
データの視覚化とテイラー・スウィフトの歌詞の分析
公開: 2018-07-19テイラー・スウィフトは、アメリカのビルボード マガジンが発行するホット カントリー ソング チャートでナンバーワンの曲を単独で書き、演奏した最年少の人物であることをご存知でしたか? 彼女は、多くのメディアで取り上げられている音楽に私生活を吹き込むことで特に知られています。 テイラー・スウィフトの歌の歌詞を探索的分析と感情分析で分析して、さまざまな根底にあるテーマを見つけ出すのは興味深いことです。
テイラー・スウィフトの歌の歌詞を分析するためのデータセット
Genius.com によって公開された素晴らしい API のおかげで、Taylor Swift の曲に関連するさまざまなデータ ポイントを抽出することができました。
彼女がリリースした 6 枚のアルバムのみを選択し、重複したトラック (アコースティック、US バージョン、ポップ ミックス、デモ録音など) を削除しました。 これにより、次のデータ フィールドを持つ 94 の一意のトラックが作成されました。
- アルバム名
- トラックタイトル
- 追跡番号
- 歌詞テキスト
- 行番号
- アルバムのリリース年
[call_to_action title="データ セットを無料でダウンロード" icon="icon-download" link="https://app.promptcloud.com/users/sign_up?target=data_stocks&itm_source=website&itm_medium=blog&itm_campaign=dataviz&itm_term=ts-lyrics&itm_content= data-mining" button_title="" class="" target="_blank" animate=""]CrawlBoard から DataStock にサインアップし、「無料」カテゴリをクリックしてデータセットをダウンロードしてください![/call_to_action]
目標
私たちの目標は、最初に探索的分析を実行し、次に自然言語処理を含む感情分析を含むテキスト マイニングに移行することです。
– 探索的分析
- トラックとアルバムに基づく単語数
- 文字数の時系列分析
- 単語数の分布
– テキストマイニング
- 単語の雲
- バイグラムネットワーク
- 感情分析 (コード ダイアグラムを含む)
Rとggplot2を使用して、データを分析および視覚化します。 この投稿にはコードも含まれているので、データをダウンロードすれば従うことができます。
探索的分析
まず、単語数が最も多い曲のトップ 10 を見つけてみましょう。 以下に示すコード スニペットには、この分析に必要なパッケージが含まれており、長さの点で上位の曲を見つけます。
[コード言語=”r”]
ライブラリ(マグリット)
ライブラリ(stringr)
ライブラリ(dplyr)
ライブラリ (ggplot2)
ライブラリ(tm)
図書館(ワードクラウド)
