
Визуализация данных и анализ текстов песен Тейлор Свифт
Опубликовано: 2018-07-19Знаете ли вы, что Тейлор Свифт — самый молодой человек, который в одиночку написал и исполнил песню номер один в чарте Hot Country Songs, опубликованном журналом Billboard в США! Она особенно известна тем, что вкладывает свою личную жизнь в свою музыку, которая широко освещается в СМИ. Было бы интересно проанализировать тексты песен Тейлор Свифт с помощью исследовательского анализа и анализа настроений, чтобы выяснить различные основные темы.
Набор данных для анализа текстов песен Тейлор Свифт
Благодаря удивительному API, предоставленному Genius.com, мы смогли извлечь различные точки данных, связанные с песнями Тейлор Свифт.
Мы отобрали только шесть выпущенных ею альбомов и удалили повторяющиеся треки (акустика, американская версия, поп-микс, демо-запись и т.д.). В результате получилось 94 уникальных трека со следующими полями данных:
- название альбома
- название трека
- номер дорожки
- лирический текст
- номер строчки
- год выпуска альбома
[call_to_action title="Загрузить набор данных бесплатно" icon="icon-download" link="https://app.promptcloud.com/users/sign_up?target=data_stocks&itm_source=website&itm_medium=blog&itm_campaign=dataviz&itm_term=ts-lyrics&itm_content= data-mining" button_title="" class="" target="_blank" animate=""]Зарегистрируйтесь в DataStock через CrawlBoard и выберите категорию "бесплатно", чтобы загрузить набор данных![/call_to_action]
Цели
Наша цель — сначала выполнить исследовательский анализ, а затем перейти к интеллектуальному анализу текста, включая анализ настроений, который включает обработку естественного языка.
– Исследовательский анализ
- количество слов на основе треков и альбомов
- анализ временных рядов количества слов
- распределение количества слов
- Интеллектуальный анализ текста
- облако слов
- сеть биграмм
- анализ настроений (включает хордовую диаграмму)
Мы будем использовать R и ggplot2 для анализа и визуализации данных. Код также включен в этот пост, поэтому, если вы загрузите данные, вы можете следить за ним.
Исследовательский анализ
Давайте сначала узнаем десятку песен с наибольшим количеством слов. Фрагмент кода, приведенный ниже, включает в себя пакеты, необходимые для этого анализа, и определяет лучшие песни с точки зрения длины.
[кодовый язык = "r"]
библиотека (магритр)
библиотека (строка)
библиотека (dplyr)
библиотека (ggplot2)
библиотека (тм)
библиотека (облако слов)
библиотека(сюжет)
библиотека (аккуратный текст)
библиотека (тидыр)
библиотека (играф)
библиотека (ggraph)
библиотека (читатель)
библиотека (круг)
библиотека (изменить форму2)
лирика <- read.csv(file.choose())
длина лирики $ <- str_count (лирика $ лирика, «S +»)
length_df <- текст песни %>%
group_by(track_title) %>%
суммировать (длина = сумма (длина))
length_df %>%
упорядочить (описание (длина)) %>%
срез (1:10) %>%
ggplot(., aes(x= изменить порядок(track_title, -length), y=длина)) +
geom_bar(stat='identity', fill=”#1CCCC6″) +
ylab («Количество слов») + xlab («Название дорожки») +
ggtitle("10 лучших песен по количеству слов") +
тема_минимальный() +
scale_x_discrete (метки = функция (метки) {
sapply (seq_along (метки), функция (i) paste0 (ifelse (i %% 2 == 0, ", 'n'), метки [i]))
})
[/код]
Это дает нам следующий график:
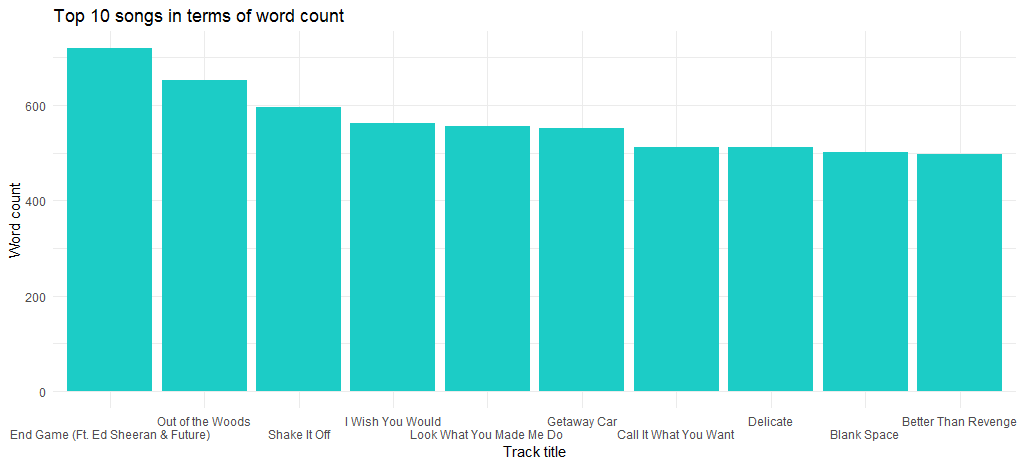
Мы видим, что «End Game» (выпущенная в ее последнем альбоме) — это песня с максимальным количеством слов, а следующая на очереди — «Out of the Woods».
