
Cum să remediați „Descoperit – Momentan neindexat” în Google Search Console
Publicat: 2022-01-11Documentația Google definește starea Descoperit – momentan neindexat în raportul Google Acoperire index ca:
Pagina a fost găsită de Google, dar încă nu a fost accesată cu crawlere. De obicei, Google dorea să acceseze cu crawlere adresa URL, dar se aștepta ca acest lucru să supraîncarce site-ul; prin urmare, Google a reprogramat accesarea cu crawlere. Acesta este motivul pentru care data ultimei accesări cu crawlere este goală în raport.sursa: Raportul Google Index Coverage
Tomek Rudzki a cercetat cele mai frecvente probleme de indexare afișate în Google Search Console și a descoperit că Discovered – moment neindexat este una dintre ele, chiar lângă:
- Conținut duplicat,
- Accesat cu crawlere – momentan nu este indexat,
- 404 moale și
- Probleme de crawler.
Abordarea problemei descoperite – neindexate în prezent ar trebui să fie o prioritate, deoarece poate afecta multe pagini și indică faptul că unele dintre paginile dvs. nu au fost accesate cu crawlere și ulterior indexate.
Această problemă poate fi cauzată de mulți factori care, dacă nu sunt abordați, pot duce la ca unele pagini să nu-și găsească niciodată drumul în indexul Google. Și dacă acesta este cazul, nu vă vor aduce trafic organic și nu vor genera conversii.
Acest articol este o analiză aprofundată în secțiunea Descoperit – neindexată în prezent a raportului Acoperirea indexului din Search Console, concentrându-se pe analizarea motivului pentru care paginile dvs. ajung acolo și cum să remediați orice probleme care ar putea cauza acest lucru.
Unde găsiți starea Descoperit – momentan neindexat
Descoperit – momentan neindexat este unul dintre tipurile de probleme din raportul Acoperirea indexului din Google Search Console. Raportul arată stările de accesare cu crawlere și de indexare a paginilor de pe site-ul dvs. web.
Descoperit – momentan neindexat apare în categoria Exclus , care include adrese URL pe care Google nu le-a indexat, dar, din perspectiva Google, această situație nu este rezultatul unei erori.
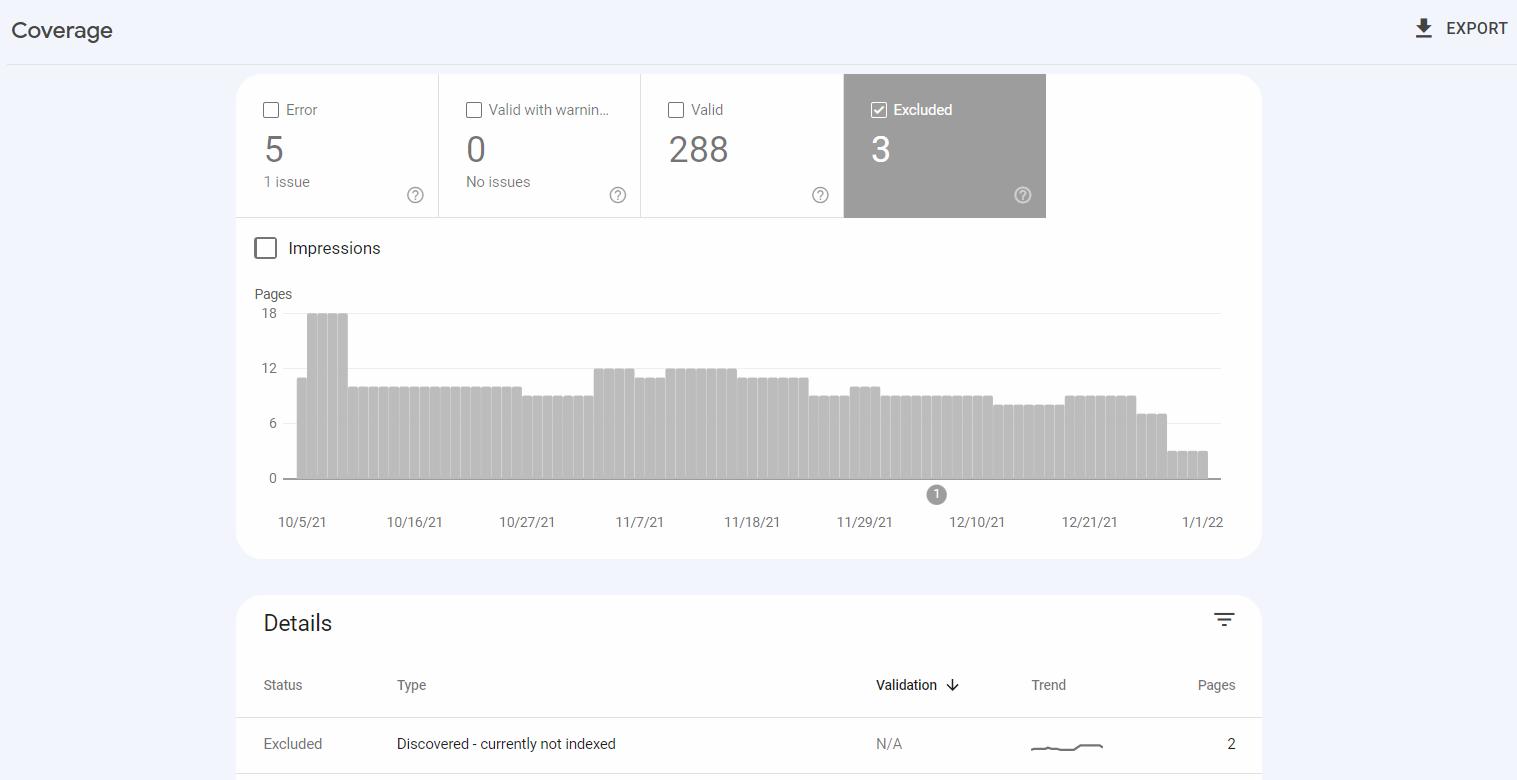
Când utilizați Google Search Console, puteți face clic pe tipul de problemă pentru a vedea o listă de adrese URL afectate.
Este posibil să descoperiți că ați intenționat să păstrați unele dintre adresele URL raportate în afara indexului – și asta e în regulă. Dar ar trebui să vă monitorizați paginile valoroase – dacă vreuna dintre ele nu a fost indexată, verificați ce probleme a găsit Google.
