
Datenvisualisierung und Analyse von Songtexten von Taylor Swift
Veröffentlicht: 2018-07-19Wussten Sie, dass Taylor Swift die jüngste Person ist, die im Alleingang einen Nummer-eins-Song in der vom Billboard Magazine in den USA veröffentlichten Hot Country Songs-Liste geschrieben und aufgeführt hat? Sie ist besonders dafür bekannt, ihr Privatleben in ihre Musik einfließen zu lassen, die viel Medienberichterstattung erhalten hat. Es wäre interessant, die Liedtexte von Taylor Swift durch explorative Analyse und Stimmungsanalyse zu analysieren, um verschiedene zugrunde liegende Themen herauszufinden.
Datensatz zur Analyse von Songtexten von Taylor Swift
Dank der erstaunlichen API von Genius.com konnten wir die verschiedenen Datenpunkte extrahieren, die mit den Songs von Taylor Swift verbunden sind.
Wir haben nur die sechs von ihr veröffentlichten Alben ausgewählt und die doppelten Tracks (Akustik, US-Version, Pop-Mix, Demo-Aufnahme usw.) entfernt. Dies führte zu 94 eindeutigen Tracks mit den folgenden Datenfeldern:
- Albumname
- Tracktitel
- Titelnummer
- lyrischer Text
- Zeilennummer
- Erscheinungsjahr des Albums
[call_to_action title="Datensatz kostenlos herunterladen" icon="icon-download" link="https://app.promptcloud.com/users/sign_up?target=data_stocks&itm_source=website&itm_medium=blog&itm_campaign=dataviz&itm_term=ts-lyrics&itm_content= Data-Mining" button_title="" class="" target="_blank" animate=""]Melden Sie sich über CrawlBoard für DataStock an und klicken Sie auf die Kategorie "kostenlos", um den Datensatz herunterzuladen![/call_to_action]
Ziele
Unser Ziel ist es, zunächst eine explorative Analyse durchzuführen und dann zum Text-Mining überzugehen, einschließlich Sentimentanalyse, die die Verarbeitung natürlicher Sprache beinhaltet.
– Explorative Analyse
- Wortzählungen basierend auf Titeln und Alben
- Zeitreihenanalyse von Wortzahlen
- Verteilung der Wortzahlen
– Text-Mining
- Wortwolke
- Bigramm-Netzwerk
- Stimmungsanalyse (inkl. Akkorddiagramm)
Wir werden R und ggplot2 , um die Daten zu analysieren und zu visualisieren. Code ist auch in diesem Beitrag enthalten, wenn Sie also die Daten herunterladen, können Sie mitverfolgen.
Explorative Analyse
Lassen Sie uns zuerst die Top-Ten-Songs mit den meisten Wörtern herausfinden. Das unten angegebene Code-Snippet enthält die für diese Analyse erforderlichen Pakete und ermittelt die Top-Songs in Bezug auf die Länge.
[code language="r"]
Bibliothek (magrittr)
Bibliothek (stringr)
Bibliothek (dplyr)
Bibliothek (ggplot2)
Bibliothek (tm)
Bibliothek (Wortwolke)
Bibliothek (syzhet)
Bibliothek (Tidytext)
Bibliothek (aufräumen)
Bibliothek (igraph)
Bibliothek (ggraph)
Bibliothek (Leser)
Bibliothek (einkreisen)
Bibliothek (umgestalten2)
Liedtexte <- read.csv(file.choose())
songtexte$länge <- str_count(lyrics$lyric,”S+”)
length_df <- Liedtext %>%
group_by(track_title) %>%
zusammenfassen (länge = summe (länge))
length_df %>%
anordnen(absteigen(länge)) %>%
Scheibe(1:10) %>%
ggplot(., aes(x=reorder(track_title, -length), y=length)) +
geom_bar(stat='identity', fill=”#1CCCC6″) +
ylab(„Wortzahl“) + xlab („Titeltitel“) +
ggtitle(“Top 10 Songs in Bezug auf die Wortzahl”) +
theme_minimal() +
scale_x_discrete(labels = function(labels) {
sapply(seq_along(labels), function(i) paste0(ifelse(i %% 2 == 0, ”, 'n'), labels[i]))
})
[/Code]
Damit erhalten wir folgendes Diagramm:
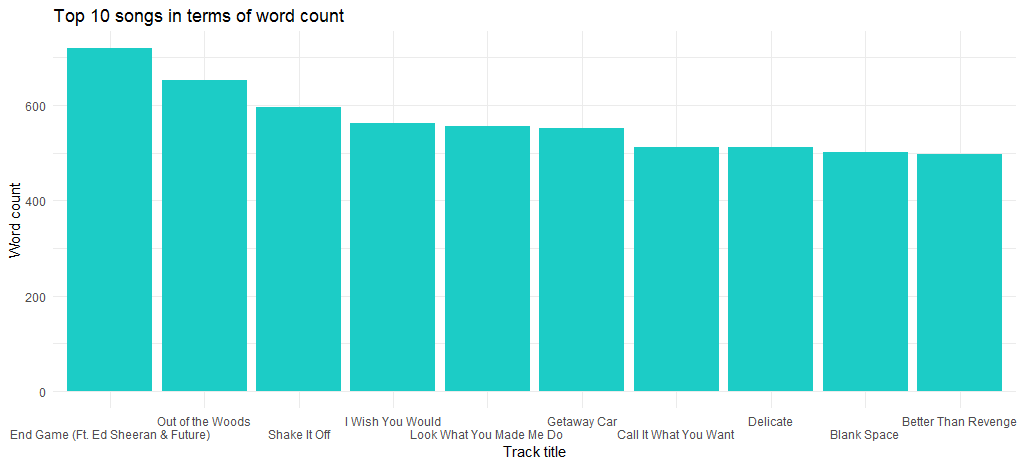
Wir können sehen, dass „End Game“ (veröffentlicht auf ihrem neuesten Album) das Lied mit der maximalen Anzahl von Wörtern ist und als nächstes „Out of the Woods“ an der Reihe ist.