図書館(シュゼット)
ライブラリ(tidytext)
ライブラリ(整頓)
ライブラリ(igraph)
ライブラリ(ggraph)
ライブラリ(リーダー)
図書館(丸で囲う)
ライブラリ(reshape2)
歌詞 <- read.csv(file.choose())
歌詞$長さ <- str_count(歌詞$歌詞,”S+”)
length_df <- 歌詞 %>%
group_by(トラックタイトル) %>%
summarise(長さ = 合計(長さ))
length_df %>%
アレンジ (説明 (長さ)) %>%
スライス(1:10) %>%
ggplot(., aes(x= reorder(track_title, -length), y=length)) +
geom_bar(stat='identity', fill=”#1CCCC6”) +
ylab(“単語数”) + xlab (“トラックタイトル”) +
ggtitle(“単語数上位10曲”) +
theme_minimal() +
scale_x_discrete(ラベル = 関数(ラベル) {
sapply(seq_along(labels), function(i) paste0(ifelse(i %% 2 == 0, ”, 'n'), ラベル[i]))
}))
[/コード]
これにより、次のチャートが得られます。
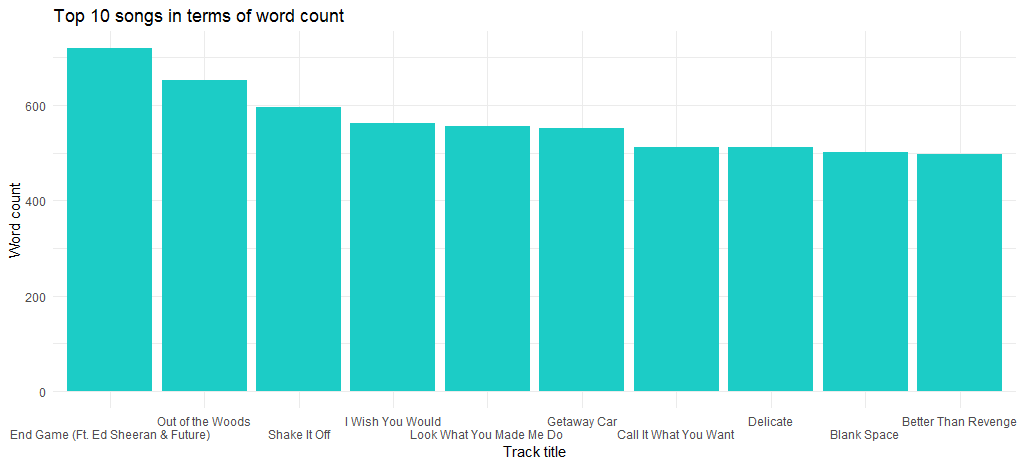
「End Game」(彼女の最新アルバムでリリースされた) が最大の単語数の曲であり、次が「Out of the Woods」であることがわかります。
では、単語数の少ない曲はどうでしょうか。 次のコードを使用して調べてみましょう。
[コード言語=”r”]
length_df %>%
アレンジ(長さ) %>%
スライス(1:10) %>%
ggplot(., aes(x= reorder(track_title, length), y=length)) +
geom_bar(stat='identity', fill=”#1CCCC6”) +
ylab(“単語数”) + xlab (“トラックタイトル”) +
ggtitle(“単語数の少ない曲10曲”) +
theme_minimal() +
scale_x_discrete(ラベル = 関数(ラベル) {
sapply(seq_along(labels), function(i) paste0(ifelse(i %% 2 == 0, ”, 'n'), ラベル[i]))
}))
[/コード]
これにより、次のチャートが得られます。
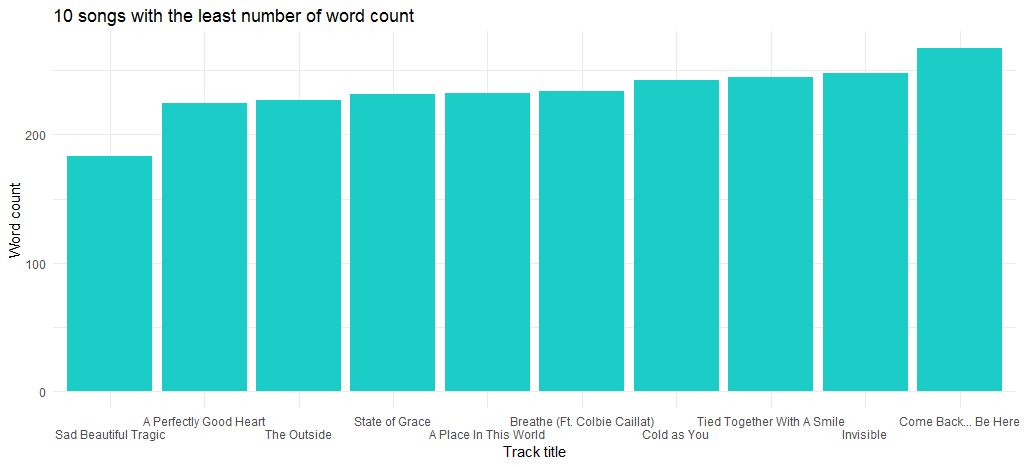
2012年にリリースされたアルバム「Red」の収録曲「Sad Beautiful Tragic」は、言葉数が最も少ない曲です。
次のデータ分析は、単語数の分布を中心に行います。 以下にコードを示します。
[コード言語=”r”]
ggplot(length_df, aes(x=長さ)) +