Descoperire, accesare cu crawlere și indexare
Înainte de a trece la caracteristicile Discovered – momentan neindexat și de a aborda această problemă, să clarificăm ce este nevoie pentru ca o adresă URL să fie clasată pe Google:
- Google trebuie să găsească o adresă URL înainte de a putea fi accesată cu crawlere. Adresele URL sunt descoperite cel mai frecvent urmărind link-uri interne sau externe sau sitemap-uri XML, care ar trebui să conțină toate paginile care ar trebui indexate.
- Prin accesarea cu crawlere a paginilor, Google le vizitează și le verifică conținutul. Google nu are resursele pentru a accesa cu crawlere toate paginile pe care le găsește – iar acest fapt se află în spatele multor probleme de accesare cu crawlere pe care le întâmpină site-urile.
- În timpul indexării , Google extrage conținutul paginilor și evaluează calitatea acestora. Indexarea este necesară pentru a apărea în rezultatele căutării și pentru a obține trafic organic de la Google. Paginile indexate sunt evaluate pe baza a numeroși factori de clasare , determinând modul în care sunt clasate ca răspuns la interogările de căutare introduse de utilizatori în Google.
A fi indexat de Google este o provocare din cauza capacității limitate a resurselor sale, a web-ului în continuă creștere și pentru că Google se așteaptă la un anumit nivel de calitate de la paginile pe care le indexează.
Mulți factori tehnici și legați de conținut pot juca un rol în ca paginile dvs. să nu fie accesate cu crawlere sau indexate.
Există soluții pentru a crește șansele de a fi indexat. Acestea includ:
- Având o strategie de crawling care prioritizează accesarea cu crawlere a părților valoroase ale site-ului dvs. web,
- Implementarea legăturilor interne,
- Crearea unui sitemap precis, care să conțină toate adresele URL care ar trebui să fie indexabile și
- Scrierea de conținut de înaltă calitate, valoros.
Asigurați-vă că parcurgeți documentația Google – există o secțiune despre liniile directoare de urmat pentru a facilita accesarea cu crawlere și indexarea paginilor de către Google.
Cum să utilizați secțiunea Descoperit – neindexat în prezent
Starea Descoperit – momentan neindexat este locul unde trebuie să mergeți pentru a fi la curent cu eventualele probleme de accesare cu crawlere.
