
Taylor Swift의 노래 가사 데이터 시각화 및 분석
게시 됨: 2018-07-19테일러 스위프트가 미국 빌보드 매거진에서 발표한 Hot Country Songs 차트에서 혼자 작곡하고 1위를 한 최연소 가수라는 사실, 알고 계셨나요? 그녀는 특히 그녀의 음악에 자신의 사생활을 불어넣은 것으로 유명하며, 이는 많은 언론 보도를 받았습니다. 탐색적 분석과 감성 분석을 통해 Taylor Swift의 노래 가사를 분석하여 다양한 기저 주제를 찾는 것도 재미있을 것입니다.
Taylor Swift의 노래 가사 분석을 위한 데이터 세트
Genius.com이 공개한 놀라운 API 덕분에 Taylor Swift의 노래와 관련된 다양한 데이터 포인트를 추출할 수 있었습니다.
그녀가 발표한 6개의 앨범만 선택하고 중복 트랙(어쿠스틱, 미국 버전, 팝 믹스, 데모 녹음 등)을 제거했습니다. 그 결과 다음 데이터 필드가 있는 94개의 고유한 트랙이 생성되었습니다.
- 앨범 이름
- 트랙 제목
- 트랙 번호
- 가사 텍스트
- 줄 번호
- 앨범 발매 연도
[call_to_action title="데이터 세트 무료 다운로드" icon="icon-download" link="https://app.promptcloud.com/users/sign_up?target=data_stocks&itm_source=website&itm_medium=blog&itm_campaign=dataviz&itm_term=ts-lyrics&itm_content= data-mining" button_title="" class="" target="_blank" animate=""]CrawlBoard를 통해 DataStock에 가입하고 '무료' 카테고리를 클릭하여 데이터 세트를 다운로드하세요![/call_to_action]
목표
우리의 목표는 먼저 탐색적 분석을 수행한 다음 자연어 처리와 관련된 감정 분석을 포함한 텍스트 마이닝으로 이동하는 것입니다.
– 탐색적 분석
- 트랙 및 앨범을 기반으로 한 단어 수
- 단어 수의 시계열 분석
- 단어 수 분포
– 텍스트 마이닝
- 단어 구름
- 바이그램 네트워크
- 감정 분석(코드 다이어그램 포함)
R 과 ggplot2 를 사용하여 데이터를 분석하고 시각화할 것입니다. 이 글에도 코드가 포함되어 있으니 데이터를 다운받으시면 따라하시면 됩니다.
탐색적 분석
먼저 단어 수가 가장 많은 상위 10개 노래를 알아보겠습니다. 아래에 제공된 코드 스니펫에는 이 분석에 필요한 패키지가 포함되어 있으며 길이 측면에서 상위 곡을 찾습니다.
[코드 언어 = "r"]
라이브러리(magrittr)
라이브러리(문자열)
라이브러리(dplyr)
라이브러리(ggplot2)
라이브러리(tm)
라이브러리(워드클라우드)
도서관(슈제트)
라이브러리(정리텍스트)
도서관(정리)
라이브러리(igraph)
라이브러리(ggraph)
라이브러리(리더)
도서관(동그라미)
라이브러리(reshape2)
가사 <- read.csv(file.choose())
가사$length <- str_count(lyrics$lyric,"S+")
length_df <- 가사 %>%
group_by(트랙 제목) %>%
요약(길이 = 합(길이))
길이_df %>%
정렬(desc(길이)) %>%
슬라이스(1:10) %>%
ggplot(., aes(x= 재정렬(트랙_제목, -길이), y=길이)) +
geom_bar(stat='identity', fill=”#1CCCC6″) +
ylab("단어 수") + xlab("트랙 제목") +
ggtitle("단어 수 기준으로 상위 10곡") +
theme_minimal() +
scale_x_discrete(레이블 = 기능(레이블) {
sapply(seq_along(labels), function(i) paste0(ifelse(i %% 2 == 0, ”, 'n'), labels[i]))
})
[/암호]
이것은 우리에게 다음 차트를 제공합니다:
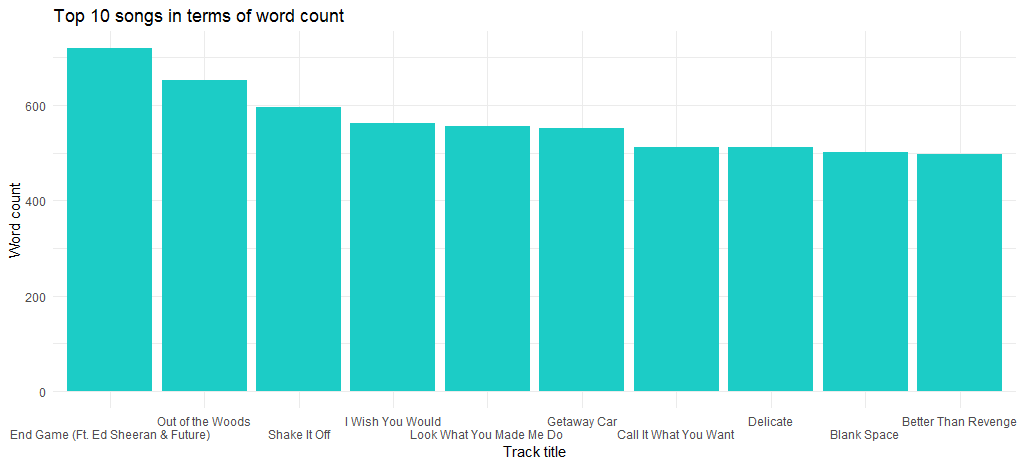
그녀의 최신 앨범에 수록된 "End Game"이 단어 수가 가장 많은 곡이고 그 다음이 "Out of the Woods"인 것을 알 수 있습니다.