Wie sieht es nun mit den Liedern mit den wenigsten Wörtern aus? Finden wir es mit dem folgenden Code heraus:
[code language="r"]
length_df %>%
anordnen(länge) %>%
Scheibe(1:10) %>%
ggplot(., aes(x=reorder(track_title, length), y=length)) +
geom_bar(stat='identity', fill=”#1CCCC6″) +
ylab(„Wortzahl“) + xlab („Titeltitel“) +
ggtitle(“10 Lieder mit der geringsten Anzahl an Wörtern”) +
theme_minimal() +
scale_x_discrete(labels = function(labels) {
sapply(seq_along(labels), function(i) paste0(ifelse(i %% 2 == 0, ”, 'n'), labels[i]))
})
[/Code]
Daraus ergibt sich folgendes Diagramm:
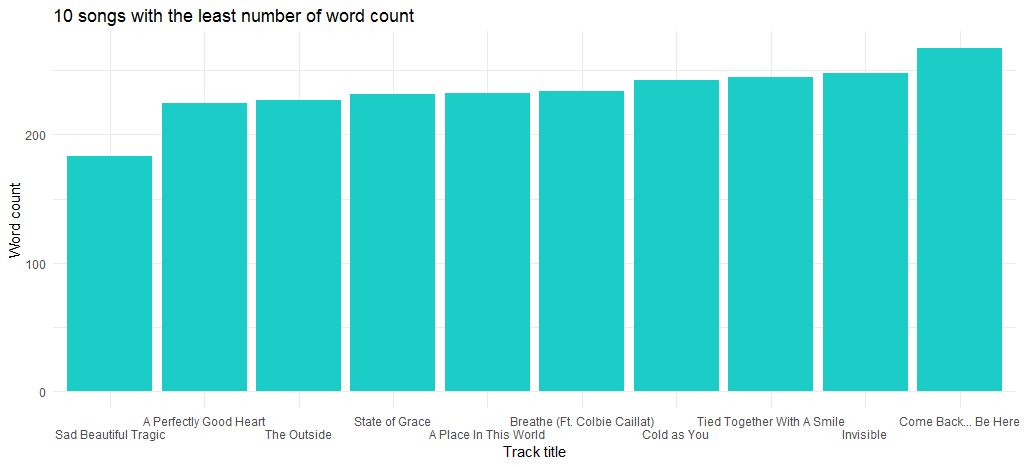
Der Song „Sad Beautiful Tragic“, der 2012 als Teil des Albums „Red“ veröffentlicht wurde, ist der Song mit den wenigsten Wörtern.
Die nächste Datenanalyse konzentriert sich auf die Verteilung der Wortanzahl. Da unten ist der Code:
[code language="r"]
ggplot(length_df, aes(x=length)) +
geom_histogram(bins=30,aes(fill = ..count..)) +
geom_vline(aes(xintercept=Mittelwert(Länge)),
color=“#FFFFFF“, linetype=“gestrichelt“, size=1) +
geom_density(aes(y=25 * ..count..),alpha=.2, fill=”#1CCCC6″) +
ylab(„Anzahl“) + xlab („Länge“) +
ggtitle(“Verteilung der Wortanzahl”) +
theme_minimal()
[/Code]
Dieser Code gibt uns das folgende Histogramm zusammen mit einer Dichtekurve:
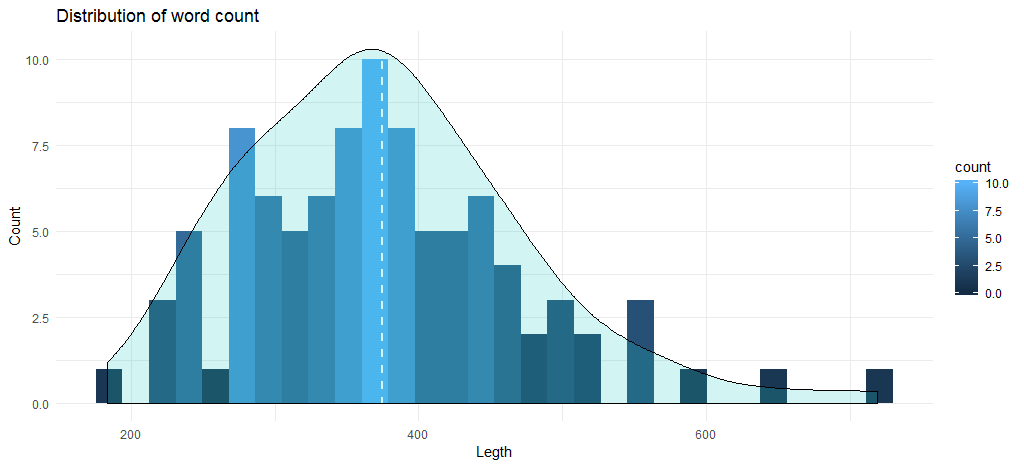
Die durchschnittliche Wortzahl für die Tracks liegt bei fast 375, und das Diagramm zeigt, dass die maximale Anzahl von Songs zwischen 345 und 400 Wörtern liegt. Kommen wir nun zur Datenanalyse basierend auf Alben. Erstellen wir zunächst einen Datenrahmen mit Wortzahlen basierend auf Album und Erscheinungsjahr.