După ce găsiți adrese URL în această secțiune, verificați dacă ar trebui să fie accesate cu crawlere în primul rând.
Dacă ar trebui, încercați să găsiți un model în ce adrese URL apar în raport . Acest lucru vă va ajuta să identificați ce aspecte ale acestor adrese URL ar putea cauza problema.
De exemplu, problema se poate referi la adresele URL dintr-o anumită categorie de produse, paginile cu parametri sau cele cu o structură specifică, ceea ce face ca toate acestea să fie considerate conținut subțire.
Când secțiunea Descoperit – momentan neindexat necesită acțiune
Adresele URL din Discovered – momentan care nu sunt indexate nu necesită întotdeauna să faceți modificări site-ului dvs.
Și anume, nu trebuie să faci nimic dacă:
- Numărul de adrese URL afectate este scăzut și rămâne stabil în timp sau
- Raportul conține adrese URL care nu ar trebui accesate cu crawlere sau indexate, de exemplu, cele cu etichete canonice sau „noindex” sau cele blocate de accesarea cu crawlere în fișierul robots.txt.
Dar este totuși crucial să avem secțiunea acestui raport sub control.
Adresele URL necesită atenția dvs. dacă numărul lor crește sau constau în adrese URL valoroase pe care vă așteptați să le clasați și să vă aducă trafic organic semnificativ.
Impactul Discovered – momentan nu este indexat pe site-uri mici vs. mari
Impactul secțiunii Discovered – moment neindexată poate diferi în funcție de dimensiunea unui site web.
Dacă aveți un site web mai mic – care de obicei nu depășește 10.000 de adrese URL – și paginile dvs. au conținut unic și de bună calitate, starea Descoperit – în prezent neindexată se va rezolva adesea de la sine. Este posibil ca Google să nu întâmpine nicio problemă, dar pur și simplu nu a accesat încă cu crawlere adresele URL enumerate.
Site-urile mici nu se confruntă, în general, cu probleme legate de bugetul de accesare cu crawlere și poate apărea o creștere a numărului de pagini raportate din cauza problemelor de calitate a conținutului sau a structurii proaste a legăturilor interne.
Starea Descoperit – momentan neindexat poate fi deosebit de gravă pentru site-urile mari (peste 10.000 de adrese URL) și se aplică la mii sau chiar milioane de adrese URL.
La Onely, am constatat că site-urile web care conțin mai mult de 100.000 de adrese URL suferă de obicei probleme de accesare cu crawlere , care provin adesea din bugetul de accesare cu crawlere irosit.
Aceste probleme vor apărea de obicei pe site-urile de comerț electronic . Acestea au adesea conținut duplicat sau subțire sau conțin produse epuizate sau expirate. Astfel de pagini nu vor avea de obicei calitatea necesară pentru a intra în coada de indexare a Google, cu atât mai puțin să fie accesate cu crawlere.
La lansarea unui site mare
Dacă tocmai lansați un site web mare, puteți ușura munca Googlebot de la început.
Dacă doriți să lansați un site mare, nu ar trebui să lansați imediat întreaga sa structură dacă conține multe pagini goale sau neterminate care vor fi actualizate abia mai târziu. Googlebot va întâlni aceste pagini și le va considera de calitate scăzută, ceea ce prezintă riscul de a avea un buget redus de accesare cu crawlere încă de la început. Și această situație poate dura chiar și ani să se remedieze.
Este mult mai bine să adăugați conținut pe măsură ce îl lansați în mod regulat. În acest fel, Googlebot are o impresie pozitivă despre calitatea dvs. chiar de la început.
Înainte de a lansa, ar trebui să aveți întotdeauna o strategie de indexare și accesare cu crawlere și să știți ce pagini ar trebui să fie vizitate de Google.
Cauzele descoperite – starea neindexată în prezent și cum să le remediați
De obicei, adresele URL vor fi clasificate ca Descoperite – momentan nu sunt indexate din cauza calității conținutului, a legăturilor interne sau a problemelor legate de bugetul de accesare cu crawlere.
Să ne gândim de ce este posibil să vedeți paginile dvs. cu această stare și cum să o remediați.
Probleme de calitate a conținutului
Google are praguri de calitate pe care dorește să le îndeplinească paginile , deoarece nu poate accesa cu crawlere și indexează totul pe web.