А как насчет песен с наименьшим количеством слов? Давайте узнаем, используя следующий код:
[кодовый язык = "r"]
length_df %>%
аранжировать(длина) %>%
срез (1:10) %>%
ggplot(., aes(x= переупорядочить(track_title, длина), y=длина)) +
geom_bar(stat='identity', fill=”#1CCCC6″) +
ylab («Количество слов») + xlab («Название дорожки») +
ggtitle("10 песен с наименьшим количеством слов") +
тема_минимальный() +
scale_x_discrete (метки = функция (метки) {
sapply (seq_along (метки), функция (i) paste0 (ifelse (i %% 2 == 0, ", 'n'), метки [i]))
})
[/код]
В результате получается следующая диаграмма:
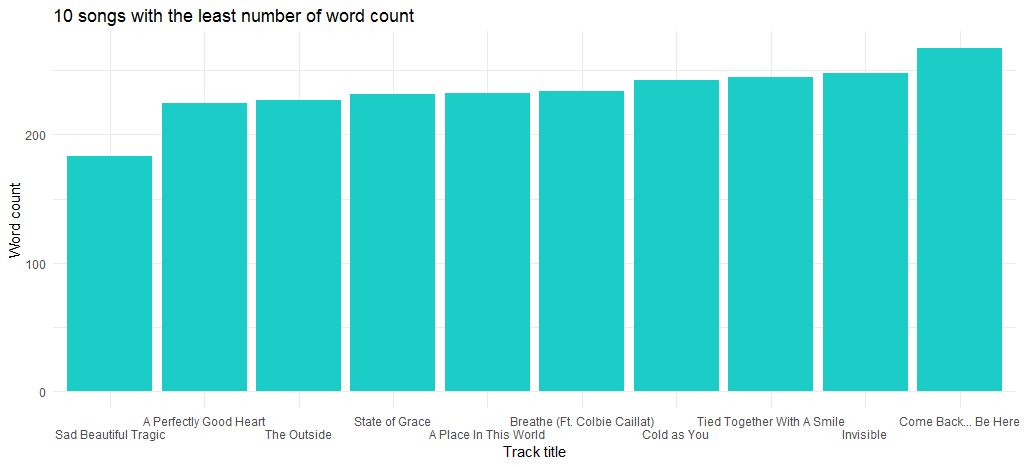
Песня «Sad Beautiful Tragic», выпущенная в 2012 году в составе альбома «Red», является песней с наименьшим количеством слов.
Следующий анализ данных сосредоточен вокруг распределения количества слов. Ниже приведен код:
[кодовый язык = "r"]
ggplot (length_df, aes (x = длина)) +
geom_histogram (бины = 30, aes (заполнить = .. количество ..)) +
geom_vline (aes (xintercept = среднее (длина)),
цвет = «#FFFFFF», тип линии = «штрих», размер = 1) +
geom_density(aes(y=25 * ..count..),alpha=.2, fill=”#1CCCC6″) +
ylab («Количество») + xlab («Длина») +
ggtitle("Распределение количества слов") +
тема_минимальный()
[/код]
Этот код дает нам следующую гистограмму вместе с кривой плотности:
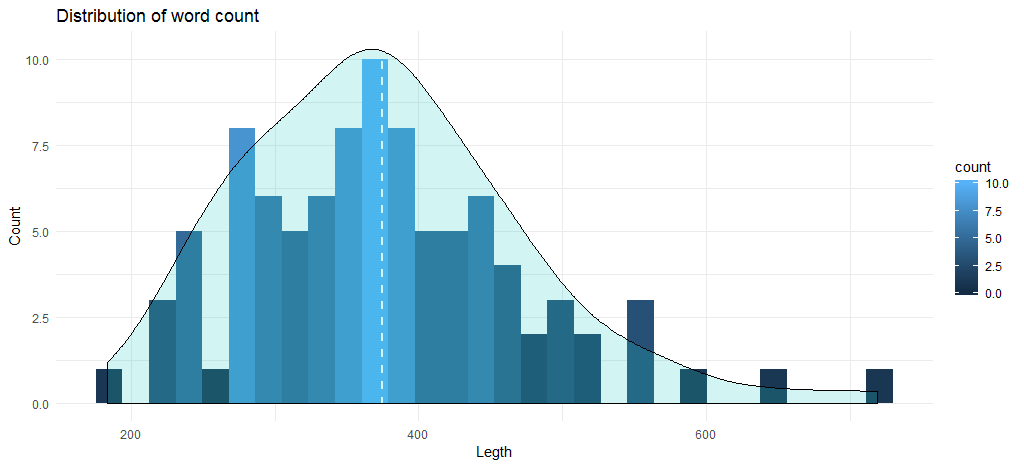
Среднее количество слов в треках приближается к 375, а диаграмма показывает, что максимальное количество песен находится в диапазоне от 345 до 400 слов. Теперь перейдем к анализу данных на основе альбомов. Давайте сначала создадим фрейм данных с количеством слов на основе альбома и года выпуска.
[кодовый язык = "r"]
текст %>%
group_by(альбом,год) %>%
суммировать (длина = сумма (длина)) -> length_df_album
[/код]
Следующим шагом для нас является создание диаграммы, которая будет отображать продолжительность альбомов на основе совокупного количества слов в песнях.
