
การแสดงข้อมูลและวิเคราะห์เนื้อเพลงของ Taylor Swift
เผยแพร่แล้ว: 2018-07-19รู้หรือไม่ เทย์เลอร์ สวิฟต์ เป็นคนที่อายุน้อยที่สุดที่เขียนและแสดงเพลงอันดับหนึ่งบนชาร์ต Hot Country Songs ที่จัดพิมพ์โดยนิตยสาร Billboard ในสหรัฐอเมริกา! เธอเป็นที่รู้จักโดยเฉพาะอย่างยิ่งในการใส่ชีวิตส่วนตัวของเธอลงในเพลงของเธอซึ่งได้รับความคุ้มครองจากสื่อมากมาย การวิเคราะห์เนื้อเพลงของเทย์เลอร์ สวิฟต์ผ่านการวิเคราะห์เชิงสำรวจและการวิเคราะห์ความรู้สึกจะเป็นเรื่องที่น่าสนใจ เพื่อค้นหาธีมพื้นฐานต่างๆ
ชุดข้อมูลสำหรับวิเคราะห์เนื้อเพลงของ Taylor Swift
ขอบคุณ API ที่น่าทึ่งที่เปิดเผยโดย Genius.com ทำให้เราดึงจุดข้อมูลต่างๆ ที่เกี่ยวข้องกับเพลงของ Taylor Swift ได้
เราได้เลือกเพียงหกอัลบั้มที่ออกโดยเธอและนำเพลงที่ซ้ำกันออก (อะคูสติก เวอร์ชันสหรัฐอเมริกา ป๊อปมิกซ์ การบันทึกการสาธิต ฯลฯ) ส่งผลให้มีแทร็กที่ไม่ซ้ำ 94 แทร็กพร้อมฟิลด์ข้อมูลต่อไปนี้:
- ชื่ออัลบั้ม
- ชื่อเพลง
- หมายเลขแทร็ก
- เนื้อเพลง
- หมายเลขสาย
- ปีที่ออกอัลบั้ม
[call_to_action title="ดาวน์โหลดชุดข้อมูลฟรี" icon="icon-download" link="https://app.promptcloud.com/users/sign_up?target=data_stocks&itm_source=website&itm_medium=blog&itm_campaign=dataviz&itm_term=ts-lyrics&itm_content= data-mining" button_title="" class="" target="_blank" animate=""]ลงทะเบียนสำหรับ DataStock ผ่าน CrawlBoard และคลิกที่หมวดหมู่ 'ฟรี' เพื่อดาวน์โหลดชุดข้อมูล![/call_to_action]
เป้าหมาย
เป้าหมายของเราคือทำการวิเคราะห์เชิงสำรวจก่อน จากนั้นจึงย้ายไปที่การทำเหมืองข้อความ รวมถึงการวิเคราะห์ความรู้สึกซึ่งเกี่ยวข้องกับการประมวลผลภาษาธรรมชาติ
– การวิเคราะห์เชิงสำรวจ
- จำนวนคำตามเพลงและอัลบั้ม
- การวิเคราะห์อนุกรมเวลาของการนับคำ
- การกระจายจำนวนคำ
– การขุดข้อความ
- เมฆคำ
- เครือข่ายบิ๊กราม
- การวิเคราะห์ความรู้สึก (รวมถึงแผนภาพคอร์ด)
เราจะใช้ R และ ggplot2 เพื่อวิเคราะห์และแสดงข้อมูลเป็นภาพ มีโค้ดรวมอยู่ในโพสต์นี้ด้วย ดังนั้นหากคุณดาวน์โหลดข้อมูล ก็สามารถทำตามได้
การวิเคราะห์เชิงสำรวจ