geom_histogram(bins=30,aes(fill = ..count..)) +
geom_vline(aes(xintercept=平均(長さ)),
color=”#FFFFFF”, linetype=”dashed”, size=1) +
geom_density(aes(y=25 * ..count..),alpha=.2, fill=”#1CCCC6”) +
ylab(“カウント”) + xlab (“レッグ”) +
ggtitle(“単語数分布”) +
theme_minimal()
[/コード]
このコードにより、次のヒストグラムと密度曲線が得られます。
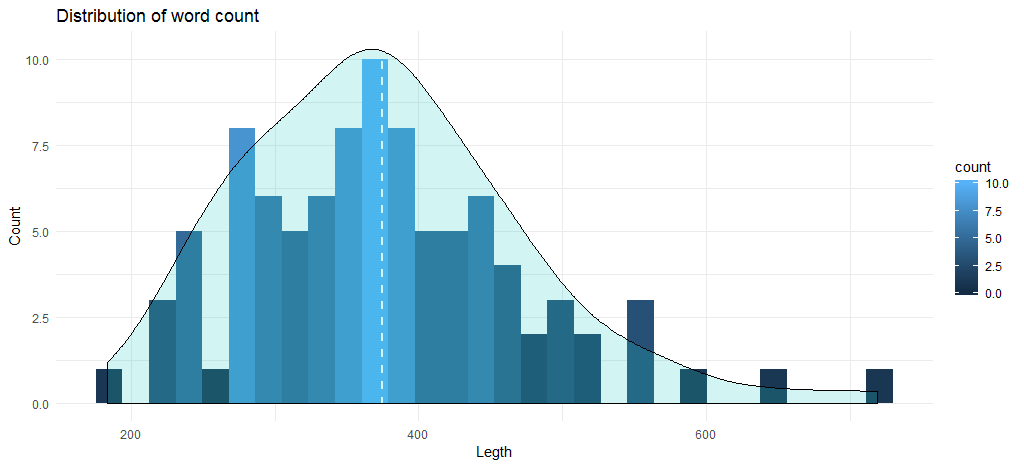
トラックの平均単語数は 375 に近く、チャートは曲の最大数が 345 から 400 単語の間にあることを示しています。 では、アルバムに基づくデータ分析に移りましょう。 最初に、アルバムとリリース年に基づく単語数を含むデータ フレームを作成しましょう。
[コード言語=”r”]
歌詞 %>%
group_by(アルバム,年) %>%
要約 (長さ = 合計 (長さ)) -> length_df_album
[/コード]
次のステップは、曲の累積単語数に基づいてアルバムの長さを示すチャートを作成することです。
[コード言語=”r”]
ggplot(length_df_album, aes(x= reorder(album, -length), y=length)) +
geom_bar(stat='identity', fill=”#1CCCC6”) +
ylab(“単語数”) + xlab (“アルバム”) +
ggtitle(“アルバム単位のワードカウント”) +
theme_minimal()
[/コード]
結果のチャートは、最新アルバムでもある「評判」アルバムが最大の単語数を持っていることを示しています。
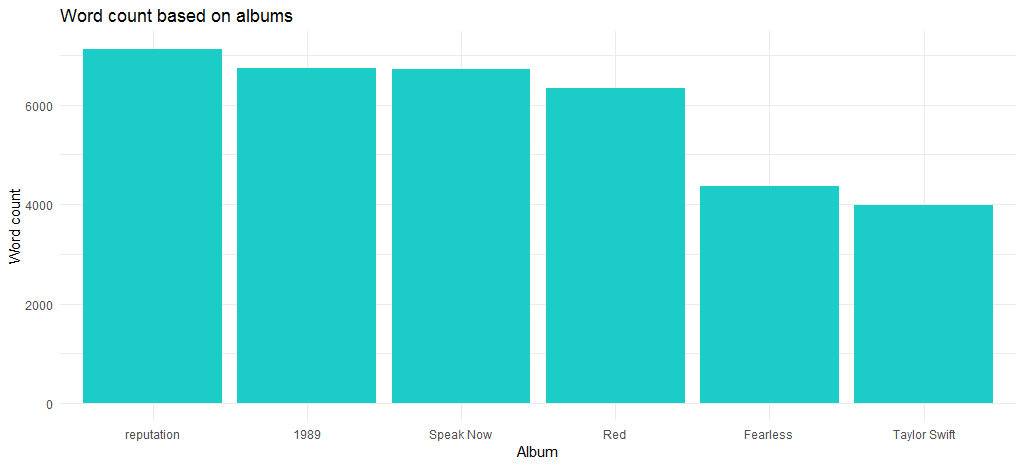
さて、2006年のデビュー以来、曲の長さはどのように変化しましたか? 次のコードはこれに答えます。
[コード言語=”r”]
length_df_album %>%
アレンジ(降順(年)) %>%
ggplot(., aes(x=係数(年), y=長さ, グループ= 1)) +
geom_line(色=”#1CCCC6”, サイズ=1) +
ylab(“単語数”) + xlab(“年”) +
ggtitle(“文字数の経年変化”) +
theme_minimal()
[/コード]
結果のグラフは、アルバムの長さが年々増加していることを示しています.2006年の4000語近くから2017年には6700語以上になりました.
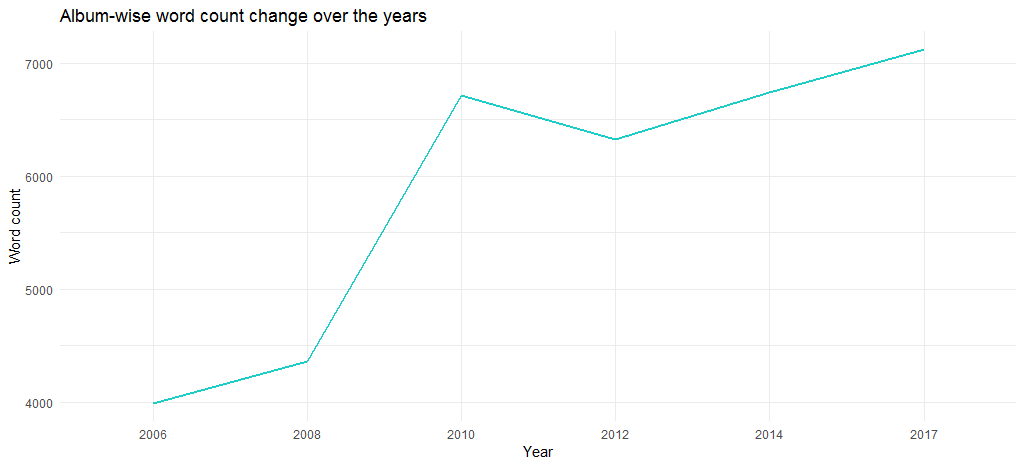
でも、それは個々のトラックの単語数のせいですか? 次のコードを使用して調べてみましょう。
[コード言語=”r”]
#track_title に合わせて年列を追加