[кодовый язык = "r"]
ggplot (length_df_album, aes (x = изменить порядок (альбом, -длина), y = длина)) +
geom_bar(stat='identity', fill=”#1CCCC6″) +
ylab («Количество слов») + xlab («Альбом») +
ggtitle("Подсчет слов по альбомам") +
тема_минимальный()
[/код]
Полученная диаграмма показывает, что альбом «Reputation», который также является последним альбомом, имеет максимальное количество слов.
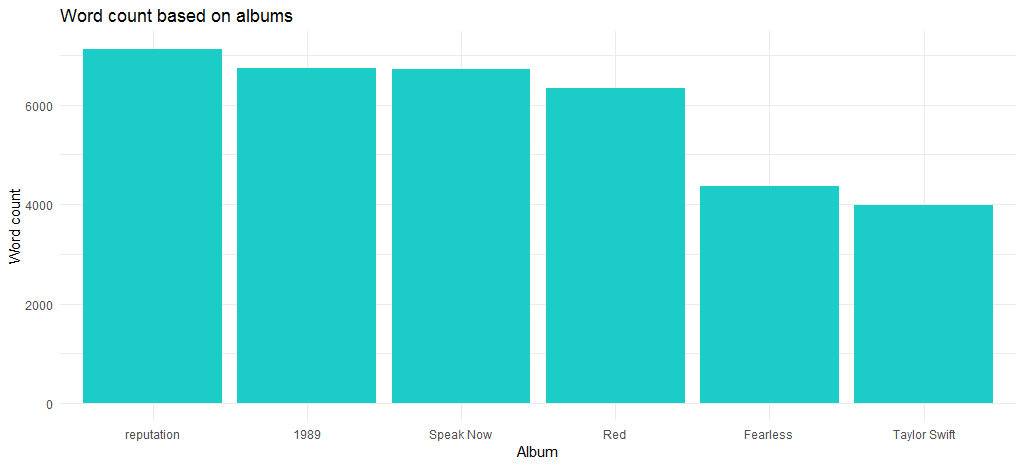
Итак, как изменилась продолжительность песен с момента дебюта в 2006 году? На это отвечает следующий код:
[кодовый язык = "r"]
length_df_album %>%
упорядочить (описание (год)) %>%
ggplot (., aes (x = фактор (год), y = длина, группа = 1)) +
geom_line (цвет = «# 1CCCC6», размер = 1) +
ylab («Количество слов») + xlab («Год») +
ggtitle("С годами количество слов меняется") +
тема_минимальный()
[/код]
Полученная диаграмма показывает, что объем альбомов с годами увеличился — с почти 4000 слов в 2006 году до более чем 6700 в 2017 году.
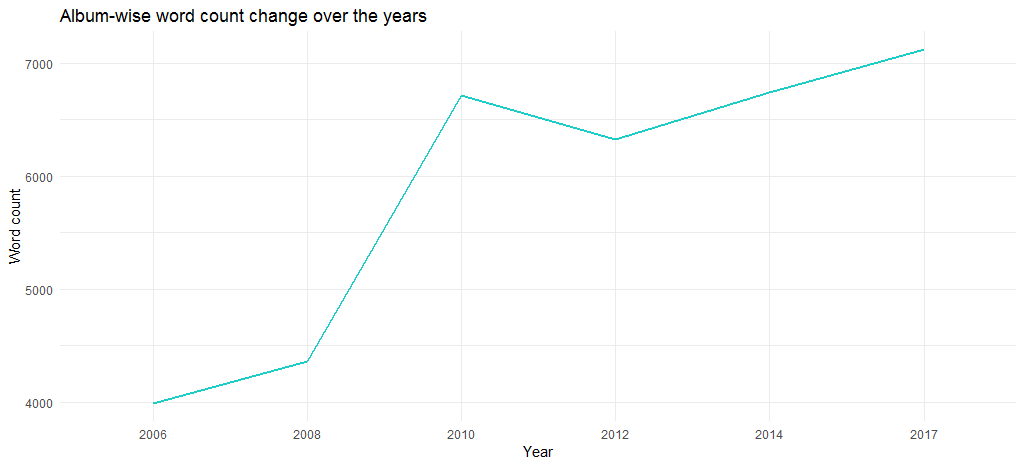
Но это из-за количества слов в отдельных треках? Давайте узнаем, используя следующий код:
[кодовый язык = "r"]
# добавление столбца года путем сопоставления track_title
length_df$год <- лирика$год[соответствие(length_df$track_title, лирика$track_title)]
length_df %>%
group_by(год) %>%
суммировать (длина = среднее (длина)) %>%
ggplot (., aes (x = фактор (год), y = длина, группа = 1)) +
geom_line (цвет = «# 1CCCC6», размер = 1) +
ylab («Среднее количество слов») + xlab («Год») +
ggtitle("Среднее изменение количества слов за год") +
тема_минимальный()
[/код]
Полученная диаграмма подтверждает, что среднее количество слов с годами увеличилось (с 285 в 2006 г. до 475 в 2017 г.), т. е. ее песни постепенно становились более длинными по содержанию.