มาค้นหาเพลงสิบอันดับแรกที่มีจำนวนคำมากที่สุดกันก่อน ข้อมูลโค้ดด้านล่างประกอบด้วยแพ็คเกจที่จำเป็นในการวิเคราะห์นี้และค้นหาเพลงยอดนิยมในแง่ของความยาว
[รหัสภาษา =”r”]
ห้องสมุด(magrittr)
ห้องสมุด(stringr)
ห้องสมุด (dplyr)
ห้องสมุด (ggplot2)
ห้องสมุด(TM)
ห้องสมุด (wordcloud)
ห้องสมุด(syuzhet)
ห้องสมุด(tidytext)
ห้องสมุด (tidyr)
ห้องสมุด (igraph)
ห้องสมุด(ggraph)
ห้องสมุด (ผู้อ่าน)
ห้องสมุด(วงกลม)
ห้องสมุด(ก่อร่างใหม่2)
เนื้อเพลง <- read.csv(file.choose())
เนื้อเพลง$ความยาว <- str_count(lyrics$lyric,”S+”)
length_df <- เนื้อเพลง %>%
group_by(track_title) %>%
สรุป (ความยาว = ผลรวม (ความยาว))
length_df %>%
จัด(เดสก์(ความยาว)) %>%
ชิ้น(1:10) %>%
ggplot(., aes(x= จัดลำดับใหม่(track_title, -length), y=length)) +
geom_bar(stat='identity', fill=”#1CCCC6″) +
ylab("จำนวนคำ") + xlab ("ชื่อแทร็ก") +
ggtitle(“10 อันดับเพลงในแง่ของจำนวนคำ”) +
theme_minimal() +
scale_x_discrete (ป้ายกำกับ = ฟังก์ชัน (ป้ายกำกับ) {
sapply(seq_along(labels), function(i) paste0(ifelse(i %% 2 == 0, ”, 'n'), labels[i]))
})
[/รหัส]
สิ่งนี้ทำให้เรามีแผนภูมิต่อไปนี้:
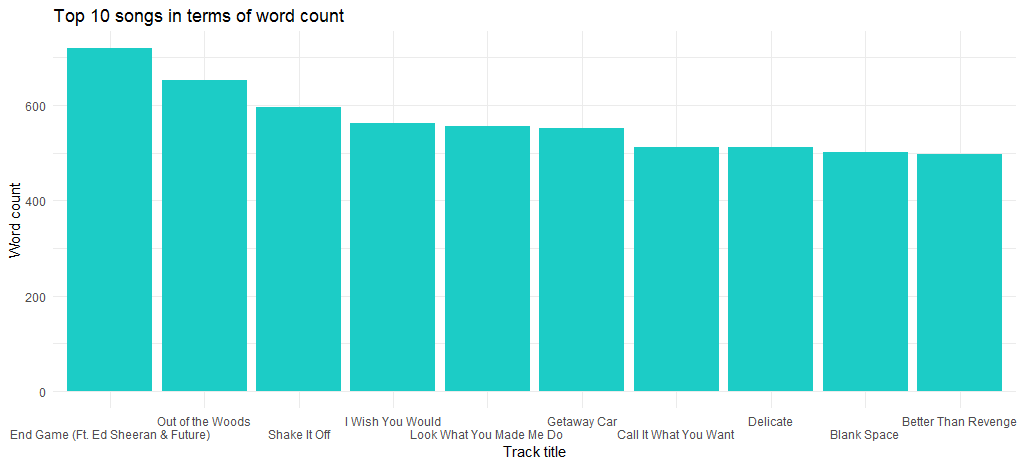
เราจะเห็นได้ว่า “End Game” (ออกในอัลบั้มล่าสุดของเธอ) เป็นเพลงที่มีจำนวนคำสูงสุดและในบรรทัดถัดไปคือ “Out of the Woods”
แล้วเพลงที่มีจำนวนคำน้อยที่สุดล่ะ? ลองหาโดยใช้รหัสต่อไปนี้:
[รหัสภาษา =”r”]
length_df %>%
จัด (ความยาว) %>%
ชิ้น(1:10) %>%
ggplot(., aes(x= จัดลำดับใหม่(track_title, length), y=length)) +
geom_bar(stat='identity', fill=”#1CCCC6″) +
ylab("จำนวนคำ") + xlab ("ชื่อแทร็ก") +
ggtitle(“10 เพลงที่มีจำนวนคำน้อยที่สุด”) +
theme_minimal() +
scale_x_discrete (ป้ายกำกับ = ฟังก์ชัน (ป้ายกำกับ) {
sapply(seq_along(labels), function(i) paste0(ifelse(i %% 2 == 0, ”, 'n'), labels[i]))
})
[/รหัส]
ส่งผลให้แผนภูมิต่อไปนี้:
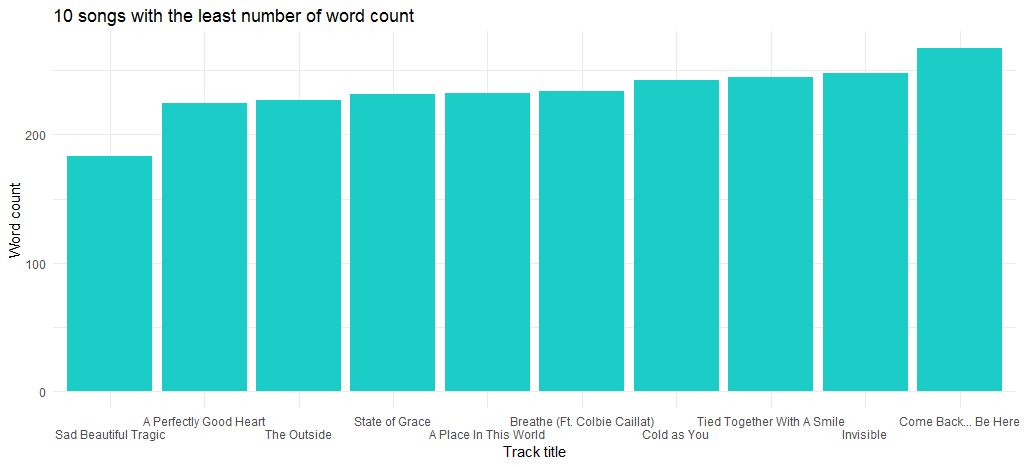
เพลง “Sad Beautiful Tragic” ที่ออกในปี 2555 โดยเป็นส่วนหนึ่งของอัลบั้ม “Red” เป็นเพลงที่มีจำนวนคำน้อยที่สุด