length_df$年 <- 歌詞$年[一致(長さ_df$トラック_タイトル, 歌詞$トラック_タイトル)]
length_df %>%
group_by(年) %>%
要約 (長さ = 平均 (長さ)) %>%
ggplot(., aes(x=係数(年), y=長さ, グループ= 1)) +
geom_line(色=”#1CCCC6”, サイズ=1) +
ylab(“平均単語数”) + xlab (“年”) +
ggtitle(“年間平均文字数変化”) +
theme_minimal()
[/コード]
結果のグラフは、平均単語数が長年にわたって増加していることを確認します (2006 年の 285 から 2017 年の 475 へ)。つまり、彼女の歌は内容に関して徐々に長くなります。
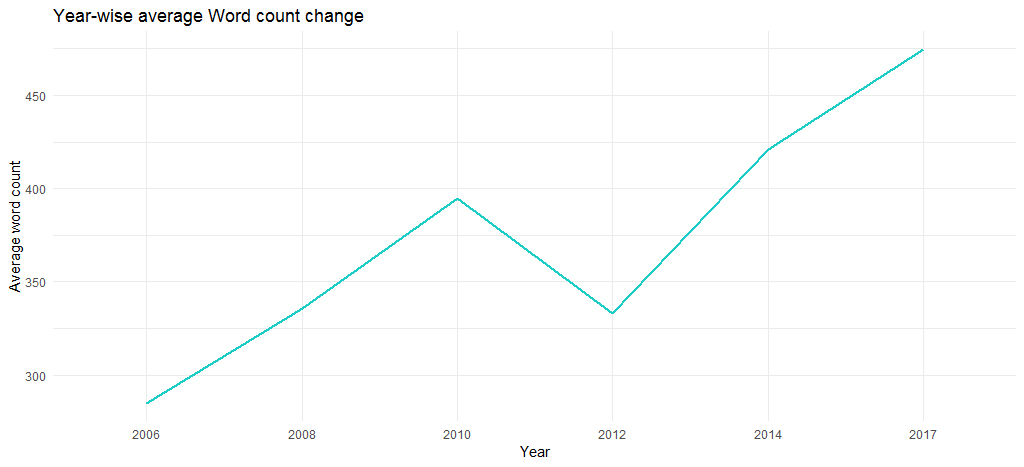
ここで探索的分析を終了し、テキスト マイニングに移ります。
Taylor Swift の歌詞のテキスト マイニング
最初のアクティビティは、単語クラウドを作成して、彼女の歌詞で頻繁に使用される単語を視覚化することです。 開始するには、次のコードを実行します。
[コード言語=”r”]
ライブラリ(「tm」)
ライブラリ(「ワードクラウド」)
歌詞_テキスト <- 歌詞$歌詞
#句読点と英数字コンテンツの削除
歌詞テキスト <- gsub('[[:punct:]]+', ”, 歌詞テキスト)
歌詞テキスト<- gsub(“([[:alpha:]])1+”, “”, 歌詞テキスト)
#テキストコーパスの作成
docs <- Corpus(VectorSource(lyrics_text))
# テキストを小文字に変換
docs <- tm_map(docs, content_transformer(tolower))
# 英語の一般的なストップワードの削除
docs <- tm_map(docs, removeWords, stopwords(“english”))
# 用語ドキュメント マトリックスの作成
tdm <- TermDocumentMatrix(ドキュメント)
# tdm を行列として定義
m <- as.matrix(tdm)
# 単語数を降順で取得
word_freqs = sort(rowSums(m), 減少=TRUE)
# 単語とその頻度でデータ フレームを作成する
Lyrics_wc_df <- data.frame(word=names(word_freqs), freq=word_freqs)
歌詞_wc_df <- 歌詞_wc_df[1:300,]
# ワードクラウドのプロット
セット.シード(1234)
wordcloud(単語 = 歌詞_wc_df$単語、頻度 = 歌詞_wc_df$頻度、
min.freq = 1,scale=c(1.8,.5),
max.words=200、random.order=FALSE、rot.per=0.15、
colors=brewer.pal(8, "Dark2"))
[/コード]