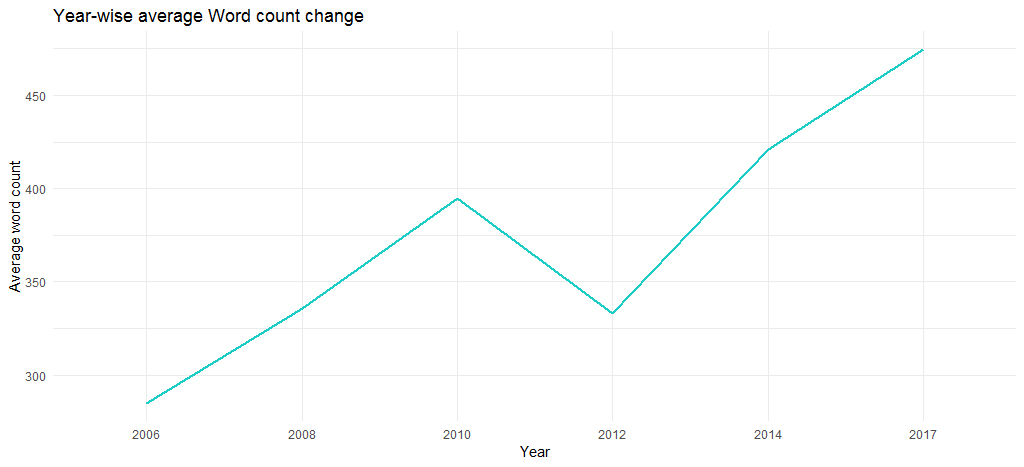
На этом мы завершим исследовательский анализ и перейдем к интеллектуальному анализу текста.
Текстовый анализ текстов песен Тейлор Свифт
Нашим первым действием будет создание облака слов, чтобы мы могли визуализировать часто используемые слова в ее текстах. Для начала выполните следующий код:
[кодовый язык = "r"]
библиотека («тм»)
библиотека («облако слов»)
лирика_текст <- лирика$лирик
#Удаление пунктуации и буквенно-цифрового содержимого
текст_текста<- gsub('[[:punct:]]+', ", текст_текста)
Текст_текста<- gsub("([[:alpha:]])1+", "", Текст_текста)
#создание корпуса текстов
документы <- Корпус (VectorSource (текст_текста))
# Преобразование текста в нижний регистр
документы <- tm_map (документы, content_transformer (tolower))
# Удаление английских стоп-слов
docs <- tm_map(docs, removeWords, стоп-слова("английский"))
# создание матрицы документа термина
tdm <- TermDocumentMatrix(docs)
# определение tdm как матрицы
m <- as.matrix(tdm)
# получение количества слов в порядке убывания
word_freqs = сортировка (суммы строк (м), уменьшение = ИСТИНА)
# создание фрейма данных со словами и их частотностью
song_wc_df <- data.frame(word=names(word_freqs), freq=word_freqs)
лирика_wc_df <- лирика_wc_df[1:300,]
# построение облака слов
set.seed(1234)
облако слов (слова = текст_wc_df$слово, частота = текст_wc_df$частота,
мин.частота = 1, шкала = с (1,8, 5),
max.words=200, random.order=FALSE, rot.per=0,15,
colors=brewer.pal(8, «Dark2»))

[/код]
Полученное облако слов показывает, что наиболее часто используемые слова: know , like , don't , you're , now , back . Это подтверждает, что ее песни в основном о ком-то, так как you're значительное количество упоминаний.
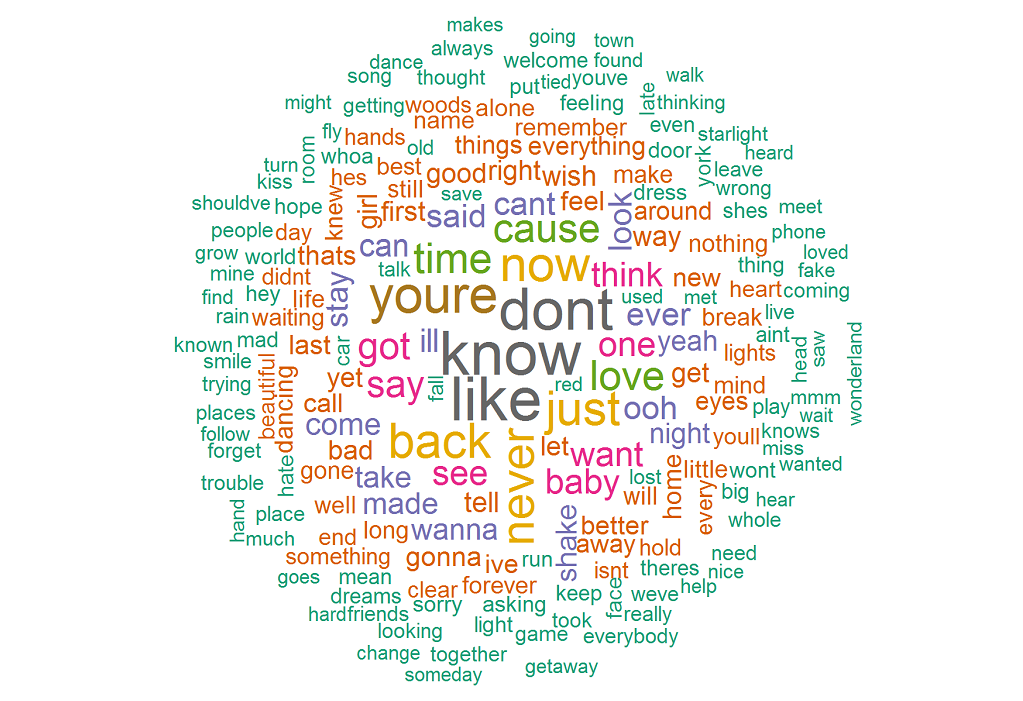
Как насчет биграмм (пар слов, которые встречаются вместе)? Следующий код даст нам первую десятку биграмм:
[кодовый язык = "r"]
count_bigrams <- функция (набор данных) {
набор данных %>%
unnest_tokens (bigram, lyric, token = «ngrams», n = 2) %>%
раздельно(биграмма, с("слово1", "слово2"), sep = " ") %>%
filter(!word1 %in% stop_words$слово,
!word2 %in% stop_words$word) %>%
количество (слово1, слово2, сортировка = ИСТИНА)
}
лирика_биграммы <- лирика %>%
count_bigrams()
голова (lyrics_bigrams, 10)
[/код]
Ниже приведен список биграмм:
| Слово 1 | Слово 2 |
|---|---|
| Эй | Эй |
| ох | ох |
| ля | ля |
| встряхнуть | встряхнуть |
| остаться | остаться |
| уходи | автомобиль |
| га | га |
| ох | вау |
| Эм-м-м | Эм-м-м |
| га | ах |