[code language="r"]
Liedtext %>%
group_by(Album,Jahr) %>%
summarise(length = sum(length)) -> length_df_album
[/Code]
Der nächste Schritt besteht für uns darin, ein Diagramm zu erstellen, das die Länge der Alben basierend auf der kumulativen Wortzahl der Songs darstellt.
[code language="r"]
ggplot(length_df_album, aes(x= reorder(album, -length), y=length)) +
geom_bar(stat='identity', fill=”#1CCCC6″) +
ylab(„Wörter zählen“) + xlab („Album“) +
ggtitle(“Wortzahl basierend auf Alben”) +
theme_minimal()
[/Code]
Das resultierende Diagramm zeigt, dass das „Reputation“-Album, das auch das neueste Album ist, die maximale Anzahl von Wörtern hat.
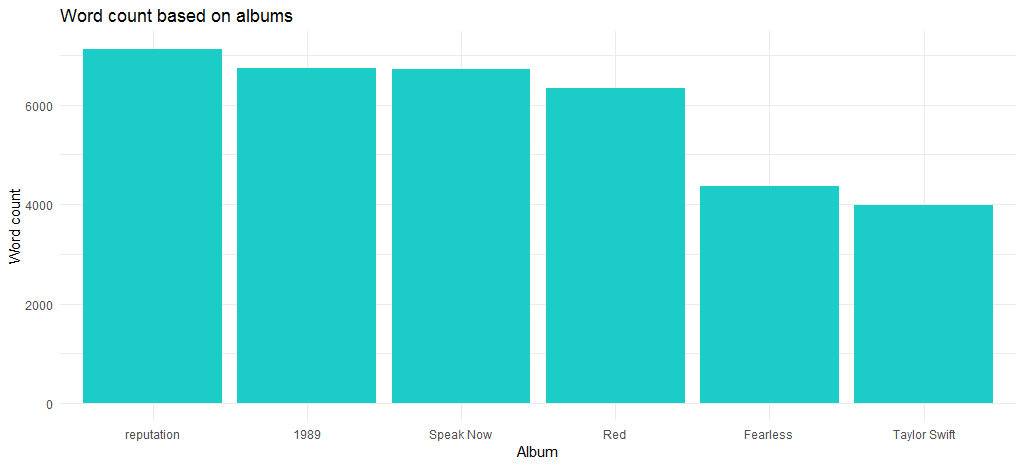
Wie hat sich die Länge der Songs seit dem Debüt von 2006 verändert? Der folgende Code beantwortet dies:
[code language="r"]
length_df_album %>%
arrangieren(desc(Jahr)) %>%
ggplot(., aes(x= Faktor(Jahr), y=Länge, Gruppe = 1)) +
geom_line(colour=”#1CCCC6″, size=1) +
ylab(„Wörteranzahl“) + xlab („Jahr“) +
ggtitle(„Änderung der Wortanzahl im Laufe der Jahre“) +
theme_minimal()
[/Code]
Das resultierende Diagramm zeigt, dass die Länge der Alben im Laufe der Jahre zugenommen hat – von fast 4000 Wörtern im Jahr 2006 auf mehr als 6700 im Jahr 2017.
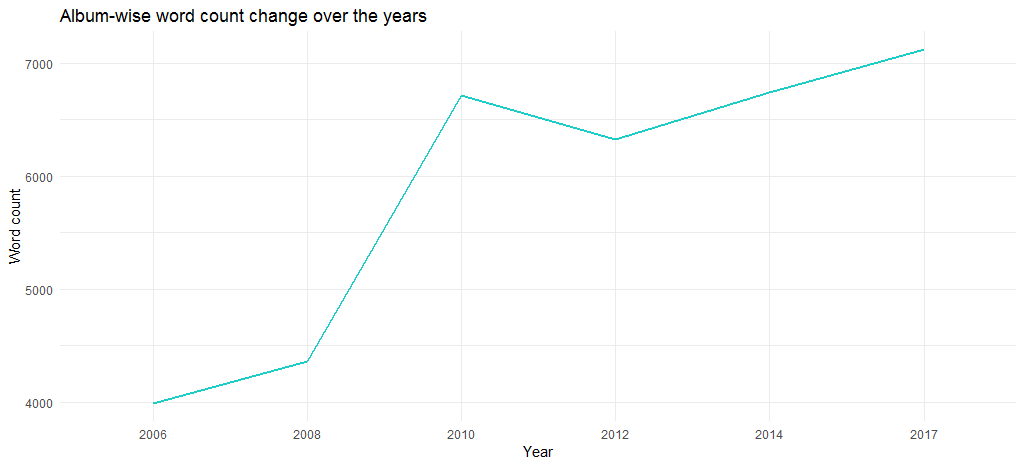
Aber liegt das an der Anzahl der Wörter in den einzelnen Tracks? Finden wir es mit dem folgenden Code heraus:
[code language="r"]
#Hinzufügen einer Jahresspalte durch Abgleichen von track_title
length_df$year <- lyrics$year[match(length_df$track_title, lyrics$track_title)]
length_df %>%
group_by(Jahr) %>%
zusammenfassen (Länge = Mittelwert (Länge)) %>%
ggplot(., aes(x= Faktor(Jahr), y=Länge, Gruppe = 1)) +
geom_line(colour=”#1CCCC6″, size=1) +
ylab("Durchschnittliche Wortanzahl") + xlab ("Jahr") +
ggtitle("Jahresdurchschnittliche Änderung der Wortanzahl") +
theme_minimal()
[/Code]
Die resultierende Grafik bestätigt, dass die durchschnittliche Wortzahl über die Jahre gestiegen ist (von 285 im Jahr 2006 auf 475 im Jahr 2017), dh ihre Songs wurden inhaltlich immer länger.