การวิเคราะห์ข้อมูลครั้งต่อไปจะเน้นที่การกระจายจำนวนคำ รับด้านล่างเป็นรหัส:
[รหัสภาษา =”r”]
ggplot(length_df, aes(x=length)) +
geom_histogram(bins=30,aes(fill = ..count..)) +
geom_vline(aes(xintercept=mean(length)))
color=”#FFFFFF”, linetype=”dash”, size=1) +
geom_density(aes(y=25 * ..count..),alpha=.2, fill=”#1CCCC6″) +
ylab(“นับ”) + xlab (“ขา”) +
ggtitle("การกระจายจำนวนคำ") +
theme_minimal()
[/รหัส]
รหัสนี้ให้ฮิสโตแกรมต่อไปนี้พร้อมกับกราฟความหนาแน่น:
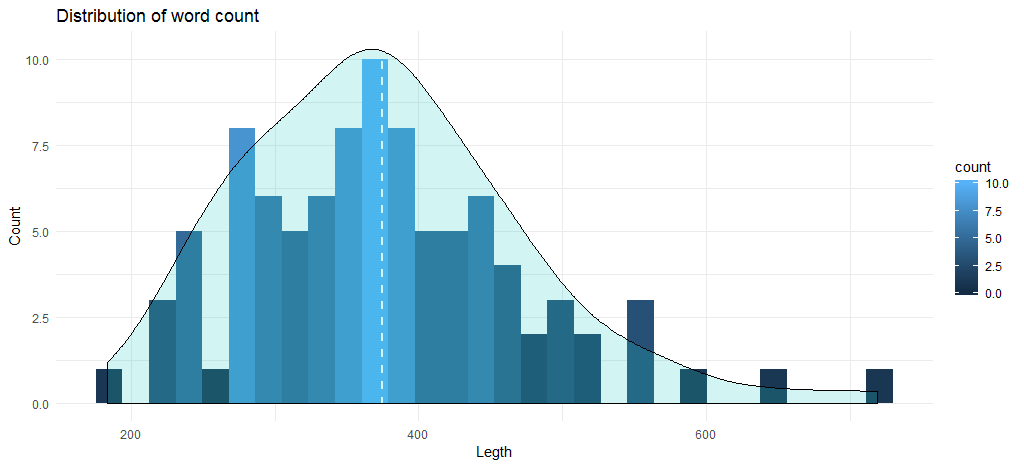
จำนวนคำเฉลี่ยสำหรับแทร็กนั้นอยู่ที่ 375 และแผนภูมิแสดงให้เห็นว่าจำนวนเพลงสูงสุดอยู่ระหว่าง 345 ถึง 400 คำ ตอนนี้ เราจะย้ายไปยังการวิเคราะห์ข้อมูลตามอัลบั้ม ขั้นแรก มาสร้าง data frame ที่มีจำนวนคำตามอัลบั้มและปีที่วางจำหน่ายกัน
[รหัสภาษา =”r”]
เนื้อเพลง %>%
group_by(อัลบั้ม,ปี) %>%
สรุป (ความยาว = ผลรวม (ความยาว)) -> length_df_album
[/รหัส]
ขั้นตอนต่อไปสำหรับเราคือการสร้างแผนภูมิที่จะพรรณนาความยาวของอัลบั้มตามจำนวนคำสะสมของเพลง
[รหัสภาษา =”r”]
ggplot(length_df_album, aes(x= จัดลำดับใหม่ (อัลบั้ม, -length), y=length)) +
geom_bar(stat='identity', fill=”#1CCCC6″) +
ylab("จำนวนคำ") + xlab ("อัลบั้ม") +
ggtitle("คำนับตามอัลบั้ม") +
theme_minimal()
[/รหัส]
แผนภูมิผลลัพธ์แสดงให้เห็นว่าอัลบั้ม "ชื่อเสียง" ซึ่งเป็นอัลบั้มล่าสุดมีจำนวนคำสูงสุด
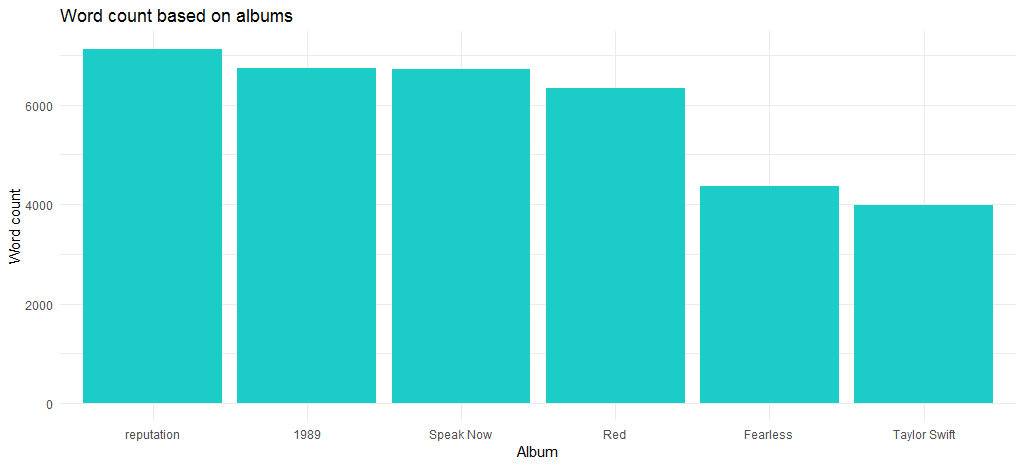
ตอนนี้ ความยาวของเพลงเปลี่ยนไปตั้งแต่เดบิวต์เมื่อปี 2549 ไปอย่างไรบ้าง? รหัสต่อไปนี้ตอบคำถามนี้:
[รหัสภาษา =”r”]
length_df_album %>%
จัด(desc(ปี)) %>%
ggplot(., aes(x= factor(year), y=length, group = 1)) +
geom_line(สี=”#1CCCC6″, ขนาด=1) +
ylab("จำนวนคำ") + xlab ("ปี") +
ggtitle("จำนวนคำเปลี่ยนไปหลายปี") +
theme_minimal()
[/รหัส]
แผนภูมิที่ได้แสดงให้เห็นว่าความยาวของอัลบั้มเพิ่มขึ้นในช่วงหลายปีที่ผ่านมา จากเกือบ 4,000 คำในปี 2549 เป็นมากกว่า 6700 ในปี 2560