Хотя мы узнали список слов, он не дает никакого представления о некоторых отношениях, существующих между словами. Чтобы получить визуализацию множественных взаимосвязей, которые могут существовать, мы будем использовать сетевые графы. Давайте начнем со следующего:
[кодовый язык = "r"]
visualize_bigrams <- function(bigrams) {
set.seed (2016)
a <- grid::arrow(type = «closed», length = unit(.15, «дюймы»))
биграммы %>%
graph_from_data_frame() %>%
ggraph (макет = «fr») +
geom_edge_link (aes (edge_alpha = n), show.legend = FALSE, стрелка = a) +
geom_node_point (цвет = «голубой», размер = 5) +
geom_node_text (aes (метка = имя), vjust = 1, hjust = 1) +
ggtitle("Сетевой граф биграмм") +
тема_void()
}
лирика_биграммы %>%
фильтр (n > 3,
!str_detect(слово1, «д»),
!str_detect(word2, «d»)) %>%
визуализировать_биграммы()
[/код]
Посмотрите на приведенный ниже график, чтобы увидеть, как love связана с story , mad , true , tragic , magic и affair . Также с beautiful связано и tragic , и magic .

Давайте теперь перейдем к анализу настроений, который представляет собой метод анализа текста.
Анализ настроений песен Тейлор Свифт
Сначала мы узнаем общее настроение с помощью метода nrc пакета syuzhet . Следующий код создаст диаграмму положительной и отрицательной полярности вместе с соответствующими эмоциями.
[кодовый язык = "r"]
# Получение значения тональности для текстов песен
ty_sentiment <- get_nrc_sentiment((lyrics_text))
# Dataframe с кумулятивным значением настроений
оценки настроений <-data.frame(colSums(ty_sentiment[,]))
# Dataframe с настроением и оценкой в виде столбцов
имена (оценка настроений) <- «Оценка»
оценки настроений <- cbind («настроения» = имена строк (оценки настроений), оценки настроений)
имена строк (показатели настроений) <- NULL
# График для кумулятивных настроений
ggplot (данные = оценки настроений, aes (x = настроения, y = оценка)) +
geom_bar (aes (fill = настроение), stat = «личность») +
тема(легенда.позиция=”нет”)+
xlab("Настроения")+ylab("Оценки")+
ggtitle("Общее мнение на основе оценок")+
тема_минимальный()
[/код]
Полученная диаграмма показывает, что положительные и отрицательные оценки настроений относительно близки со значениями 1340 и 1092 соответственно. Что касается эмоций, joy , anticipation и trust выходят на тройку лидеров.
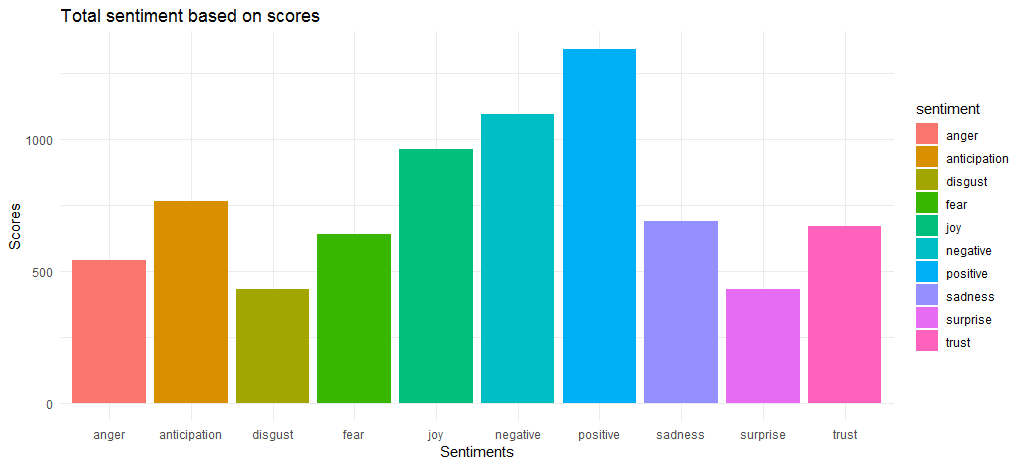
Теперь, когда мы вычислили общие оценки тональности, мы должны выяснить, какие слова чаще всего вызывают различные эмоции и положительные/отрицательные настроения.