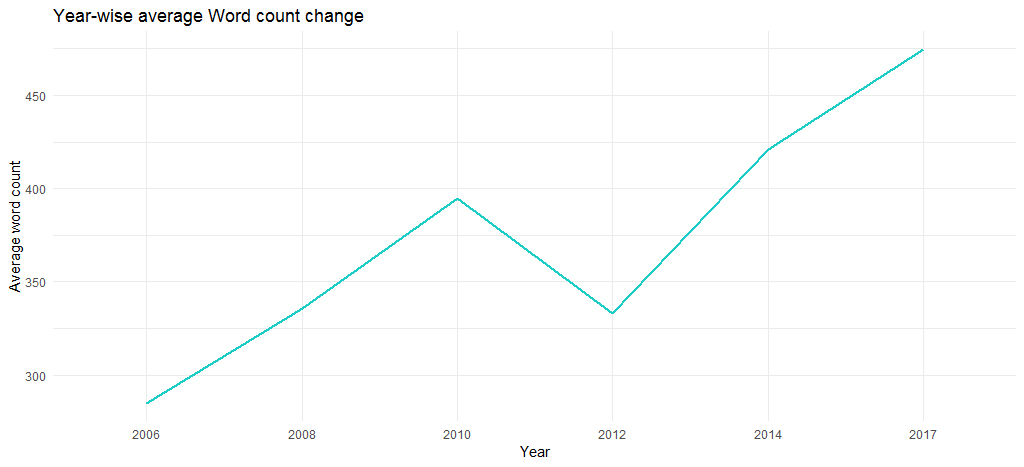
Wir schließen hier die explorative Analyse ab und gehen zum Text Mining über.
Text-Mining von Songtexten von Taylor Swift Songs
Unsere erste Aktivität wäre, eine Wortwolke zu erstellen, damit wir die häufig verwendeten Wörter in ihren Texten visualisieren können. Führen Sie den folgenden Code aus, um zu beginnen:
[code language="r"]
Bibliothek ("tm")
Bibliothek ("Wortwolke")
lyrics_text <- songtext$text
#Entfernen von Satzzeichen und alphanumerischen Inhalten
songtext_text<- gsub('[[:punct:]]+', ”, songtext_text)
songtext_text<- gsub(“([[:alpha:]])1+”, “”, songtext_text)
#Erstellen eines Textkorpus
docs <- Corpus(VectorSource(lyrics_text))
# Umwandlung des Textes in Kleinbuchstaben
docs <- tm_map(docs, content_transformer(tolower))
# Entfernen allgemeiner englischer Stoppwörter
docs <- tm_map(docs, removeWords, stopwords(“english”))
# Begriffsdokumentmatrix erstellen
tdm <- TermDocumentMatrix(docs)
# tdm als Matrix definieren
m <- as.Matrix(tdm)
# Abrufen der Wortanzahl in absteigender Reihenfolge
word_freqs = sort(rowSums(m), absteigend=TRUE)
# Erstellen eines Datenrahmens mit Wörtern und ihren Häufigkeiten
lyrics_wc_df <- data.frame (word=names(word_freqs), freq=word_freqs)

lyrics_wc_df <- lyrics_wc_df[1:300,]
# Wortwolke plotten
set.seed(1234)
wordcloud(words = lyrics_wc_df$word, freq = lyrics_wc_df$freq,
min.freq = 1, Skala = c (1,8, 0,5),
max.words=200, random.order=FALSE, rot.per=0.15,
colors=brewer.pal(8, „Dark2“))
[/Code]
Die sich daraus ergebende Wortwolke zeigt, dass die am häufigsten verwendeten Wörter know like don't , you're , now , back sind. Dies bestätigt, dass es in ihren Liedern hauptsächlich um jemanden geht, da you're eine beträchtliche Anzahl von Vorkommen hat.
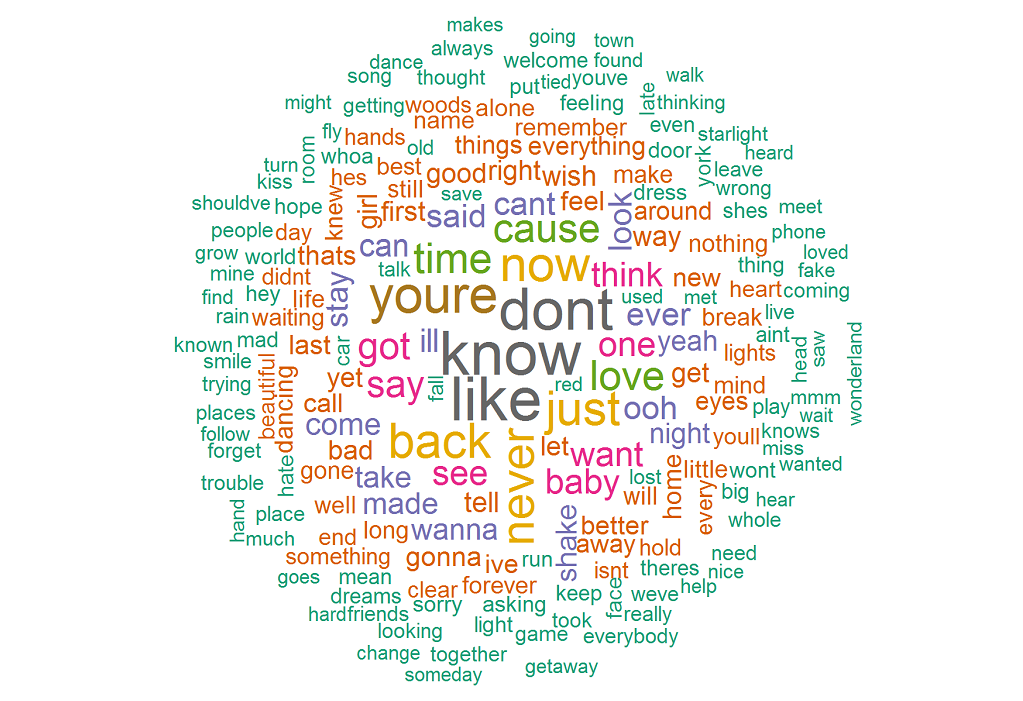
Wie wäre es mit Bigrammen (Wortpaare, die in Konjunktion vorkommen)? Der folgende Code gibt uns die zehn besten Bigramme:
[code language="r"]
count_bigrams <- Funktion (Datensatz) {
Datensatz %>%
unnest_tokens(bigram, lyric, token = „ngrams“, n = 2) %>%
separate(bigram, c(„word1“, „word2″), sep = ” “) %>%
filter(!word1 %in% stop_words$wort,
!word2 %in% stop_words$word) %>%
count(word1, word2, sort = TRUE)
}
lyrics_bigramme <- songtexte %>%
count_bigrams()
Kopf (lyrics_bigrams, 10)
[/Code]
Unten ist die Liste der Bigramme:
| Wort 1 | Wort 2 |
|---|---|
| ey | ey |
| Oh | Oh |
| la | la |
| Shake | Shake |
| bleibe | bleibe |
| Flucht | Wagen |
| Ha | Ha |
| Oh | wow |
| äh | äh |