結果のワード クラウドは、最も頻繁に使用される単語が、 know 、 like 、 don't 、 you're 、 now 、 backいることを示しています。 これは、 you'reがかなりの数のオカレンスを持っているので、彼女の歌は主に誰かについてのものであることを確認しています.

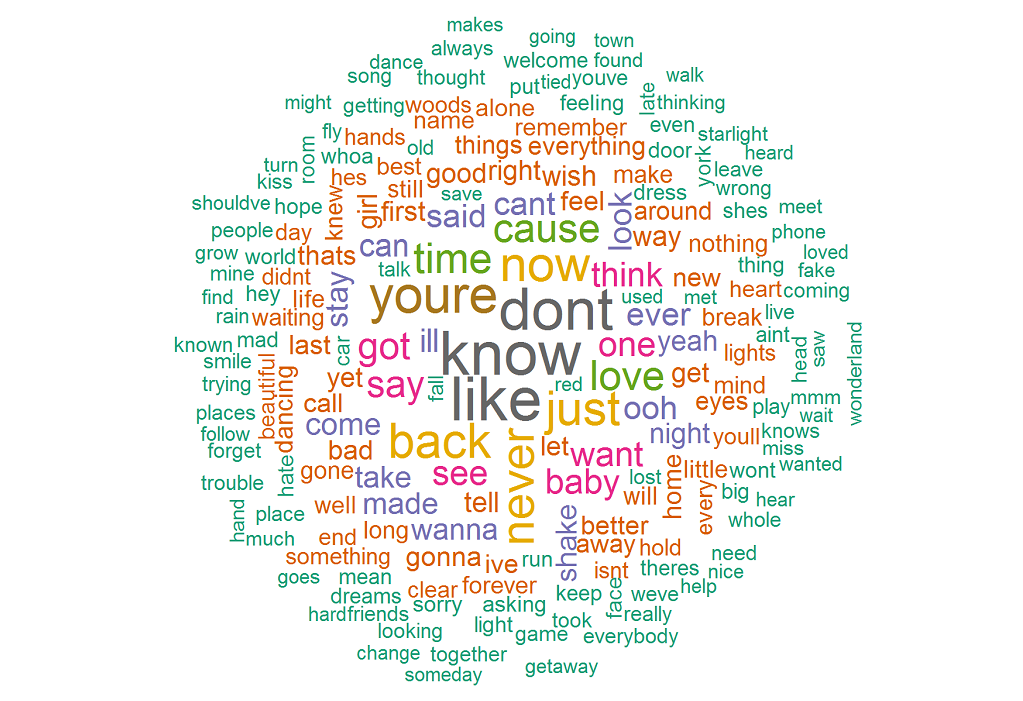
バイグラム(連接して現れる単語のペア)はどうですか? 次のコードは、上位 10 個のバイグラムを提供します。
[コード言語=”r”]
count_bigrams <- 関数(データセット) {
データセット %>%
unnest_tokens(bigram, lyric, token = “ngrams”, n = 2) %>%
分離(bigram, c(“単語1”, “単語2”), sep = ” “) %>%
filter(!word1 %in% stop_words$word,
!word2 %in% stop_words$word) %>%
カウント (単語 1、単語 2、並べ替え = TRUE)
}
Lyrics_bigrams <- 歌詞 %>%
count_bigrams()
head(lyrics_bigrams, 10)
[/コード]
以下に、バイグラムのリストを示します。
| 単語 1 | 単語 2 |
|---|---|
| ええ | ええ |
| ああ | ああ |
| ラ | ラ |
| 振る | 振る |
| 止まる | 止まる |
| 逃げる | 車 |
| ハ | ハ |
| ああ | うわあ |
| うーん | うーん |
| ハ | ああ |
単語リストを発見しましたが、単語間に存在するいくつかの関係についての洞察は明らかにされていません。 存在する可能性のある複数の関係を視覚化するために、ネットワーク グラフを活用します。 次のことから始めましょう。
[コード言語=”r”]
視覚化_バイグラム <- 関数(バイグラム) {
セットシード(2016)
a <- grid::arrow(type = "closed", length = unit(.15, "inches"))
バイグラム %>%
graph_from_data_frame() %>%
ggraph(レイアウト = “fr”) +
geom_edge_link(aes(edge_alpha = n), show.legend = FALSE, arrow = a) +
geom_node_point(色 = “水色”, サイズ = 5) +
geom_node_text(aes(ラベル = 名前), vjust = 1, hjust = 1) +
ggtitle(“バイグラムのネットワークグラフ”) +
theme_void()
}
歌詞_バイグラム %>%
フィルター (n > 3、
!str_detect(word1, “d”),
!str_detect(word2, “d”)) %>%
視覚化_バイグラム()
[/コード]