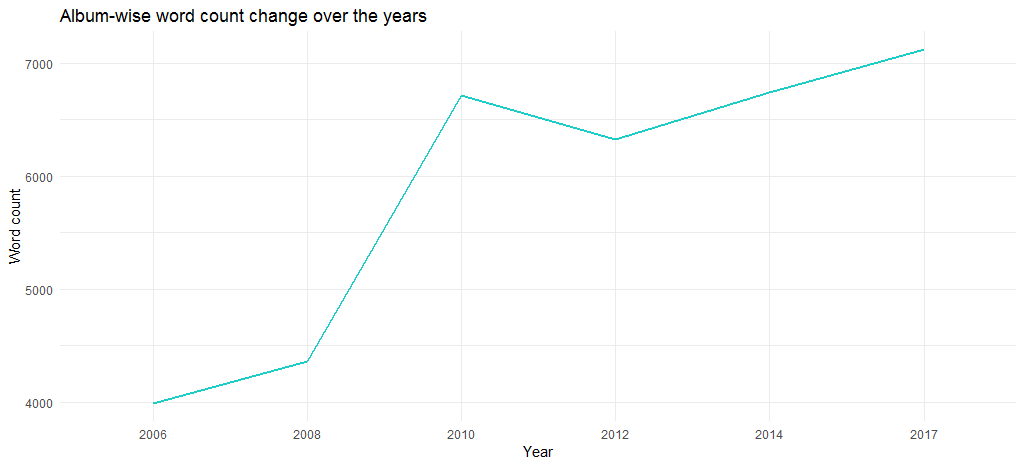
แต่นั่นเป็นเพราะจำนวนคำในแต่ละแทร็กหรือไม่? ลองหาโดยใช้รหัสต่อไปนี้:
[รหัสภาษา =”r”]
#เพิ่มคอลัมน์ปีด้วยการจับคู่ track_title
length_df$ปี <- เนื้อเพลง$ปี[match(length_df$track_title, เนื้อเพลง$track_title)]
length_df %>%
group_by(ปี) %>%
สรุป (ความยาว = ค่าเฉลี่ย (ความยาว)) %>%
ggplot(., aes(x= factor(year), y=length, group = 1)) +
geom_line(สี=”#1CCCC6″, ขนาด=1) +
ylab(“จำนวนคำเฉลี่ย”) + xlab (“ปี”) +
ggtitle("การเปลี่ยนแปลงจำนวนคำเฉลี่ยทั้งปี") +
theme_minimal()
[/รหัส]
แผนภูมิผลลัพธ์ยืนยันว่าจำนวนคำโดยเฉลี่ยเพิ่มขึ้นในช่วงหลายปีที่ผ่านมา (จาก 285 ในปี 2549 เป็น 475 ในปี 2560) กล่าวคือ เพลงของเธอค่อยๆ ยาวขึ้นในแง่ของเนื้อหา
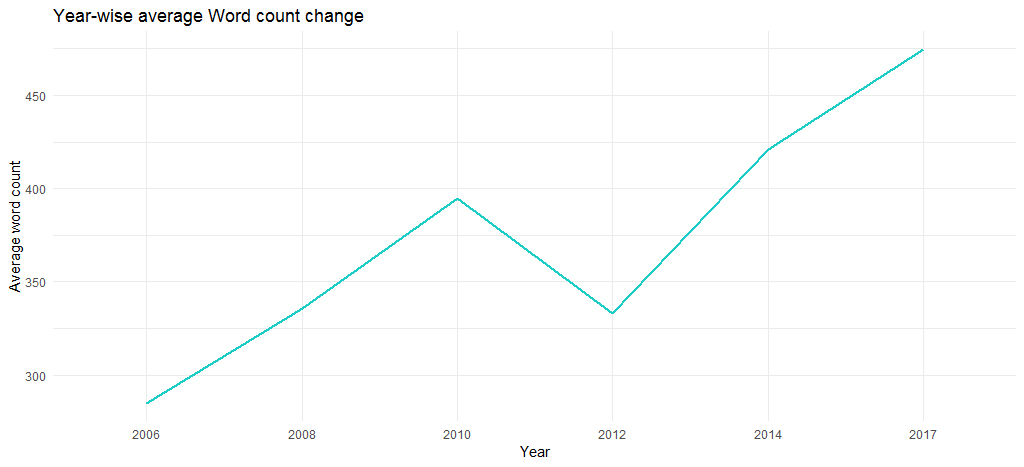
เราจะสรุปการวิเคราะห์เชิงสำรวจที่นี่และย้ายไปที่การทำเหมืองข้อความ
การทำเหมืองข้อความของเนื้อเพลง Taylor Swift Songs
กิจกรรมแรกของเราคือการสร้าง word cloud เพื่อให้เราสามารถเห็นภาพคำที่ใช้บ่อยในเนื้อเพลงของเธอ รันรหัสต่อไปนี้เพื่อเริ่มต้น:
[รหัสภาษา =”r”]
ห้องสมุด (“tm”)
ห้องสมุด (“wordcloud”)
Lyrics_text <- เนื้อเพลง$lyric
#การลบเครื่องหมายวรรคตอนและเนื้อหาที่เป็นตัวอักษรและตัวเลข
Lyrics_text<- gsub('[[:punct:]]+', ”, เนื้อเพลง_text)
Lyrics_text<- gsub(“([[:alpha:]])1+”, “”, เนื้อเพลง_text)
#การสร้างคลังข้อความ
เอกสาร <- Corpus(VectorSource(lyrics_text))
#แปลงข้อความเป็นตัวพิมพ์เล็ก
เอกสาร <- tm_map(docs, content_transformer(tolower))
# การลบคำหยุดทั่วไปภาษาอังกฤษ
เอกสาร <- tm_map(docs, removeWords, stopwords("ภาษาอังกฤษ"))
#สร้างเมทริกซ์เอกสารเทอม
tdm <- TermDocumentMatrix (เอกสาร)
# กำหนด tdm เป็นเมทริกซ์
ม <- as.matrix(tdm)
# นับจำนวนคำในลำดับที่ลดลง
word_freqs = sort(rowSums(m), ลดลง=TRUE)
# การสร้าง data frame ด้วยคำและความถี่
Lyrics_wc_df <- data.frame(word=names(word_freqs), freq=word_freqs)
Lyrics_wc_df <- เนื้อเพลง_wc_df[1:300,]
#พล็อต wordcloud
ชุด.เมล็ด(1234)