| Ha | Ah |
Obwohl wir die Wortliste herausgefunden haben, gibt sie keinen Einblick in mehrere Beziehungen, die zwischen Wörtern bestehen. Um eine Visualisierung der vielfältigen Beziehungen zu erhalten, die bestehen können, werden wir Netzwerkdiagramme nutzen. Beginnen wir mit Folgendem:
[code language="r"]
visual_bigrams <- funktion(bigramme) {
set.seed(2016)
a <- grid::arrow(type = „closed“, length = unit(.15, „inches“))
Bigramme %>%
graph_from_data_frame() %>%
ggraph(Layout = „fr“) +
geom_edge_link(aes(edge_alpha = n), show.legend = FALSE, Pfeil = a) +
geom_node_point(Farbe = „hellblau“, Größe = 5) +
geom_node_text(aes(label = name), vjust = 1, hjust = 1) +
ggtitle(“Netzwerkdiagramm von Bigrammen”) +
theme_void()
}
lyrics_bigramme %>%
filter(n > 3,
!str_detect(word1, „d“),
!str_detect(word2, „d“)) %>%
visual_bigrams()
[/Code]
Sehen Sie sich die Grafik unten an, um zu sehen, wie love mit story , mad , true , tragic , magic und affair verbunden ist. Auch tragic und magic sind mit dem beautiful verbunden.

Kommen wir nun zur Stimmungsanalyse, einer Text-Mining-Technik.
Stimmungsanalyse von Taylor Swift-Songs
Zuerst ermitteln wir die Gesamtstimmung über die nrc -Methode des syuzhet -Pakets. Der folgende Code generiert das Diagramm der positiven und negativen Polarität zusammen mit den zugehörigen Emotionen.
[code language="r"]
# Abrufen des Sentimentwerts für den Text
ty_sentiment <- get_nrc_sentiment((lyrics_text))
# Dataframe mit kumulativem Wert der Stimmungen
sentimentscores<-data.frame(colSums(ty_sentiment[,]))
# Dataframe mit Sentiment und Punktzahl als Spalten
Namen (Sentimentscores) <- „Score“
Sentimentscores <- cbind(“sentiment”=rownames(sentimentscores),sentimentscores)
rownames(sentimentscores) <- NULL
# Diagramm für die kumulativen Stimmungen
ggplot(data=Stimmungsergebnisse,aes(x=Stimmung,y=Punktzahl))+
geom_bar(aes(fill=sentiment),stat = „identity“)+
theme(legend.position="none")+
xlab(„Stimmungen“)+ylab(„Ergebnisse“)+
ggtitle("Gesamtstimmung basierend auf Bewertungen")+
theme_minimal()
[/Code]
Das resultierende Diagramm zeigt, dass die positiven und negativen Stimmungswerte mit Werten von 1340 bzw. 1092 relativ nahe beieinander liegen. Bei den Emotionen kommen joy , anticipation und trust als Top 3 heraus.
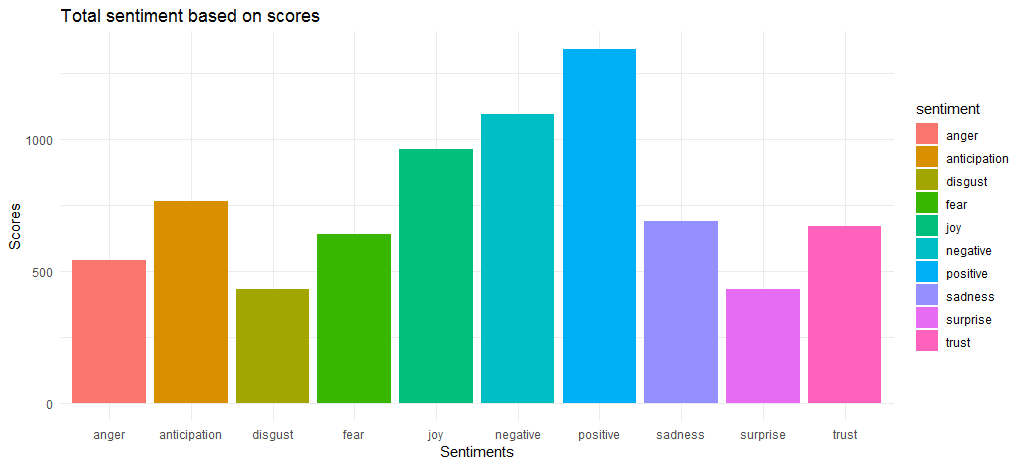
Nachdem wir nun die Gesamtstimmungswerte ermittelt haben, sollten wir die wichtigsten Wörter herausfinden, die zu verschiedenen Emotionen und positiven/negativen Stimmungen beitragen.