자, 단어 수가 가장 적은 노래는 어떻습니까? 다음 코드를 사용하여 알아봅시다.
[코드 언어 = "r"]
길이_df %>%
배열(길이) %>%
슬라이스(1:10) %>%
ggplot(., aes(x= 재정렬(트랙 제목, 길이), y=길이)) +
geom_bar(stat='identity', fill=”#1CCCC6″) +
ylab("단어 수") + xlab("트랙 제목") +
ggtitle("단어 개수가 가장 적은 10곡") +
theme_minimal() +
scale_x_discrete(레이블 = 기능(레이블) {
sapply(seq_along(labels), function(i) paste0(ifelse(i %% 2 == 0, ”, 'n'), labels[i]))
})
[/암호]
그 결과 다음 차트가 생성됩니다.
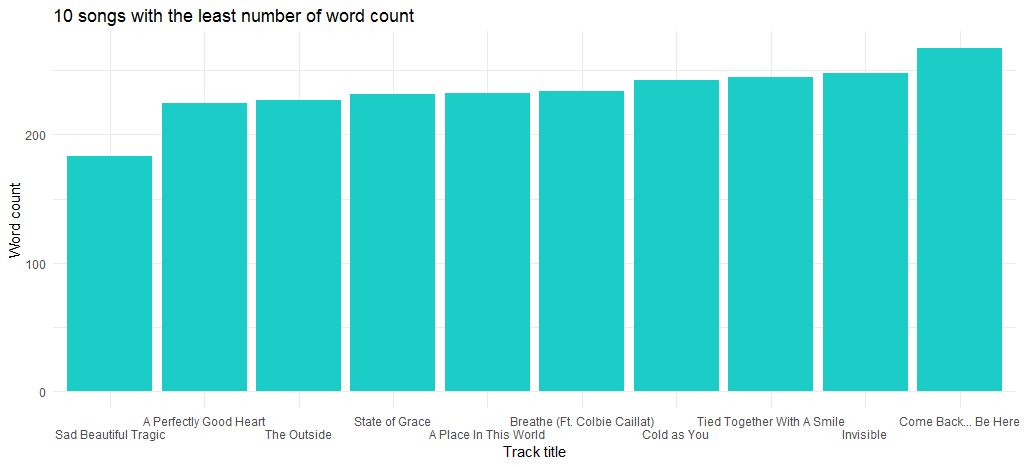
2012년 '빨간색'의 수록곡 '아름답고 슬프다'는 가사가 가장 적은 곡이다.
다음 데이터 분석은 단어 수 분포를 중심으로 이루어집니다. 코드는 다음과 같습니다.
[코드 언어 = "r"]
ggplot(길이_df, aes(x=길이)) +
geom_histogram(bins=30,aes(채우기 = ..count..)) +
geom_vline(aes(xintercept=평균(길이)),
색상 = "#FFFFFF", 선종류 = "대시", 크기 = 1) +
geom_density(aes(y=25 * ..count..),alpha=.2, fill=”#1CCCC6″) +
ylab("카운트") + xlab("다리") +
ggtitle("단어수 분포") +
theme_minimal()
[/암호]
이 코드는 밀도 곡선과 함께 다음 히스토그램을 제공합니다.
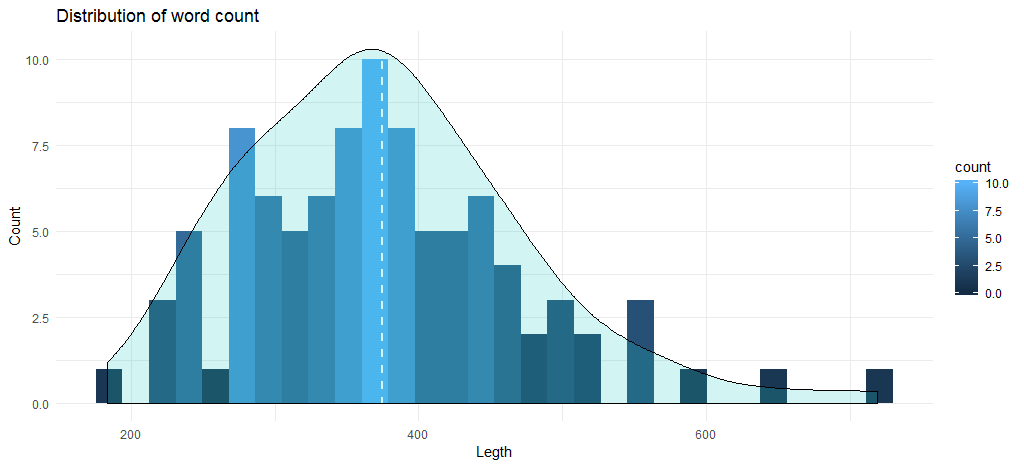
트랙의 평균 단어 수는 375개에 가깝고 차트는 최대 노래 수가 345개에서 400개 단어 사이에 있음을 보여줍니다. 이제 앨범을 기반으로 한 데이터 분석으로 넘어가겠습니다. 먼저 앨범과 출시 연도를 기준으로 단어 수를 사용하여 데이터 프레임을 생성해 보겠습니다.