下のグラフをチェックして、 loveがstory 、 mad 、 true 、 tragic 、 magic 、 affairとどのように関連しているかを確認してください。 また、 tragicとmagicの両方がbeautifulと結びついています。

それでは、テキストマイニング手法であるセンチメント分析に移りましょう。
テイラー・スウィフトの曲の感情分析
まず、 syuzhetパッケージのnrcメソッドを使用して、全体的な感情を調べます。 次のコードは、関連する感情とともに正と負の極性のチャートを生成します。
[コード言語=”r”]
# 歌詞のセンチメント値を取得する
ty_sentiment <- get_nrc_sentiment((歌詞テキスト))
# 感情の累積値を持つデータフレーム
センチメントスコア<-data.frame(colSums(ty_sentiment[,]))
# センチメントとスコアを列とするデータフレーム
names(sentimentscores) <- 「スコア」
センチメントスコア <- cbind(“センチメント”=rownames(センチメントスコア),センチメントスコア)
行名 (センチメントスコア) <- NULL
# 累積感情のプロット
ggplot(データ=センチメントスコア,aes(x=センチメント,y=スコア))+
geom_bar(aes(fill=感情),stat = “アイデンティティ”)+
テーマ(legend.position="なし")+
xlab(“センチメント”)+ylab(“スコア”)+
ggtitle(“スコアに基づく総感情”)+
theme_minimal()
[/コード]
結果のグラフは、肯定的な感情スコアと否定的な感情スコアがそれぞれ 1340 と 1092 の値で比較的近いことを示しています。 感情面では、 joy 、 anticipation 、 trustが上位 3 位にランクインしています。
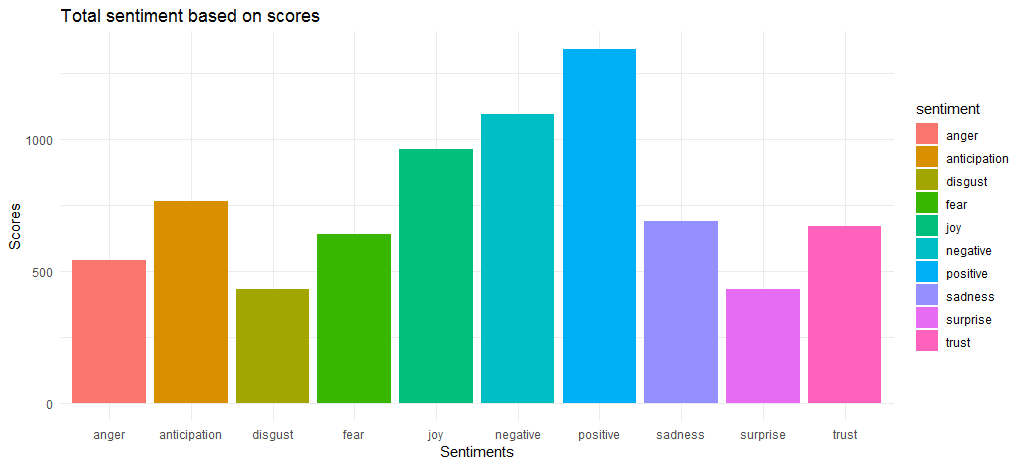
全体的なセンチメント スコアを把握したので、さまざまな感情とポジティブ/ネガティブな感情に寄与する上位の単語を見つける必要があります。
[コード言語=”r”]
歌詞$歌詞 <- as.character(歌詞$歌詞)
tidy_lyrics <- 歌詞 %>%
unnest_tokens(単語,歌詞)
song_wrd_count <- tidy_lyrics %>% count(track_title)
lyric_counts <- tidy_lyrics %>%
left_join(song_wrd_count, by = “track_title”) %>%
名前の変更 (total_words=n)
lyric_sentiment <- tidy_lyrics %>%
inner_join(get_sentiments(“nrc”),by="単語")
歌詞の感情 %>%
count(word,sentiment,sort=TRUE) %>%