wordcloud (คำ = เนื้อเพลง_wc_df$คำ, ความถี่ = เนื้อเพลง_wc_df$ความถี่,
min.freq = 1,ขนาด=c(1.8,.5),
max.words=200, random.order=FALSE, rot.per=0.15,
สี=brewer.pal(8, “Dark2”))

[/รหัส]
ผลลัพธ์ของ word cloud แสดงให้เห็นว่าคำที่ใช้บ่อยที่สุดคือ know , like , don't , you're , now , back นี่เป็นการยืนยันว่าเพลงของเธอเกี่ยวกับใครบางคนเป็นส่วนใหญ่ เนื่องจาก you're มีเพลงเกิดขึ้นเป็นจำนวนมาก
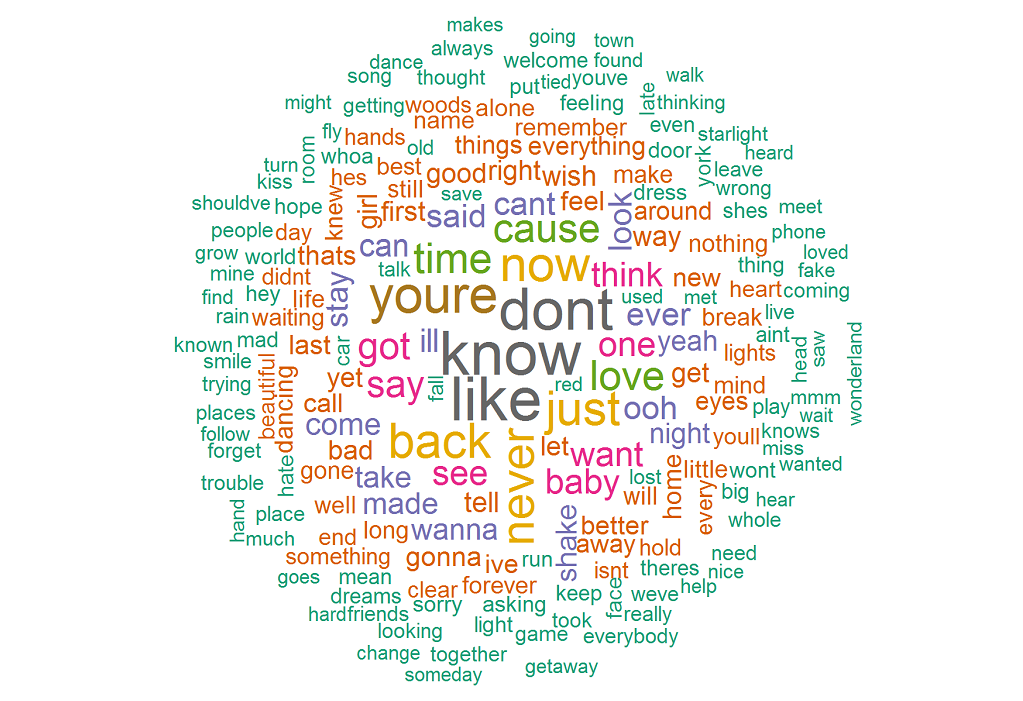
แล้ว bigrams (คู่คำที่ปรากฏร่วมกัน) ล่ะ? รหัสต่อไปนี้จะให้ bigrams สิบอันดับแรกแก่เรา:
[รหัสภาษา =”r”]
count_bigrams <- ฟังก์ชั่น (ชุดข้อมูล) {
ชุดข้อมูล %>%
unnest_tokens(bigram, lyric, token = “ngrams”, n = 2) %>%
แยก (bigram, c(“word1”, “word2″), sep = ” “) %>%
ตัวกรอง (!word1 %in% stop_words$word,
!word2 %in% stop_words$word) %>%
นับ (word1, word2, sort = TRUE)
}
Lyrics_bigrams <- เนื้อเพลง %>%
count_bigrams()
หัว(lyrics_bigrams, 10)
[/รหัส]
รับด้านล่างเป็นรายการของ bigrams:
| คำ 1 | คำ2 |
|---|---|
| อาย | อาย |
| โอ้ | โอ้ |
| ลา | ลา |
| เขย่า | เขย่า |
| อยู่ | อยู่ |
| พักผ่อน | รถยนต์ |
| ฮา | ฮา |
| โอ้ | โว้ว |
| เอ่อ | เอ่อ |
| ฮา | อา |
แม้ว่าเราจะพบรายการคำศัพท์ แต่ก็ไม่ได้เปิดเผยข้อมูลเชิงลึกเกี่ยวกับความสัมพันธ์หลายอย่างที่มีอยู่ระหว่างคำ เพื่อให้เห็นภาพของความสัมพันธ์ที่หลากหลายที่มีอยู่ เราจะใช้ประโยชน์จากกราฟเครือข่าย เริ่มต้นด้วยสิ่งต่อไปนี้:
[รหัสภาษา =”r”]
visualize_bigrams <- ฟังก์ชั่น (bigrams) {
ชุด.เมล็ด(2016)
a <- grid::arrow(type = “closed”, length = unit(.15, “inches”))
บิ๊กแรม %>%
graph_from_data_frame() %>%
ggraph(เลย์เอาต์ = “fr”) +
geom_edge_link(aes(edge_alpha = n), show.legend = FALSE, ลูกศร = a) +
geom_node_point(สี = “ฟ้าอ่อน”, ขนาด = 5) +
geom_node_text(aes(label = ชื่อ), vjust = 1, hjust = 1) +
ggtitle(“กราฟเครือข่ายของ bigrams”) +
theme_void()
}
เนื้อเพลง_bigrams %>%
ตัวกรอง (n > 3,
!str_detect(word1, “d”),
!str_detect(word2, “d”)) %>%