[code language="r"]
songtext$lyric <- as.character(lyrics$lyric)
tidy_lyrics <- Text %>%
unnest_tokens(word,lyric)
song_wrd_count <- tidy_lyrics %>% count(track_title)
lyric_counts <- tidy_lyrics %>%
left_join(song_wrd_count, by = „track_title“) %>%
umbenennen (total_words=n)
lyric_sentiment <- tidy_lyrics %>%
inner_join(get_sentiments(“nrc”),by=”word”)
lyric_sentiment %>%
count(word,gefühl,sort=TRUE) %>%
group_by(meinung)%>%top_n(n=10) %>%
Gruppierung aufheben () %>%
ggplot(aes(x=reorder(word,n),y=n,fill=sentiment)) +
geom_col(show.legend = FALSE) +
facet_wrap(~sentiment,scales="free") +
xlab(„Stimmungen“) + ylab(„Ergebnisse“)+
ggtitle(„Top-Wörter zum Ausdruck von Emotionen und Gefühlen“) +
coord_flip()
[/Code]
Die angegebene Datenvisualisierung zeigt, dass, während das Wort bad in Emotionen wie anger , disgust , sadness und fear, Surprise und trust durch das Wort good angetrieben werden.
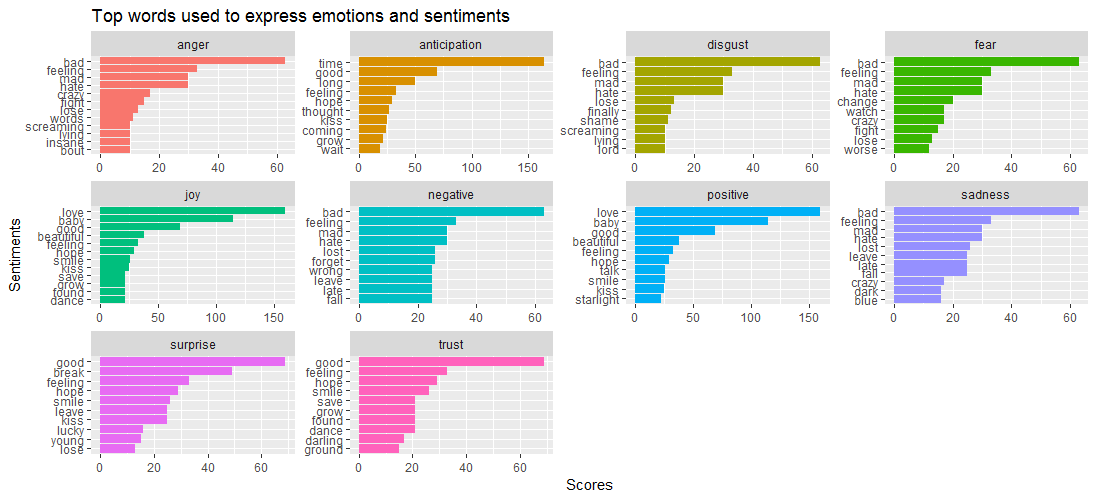
Das bringt uns zu folgender Frage: Welche Songs sind eng mit verschiedenen Emotionen verbunden? Finden wir es über den unten angegebenen Code heraus:
[code language="r"]
lyric_sentiment %>%
count(track_title,sentiment,sort=TRUE) %>%
group_by(meinung) %>%
top_n(n=5) %>%
ggplot(aes(x=reorder(track_title,n),y=n,fill=sentiment)) +
geom_bar(stat=“identität“,show.legend = FALSE) +
facet_wrap(~sentiment,scales="free") +
xlab(„Stimmungen“) + ylab(„Ergebnisse“)+
ggtitle („Top-Songs, die mit Emotionen und Gefühlen verbunden sind“) +
coord_flip()
[/Code]
Wir sehen, dass der Song Black Space im Vergleich zu anderen Songs viel Wut und Angst hat. Machen Sie mir keine Vorwürfe, denn ich habe eine beträchtliche Punktzahl für positive und negative Stimmung. Wir sehen auch, dass Shake it off bei negative Stimmung hoch abschneidet; hauptsächlich wegen häufig vorkommender Wörter wie hate und fake .