Este posibil ca Google să vadă unele pagini de pe domeniul dvs. ca nu merită accesate cu crawlere și să le omite, dând prioritate altor conținuturi mai valoroase. Drept urmare, aceste adrese URL pot fi marcate ca Descoperite – momentan neindexate.
Merită remarcat faptul că a avea URL-uri ca fiind descoperite – în prezent neindexate nu se limitează adesea la paginile marcate, ci mai degrabă ar putea fi o problemă de calitate a conținutului la nivel de site, după cum a spus John Mueller . Dacă Google consideră site-ul dvs. de calitate scăzută în comparație cu alt conținut de pe web, este posibil să omite accesarea cu crawlere și indexarea paginilor dvs.
Pentru a începe să rezolvați această problemă, parcurgeți lista de adrese URL afectate și asigurați-vă că fiecare pagină conține conținut unic. Conținutul ar trebui să satisfacă intenția de căutare a utilizatorului și să rezolve o anumită problemă.
Vă recomand să parcurgeți Ghidul pentru evaluarea calității pe care Google le urmează atunci când evaluează site-urile web – vă va ajuta să înțelegeți ce caută Google în conținutul găsit pe web.
În același timp, nu uitați că nu ar trebui să aveți toate paginile indexate.
Unele pagini de calitate scăzută nu ar trebui să fie indexabile , cum ar fi:
- Conținut învechit (cum ar fi articole de știri vechi),
- Pagini generate de o casetă de căutare într-un site web,
- Pagini generate prin aplicarea filtrelor,
- Conținut duplicat,
- Conținut generat automat,
- Conținut generat de utilizatori.
Cel mai bine este să blocați astfel de secțiuni să nu fie accesate cu crawlere și indexate în fișierul dvs. robots.txt.
În timpul programului de lucru SEO din 31 decembrie 2021, John Mueller a discutat despre modificarea calității unui site web ca o modalitate de a aborda Discovered – momentan neindexat:
[…] Efectuarea unor modificări de calitate mai mari pe un site web necesită destul de mult timp pentru ca sistemele Google să le înțeleagă. […] Acesta este ceva mai mult de câteva luni și nu câteva zile. […] Deoarece este nevoie de atât de mult pentru a obține modificări de calitate, recomandarea mea ar fi să nu faceți mici modificări și să așteptați să vedeți dacă este suficient de bun, ci mai degrabă să vă asigurați că, dacă faceți modificări semnificative de calitate, […] sunt chiar schimbări de calitate […]. Nu vrei să aștepți câteva luni și apoi să te decizi: „Oh, da, chiar trebuie să schimb și alte pagini”.sursa: John Mueller
Probleme de conectare internă
Googlebot urmărește linkurile interne de pe site-ul dvs. pentru a descoperi alte pagini și pentru a înțelege conexiunile dintre ele. Prin urmare, asigurați-vă că paginile dvs. cele mai importante sunt conectate frecvent la nivel intern.

Martin Splitt a vorbit despre motivul pentru care structurile de legături incorecte ar putea fi problematice în webinarul Rendering SEO :
[…] Dacă avem aproximativ o mie de adrese URL de la tine, toate sunt doar în harta site-ului și nu le-am văzut în niciuna dintre celelalte pagini pe care le-am accesat cu crawlere, s-ar putea să ne spunem: „Nu știm cât de important asta chiar este” […]. În loc să îl aveți doar în harta site-ului, creați un link către el din alte locuri de pe site-ul dvs., astfel încât atunci când accesăm cu crawlere aceste pagini, să vedem „Aha! Deci această pagină, și această pagină și această pagină indică toate această pagină de produs, deci poate că este puțin mai important decât acest alt produs care trăiește doar în harta site-ului” […].sursa: Martin Splitt
Legăturile interne adecvate se referă la conectarea paginilor dvs. pentru a crea o structură logică care ajută motoarele de căutare și utilizatorii să urmărească ierarhia site-ului dvs. Legăturile interne sunt, de asemenea, asociate cu modul în care este structurată arhitectura site-ului dvs.
A ajuta motoarele de căutare să găsească și să acorde importanța corespunzătoare paginilor dvs. include:
- Decideți care este conținutul dvs. de temelie și asigurați-vă că este legat de el din alte pagini,
- Adăugarea de linkuri contextuale în conținutul dvs.,
- Conectarea paginilor pe baza ierarhiei lor, de exemplu, legând paginile părinte la paginile secundare și invers, sau includerea de linkuri în navigarea site-ului,
- Evitarea plasării link-urilor într-un mod spam și optimizarea excesivă a textului de ancorare,
- Încorporarea de link-uri către produse sau postări conexe.