visualize_bigrams()
[/รหัส]
ตรวจสอบกราฟด้านล่างเพื่อดูว่าความ love เชื่อมโยงกับ story ความ mad true tragic magic และ affair อย่างไร นอกจากนี้ทั้ง tragic และ magic ยังเชื่อมโยงกับ beautiful อีกด้วย

ตอนนี้เรามาดูการวิเคราะห์ความรู้สึกซึ่งเป็นเทคนิคการทำเหมืองข้อความกัน
การวิเคราะห์ความเชื่อมั่นของเพลง Taylor Swift
อันดับแรก เราจะค้นหาความรู้สึกโดยรวมผ่านวิธี nrc ของแพ็คเกจ syuzhet รหัสต่อไปนี้จะสร้างแผนภูมิของขั้วบวกและขั้วลบพร้อมกับอารมณ์ที่เกี่ยวข้อง
[รหัสภาษา =”r”]
#รับค่าความรู้สึกของเนื้อเพลง
ty_sentiment <- get_nrc_sentiment((lyrics_text))
#ดาต้าเฟรมที่มีค่าสะสมความรู้สึก
คะแนนความรู้สึก<-data.frame(colSums(ty_sentiment[,]))
# Dataframe ด้วยความรู้สึกและคะแนนเป็นคอลัมน์
ชื่อ (คะแนนความรู้สึก) <- “คะแนน”
Sentimentscores <- cbind(“sentiment”=rownames(sentimentscores),sentimentscores)
ชื่อแถว (คะแนนความรู้สึก) <- NULL
# โครงเรื่องความรู้สึกสะสม
ggplot(data=sentimentscores,aes(x=sentiment,y=Score))+
geom_bar(aes(เติม=ความรู้สึก),stat = “ตัวตน”)+
ธีม(legend.position=”none”)+
xlab("ความรู้สึก")+ylab("คะแนน")+
ggtitle("ความรู้สึกโดยรวมตามคะแนน")+
theme_minimal()
[/รหัส]
แผนภูมิผลลัพธ์แสดงให้เห็นว่าคะแนนความเชื่อมั่นเชิงบวกและเชิงลบค่อนข้างใกล้เคียงกับค่า 1340 และ 1092 ตามลำดับ มาที่อารมณ์ joy anticipation และ trust กลายเป็น 3 อันดับแรก
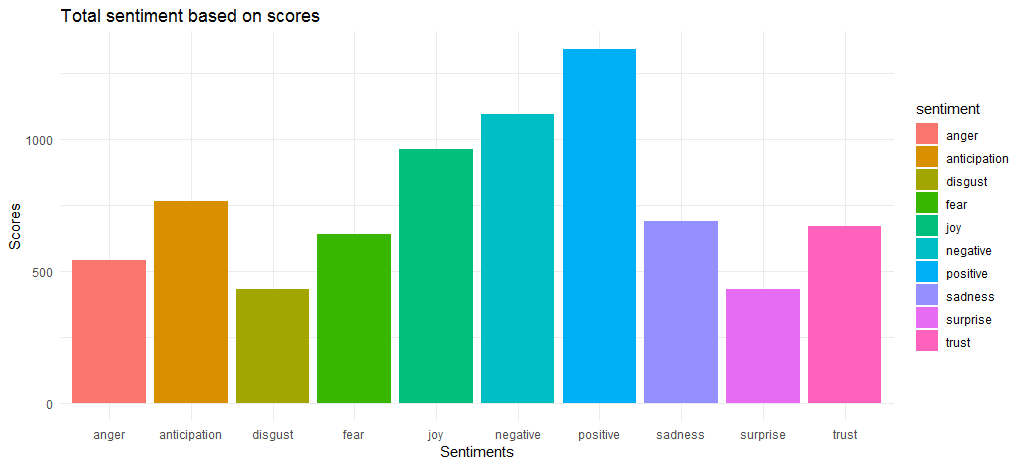
ตอนนี้เราหาคะแนนความเชื่อมั่นโดยรวมได้แล้ว เราควรหาคำยอดนิยมที่นำไปสู่อารมณ์ต่างๆ และความรู้สึกเชิงบวก/เชิงลบ
[รหัสภาษา =”r”]
เนื้อเพลง$lyric <- as.character(lyrics$lyric)
tidy_lyrics <- เนื้อเพลง %>%
unnest_tokens(คำ,เนื้อเพลง)
song_wrd_count <- tidy_lyrics %>% count(track_title)
lyric_counts <- tidy_lyrics %>%
left_join(song_wrd_count, โดย = “track_title”) %>%
เปลี่ยนชื่อ(total_words=n)
lyric_sentiment <- tidy_lyrics %>%
inner_join(get_sentiments(“nrc”),by=”word”)
lyric_sentiment %>%