[코드 언어 = "r"]
가사 %>%
group_by(앨범, 연도) %>%
요약(길이 = 합(길이)) -> length_df_album
[/암호]
다음 단계는 노래의 누적 단어 수를 기반으로 앨범의 길이를 나타내는 차트를 만드는 것입니다.
[코드 언어 = "r"]
ggplot(length_df_album, aes(x= 재정렬(앨범, -length), y=length)) +
geom_bar(stat='identity', fill=”#1CCCC6″) +
ylab("단어 수") + xlab("앨범") +
ggtitle("앨범 기준 단어 수") +
theme_minimal()
[/암호]
결과 차트는 최신 앨범이기도 한 "Reputation" 앨범의 최대 단어 수를 보여줍니다.
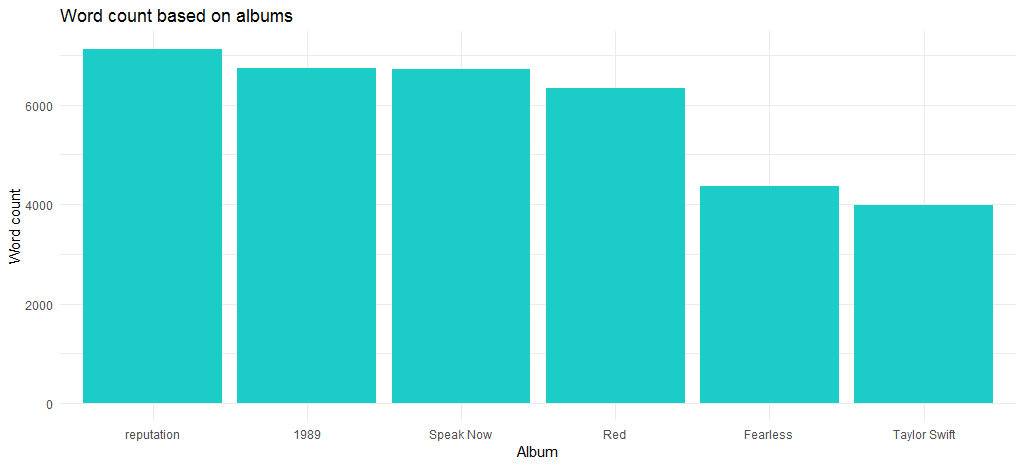
그렇다면 2006년 데뷔 이후 곡 길이는 어떻게 달라졌을까. 다음 코드는 이에 대한 답을 제공합니다.
[코드 언어 = "r"]
length_df_album %>%
정렬(내림차순(년)) %>%
ggplot(., aes(x= 요인(연도), y=길이, 그룹 = 1)) +
geom_line(색상=”#1CCCC6″, 크기=1) +
ylab("단어 수") + xlab("연도") +
ggtitle("몇 년 동안 단어 수 변화") +
theme_minimal()
[/암호]
결과 차트는 앨범의 길이가 2006년 4000단어 가까이에서 2017년 6700단어 이상으로 수년 동안 증가했음을 보여줍니다.
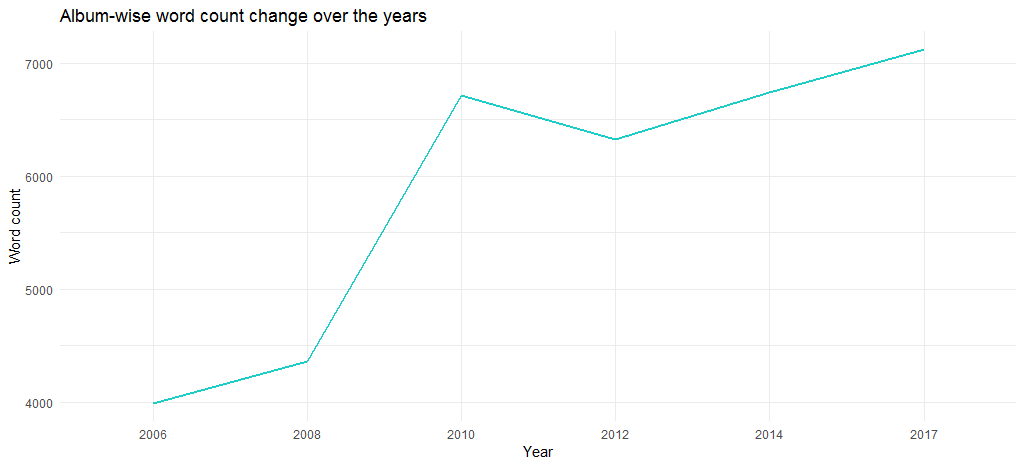
하지만, 개별 트랙의 단어 수 때문인가요? 다음 코드를 사용하여 알아봅시다.
[코드 언어 = "r"]
# track_title을 일치시켜 연도 열 추가
length_df$year <- 가사$year[match(length_df$track_title, 가사$track_title)]
길이_df %>%
그룹별(연도) %>%
요약(길이 = 평균(길이)) %>%
ggplot(., aes(x= 요인(연도), y=길이, 그룹 = 1)) +
geom_line(색상=”#1CCCC6″, 크기=1) +
ylab("평균 단어 수") + xlab("연도") +
ggtitle("연간 평균 단어 수 변화") +
theme_minimal()
[/암호]
결과 차트는 평균 단어 수가 수년에 걸쳐(2006년 285개에서 2017년 475개로) 증가했음을 확인합니다. 즉, 그녀의 노래는 콘텐츠 측면에서 점차 길어졌습니다.