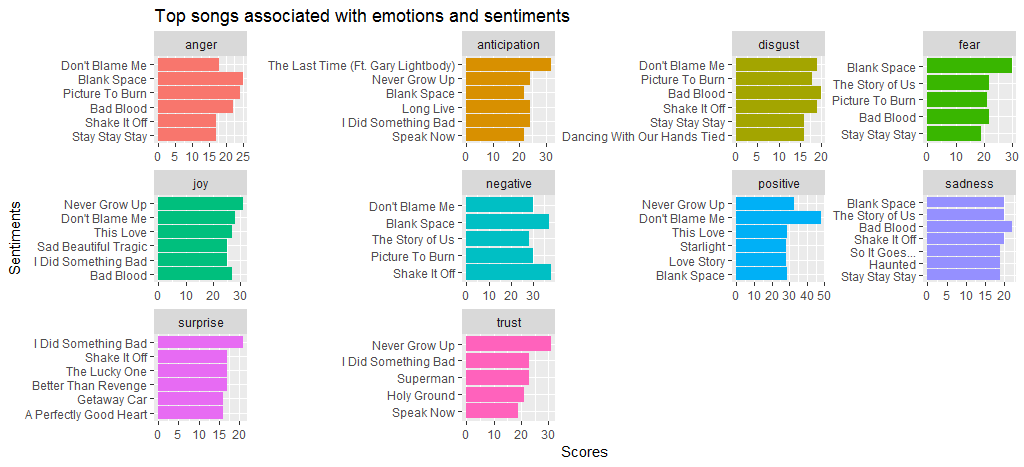
Lassen Sie uns nun zu einer anderen Stimmungsanalysemethode übergehen und eine vergleichende bing aus positiver und negativer Stimmung erstellen.
[code language="r"]
bng <- get_sentiments(“bing”)
set.seed(1234)
tidy_lyrics %>%
inner_join(get_sentiments(“bing”)) %>%
count(word, sentiment, sort = TRUE) %>%
acast(word ~ sentiment, value.var = „n“, fill = 0) %>%
Vergleich.Cloud (Farben = c ("#F8766D", "#00BFC4"),
max. Wörter = 250)
[/Code]
Die folgende Datenvisualisierung zeigt, dass ihre Songs positive Wörter wie „ like “, love , good , right “ und negative Wörter wie „ bad , „ break “, shake , mad , „ wrong .
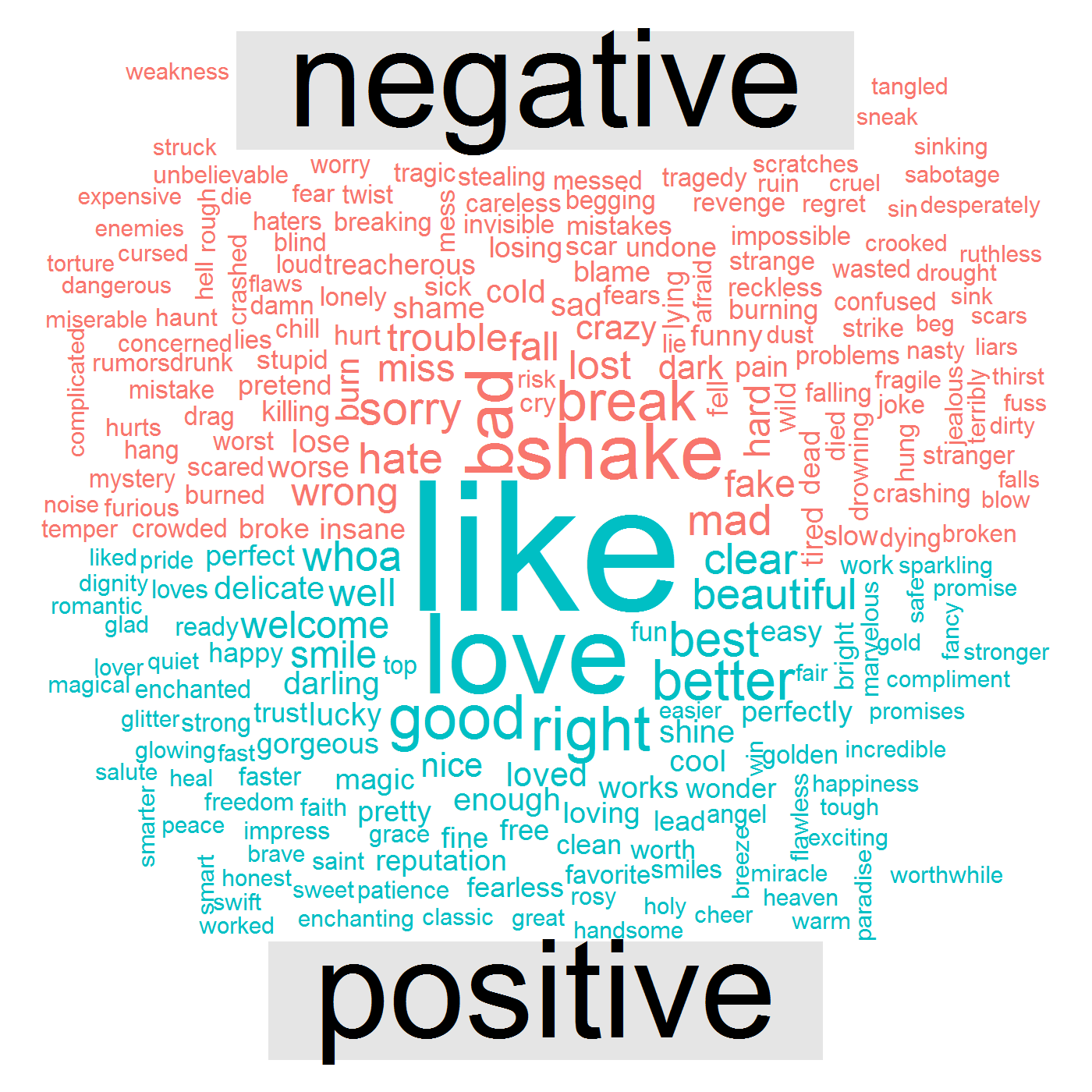
Dies bringt uns zur letzten Frage – wie haben sich ihre Gefühle und Emotionen im Laufe der Jahre verändert? Für diese spezielle Antwort erstellen wir eine Visualisierung namens chord diagram . Hier ist der Code:
[code language="r"]
grid.col = c("2006" = "#E69F00", "2008" = "#56B4E9", "2010" = "#009E73", "2012" = "#CC79A7", "2014" = "#D55E00" , „2017“ = „#00D6C9“, „Wut“ = „grau“, „Vorfreude“ = „grau“, „Ekel“ = „grau“, „Angst“ = „grau“, „Freude“ = „grau“, „Traurigkeit“ = „grau“, „Überraschung“ = „grau“, „Vertrauen“ = „grau“)
year_emotion <- lyric_sentiment %>%
filter(!Sentiment %in% c(„positiv“, „negativ“)) %>%