[кодовый язык = "r"]
лирика $ лирика <- as.character (лирика $ лирика)
tidy_lyrics <- текст песни %>%
unnest_tokens (слово, текст)
song_wrd_count <- tidy_lyrics %>% count(track_title)
lyric_counts <- tidy_lyrics %>%
left_join (song_wrd_count, by = «track_title») %>%
переименовать(total_words=n)
lyric_sentiment <- tidy_lyrics %>%
inner_join (get_sentiments («nrc»), by = «слово»)
lyric_sentiment %>%
количество (слово, настроение, сортировка = ИСТИНА) %>%
group_by(настроение)%>%top_n(n=10) %>%
разгруппировать() %>%
ggplot (aes (x = изменить порядок (слово, n), y = n, заполнить = настроение)) +
geom_col(show.legend = ЛОЖЬ) +
facet_wrap (~ настроение, весы = «бесплатно») +
xlab("Настроения") + ylab("Оценки")+
ggtitle("Лучшие слова, используемые для выражения эмоций и чувств") +
координата_флип ()
[/код]
Приведенная визуализация данных показывает, что в то время как слово « bad » преобладает в таких эмоциях, как anger , disgust , sadness и fear, « Surprise и « trust » определяются словом « good ».
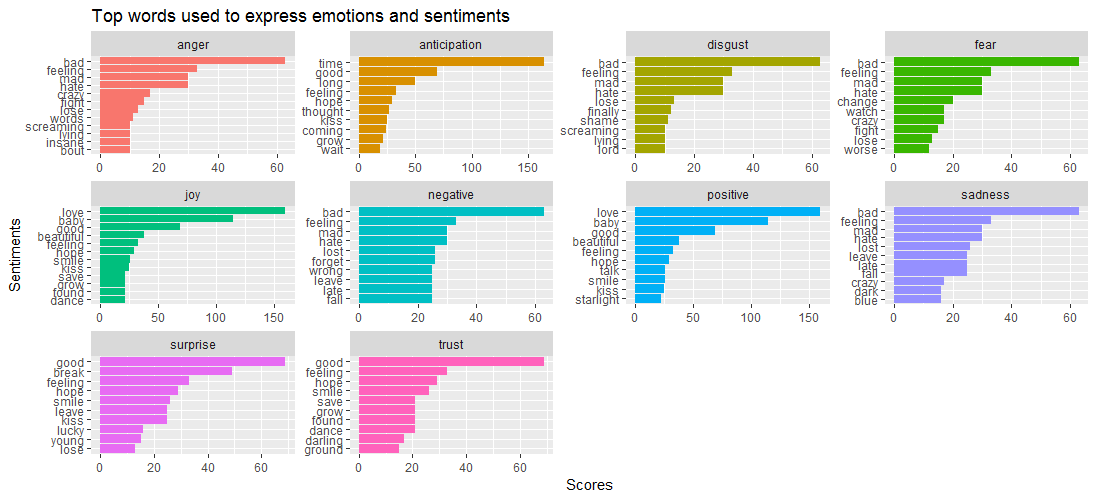
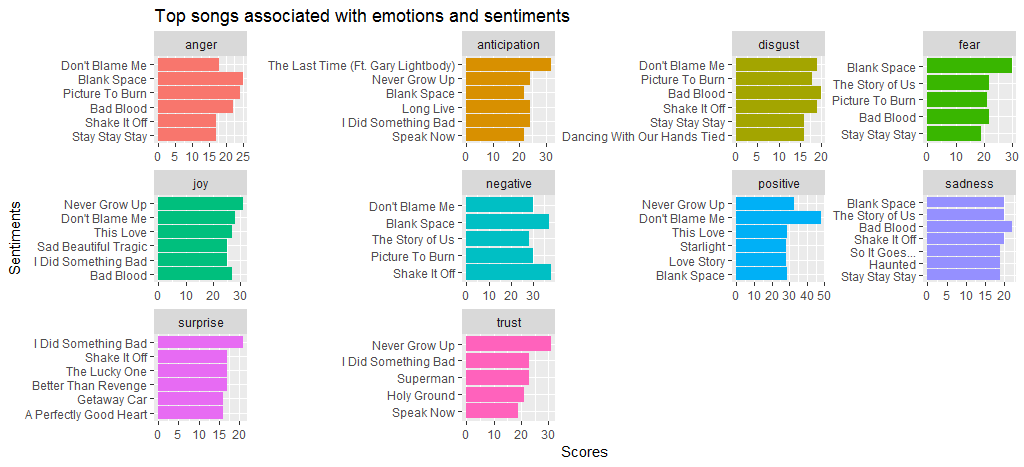
Это приводит к следующему вопросу – какие песни тесно связаны с разными эмоциями? Давайте выясним это с помощью кода, приведенного ниже:
[кодовый язык = "r"]
lyric_sentiment %>%
count(track_title,настроение,sort=TRUE) %>%
group_by(настроение) %>%
топ_n(n=5) %>%
ggplot(aes(x=переупорядочить(track_title,n),y=n,fill=настроение)) +
geom_bar (stat = «идентификация», show.legend = FALSE) +
facet_wrap (~ настроение, весы = «бесплатно») +
xlab("Настроения") + ylab("Оценки")+
ggtitle("Лучшие песни, связанные с эмоциями и чувствами") +
координата_флип ()
[/код]
Мы видим, что в песне Black Space много гнева и страха по сравнению с другими песнями. Не вините меня, потому что у меня значительный балл как за positive , так и за negative настроения. Мы также видим, что Shake it off высокие баллы за negative настроение; в основном из-за часто используемых слов, таких как hate и fake .