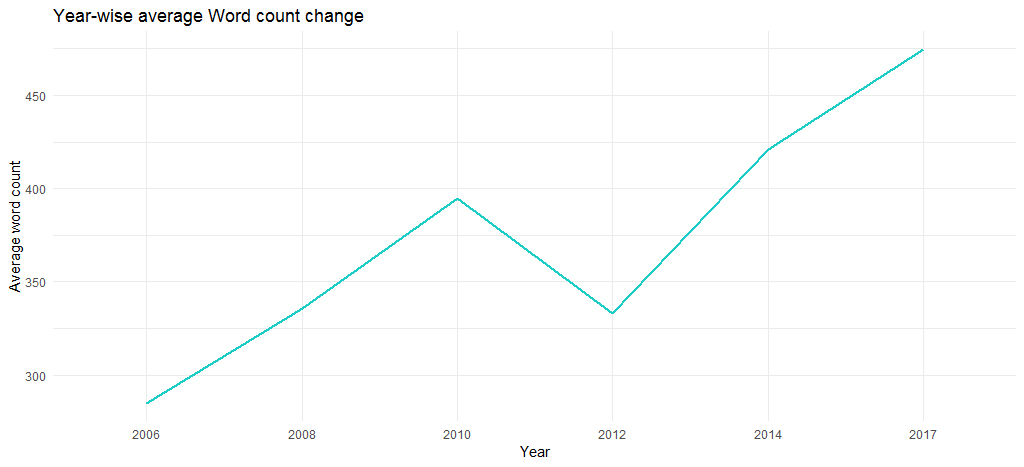
여기에서 탐색적 분석을 마치고 텍스트 마이닝으로 넘어갈 것입니다.
Taylor Swift Songs 가사의 텍스트 마이닝
첫 번째 활동은 그녀의 가사에서 자주 사용되는 단어를 시각화할 수 있도록 워드 클라우드를 만드는 것입니다. 시작하려면 다음 코드를 실행하세요.
[코드 언어 = "r"]
라이브러리("tm")
라이브러리("워드클라우드")
가사_텍스트 <- 가사$가사
#구두점 및 영숫자 콘텐츠 제거
가사_텍스트<- gsub('[[:punct:]]+', ”, 가사_텍스트)
가사_text<- gsub(“([[:alpha:]])1+”, “”, 가사_텍스트)
#텍스트 코퍼스 생성
문서 <- 말뭉치(VectorSource(lyrics_text))
# 텍스트를 소문자로 변환
문서 <- tm_map(문서, content_transformer(tolower))
# 영어 공통 불용어 제거
문서 <- tm_map(문서, 제거 단어, 불용어("영어"))
# 용어 문서 행렬 생성
tdm <- TermDocumentMatrix(문서)
# tdm을 행렬로 정의
m <- as.matrix(tdm)
# 단어 수를 내림차순으로 가져오기
word_freqs = 정렬(rowSums(m), 감소=TRUE)
# 단어와 빈도로 데이터 프레임 생성
가사_wc_df <- data.frame(word=names(word_freqs), freq=word_freqs)
가사_wc_df <- 가사_wc_df[1:300,]
# 플로팅 워드 클라우드
set.seed(1234)
wordcloud(단어 = 가사_wc_df$단어, 주파수 = 가사_wc_df$freq,
min.freq = 1, scale=c(1.8,.5),
max.words=200, random.order=FALSE, rot.per=0.15,
색상=brewer.pal(8, "Dark2"))
[/암호]
결과 단어 구름은 가장 자주 사용되는 단어가 know , like , don't , you're , now , back 임을 보여줍니다. 이것은 그녀의 노래가 주로 누군가에 관한 you're 확인시켜줍니다.

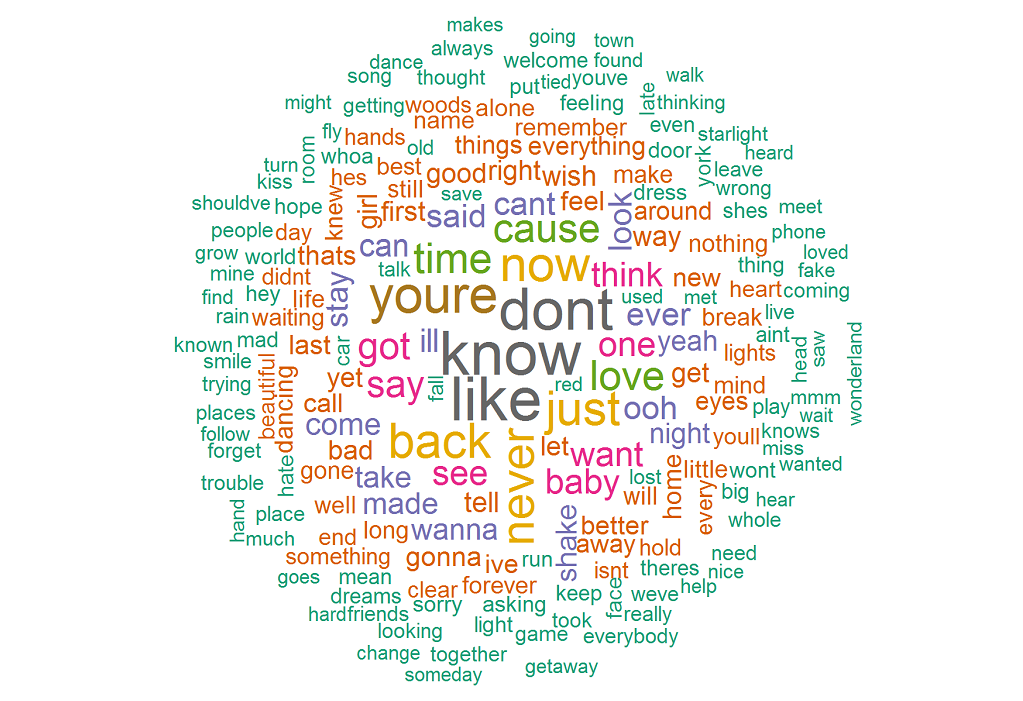
bigrams(함께 나타나는 단어 쌍)는 어떻습니까? 다음 코드는 상위 10개 빅그램을 제공합니다.
