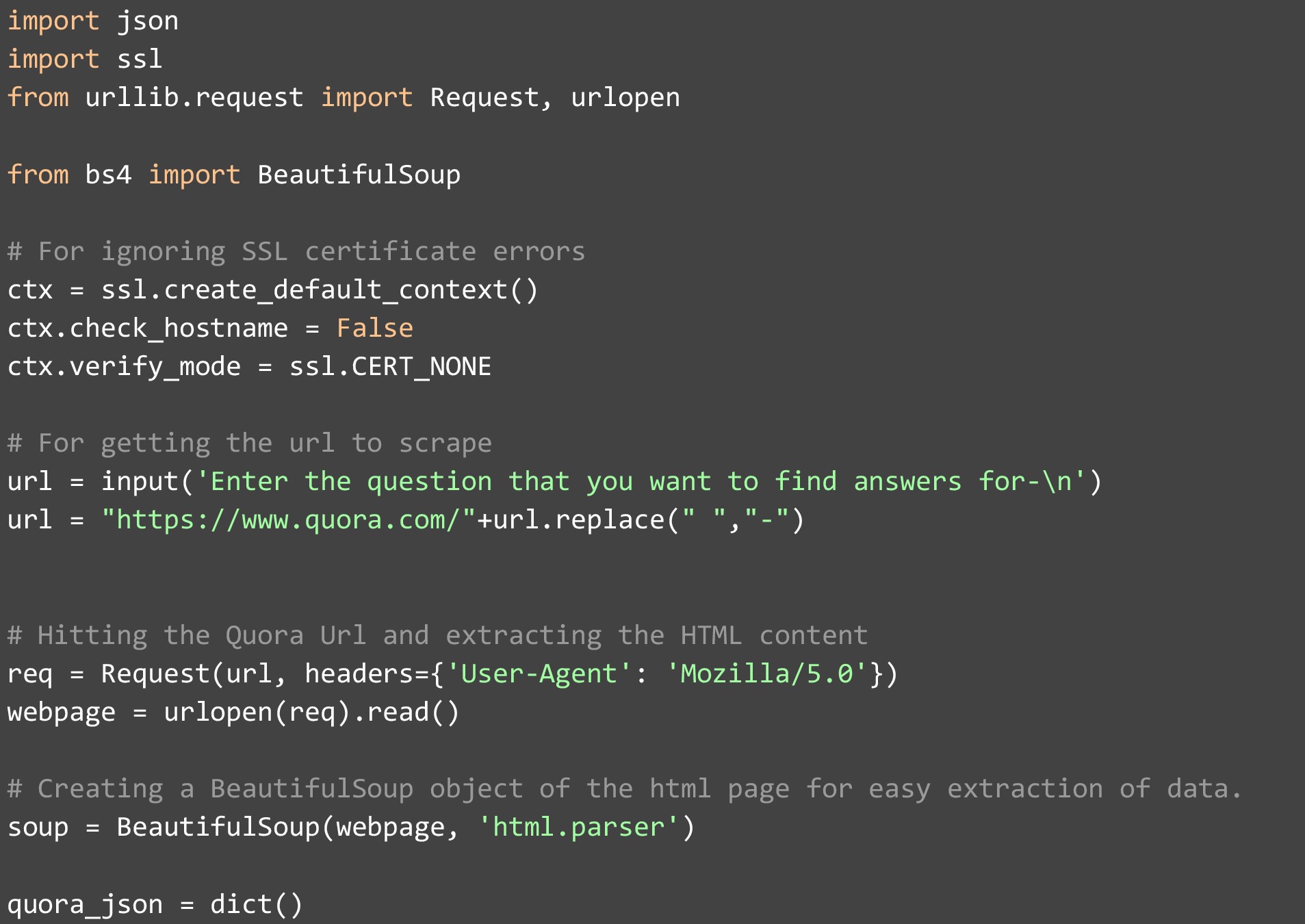
따라서 코드로 시작하려면 내부 및 외부에서 필요한 라이브러리를 가져오는 것으로 시작합니다. 완료되면 SSL 인증서의 확인 모드를 "CERT_NONE"으로 설정하고 호스트 이름을 False로 설정하여 데이터 스크랩을 시작할 때 SSL 인증서 오류가 발생하지 않도록 해야 합니다. 이 작업이 완료되면 설정이 완료되고 사용자의 질문을 수락할 수 있습니다. 이 데모에서는 이 질문을 받았을 때 다음 값을 제공했습니다.