Puteți citi și acest articol despre îmbunătățirea structurii legăturilor interne.
Buget de accesare cu crawlere
Bugetul de accesare cu crawlere este numărul de pagini pe care Googlebot poate și dorește să le acceseze cu crawlere pe un site web.
Bugetul de accesare cu crawlere al unui site este determinat de:
- Limita ratei de accesare cu crawlere – câte adrese URL poate accesa Google, care este ajustată la capacitățile site-ului dvs.
- Cerere de accesare cu crawlere – câte adrese URL dorește Google să acceseze cu crawlere, în funcție de cât de importante consideră adresele URL, analizând popularitatea acestora și cât de des sunt actualizate.
Risipirea bugetului de accesare cu crawlere poate duce la accesarea ineficientă a site-ului dvs. de către motoarele de căutare. Ca urmare, unele părți fundamentale ale site-ului dvs. web pot fi omise.
Mulți factori pot cauza probleme legate de bugetul de accesare cu crawlere - aceștia includ:
- Conținut de calitate scăzută,
- Structură de legătură internă slabă,
- Greșeli în implementarea redirecționărilor,
- Servere supraîncărcate,
- Site-uri web grele.
Înainte de a optimiza bugetul de accesare cu crawlere, ar trebui să vă uitați la modul exact în care Googlebot vă accesează cu crawlere site-ul.
Puteți face acest lucru navigând la un alt instrument util în Search Console – raportul Statistici de accesare cu crawlere. De asemenea, verificați jurnalele de server pentru informații detaliate despre ce resurse a accesat cu crawlere Googlebot și ce a omis.
Mai jos sunt 5 aspecte pe care ar trebui să le analizați pentru a vă optimiza bugetul de accesare cu crawlere și pentru a determina Google să acceseze cu crawlere unele dintre paginile descoperite, care nu sunt în prezent indexate de pe site-ul dvs.:
Conținut de calitate scăzută
Dacă Googlebot poate accesa cu crawlere pagini de calitate scăzută, este posibil să nu aibă resursele necesare pentru a ajunge la lucrurile valoroase de pe site-ul dvs.
Pentru a împiedica crawlerele motoarelor de căutare să acceseze cu crawlere anumite pagini, aplicați directivele corecte din fișierul robots.txt.
De asemenea, trebuie să vă asigurați că site-ul dvs. are o hartă a site-ului optimizată corect, care ajută Googlebot să descopere pagini unice, indexabile de pe site și să observe modificări ale acestora.
Harta site-ului trebuie să conțină:
- URL-uri care răspund cu 200 de coduri de stare,
- Adresele URL fără etichete meta roboți care le împiedică să fie indexate și
- Doar versiunile canonice ale paginilor dvs.
Structură de legătură internă slabă
Dacă Google nu găsește suficiente linkuri care ajung la o adresă URL, poate să omite accesarea cu crawlere din cauza semnalelor insuficiente care indică importanța acesteia.
Urmați îndrumările mele prezentate în subcapitolul „Probleme de conectare internă”.
Greșeli în implementarea redirecționărilor
Implementarea redirecționărilor poate fi benefică pentru site-ul dvs., dar numai dacă este făcută corect. Ori de câte ori Googlebot întâlnește o adresă URL redirecționată, trebuie să trimită o solicitare suplimentară pentru a ajunge la adresa URL de destinație, care necesită mai multe resurse.
Asigurați-vă că respectați cele mai bune practici pentru implementarea redirecționărilor. Puteți redirecționa atât utilizatorii, cât și roboții din paginile de eroare 404 care au fost legate din surse externe către pagini de lucru, ceea ce vă va ajuta să păstrați semnalele de clasare.
Asigurați-vă totuși că nu faceți linkuri către pagini redirecționate – în schimb, actualizați-le astfel încât să trimită către paginile corecte. De asemenea, trebuie să evitați buclele și lanțurile de redirecționare.
Probleme cu serverul
Google ar putea întâmpina probleme de accesare cu crawlere, deoarece site-ul dvs. părea a fi supraîncărcat. Acest lucru se întâmplă deoarece rata de accesare cu crawlere, care afectează bugetul de accesare cu crawlere, este ajustată la capacitățile serverului dvs.