[코드 언어 = "r"]
count_bigrams <- function(dataset) {
데이터세트 %>%
unnest_tokens(bigram, 가사, 토큰 = "ngrams", n = 2) %>%
분리(bigram, c("단어1", "단어2"), sep = " ") %>%
필터(!word1 %in% stop_words$word,
!word2 %in% stop_words$word) %>%
개수(단어1, 단어2, 정렬 = TRUE)
}
가사_bigrams <- 가사 %>%
count_bigrams()
머리(lyrics_bigrams, 10)
[/암호]
다음은 빅그램 목록입니다.
| 단어 1 | 단어 2 |
|---|---|
| 어이 | 어이 |
| 우 | 우 |
| 라 | 라 |
| 떨림 | 떨림 |
| 머무르다 | 머무르다 |
| 도주 | 자동차 |
| 하아 | 하아 |
| 우 | 우와 |
| 음 | 음 |
| 하아 | 아 |
우리는 단어 목록을 찾았지만 단어 사이에 존재하는 여러 관계에 대한 통찰력을 누설하지 않습니다. 존재할 수 있는 여러 관계를 시각화하기 위해 네트워크 그래프를 활용할 것입니다. 다음부터 시작해 보겠습니다.
[코드 언어 = "r"]
visual_bigrams <- function(bigrams) {
set.seed(2016)
a <- grid::arrow(유형 = "닫힌", 길이 = 단위(.15, "인치"))
바이그램 %>%
graph_from_data_frame() %>%
ggraph(레이아웃 = "fr") +
geom_edge_link(aes(edge_alpha = n), show.legend = FALSE, 화살표 = a) +
geom_node_point(색상 = "하늘색", 크기 = 5) +
geom_node_text(aes(레이블 = 이름), vjust = 1, hjust = 1) +
ggtitle("빅그램의 네트워크 그래프") +
theme_void()
}
가사_bigrams %>%
필터(n > 3,
!str_detect(단어1, "d"),
!str_detect(단어2, "d")) %>%
시각화_빅그램()
[/암호]
love 이 story , mad , true , tragic , magic , affair 과 어떻게 연결되어 있는지 아래의 그래프를 확인하십시오. 또한 tragic 과 magic 은 모두 beautiful 것과 연결되어 있습니다.

이제 텍스트 마이닝 기법인 감정 분석으로 넘어가 보겠습니다.
Taylor Swift 노래의 감정 분석
먼저 syuzhet 패키지의 nrc 메서드를 통해 전체적인 감성을 알아보겠습니다. 다음 코드는 관련된 감정과 함께 양극 및 음극 차트를 생성합니다.
[코드 언어 = "r"]
# 가사에 대한 감정 값 얻기
ty_sentiment <- get_nrc_sentiment((가사_텍스트))
# 감정의 누적 값이 있는 데이터 프레임
감정 점수<-data.frame(colSums(ty_sentiment[,]))
# 감정과 점수를 열로 사용하는 데이터 프레임
이름(감정 점수) <- "점수"
감정 점수 <- cbind(“sentiment”=rownames(sentimentscores),sentimentscores)
행 이름(감정 점수) <- NULL
# 누적 감정에 대한 플롯
ggplot(데이터=감정점수,aes(x=감정,y=점수))+
geom_bar(aes(fill=sentiment),stat = "identity")+
테마(legend.position="없음")+
xlab("감정")+ylab("점수")+
ggtitle("점수에 따른 총 감정")+
theme_minimal()
[/암호]
결과 차트는 긍정적인 감정 점수와 부정적인 감정 점수가 각각 1340 및 1092 값으로 상대적으로 가깝다는 것을 보여줍니다. 감정, joy , anticipation , trust 가 3위에 올랐습니다.
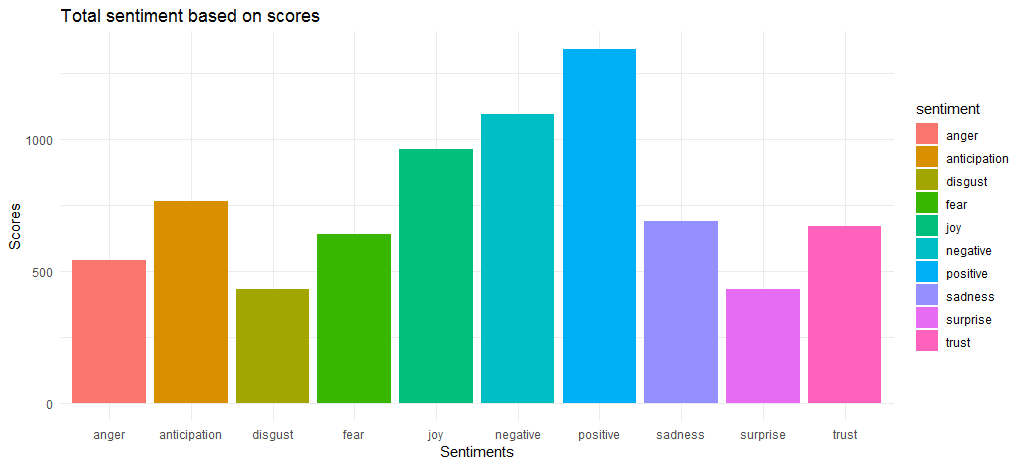
전반적인 감정 점수를 파악했으므로 다양한 감정과 긍정적/부정적 감정에 기여하는 상위 단어를 찾아야 합니다.