이 질문을 사용하여 Quora URL을 만듭니다. Quora는 이러한 방식으로 URL 형식을 지정하기 때문에 이 문자열 조작이 필요합니다.
URL을 생성한 후에는 urllib의 내장된 요청 기능을 사용하여 웹 페이지를 방문하고 헤더에 Firefox를 추가하여 웹 사이트가 코드에서 액세스하고 있음을 추적할 수 없도록 합니다. 대부분의 웹사이트가 스크레이퍼를 차단하고 헤더를 놓치면 이 부분이 중요합니다. 귀하의 IP가 차단될 가능성이 있으며 귀하에 대해 추가 조치가 시작될 수 있습니다.
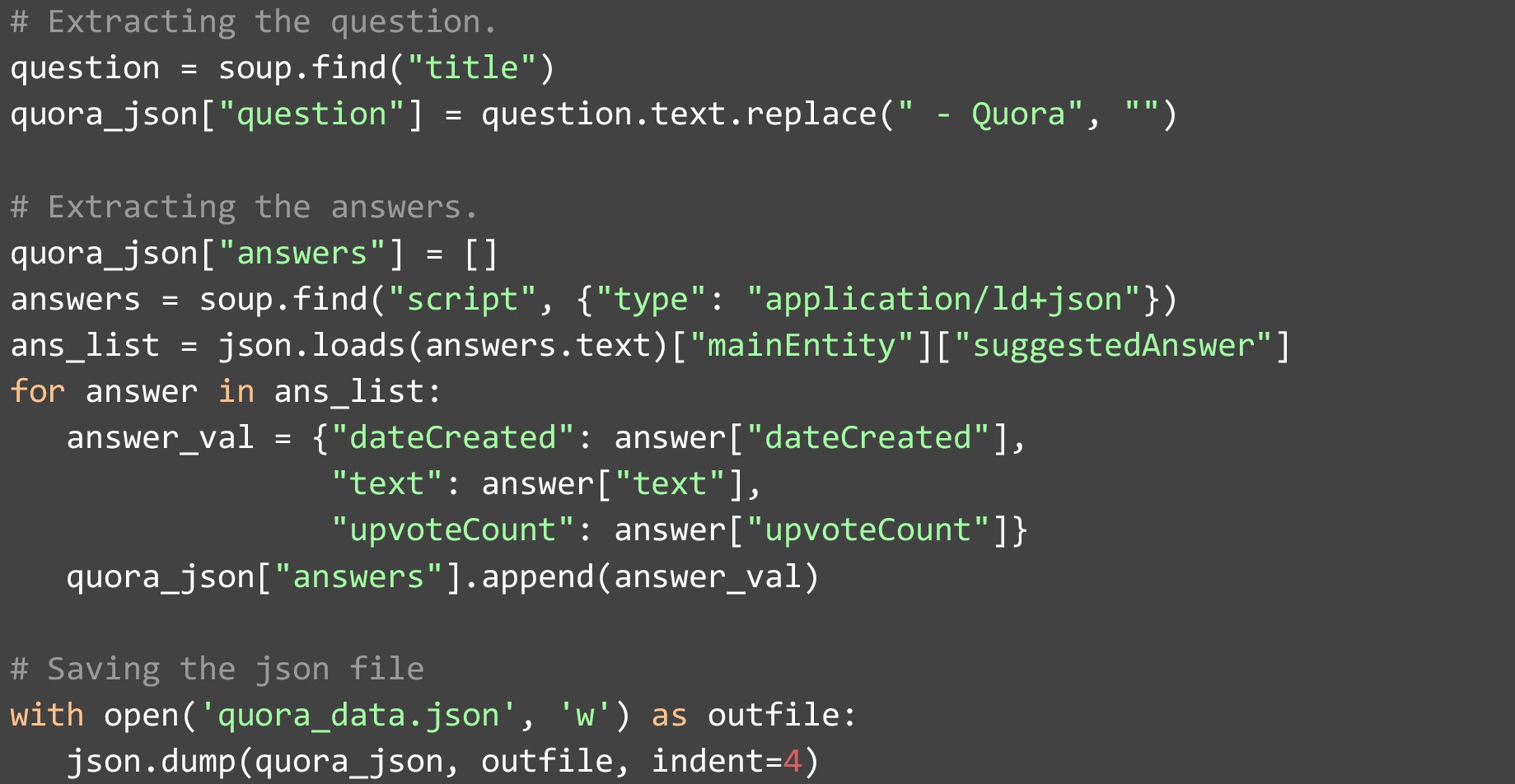
웹 페이지를 HTML 형식으로 가져와 변수에 저장한 후. 데이터를 더 쉽게 구문 분석하고 추출할 수 있도록 BeautifulSoup 객체로 변환해야 합니다. 그런 다음 페이지의 첫 번째 "제목" 태그에서 웹페이지의 질문을 추출합니다. 모든 제목에는 다음 문자열이 포함되므로 " – Quora"를 제거해야 합니다. 답을 스크랩하는 것은 약간 더 복잡합니다. "type" 값이 "application/ld+json"인 "script" 유형의 요소에 저장된 JSON을 추출해야 합니다. 