group_by(センチメント)%>%top_n(n=10) %>%
グループ解除() %>%
ggplot(aes(x=reorder(word,n),y=n,fill=感情)) +
geom_col(show.legend = FALSE) +
facet_wrap(~sentiment,scales=”無料”) +
xlab(“センチメント”) + ylab(“スコア”)+
ggtitle(“感情や感情を表現するのによく使われる言葉”) +
coord_flip()
[/コード]
与えられたデータ ビジュアライゼーションは、 badという言葉がanger 、 disgust 、 sadness 、 fear, Surpriseとtrustはgoodという言葉によって動かされることを示しています。
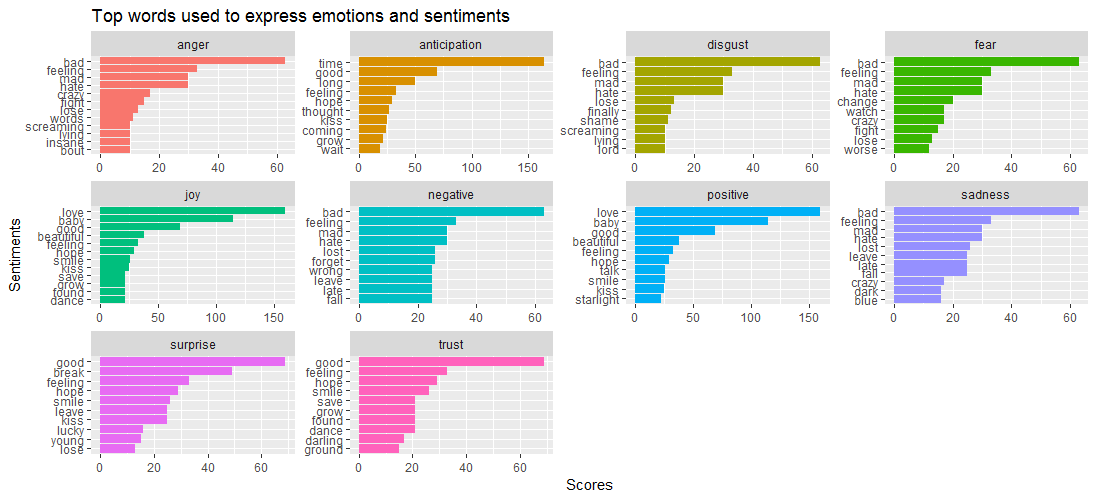
これは、次の質問につながります。さまざまな感情と密接に関連している曲はどれですか? 以下のコードで調べてみましょう。
[コード言語=”r”]
歌詞の感情 %>%
count(track_title,sentiment,sort=TRUE) %>%
group_by(センチメント) %>%
top_n(n=5) %>%
ggplot(aes(x=reorder(track_title,n),y=n,fill=感情)) +
geom_bar(stat="identity",show.legend = FALSE) +
facet_wrap(~sentiment,scales=”無料”) +
xlab(“センチメント”) + ylab(“スコア”)+
ggtitle(“感情やセンチメントに関連するトップソング”) +
coord_flip()
[/コード]
Black Spaceという曲は、他の曲に比べて怒りと恐怖がたくさんあることがわかります。 私はpositiveな感情とnegative的な感情の両方でかなりのスコアを持っているので、私を責めないでください. また、 Shake it offのスコアがnegative的なセンチメントで高いこともわかります。 主に、 hateやfakeなどの頻度の高い言葉が原因です。
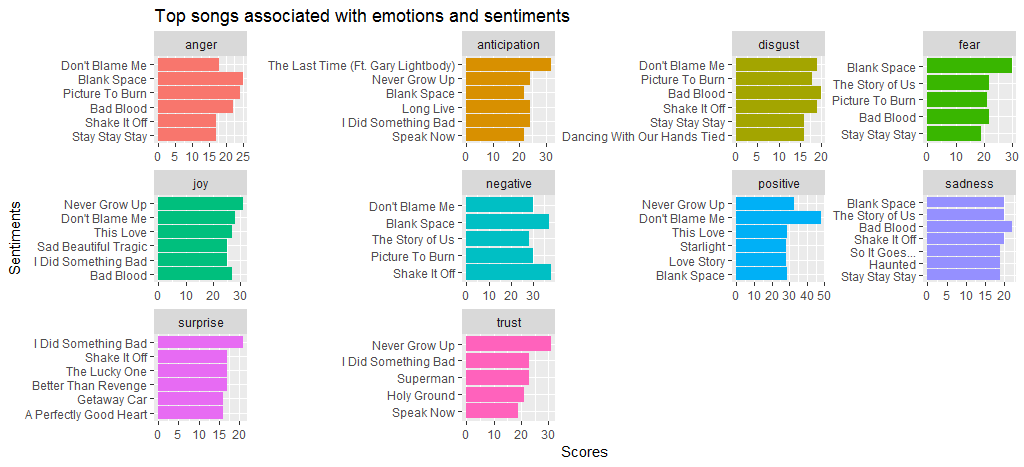
それでは、もう 1 つの感情分析方法であるbingに移り、肯定的な感情と否定的な感情の比較ワード クラウドを作成します。
[コード言語=”r”]
bng <- get_sentiments(“bing”)
セット.シード(1234)
tidy_lyrics %>%
inner_join(get_sentiments(“bing”)) %>%
count(単語、感情、並べ替え = TRUE) %>%
acast(word ~ センチメント, value.var = “n”, fill = 0) %>%
comparison.cloud(colors = c(“#F8766D”, “#00BFC4”),
最大単語数 = 250)
[/コード]