นับ(คำ,ความรู้สึก,เรียงลำดับ=จริง) %>%
group_by(sentiment)%>%top_n(n=10) %>%
ยกเลิกการจัดกลุ่ม () %>%
ggplot(aes(x=reorder(word,n),y=n,fill=sentiment)) +
geom_col(show.legend = FALSE) +
facet_wrap(~sentiment,scales=”free”) +
xlab("ความรู้สึก") + ylab("คะแนน")+
ggtitle("คำยอดนิยมที่ใช้แสดงอารมณ์และความรู้สึก") +
coord_flip()
[/รหัส]
การแสดงข้อมูลเป็นภาพแสดงให้เห็นว่าแม้ว่าคำว่า bad จะมีอิทธิพลเหนืออารมณ์ เช่น anger disgust sadness และ fear, Surprise และ trust นั้นถูกขับเคลื่อนด้วยคำว่า good
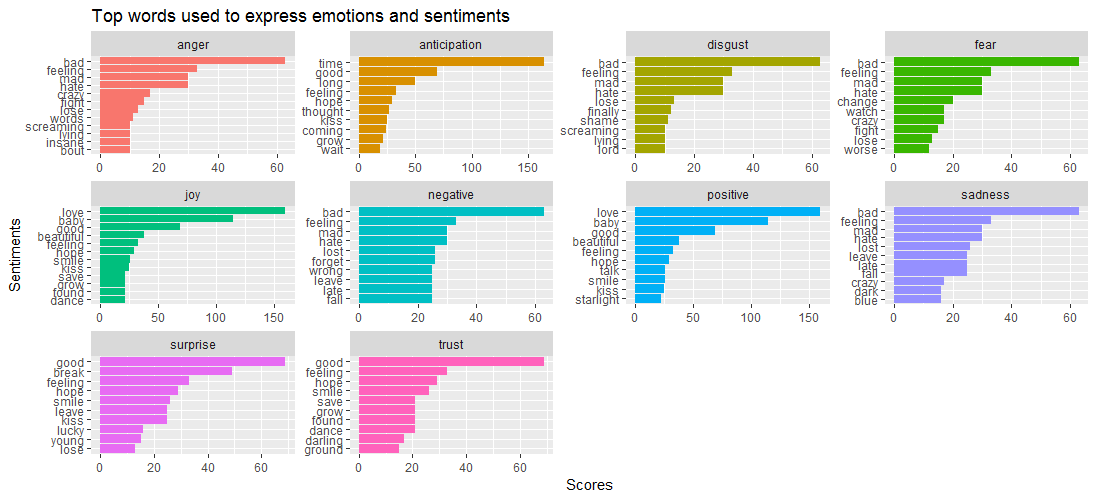
สิ่งนี้นำมาสู่คำถามต่อไปนี้ - เพลงใดมีความเกี่ยวข้องอย่างใกล้ชิดกับอารมณ์ที่แตกต่างกัน? ลองหาผ่านรหัสที่ระบุด้านล่าง:
[รหัสภาษา =”r”]
lyric_sentiment %>%
นับ(track_title,sentiment,sort=TRUE) %>%
group_by(ความรู้สึก) %>%
top_n(n=5) %>%
ggplot(aes(x=reorder(track_title,n),y=n,fill=sentiment)) +
geom_bar(stat=”identity”,show.legend = FALSE) +
facet_wrap(~sentiment,scales=”free”) +
xlab("ความรู้สึก") + ylab("คะแนน")+
ggtitle("เพลงยอดนิยมที่เกี่ยวข้องกับอารมณ์และความรู้สึก") +
coord_flip()
[/รหัส]
เราเห็นแล้วว่าเพลง Black Space โกรธและกลัวมากเมื่อเทียบกับเพลงอื่นๆ อย่าตำหนิฉันเพราะฉันมีคะแนนมากพอสำหรับความเชื่อมั่นทั้งด้าน positive และ negative นอกจากนี้เรายังเห็นว่า Shake it off ได้คะแนนสูงสำหรับความรู้สึก negative ส่วนใหญ่เป็นเพราะคำที่ใช้บ่อย เช่น hate และ fake
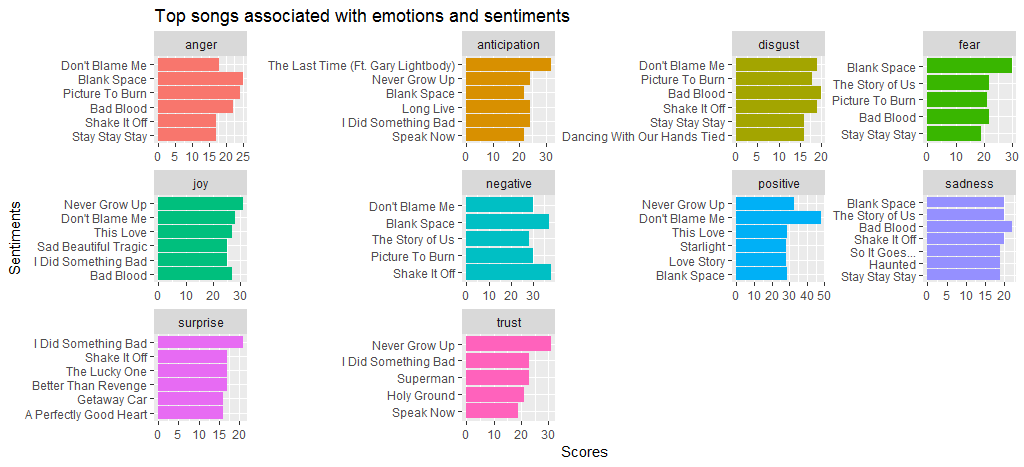
ตอนนี้เรามาดูวิธีวิเคราะห์ความรู้สึกแบบอื่นกันเถอะ bing เพื่อสร้างกลุ่มคำเปรียบเทียบของความรู้สึกเชิงบวกและเชิงลบ
[รหัสภาษา =”r”]
bng <- get_sentiments(“bing”)
ชุด.เมล็ด(1234)
tidy_lyrics %>%
inner_join(get_sentiments(“bing”)) %>%
นับ(คำ ความรู้สึก เรียงลำดับ = จริง) %>%
acast(คำ ~ ความรู้สึก, value.var = “n”, เติม = 0) %>%
comparison.cloud(สี = c(“#F8766D”, “#00BFC4”),
max.words = 250)
[/รหัส]