이 JSON을 얻으면 여러 필드가 있는 답변 목록을 찾을 수 있습니다. 각 답변에 대해 몇 개의 필드가 제공됩니다. 우리는 가장 중요한 것들을 추출했습니다:
- 답변이 작성된 날짜
- 답 자체
- 받은 추천 수
데이터 추출이 완료되면 답변 목록에 추가하고 최종 목록을 JSON 파일에 저장할 수 있습니다.
출력 이해하기
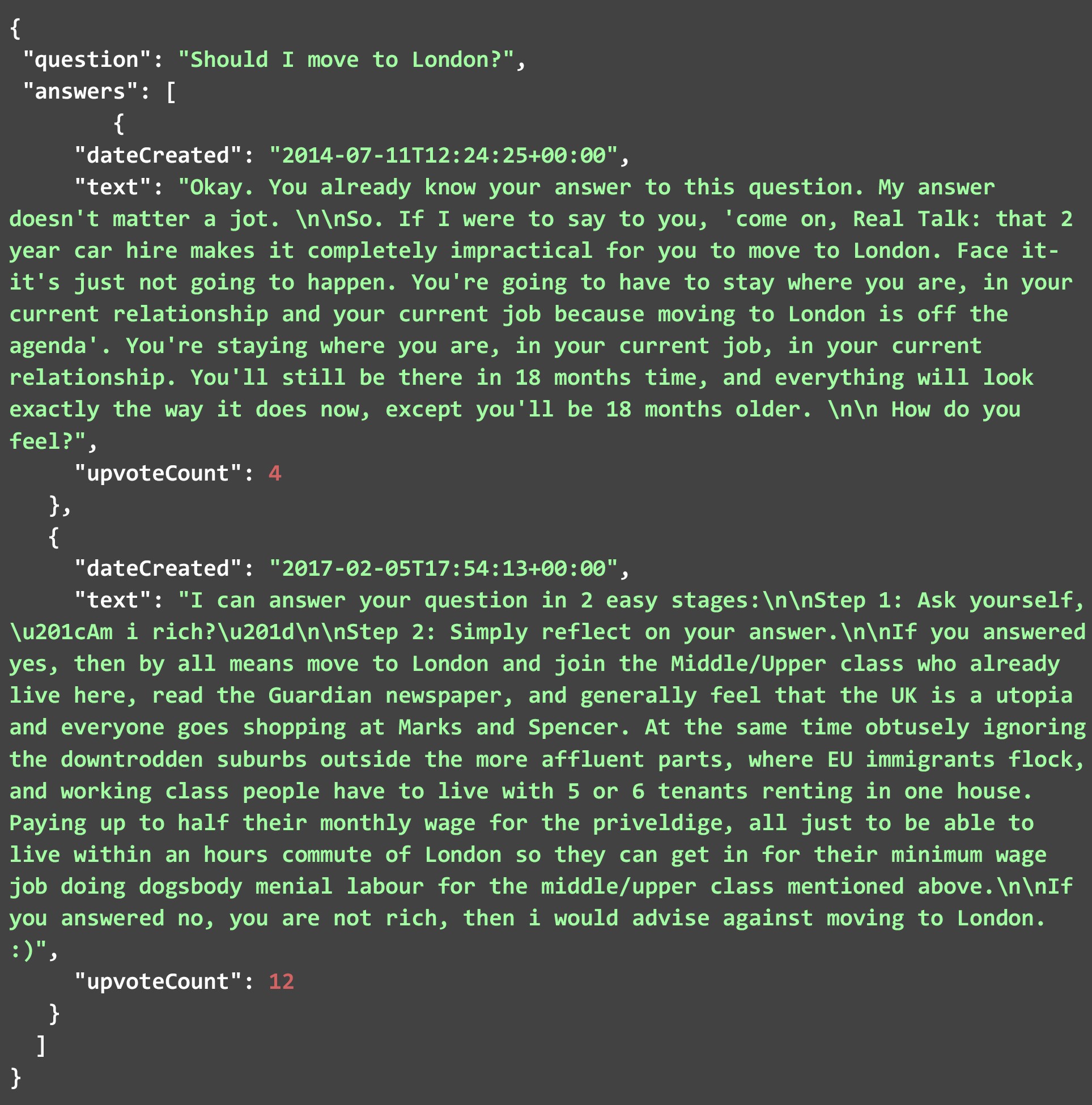
아래의 JSON 파일에는 마지막 섹션에서 언급한 질문으로 코드를 실행할 때 HTML 페이지에서 스크랩한 답변 중 일부가 포함되어 있습니다. 보시다시피 JSON에는 질문과 답변이라는 두 개의 필드가 있습니다. 각 답변은 앞에서 언급한 세 가지 매개변수로 구성됩니다. 이 특정 질문에 대해 스크랩한 답변의 수는 많았습니다. 아래에는 그 중 몇 가지만 표시했습니다. 코드를 직접 실행하고 이 질문 또는 다른 질문에 대한 모든 답변을 확인하십시오.
Quora에서 콘텐츠 스크래핑의 제한 사항
이것은 Quora에 대한 모든 질문에 대한 답변을 찾는 완벽한 솔루션처럼 보일 수 있습니다. 다른 모든 DIY 코드와 마찬가지로 여러 제한 사항이 있습니다. 