Давайте теперь перейдем к другому методу анализа настроений, а bing к созданию сравнительного облака слов положительных и отрицательных настроений.
[кодовый язык = "r"]
bng <- get_sentiments («bing»)
set.seed(1234)
tidy_lyrics %>%
inner_join (get_sentiments («bing»)) %>%
количество (слово, настроение, сортировка = ИСТИНА) %>%
acast (слово ~ настроение, value.var = «n», fill = 0) %>%
сравнение. облако (цвета = c («# F8766D», «# 00BFC4»)),
макс.слов = 250)
[/код]
Последующая визуализация данных показывает, что в ее песнях есть положительные слова, такие как like , love , good , right , и отрицательные слова, такие как bad , break , shake , mad , wrong .
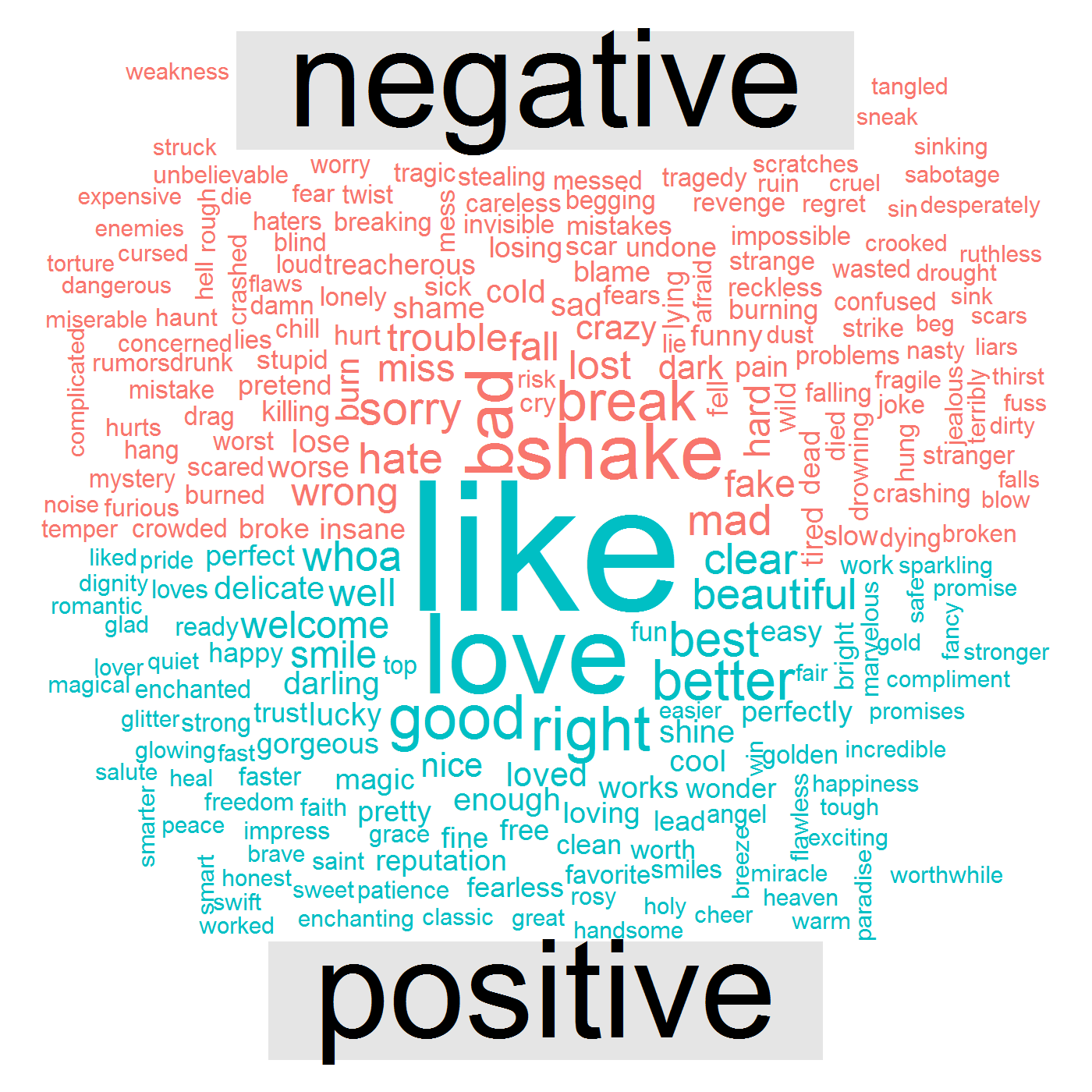
Это приводит к последнему вопросу – как изменились ее чувства и эмоции за эти годы? Для этого конкретного ответа мы создадим визуализацию, называемую chord diagram . Вот код:
[кодовый язык = "r"]
grid.col = c("2006" = "#E69F00", "2008" = "#56B4E9", "2010" = "#009E73", "2012" = "#CC79A7", "2014" = "#D55E00" , «2017» = «#00D6C9», «гнев» = «серый», «ожидание» = «серый», «отвращение» = «серый», «страх» = «серый», «радость» = «серый», «грусть» = «серый», «удивление» = «серый», «доверие» = «серый»)
year_emotion <- lyric_sentiment %>%
filter(!Отношение %in% c("положительное", "отрицательное")) %>%