การแสดงภาพข้อมูลต่อไปนี้แสดงให้เห็นว่าเพลงของเธอมีคำที่เป็นบวก เช่น like , love , good , right และ เชิงลบ เช่น bad , break , shake , mad , wrong
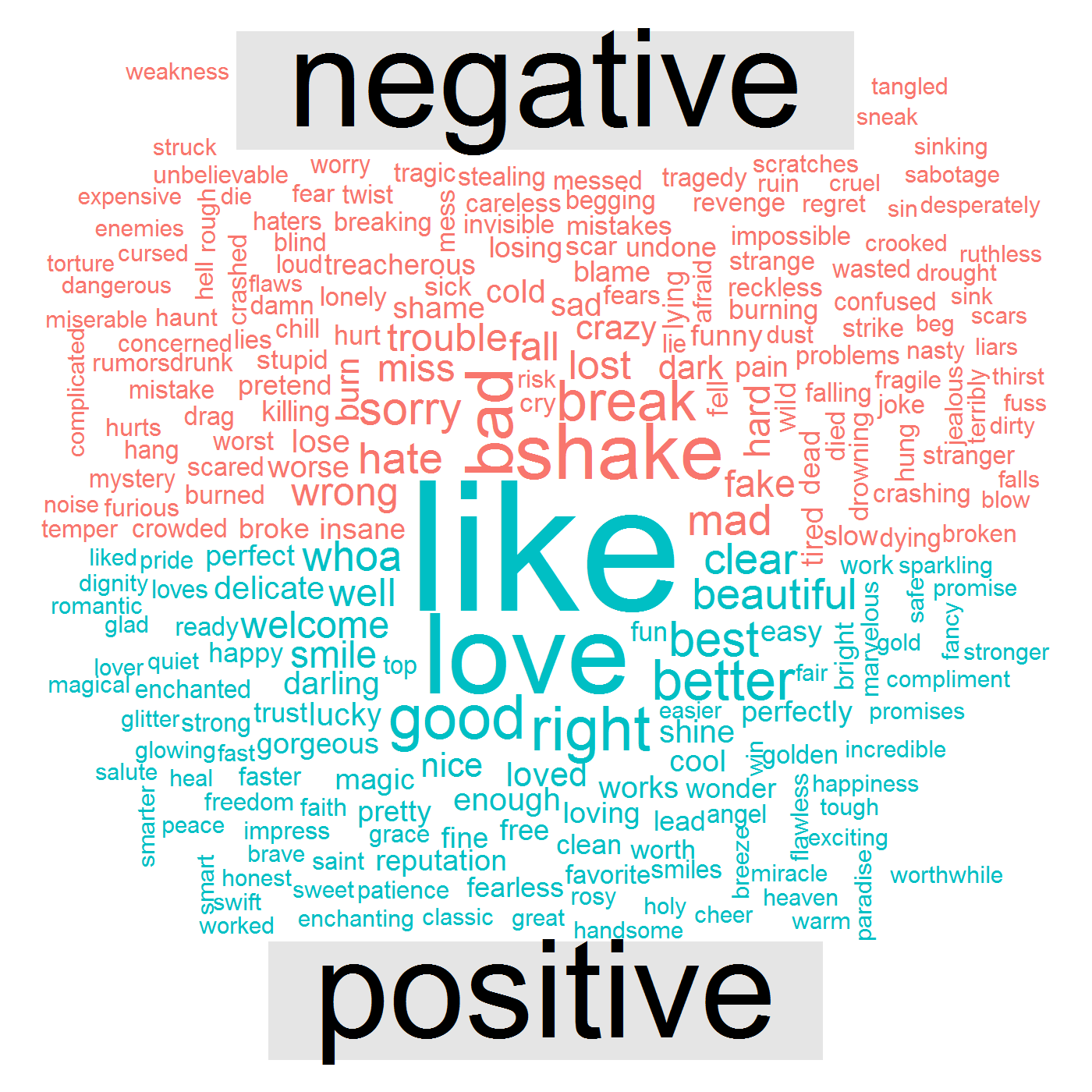
สิ่งนี้นำไปสู่คำถามสุดท้าย - ความรู้สึกและอารมณ์ของเธอเปลี่ยนไปอย่างไรในช่วงหลายปีที่ผ่านมา? สำหรับคำตอบนี้ เราจะสร้างภาพข้อมูลที่เรียกว่า chord diagram นี่คือรหัส:
[รหัสภาษา =”r”]
grid.col = c(“2006” = “#E69F00”, “2008” = “#56B4E9”, “2010” = “#009E73”, “2012” = “#CC79A7”, “2014” = “#D55E00” , “2017” = “#00D6C9”, “ความโกรธ” = “สีเทา”, “ความคาดหวัง” = “สีเทา”, “รังเกียจ” = “สีเทา”, “ความกลัว” = “สีเทา”, “ความสุข” = “สีเทา”, "ความเศร้า" = "สีเทา", "เซอร์ไพรส์" = "สีเทา", "ความไว้วางใจ" = "สีเทา")
year_emotion <- lyric_sentiment %>%
ตัวกรอง (!sentiment %in% c("บวก", "เชิงลบ")) %>%
จำนวน(ความรู้สึก ปี) %>%
group_by(ปี ความรู้สึก) %>%
สรุป(sentiment_sum = ผลรวม (n)) %>%
ยกเลิกการจัดกลุ่ม ()
circos.clear()
#กำหนดขนาดช่องว่าง
circos.par(gap.after = c(rep(6, length(unique(year_emotion[1]]))) – 1), 15,
rep(6, length(unique(year_emotion[[2]]))) – 1), 15))
chordDiagram(year_emotion, grid.col = grid.col, ความโปร่งใส = .2)
title("ความสัมพันธ์ระหว่างอารมณ์กับปีที่ปล่อยเพลง")
[/รหัส]
มันทำให้เราเห็นภาพต่อไปนี้:
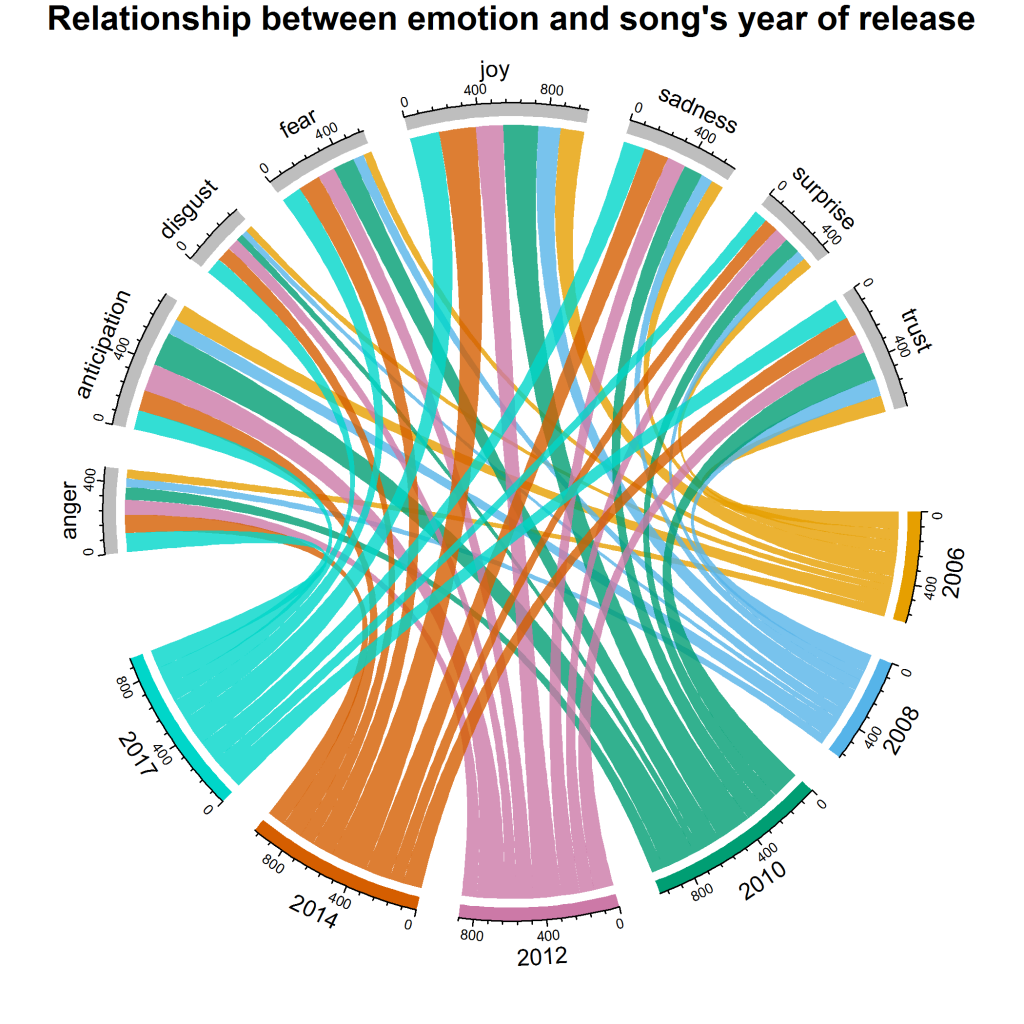
เราจะเห็นได้ว่าความ joy มีส่วนแบ่งสูงสุดในปี 2553 และ 2557 โดยรวมแล้ว surprise disgust และ anger เป็นอารมณ์ที่มีคะแนนน้อยที่สุด อย่างไรก็ตาม เมื่อเทียบกับปีอื่นๆ 2017 มีส่วนทำให้เกิด disgust สูงสุด มาถึงความ anticipation 2010 และ 2012 มีส่วนร่วมสูงกว่าเมื่อเปรียบเทียบกับปีอื่นๆ
ไปยังคุณ
ในการศึกษานี้ เราทำการวิเคราะห์เชิงสำรวจและการทำเหมืองข้อความ ซึ่งรวมถึง NLP สำหรับการวิเคราะห์ความรู้สึก หากคุณต้องการทำการวิเคราะห์เพิ่มเติม (เช่น ความหนาแน่นของคำศัพท์และการสร้างแบบจำลองหัวข้อ) หรือเพียงแค่ทำซ้ำผลลัพธ์สำหรับการเรียนรู้ ดาวน์โหลดชุดข้อมูลได้ฟรีจาก DataStock เพียงทำตามลิงก์ที่ให้ไว้ด้านล่างและเลือกหมวดหมู่ "ฟรี" บน DataStock