次のデータの視覚化は、彼女の歌にlike 、 love 、 good 、 rightなどの肯定的な言葉と、 bad 、 break 、 shake 、 mad 、 wrongなどの否定的な言葉があることを示しています。
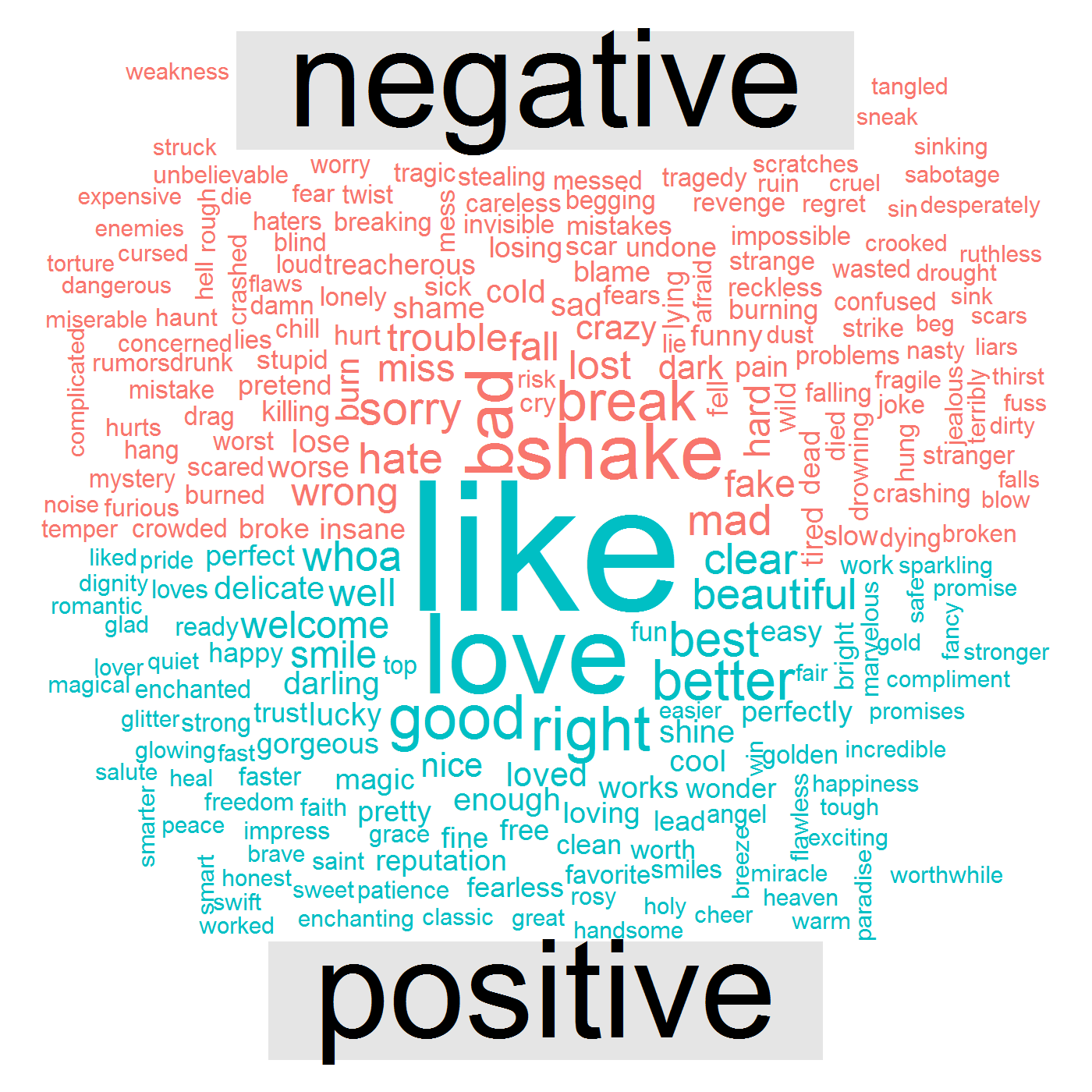
これは最後の質問につながります – 彼女の感情と感情は何年にもわたってどのように変化しましたか? この特定の回答のために、 chord diagramと呼ばれる視覚化を作成します。 コードは次のとおりです。
[コード言語=”r”]
grid.col = c(“2006” = “#E69F00”, “2008” = “#56B4E9”, “2010” = “#009E73”, “2012” = “#CC79A7”, “2014” = “#D55E00” 、「2017」=「#00D6C9」、「怒り」=「灰色」、「期待」=「灰色」、「嫌悪感」=「灰色」、「恐怖」=「灰色」、「喜び」=「灰色」、 「悲しみ」=「灰色」、「驚き」=「灰色」、「信頼」=「灰色」)
year_emotion <- lyric_sentiment %>%
filter(!感情 %in% c(“ポジティブ”, “ネガティブ”)) %>%
count(感情、年) %>%
group_by(年, センチメント) %>%
summarise(sentiment_sum = sum(n)) %>%
グループ解除()
サーコス.クリア()
#ギャップサイズの設定
circos.par(gap.after = c(rep(6, length(unique(year_emotion[[1]])) – 1), 15,
rep(6, length(unique(year_emotion[[2]])) – 1), 15))
chordDiagram(year_emotion, grid.col = grid.col, 透明度 = .2)
タイトル(「感情と歌のリリース年の関係」)
[/コード]
次の視覚化が得られます。
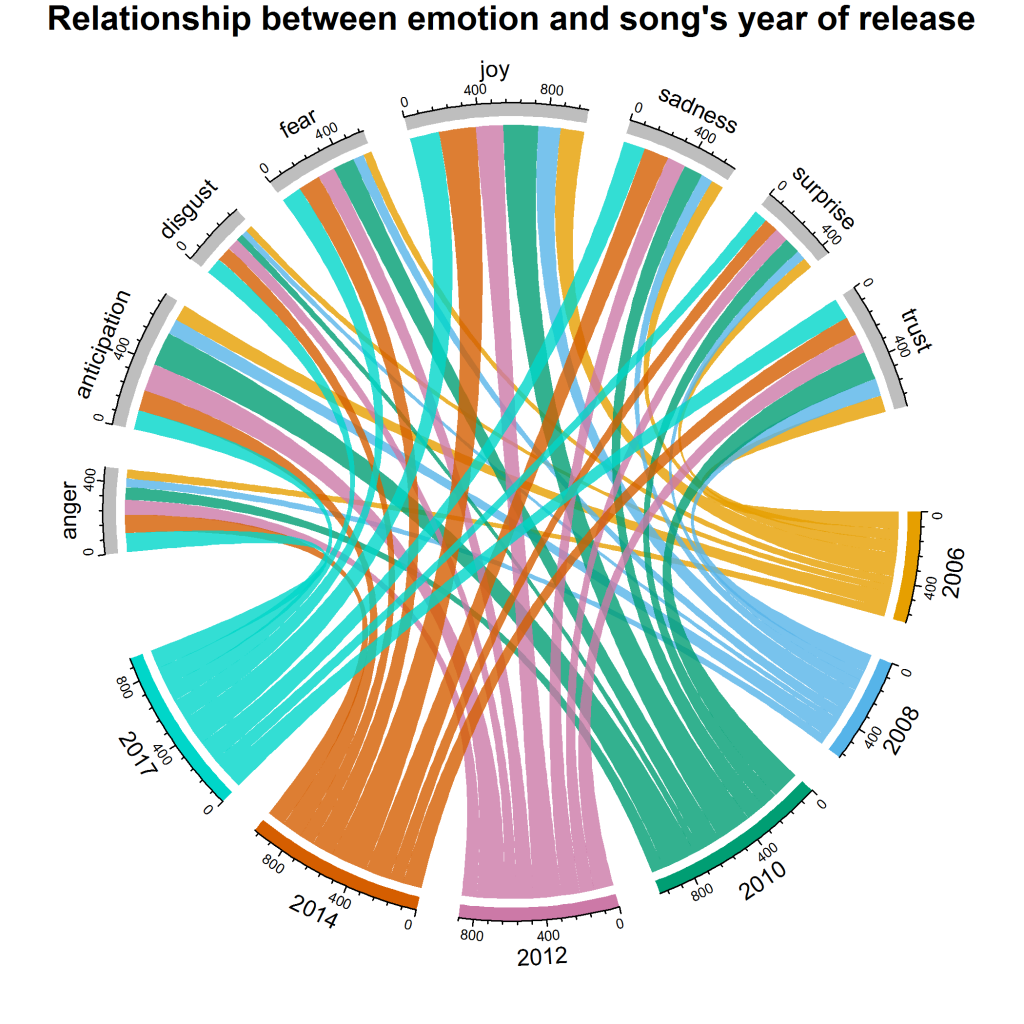
2010 年と 2014 年では、 joyの割合が最大であることがわかります。全体として、 surprise 、 disgust 、 angerが最もスコアの低い感情です。 ただし、他の年と比較して、2017年はdisgustの最大の貢献をしています。 anticipationされるように、2010 年と 2012 年は他の年に比べて貢献度が高くなっています。
オーバー・トゥ・ユー
この調査では、探索的分析と、センチメント分析のための NLP を含むテキスト マイニングを実行しました。 追加の分析 (歌詞の語彙密度やトピック モデリングなど) を実行したい場合、または単に学習のために結果を複製したい場合は、DataStock から無料でデータ セットをダウンロードしてください。 以下のリンクをたどって、DataStock の「無料」カテゴリを選択してください。