[코드 언어 = "r"]
가사$lyric <- as.character(lyrics$lyric)
Tidy_lyrics <- 가사 %>%
unnest_tokens(단어, 가사)
song_wrd_count <- Tidy_lyrics %>% count(track_title)
가사_카운트 <- 깔끔한_가사 %>%
left_join(song_wrd_count, by = "track_title") %>%
이름 바꾸기(total_words=n)
가사_감정 <- 깔끔한 가사 %>%
inner_join(get_sentiments("nrc"),by="단어")
가사_감정 %>%
개수(단어,감정,정렬=TRUE) %>%
group_by(감정)%>%top_n(n=10) %>%
그룹 해제() %>%
ggplot(aes(x=재주문(단어,n),y=n,채우기=감정)) +
geom_col(show.legend = FALSE) +
facet_wrap(~sentiment,scales="무료") +
xlab("감정") + ylab("점수")+
ggtitle("감정과 감정을 표현할 때 가장 많이 사용되는 단어") +
coord_flip()
[/암호]
제공된 데이터 시각화는 anger , disgust , sadness , fear, 과 같은 감정에서 bad 단어가 지배적이지만 Surprise 과 trust 는 good 단어에 의해 주도된다는 것을 보여줍니다.
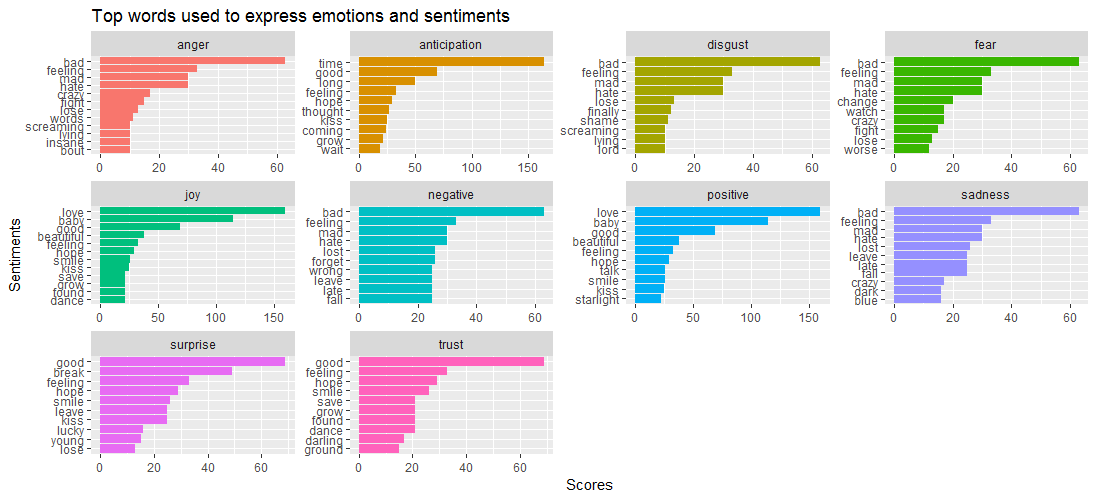
이것은 다음과 같은 질문을 가져옵니다. 어떤 노래가 서로 다른 감정과 밀접하게 연관되어 있습니까? 아래 코드를 통해 알아봅시다.
[코드 언어 = "r"]
가사_감정 %>%
개수(트랙 제목, 감정, 정렬=TRUE) %>%
group_by(감정) %>%
top_n(n=5) %>%
ggplot(aes(x=reorder(track_title,n),y=n,fill=sentiment)) +
geom_bar(stat=”identity”,show.legend = FALSE) +
facet_wrap(~sentiment,scales="무료") +
xlab("감정") + ylab("점수")+
ggtitle("감정과 감성을 담은 인기곡") +
coord_flip()
[/암호]
Black Space 라는 곡은 다른 곡들에 비해 분노와 두려움이 많다는 것을 알 수 있다. 나는 positive 이고 negative 감정 모두에 상당한 점수를 가지고 있기 때문에 나를 비난하지 마십시오. 또한 Shake it off 는 negative 감정에 대해 높은 점수를 받았습니다. 주로 hate 및 fake 와 같은 빈도가 높은 단어 때문입니다.