Anzahl (Stimmung, Jahr) %>%
group_by(Jahr, Stimmung) %>%
summarise(sentiment_sum = sum(n)) %>%
Gruppierung aufheben ()
Zirkus.clear()
#Einstellen der Lückengröße
circos.par(gap.after = c(rep(6, length(unique(year_emotion[[1]])) – 1), 15,
rep(6, length(einzigartig(year_emotion[[2]])) – 1), 15))
chordDiagram(year_emotion, grid.col = grid.col, Transparenz = .2)
title („Beziehung zwischen Emotion und Erscheinungsjahr des Songs“)
[/Code]
Es gibt uns die folgende Visualisierung:
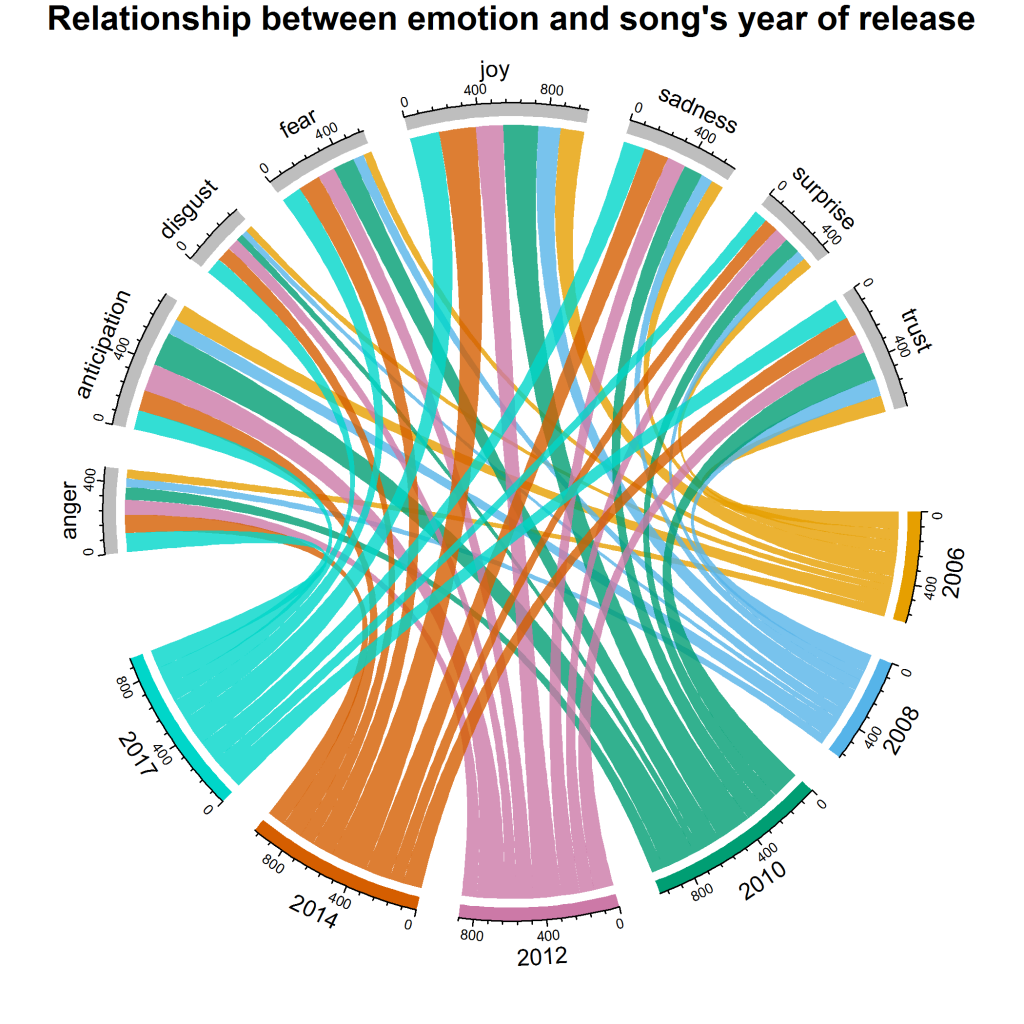
Wir können sehen, dass joy einen maximalen Anteil für die Jahre 2010 und 2014 hat. Insgesamt sind surprise , disgust und anger die Emotionen mit der geringsten Wertung; Im Vergleich zu anderen Jahren hat 2017 jedoch den höchsten disgust . anticipation haben 2010 und 2012 höhere Beiträge im Vergleich zu anderen Jahren.
Zu dir hinüber
In dieser Studie haben wir explorative Analysen und Text-Mining durchgeführt, was NLP für die Stimmungsanalyse beinhaltet. Wenn Sie zusätzliche Analysen (z. B. lexikalische Dichte von Liedtexten und Themenmodellierung) durchführen oder die Ergebnisse einfach zum Lernen replizieren möchten, laden Sie den Datensatz kostenlos von DataStock herunter. Folgen Sie einfach dem unten angegebenen Link und wählen Sie auf DataStock die Kategorie „gratis“.