count(настроение, год) %>%
group_by(год, настроение) %>%
суммировать (sentiment_sum = сумма (n)) %>%
разгруппировать()
circos.clear()
#Установка размера зазора
circos.par(gap.after = c(rep(6, length(unique(year_emotion[[1]]])) – 1), 15,
rep(6, length(unique(year_emotion[[2]])) – 1), 15))
chordDiagram (year_emotion, grid.col = grid.col, прозрачность = .2)
title("Связь между эмоциями и годом выпуска песни")
[/код]
Это дает нам следующую визуализацию:
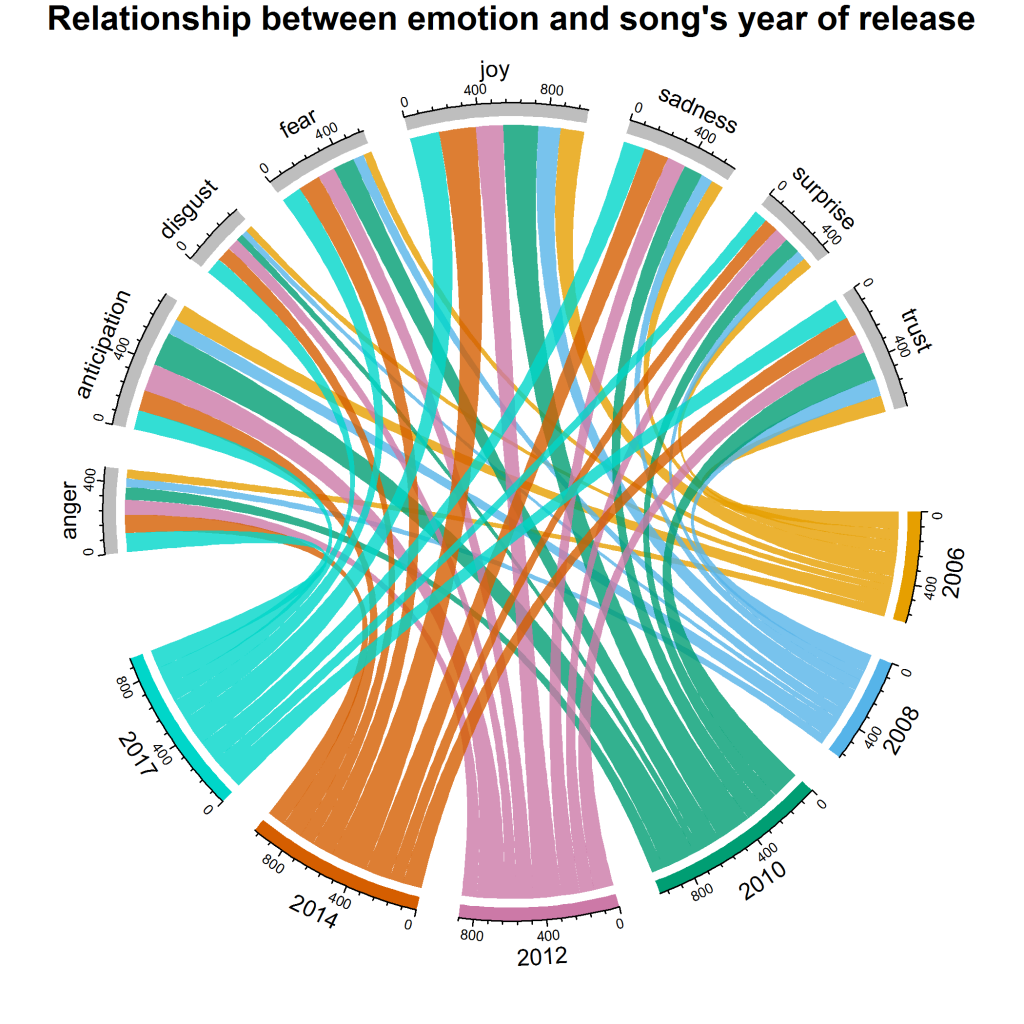
Мы видим, что joy имеет максимальную долю за 2010 и 2014 годы. В целом, surprise , disgust и anger являются эмоциями с наименьшим количеством баллов; однако по сравнению с другими годами 2017 год имеет максимальный вклад в disgust . Что касается anticipation , то в 2010 и 2012 годах взносы выше, чем в другие годы.
к вам
В этом исследовании мы провели исследовательский анализ и интеллектуальный анализ текста, который включает НЛП для анализа настроений. Если вы хотите провести дополнительный анализ (например, лексическую плотность текстов и моделирование темы) или просто воспроизвести результаты для обучения, бесплатно загрузите набор данных с DataStock. Просто перейдите по ссылке, указанной ниже, и выберите категорию «бесплатно» на DataStock.