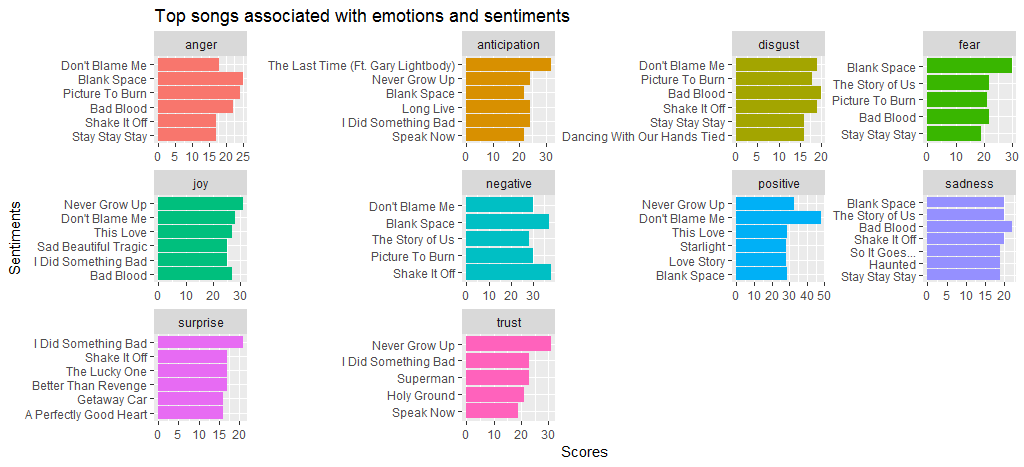
이제 긍정적인 감정과 부정적인 감정의 비교 단어 구름을 만들기 위해 다른 감정 분석 방법으로 bing 보겠습니다.
[코드 언어 = "r"]
bng <- get_sentiments("빙")
set.seed(1234)
깔끔한_가사 %>%
inner_join(get_sentiments("빙")) %>%
count(단어, 감정, 정렬 = TRUE) %>%
acast(단어 ~ 감정, value.var = "n", 채우기 = 0) %>%
compare.cloud(색상 = c(“#F8766D”, “#00BFC4”),
최대 단어 수 = 250)
[/암호]
다음 데이터 시각화는 그녀의 노래에 like , love , good , right 와 같은 긍정적인 단어와 bad , break , shake , mad , wrong 과 같은 부정적인 단어가 있음을 보여줍니다.
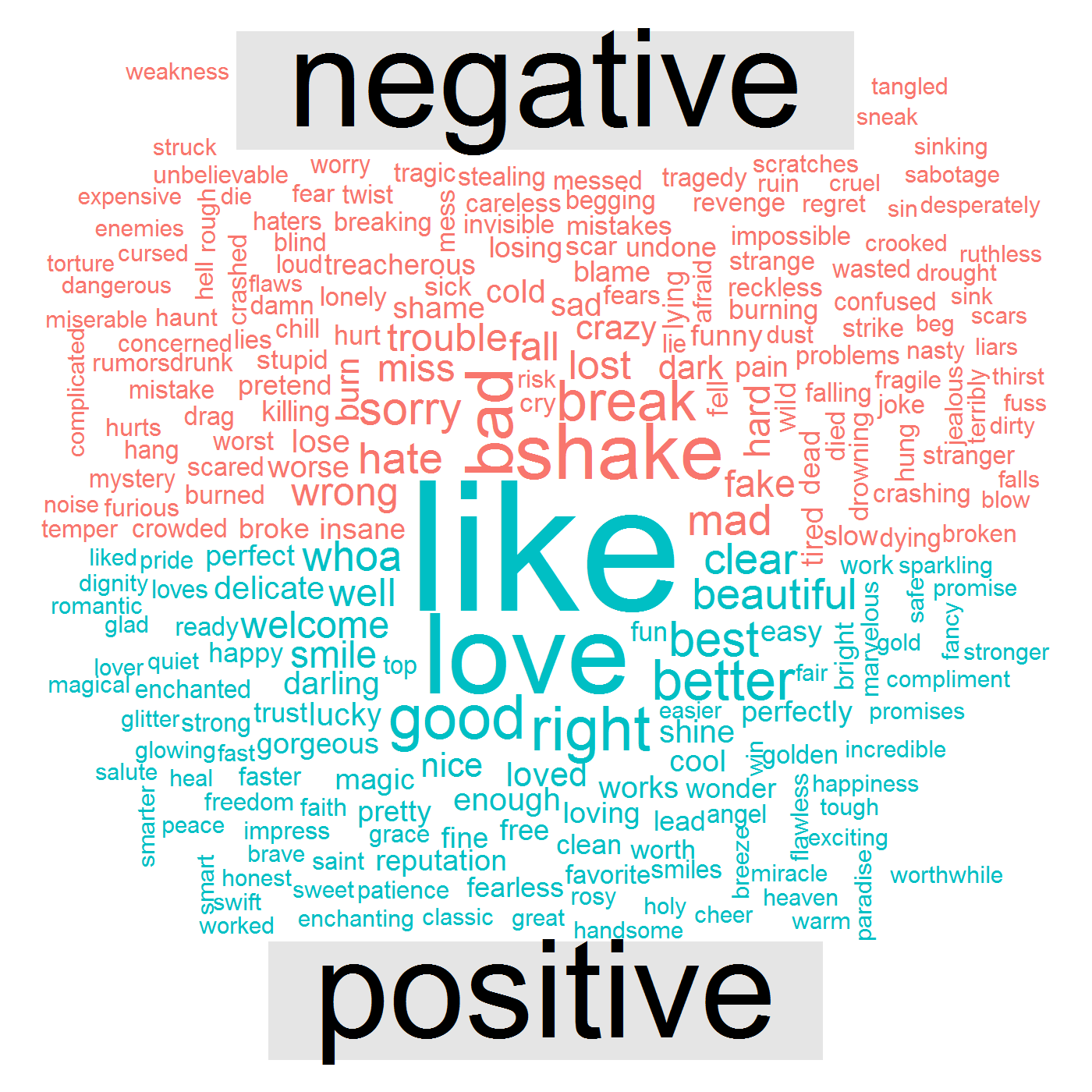
이것은 마지막 질문으로 이어집니다. 그녀의 감정과 감정은 수년에 걸쳐 어떻게 바뀌었습니까? 이 특정 답변을 위해 우리는 chord diagram 이라는 시각화를 만들 것입니다. 코드는 다음과 같습니다.