Într-un webinar despre Rendering SEO , Martin Splitt a discutat despre problemele serverului legate de accesarea cu crawlere a paginilor de către Google:
[…] Un lucru pe care îl văd că se întâmplă destul de des este că serverele dau erori intermitente – în special, 500 de ceva – și orice la care serverul tău răspunde cu un 500, 501, 502, 504, orice înseamnă că serverul tău spune „Așteaptă”. , Am o problemă aici' […], și s-ar putea să cadă în orice moment, așa că ne dăm înapoi. Ori de câte ori ne retragem și serverul dvs. răspunde pozitiv, de obicei creștem din nou încet. Imaginați-vă că aveți un răspuns de 500 de ceva în fiecare zi.Vedem asta, ne retragem un pic, revenim – o vedem din nou […]. Ar trebui să verificați dacă serverul dvs. răspunde negativ.
sursa: Martin Splitt
Verificați cu furnizorul dvs. de găzduire dacă există probleme cu serverul pe site-ul dvs.
Problemele serverului pot fi cauzate și de performanța web slabă – aflați mai multe citind articolul nostru despre performanța web și bugetul de accesare cu crawlere.
Site-uri web grele
Problemele de accesare cu crawlere pot fi cauzate de faptul că unele pagini sunt prea grele. Este posibil ca Google pur și simplu să nu aibă resurse suficiente pentru a le accesa cu crawlere și a le reda.
Fiecare resursă pe care Googlebot trebuie să o preia pentru a vă afișa pagina contează în bugetul de accesare cu crawlere. În acest caz, Google vede o pagină, dar o împinge mai departe în coada de prioritate.
Ar trebui să optimizați fișierele JavaScript și CSS ale site-ului dvs. pentru a reduce impactul negativ al codului dvs.
A avea un site web nou
Tomek Rudzki a creat un sondaj pe Twitter în care a întrebat comunitatea SEO despre problemele de indexare pe site-uri noi. Și, potrivit rezultatelor sondajului, aproape 40% dintre oameni se confruntau cu astfel de probleme:
Aveți probleme cu indexarea noilor site-uri web RECENT?
— Tomek Rudzki (@TomekRudzki) 7 decembrie 2021
În timpul uneia dintre sesiunile SEO Office Hours, un participant a prezentat noul său site web care a fost lansat acum 2 luni, unde multe pagini au fost marcate ca Descoperite – momentan neindexate. Apoi a întrebat cât de lungi ar trebui să apară paginile cu acest statut, la care John a răspuns:
Asta poate fi pentru totdeauna […]. Și mai ales cu un site web mai nou, dacă aveți mult conținut, atunci aș presupune că este de așteptat ca o mulțime de conținut nou pentru o perioadă să fie descoperit și nu indexat. Și apoi, în timp, de obicei, se cam schimbă. Și este ca și cum, ei bine, este de fapt accesat cu crawlere sau este de fapt indexat când vedem că există de fapt valoare în a ne concentra mai mult pe site-ul în sine.sursa: John Mueller
De obicei, nu există remedieri rapide pentru indexarea paginilor, dar analizarea aspectelor SEO pe care le-am descris mai devreme vă poate ajuta să aveți o șansă mai bună de a le indexa.
Este clar că Google vrea să se asigure că indexează doar conținut de înaltă calitate, iar aceste praguri de calitate par să crească. Dar acest lucru este deosebit de dificil pentru site-urile web noi care trebuie să demonstreze Google, în repetate rânduri, că conținutul lor merită să fie în index.
Informații suplimentare despre adresarea Discovered – momentan nu sunt indexate
În timpul programului de lucru SEO, John Mueller a fost întrebat despre rezolvarea problemei a aproximativ 99% dintre adresele URL de pe un site blocat în secțiunea Descoperit – neindexat în prezent.