한 가지 중요한 측면은 입력하는 모든 질문이 Quora에 존재하는 것은 아니라는 것입니다. 존재하지 않는 질문을 입력할 때마다 코드가 중단됩니다. 동시에 어떤 버전이 있는지 찾기 위해 질문을 여러 번 입력해야 할 수도 있습니다. 더 나은 구현은 가장 가깝게 입력한 질문과 일치하는 질문을 찾는 것입니다.
고려해야 할 또 다른 측면은 Quora 데이터 스크래핑의 문제 및 사용 방법과 관련된 것입니다. 반드시 robots.txt 파일을 훑어보고 데이터를 스크랩하여 적절히 사용해야 합니다. 이 코드를 상업적으로 사용하면 법적 문제가 발생할 수 있습니다. 또한 수집된 데이터를 연구 목적 이외의 용도로 사용하는 경우에도 문제가 발생할 수 있습니다.
요약해서 말하자면
소셜 미디어는 사용자 생성 데이터의 금광입니다. Quora Q&A를 스크랩하는 것은 고객의 문제점, 청중의 좋아요/싫어요/관심에 대한 액세스 권한을 얻는 것과 같습니다. 지능형 스크래핑 도구를 사용하면 Quora 데이터를 스크래핑 하는 것과 관련된 모든 수고를 덜 수 있습니다. 데이터를 추출하면 신경망 기반 ML 알고리즘을 실행하고 비즈니스에 중요한 통찰력을 얻을 수 있습니다.