[코드 언어 = "r"]
grid.col = c("2006" = "#E69F00", "2008" = "#56B4E9", "2010" = "#009E73", "2012" = "#CC79A7", "2014" = "#D55E00") , "2017" = "#00D6C9", "분노" = "회색", "기대" = "회색", "혐오" = "회색", "두려움" = "회색", "기쁨" = "회색", "슬픔" = "회색", "놀람" = "회색", "신뢰" = "회색")
year_emotion <- 가사_감정 %>%
필터(!감정 %in% c("양수", "음수")) %>%
개수(감정, 연도) %>%
group_by(연도, 감정) %>%
요약(감정_합 = 합(n)) %>%
그룹 해제()
circos.clear()
# 간격 크기 설정
circos.par(gap.after = c(rep(6, length(unique(year_emotion[[1]]))) – 1), 15,
rep(6, length(unique(year_emotion[[2]])) – 1), 15))
ChordDiagram(연도 감정, grid.col = grid.col, 투명도 = .2)
title("감정과 발매연도의 관계")
[/암호]
다음과 같은 시각화를 제공합니다.
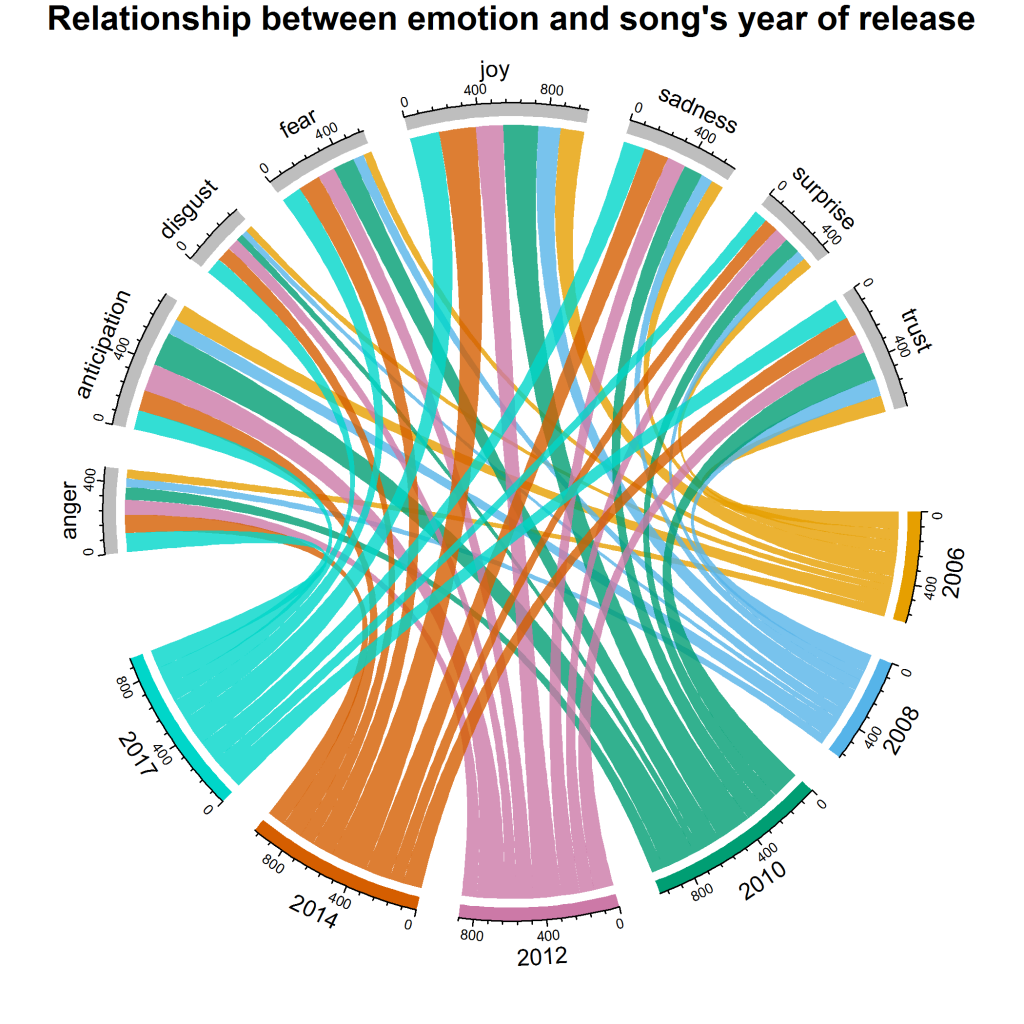
우리는 2010년과 2014년에 joy 이 최대 몫을 가짐을 알 수 있습니다. 전반적으로 surprise , disgust , anger 가 가장 낮은 점수를 받은 감정입니다. 그러나 다른 해에 비해 2017년은 disgust 에 대한 최대 기여도를 가지고 있습니다. anticipation 대로 2010년과 2012년은 다른 해에 비해 기여도가 더 높습니다.
너에게로
본 연구에서는 감성분석을 위한 NLP를 포함하는 탐색적 분석과 텍스트 마이닝을 수행하였다. 추가 분석(예: 가사의 어휘 밀도 및 주제 모델링)을 수행하거나 단순히 학습 결과를 복제하려면 DataStock에서 데이터 세트를 무료로 다운로드하십시오. 아래에 제공된 링크를 따라 DataStock에서 "무료" 카테고리를 선택하기만 하면 됩니다.