Recomandările lui John se învârte în jurul a trei pași principali:
[…] În primul rând, aș putea să văd […] că nu generați accidental adrese URL cu modele URL diferite, […] lucruri precum parametrii pe care îi aveți în adresa URL, litere mari, minuscule, toate aceste lucruri pot duce pentru a duplica în esență conținutul . Și dacă am descoperit multe dintre aceste adrese URL duplicate, am putea crede că de fapt nu trebuie să accesăm cu crawlere toate aceste duplicate, deoarece avem deja unele variante ale acestei pagini […]. Asigurați-vă că de la legătura internă, totul este ok. Că am putea accesa cu crawlere toate aceste pagini de pe site-ul tău web și am putea ajunge până la sfârșit. Puteți testa acest lucru folosind un instrument de crawler sau ceva de genul Screaming Frog sau Deep Crawl . […] Ei vă vor spune în esență dacă sunt capabili să acceseze cu crawlere site-ul dvs. și să vă arate adresele URL care au fost găsite în timpul acelei accesări cu crawlere. Dacă acest crawling funcționează, atunci m-aș concentra foarte mult pe calitatea acestor pagini . Dacă vorbești despre 20 de milioane de pagini și 99% dintre ele nu sunt indexate, atunci indexăm doar o mică parte a site-ului tău. […] Poate că are sens să spun: „Ei bine, ce se întâmplă dacă reduc numărul de pagini la jumătate sau poate chiar […] la 10% din numărul actual”. […] În general, puteți îmbunătăți calitatea conținutului de acolo, având un conținut mai cuprinzător pe aceste pagini. Și pentru sistemele noastre, este puțin mai ușor să ne uităm la aceste pagini și să spunem: „Ei bine, aceste pagini […] de fapt arată destul de bine. Ar trebui să plecăm, să ne târăm și să indexăm mult mai mult”.sursa: John Mueller
Într-o altă sesiune de program de birou din 18 februarie 2022, John a fost din nou întrebat despre un număr mare de adrese URL aparent blocate ca „Descoperite – momentan neindexate”.
Și John a spus că de multe ori este normal să ai o mulțime de pagini cu acest statut:
[…] Într-o oarecare măsură, aș accepta doar că Google nu poate accesa cu crawlere și indexa totul. […] Dacă recunoașteți, de exemplu, că […] produse individuale nu sunt accesate cu crawlere și indexate, asigurați-vă că cel puțin pagina de categorie pentru acele produse este accesată cu crawlere și indexată. Pentru că astfel, oamenii pot găsi în continuare conținut pentru acele produse individuale pe site-ul tău […].sursa: John Mueller
Membrii comunității SEO au raportat un număr crescut de pagini marcate ca Descoperite – momentan neindexate de luni de zile. Unii testează soluții alternative pentru a rezolva această problemă.
Dan Shure a decis să-l testeze prin mutarea conținutului blocat la diferite adrese URL, ceea ce a dus la indexarea acestora.
Deci, pare posibil ca multe dintre aceste pagini pur și simplu să se blocheze după ce inițial au rămas cu acest statut.
Descoperit – momentan neindexat vs. Crawled – momentan neindexat
Aceste două stări se confundă de obicei și, deși sunt conectate, înseamnă lucruri diferite.
În ambele cazuri, adresele URL nu au fost indexate, dar, cu Crawled – momentan neindexat, Google a vizitat deja pagina . Cu Discovered – momentan neindexată, pagina a fost găsită de Google, dar nu a fost accesată cu crawlere.
Accesat cu crawlere – indexat în prezent este adesea cauzat de o întârziere de indexare, probleme de calitate a conținutului, probleme de arhitectură a site-ului sau o pagină ar fi putut fi deindexată.
Avem, de asemenea, un articol detaliat care explică cum să remediați Crawled – momentan neindexat.
Încheierea
Descoperit – momentan neindexat tinde să fie cauzat de calitatea paginii și probleme legate de bugetul de accesare cu crawlere.
Remedierea acestor probleme – și ajutarea Google să acceseze cu crawlere eficient și precis paginile dvs. în viitor – vă poate necesita să parcurgeți multe aspecte ale paginilor dvs. și să le optimizați.
Iată câteva lucruri principale care pot ajuta la evitarea problemelor cu Discovered - pagini care nu sunt în prezent indexate:
- Utilizați robots.txt pentru a împiedica Googlebot să acceseze cu crawlere pagini de calitate scăzută, concentrându-se pe conținut duplicat, de exemplu, pagini generate de filtre sau casete de căutare de pe site-ul dvs.
- Acordați-vă timp pentru a crea un sitemap adecvat pe care Google îl poate folosi pentru a vă descoperi paginile.
- Păstrați arhitectura site-ului dvs. intactă și asigurați-vă că paginile dvs. esențiale sunt conectate intern.
- Aveți o strategie de indexare pentru a prioritiza paginile care sunt cele mai valoroase pentru dvs.
- Optimizați ținând cont de bugetul de accesare cu crawlere.